
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
Recurrent Neural Networks (RNN)
RNN은 기본적인 one-to-one vanilla Neural Network가 연속적으로 연결된 구조를 바탕으로 한다. 연결된 형태에 따라 다음과 같이 나눌 수 있다.
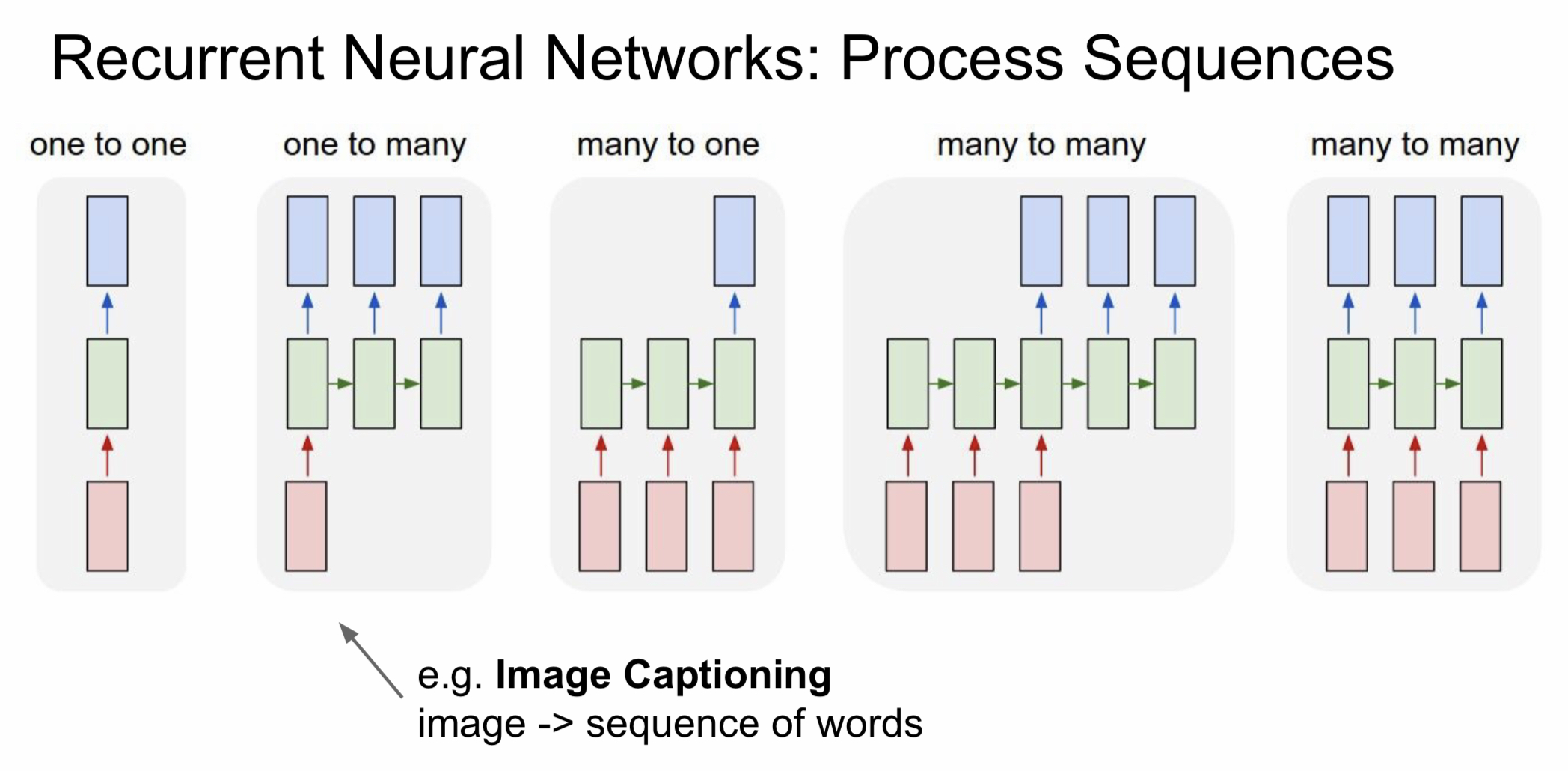
- one-to-many : image 값을 입력했을 때 그를 설명하는 단어들을 만들어내는 image captioning에서 많이 쓰인다.
- many-to-one : 연속적인 단어들을 입력했을 때 감정을 추출해내는 sentiment classification에서 많이 사용하는 방식이다.
- many-to-many : 문장을 넣었을 때 문장을 다시 추출할 수 있는 번역 모델에서 많이 사용된다. (네이버 파파고도 이러한 구조를 사용했다고는 한다..)
- many-to-many : 맨 오른쪽 그림과 같은 모델은 video classification on frame level에서 많이 사용되는 방식인데 실시간으로 영상을 분류할 때 사용되는 듯 하다.

이렇듯 RNN은 CNN과 달리 sequential processing을 바탕으로 만들어졌기에 문장, 비다오와 같이 sequential 한 data를 주로 잘 처리할 수 있다. 하지만 image와 같이 non-sequence data도 잘 처리할 수 있는데 아래와 같이 숫자 image가 있다고 할 때 image를 부분적으로 흘끔 보면서 처리하는 것이다. 이런 방식으로 하면 non-sequence data라 하더라도 sequential processing이 가능하다.
RNN의 기본 구조
RNN은 recurrent란 말에서 볼 수 있듯이 hidden state를 반복적으로 거친다. 약간 재귀함수랑 비슷한데 재귀함수에서 이전 값을 기억해 해당 값을 다음으로 넘기듯, RNN도 hidden state에 저장된 값을 다음 step에서 사용한다. 다만 이때 사용되는 가중치는 언제나 동일하다.
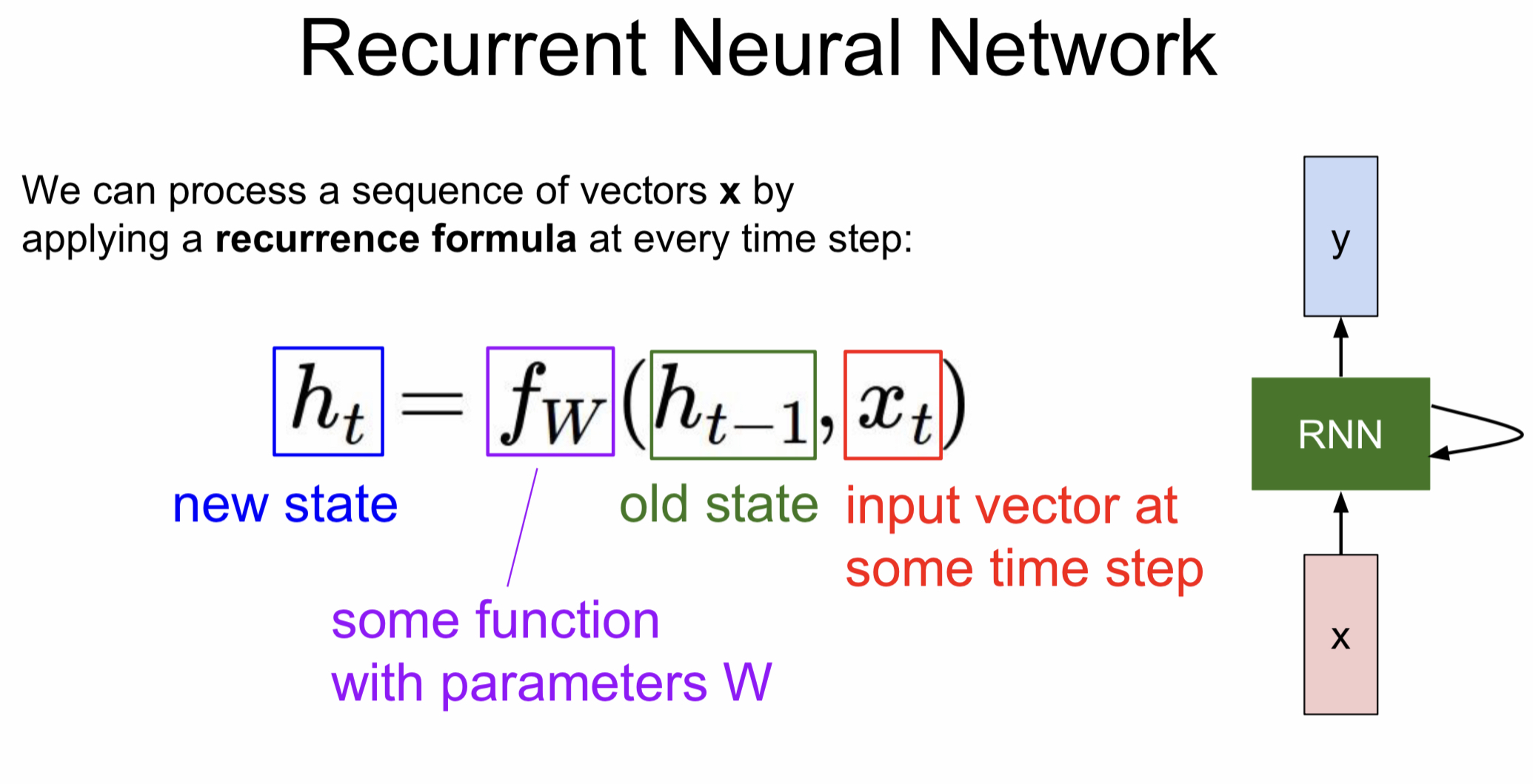
이런 구조를 갖게 된 이유는 앞서 살펴봤던 sequential process를 구현하기 위함이다. 문장을 번역한다고 했을 때 앞의 맥락을 알아야 뒷 말을 예측할 수 있는 것처럼 sequential한 구조에서는 이런 식으로 이전의 data를 기억해야만 하는 것이다.
Vanilla Recurrent Neural Network를 수식적으로 살펴보면 다음과 같다.

은 이전 상태를, 는 입력값, 는 hidden state에서 오는 가중치, 는 입력값에서 RNN으로 가는 가중치, 는 RNN cell에서 출력값으로 가는 가중치를 의미한다.
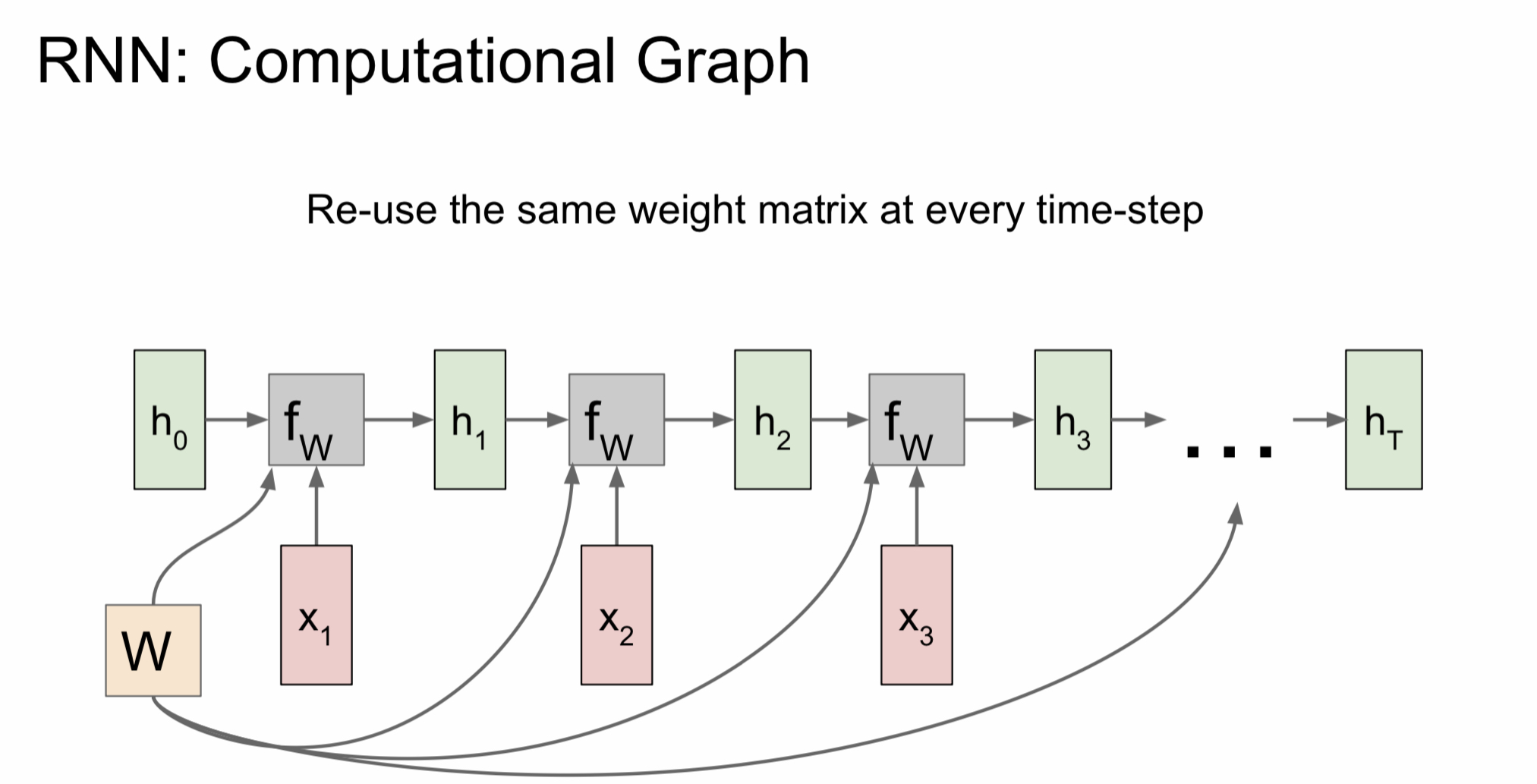
RNN 모델을 반복적으로 사용하는 것을 시간 순으로 computational graph를 그리면 위의 그림과 같다. 위의 그림에서 볼 수 있듯이 시간의 흐름에 따라 연속적인 입력값이 hidden state에 들어가고 이때 모두 같은 가중치를 사용하는 것을 알 수 있다.
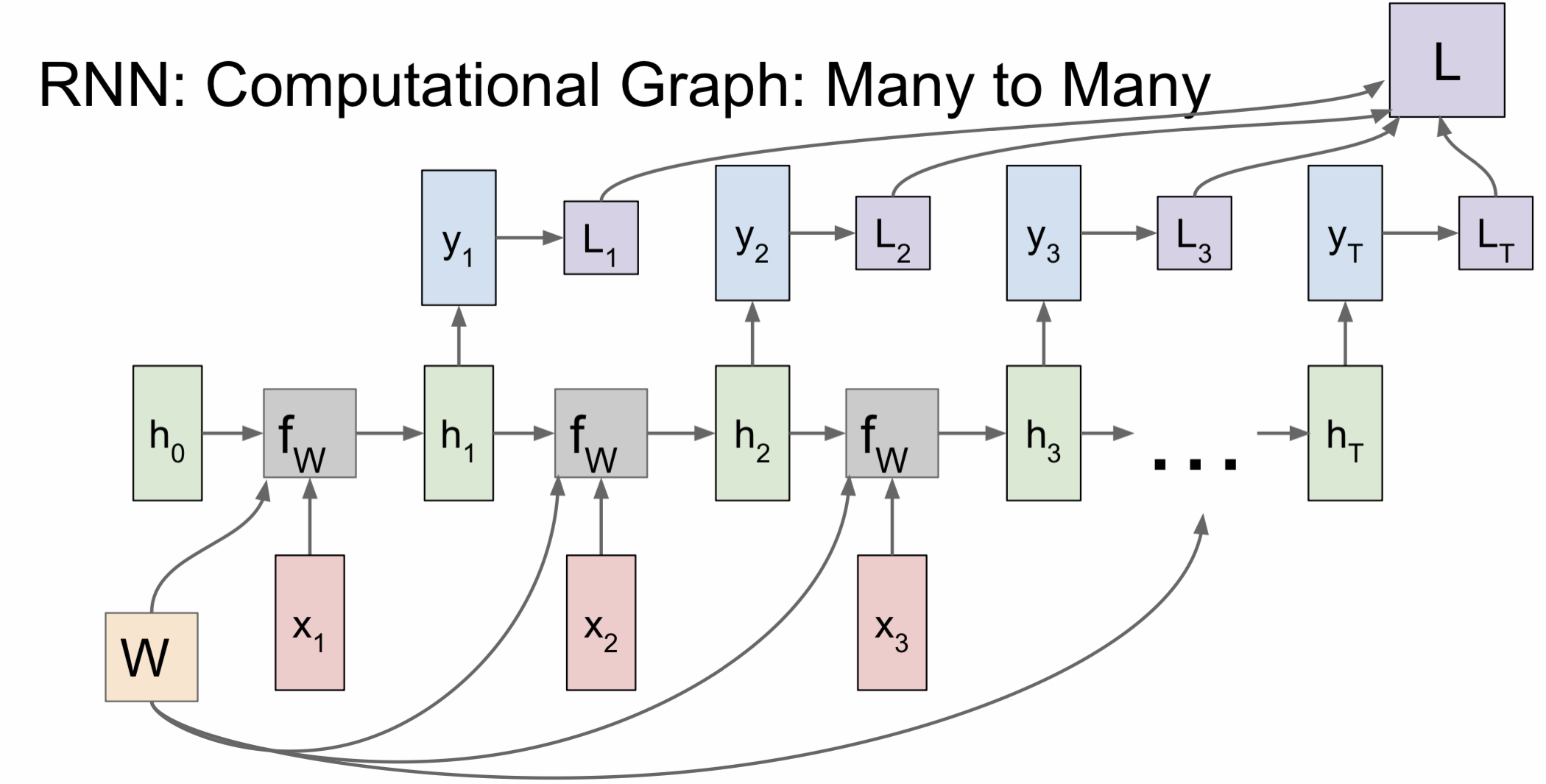
Many-to-many 모델을 살펴보면 hidden state가 반복적으로 사용됨에 따라 출력값도 연속적으로 나오는 것을 볼 수 있다. 이때 각 출력값 별로 loss를 계산해 최종 loss에 합산한다.
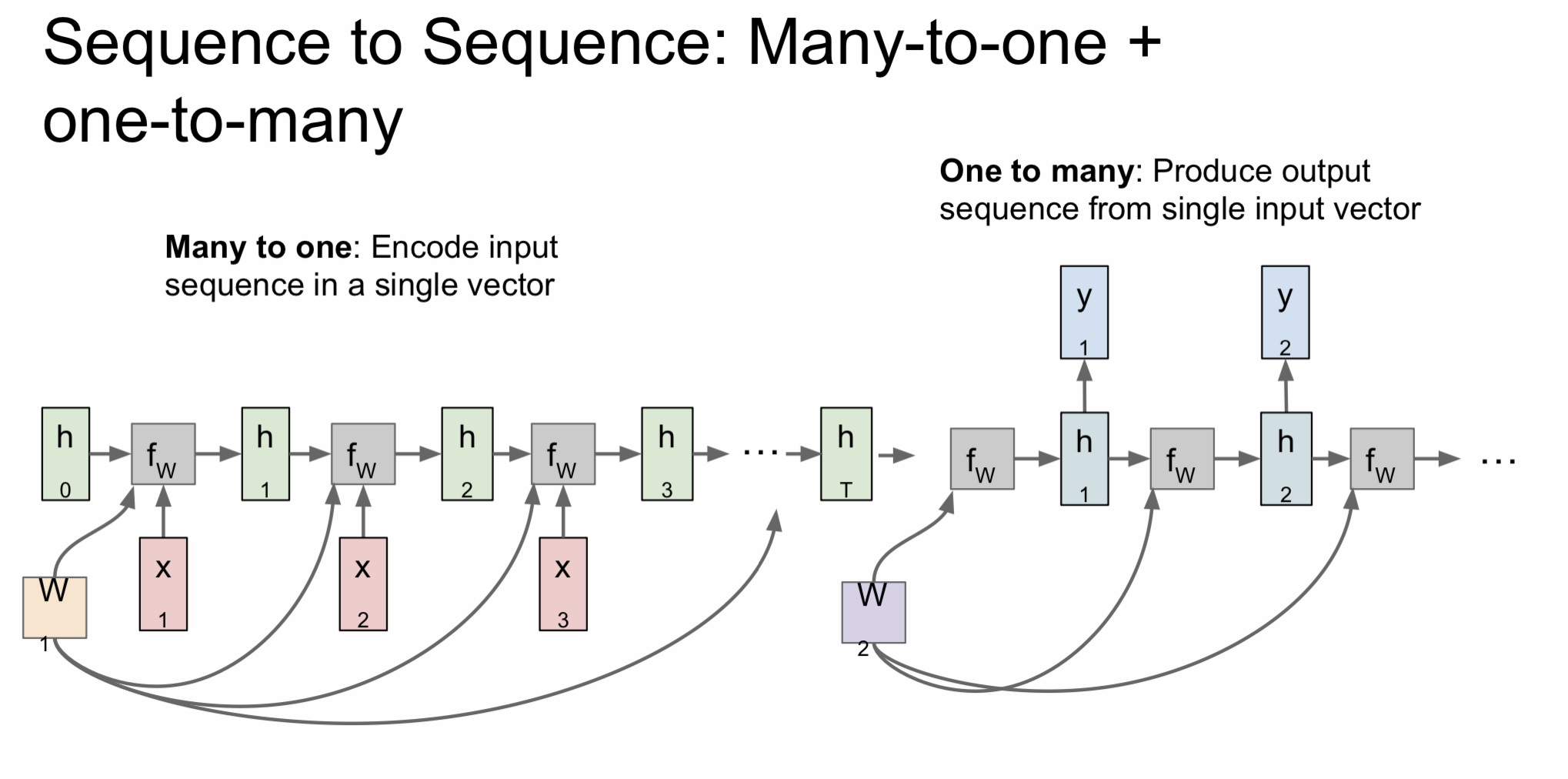
번역 모델에서 많이 활용하는 many-to-many 같은 경우에는 many-to-one과 one-to-many를 합쳐 놓은 것으로 볼 수 있는데 many-to-one에선 encode 하는 과정을 거친다면 one-to-many에선 반대로 decode 하는 과정을 거친다고 볼 수 있다.
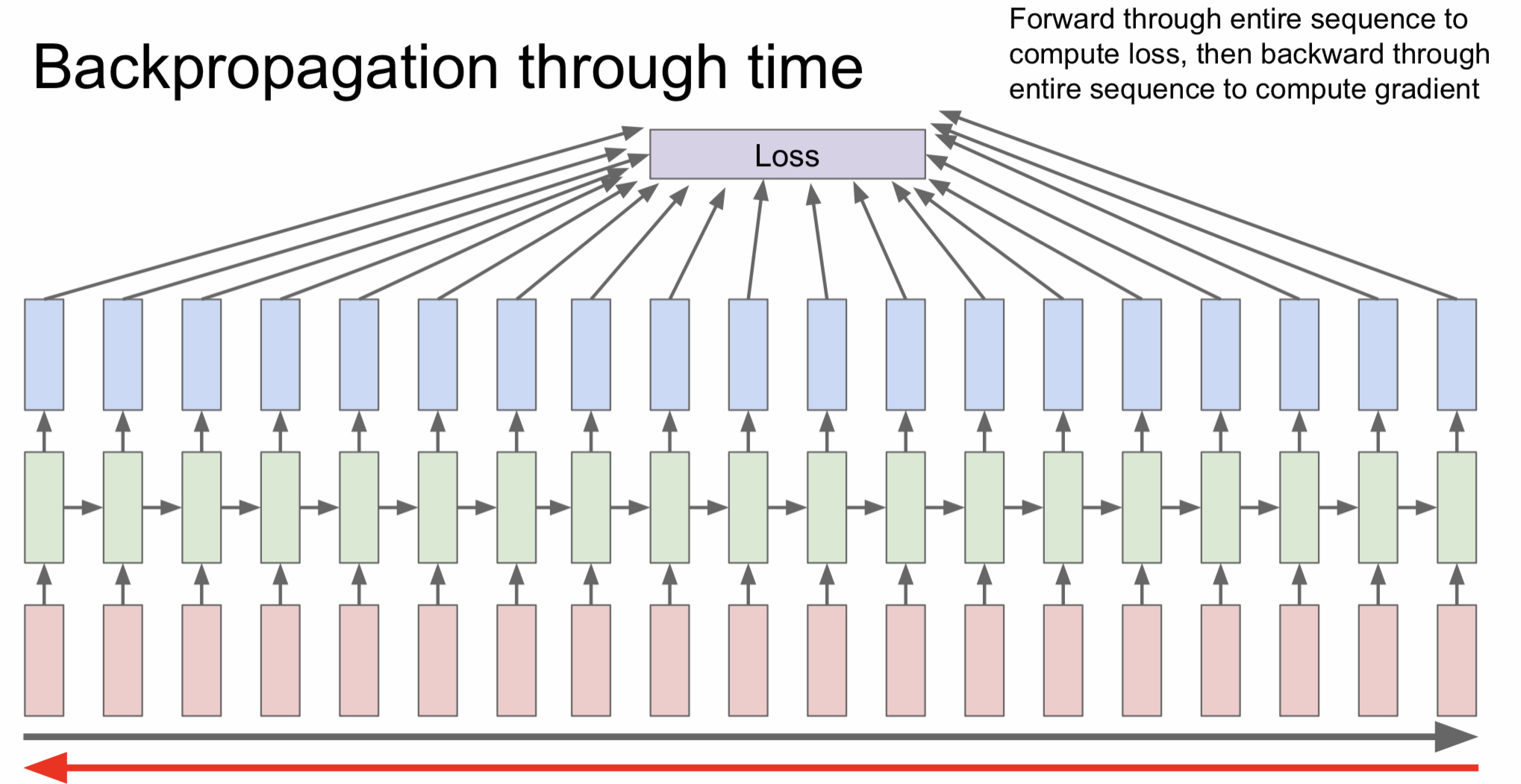
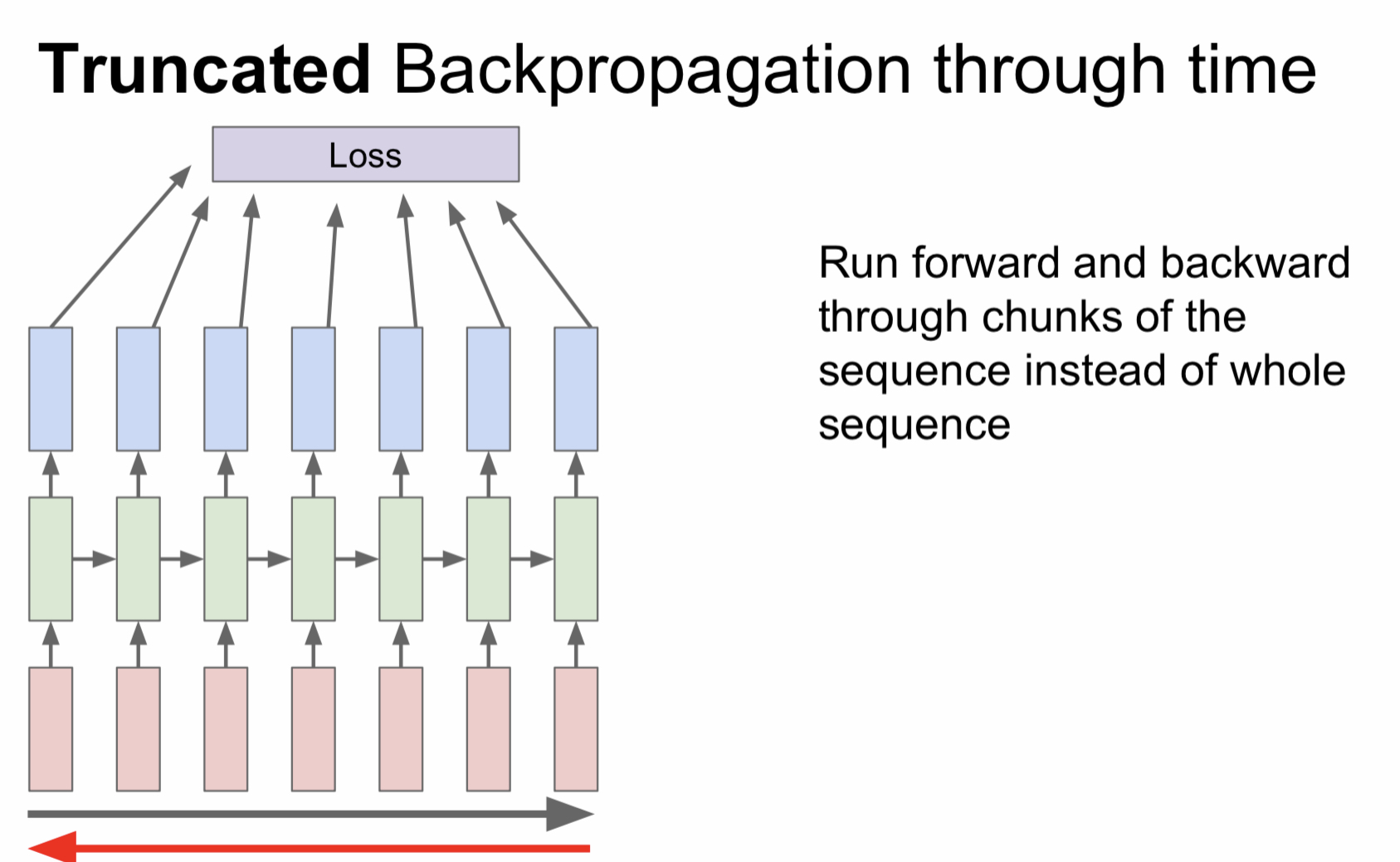
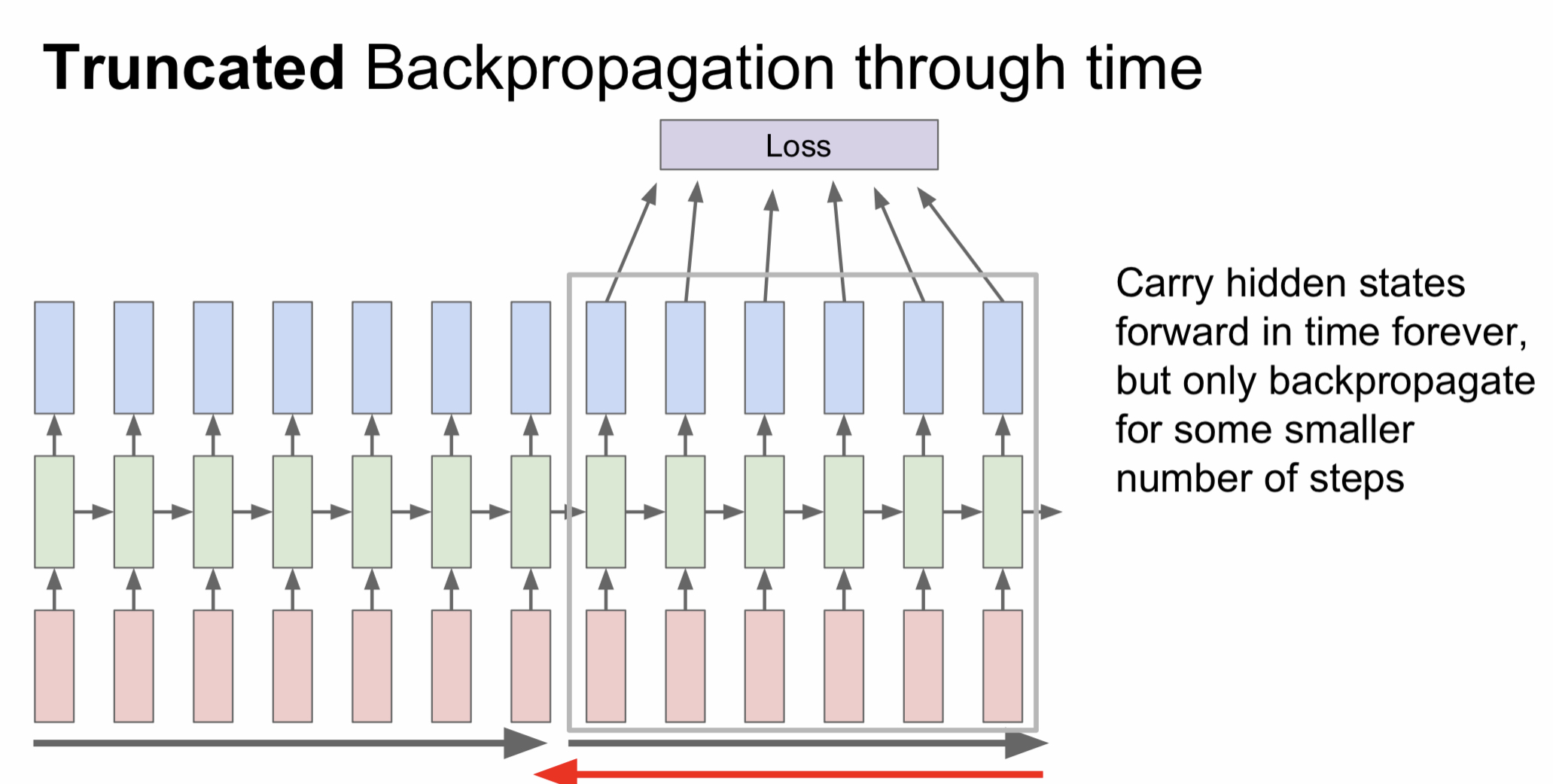
Truncated Backpropagation through time
RNN을 이용해서 학습을 진행한다고 했을 때 만약 책 한권을 입력값으로 넣는다면 backpropagation에 걸리는 시간이 매우매우 길 것이다. 따라서 이러한 경우엔 전체 문장을 잘게 쪼게서 각 단위별로 loss를 계산하는 방식을 사용한다.
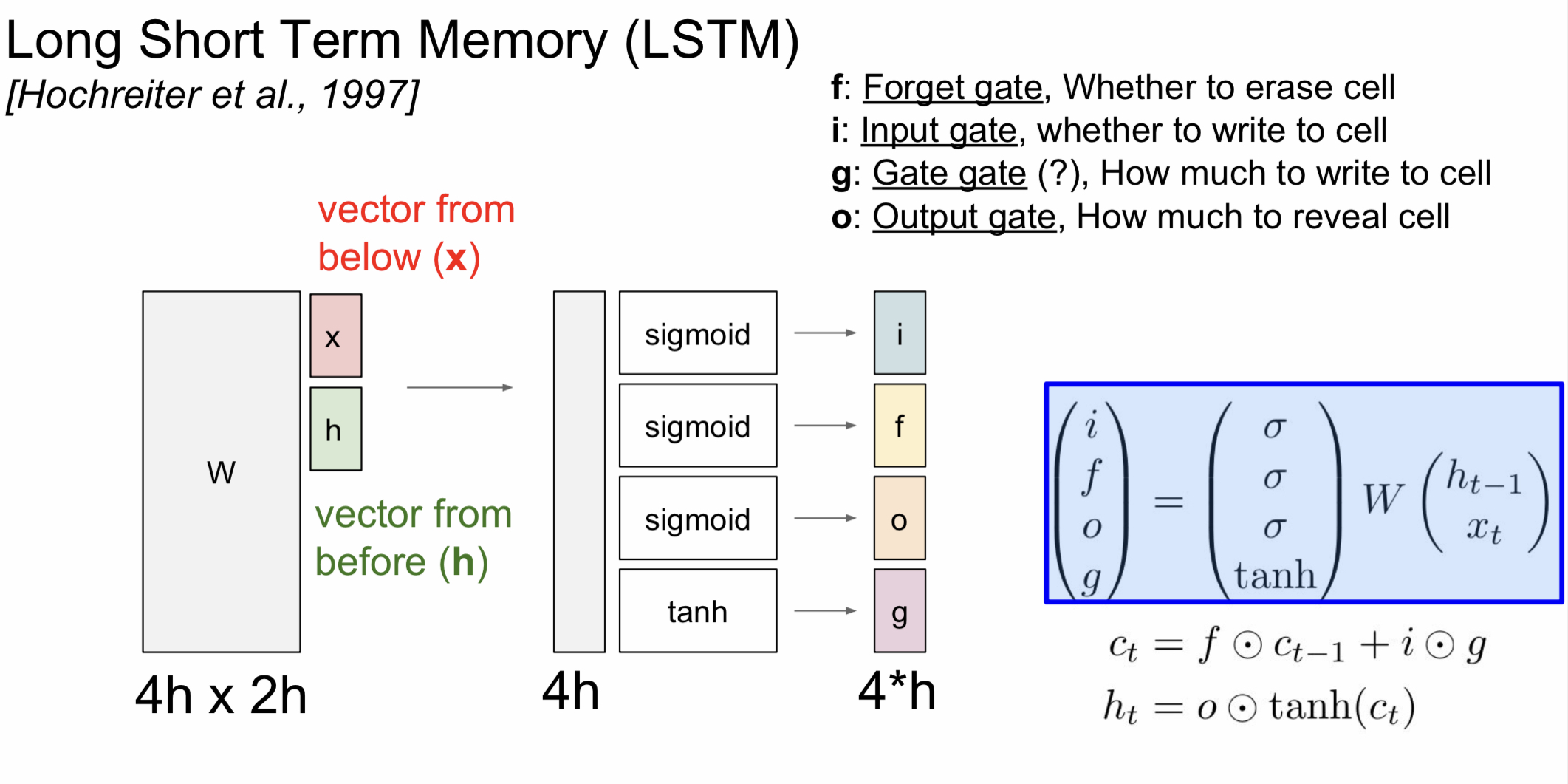
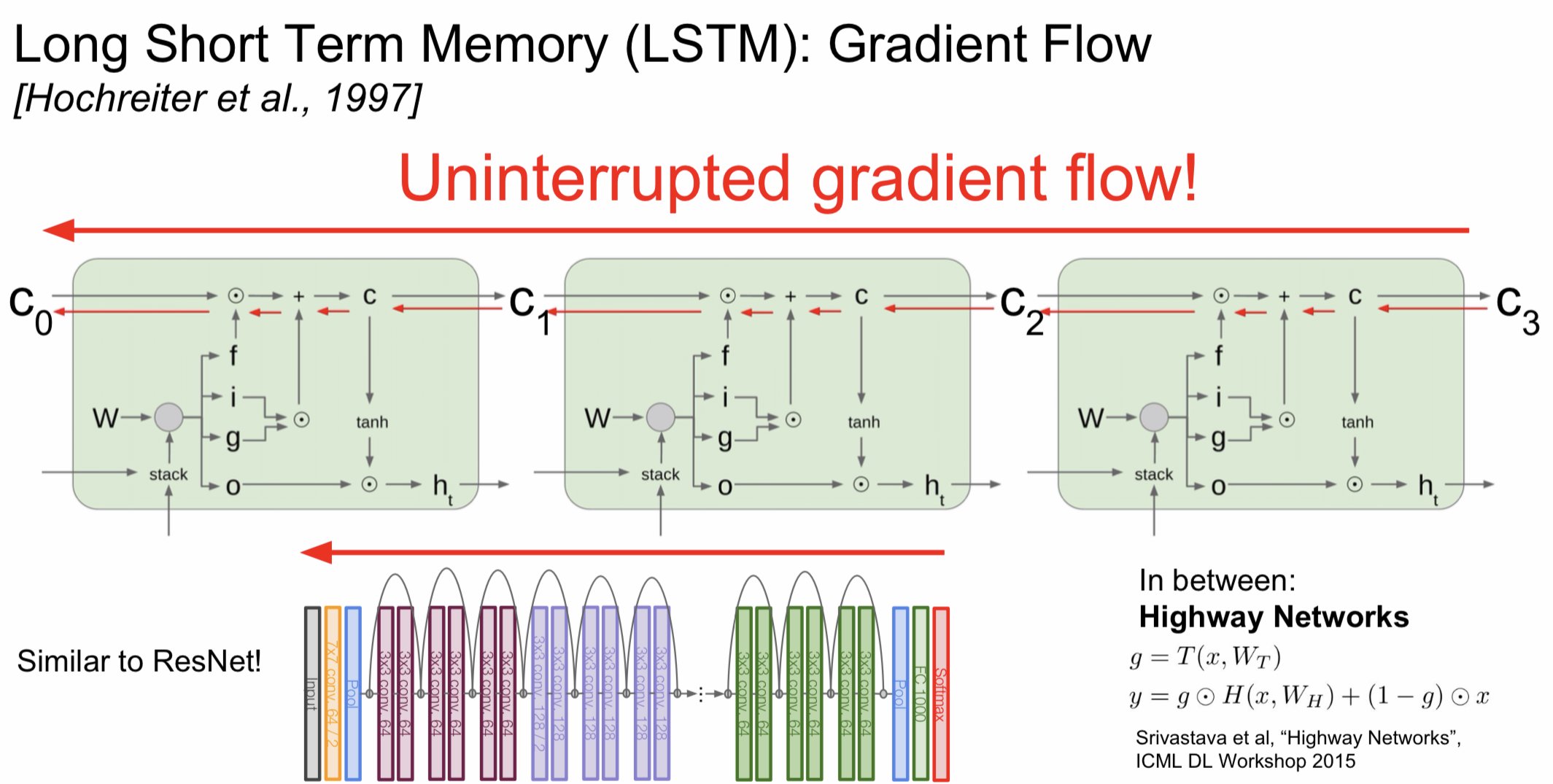
Long Short Term Memory (LSTM)
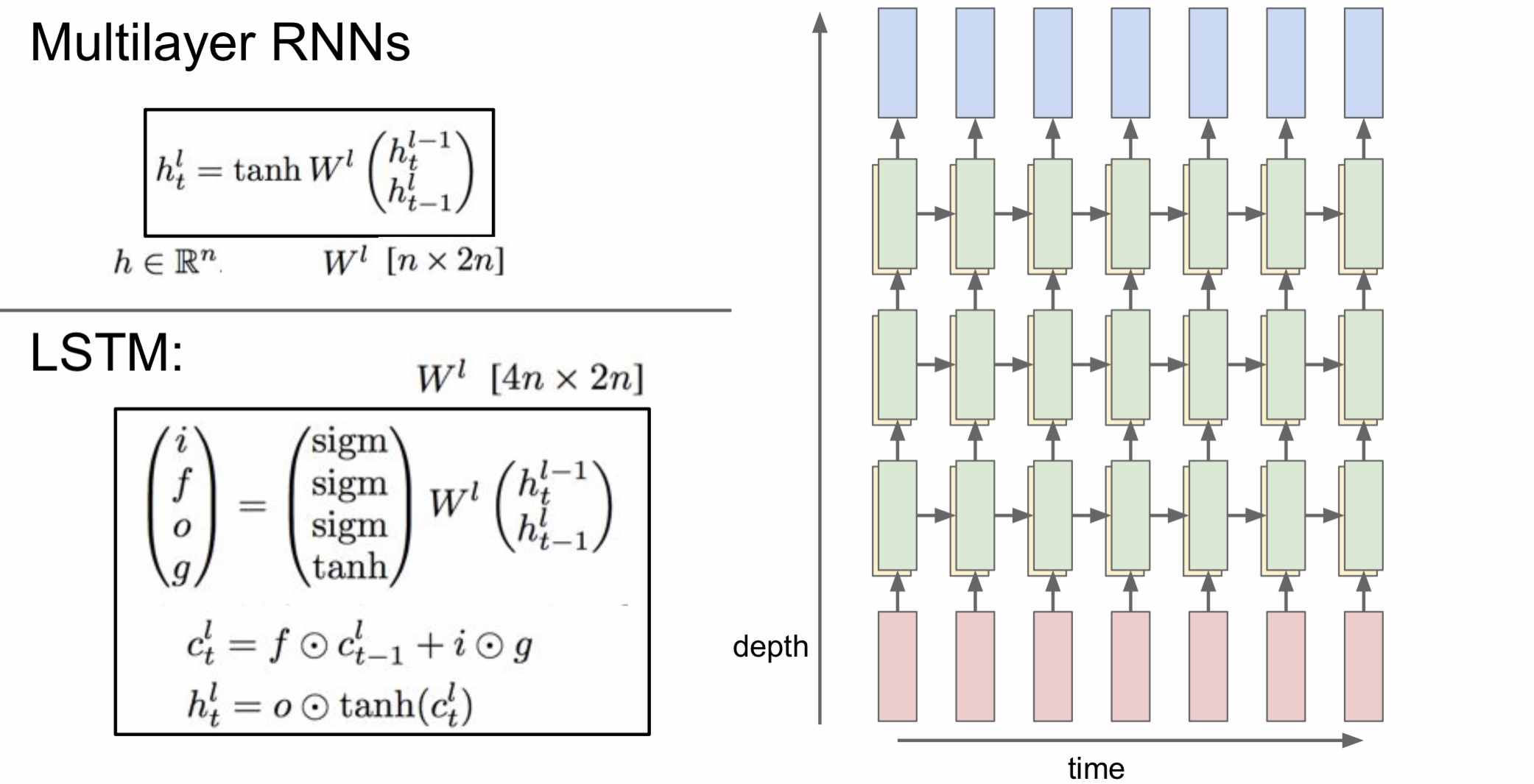
보통 더 좋은 성능을 내기 위해서 RNN을 여러층 쌓아서 사용하지만 모델이 커지면 거리가 멀리 떨어진 정보끼리 gradient가 전달이 잘 안 될 수도 있다.
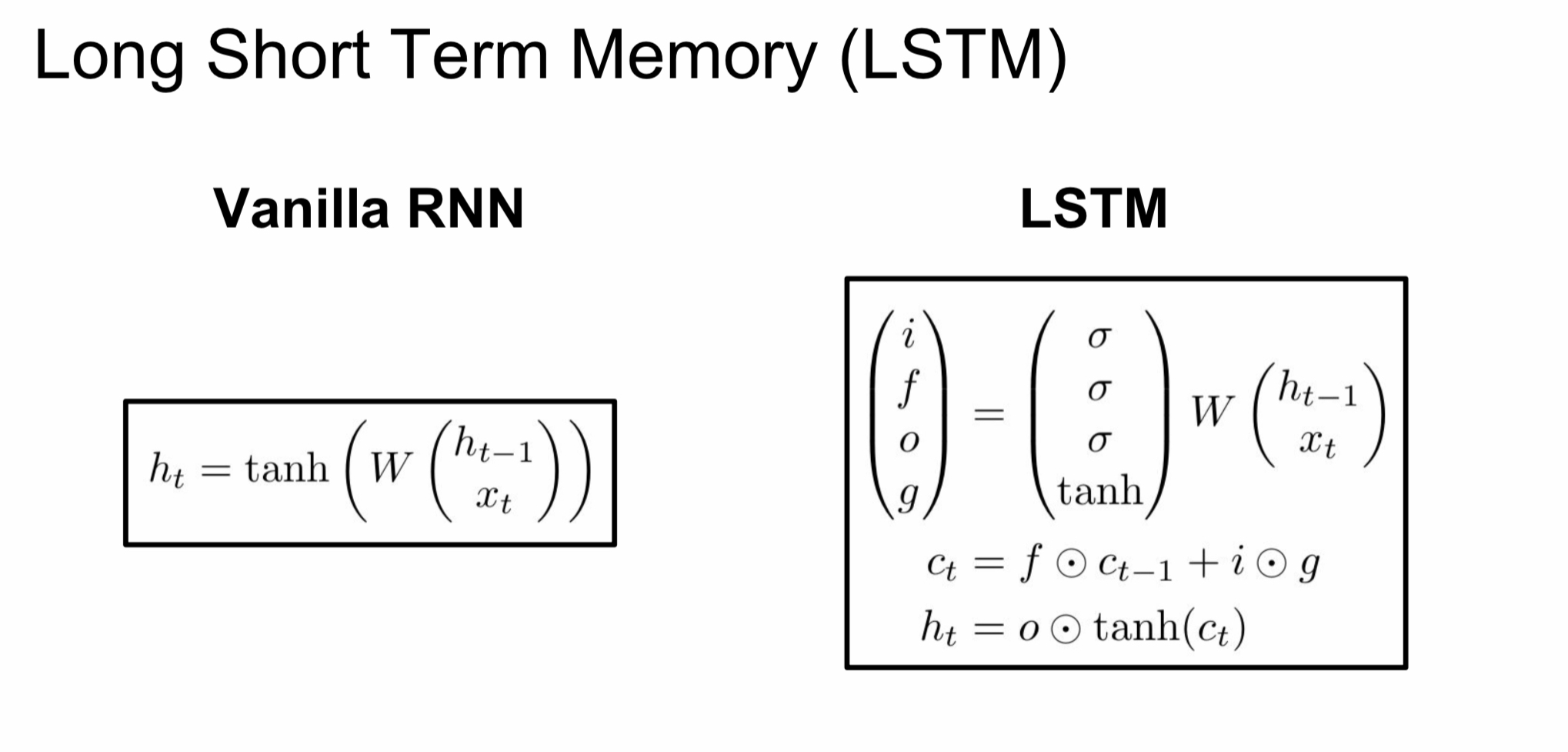
이러한 장기 의존성 문제를 해결하기 위해서 나온 것이 바로 LSTM이다.
참고자료
