
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
CNN Architectures - Case Studies
이번 시간에는 ILSVRC에서 우승을 한 CNN 모델들에 대한 case study를 진행하려 한다.
AlexNet
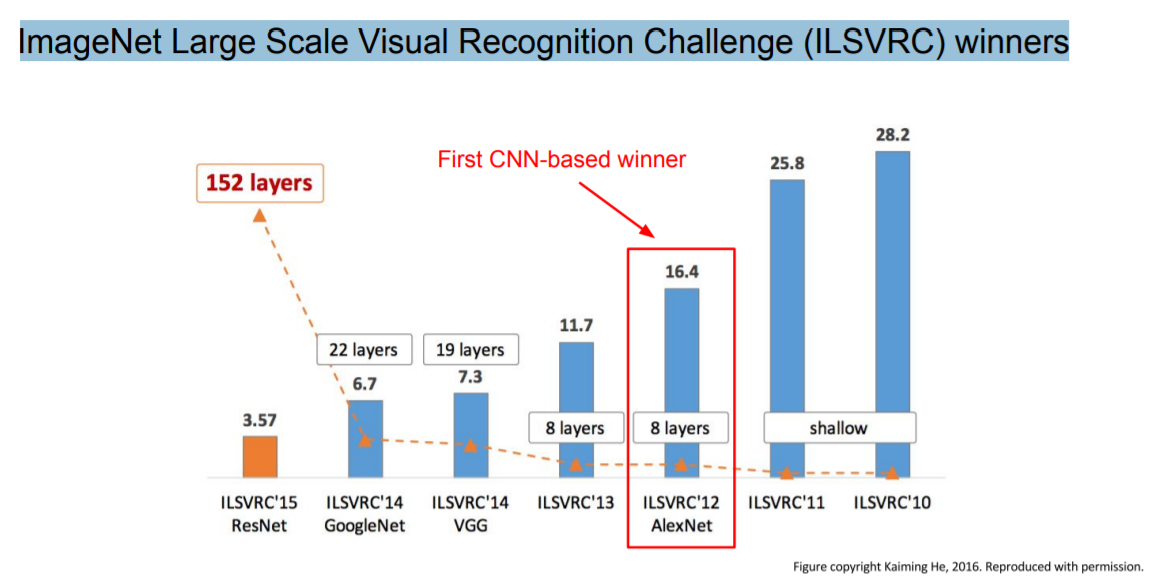
첫번째로 살펴볼 모델은 AlexNet이다. AlexNet은 처음으로 CNN 기반의 우승 모델이였는데 그 덕분에 획기적인 발전을 보여주었다.

VGGNet
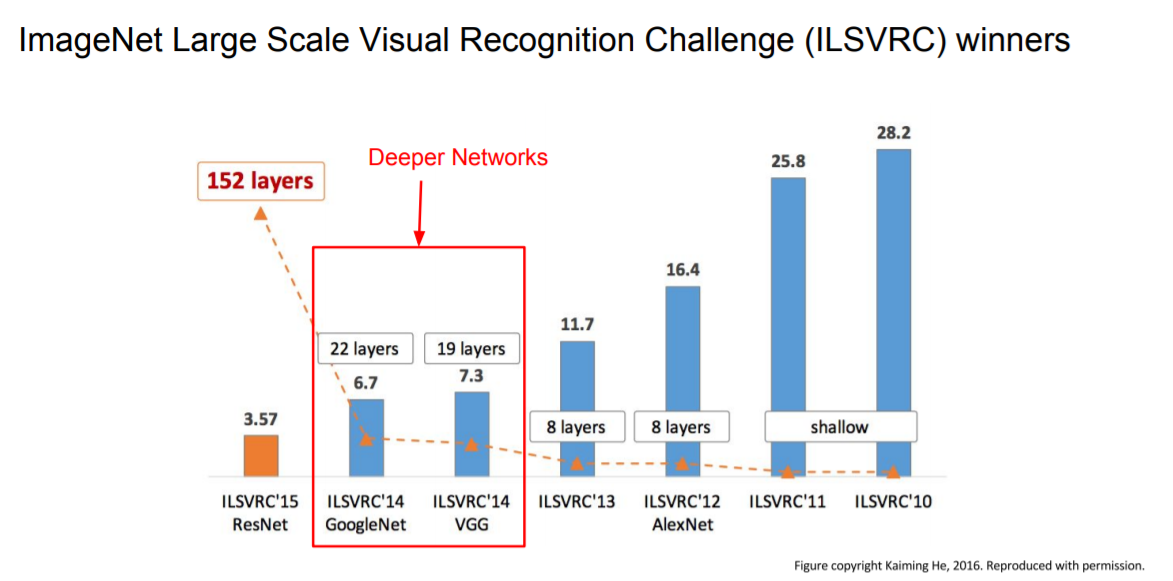
AlexNet보다 더 작은 필터와 더 깊은 networks를 사용해서 성능을 높였다.
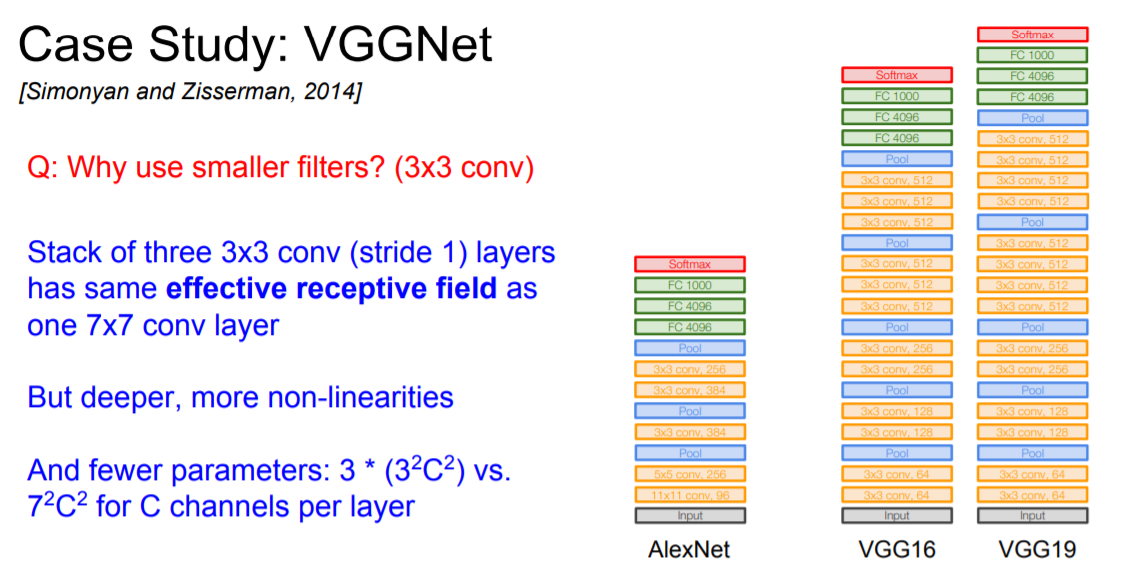
더 작은 filters를 사용한 이유는 filters를 여러 개 겹처서 사용하는 것과 filter를 하나 사용하는 것과 효과가 같은 데 계산량은 더 적어지기 때문에 더 작은 filters를 여러 개 겹쳐서 활용하게 된다.

Forward pass 시 한 image 당 96MB의 메모리가 필요하고 첫번째 FC layer의 parameter의 개수도 1억개 가까이 된다는 점에서 계산량이 너무 많다는 문제가 있다.
GoogLeNet
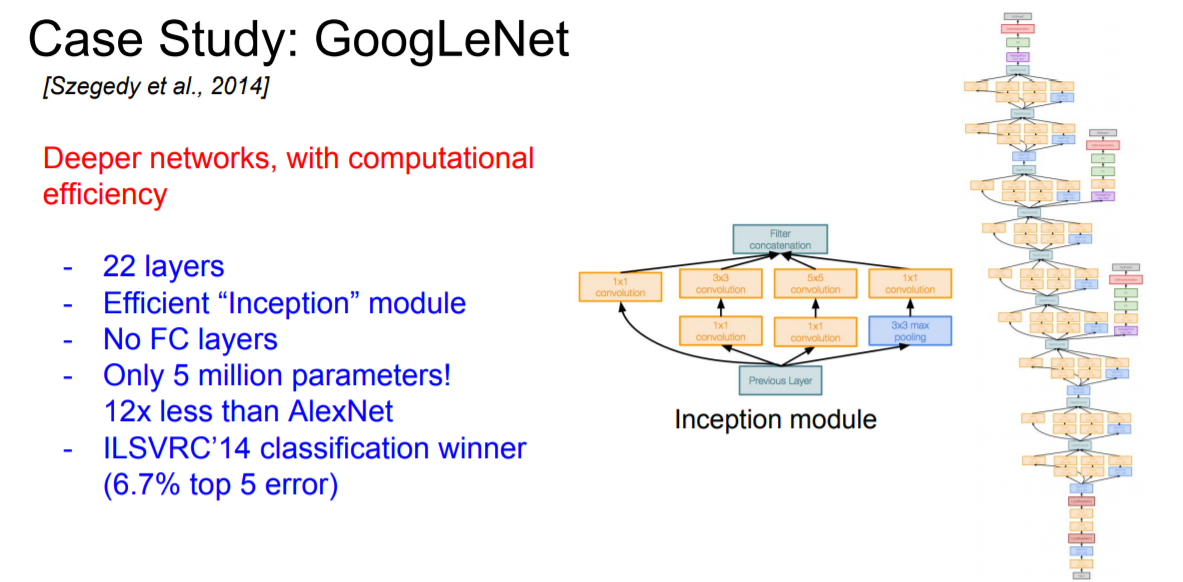
다음으로 볼 모델은 GoogLeNet이다. 22개나 되는 layer를 썼음에도 불구하고 parameter의 수는 그 전보다 많이 줄은 5M개 정도이다. 일반적으로 FC layer를 사용하면 parameter의 개수가 급격히 늘어나는데 GoogLeNet 같은 경우는 FC layer를 사용하지 않아 parameter의 수를 많이 줄일 수 있었다.
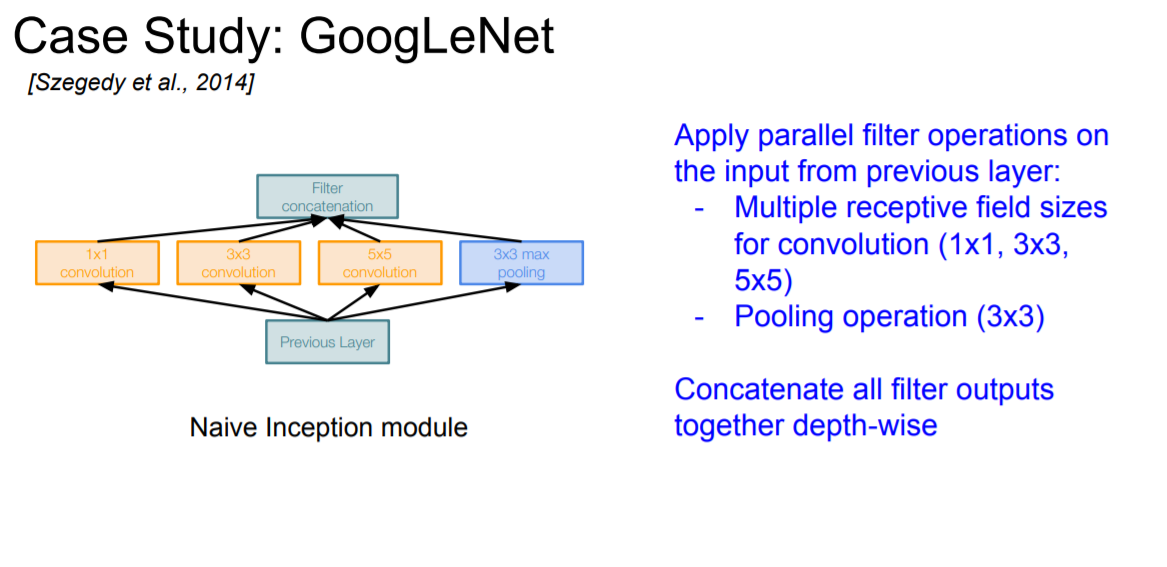
또한 network 안에 또다른 network를 집어 넣는 방식인 inception module 방식을 택했다. 위의 그림에서 볼 수 있듯이 4가지의 local informations을 병렬 처리하는 방식이다.
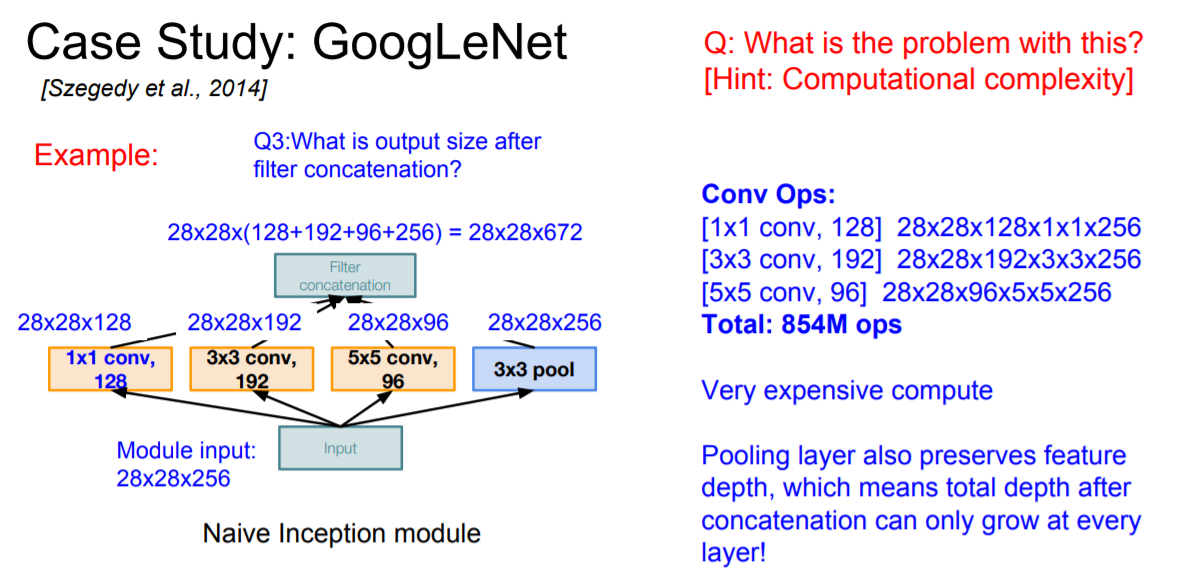
다만 이렇게 되면 계산량이 매우 많아진다는 단점이 있다.
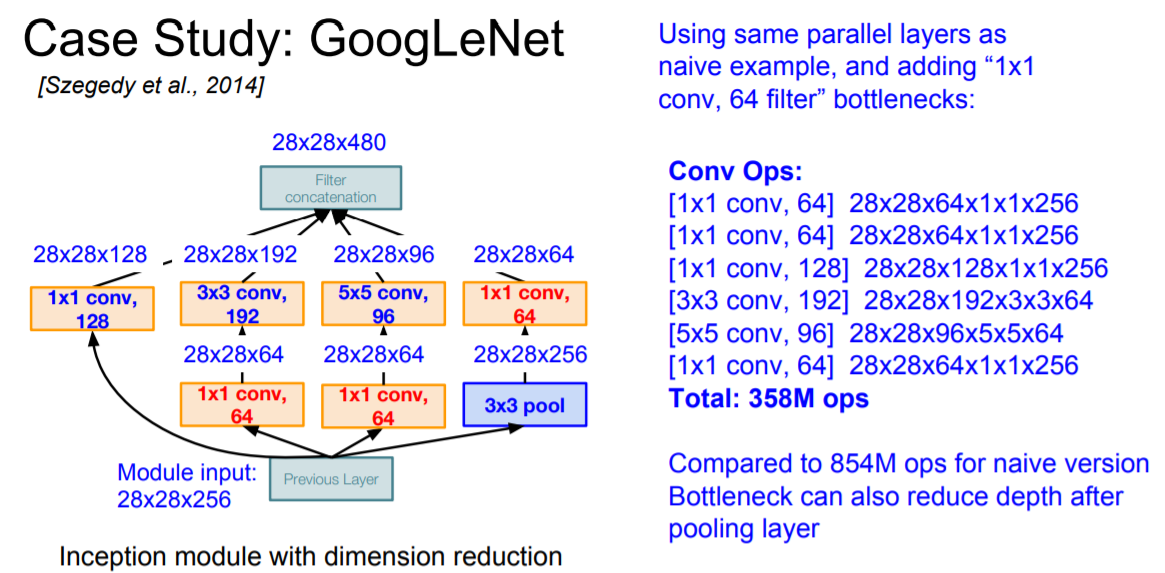
이를 해결하기 위해서 conv layer를 이용해 공간정보를 유지하되 깊이를 줄이는 방식으로 계산량을 줄이는 방법을 고안해냈다. 이러한 layer를 bottleneck layer라고 한다.
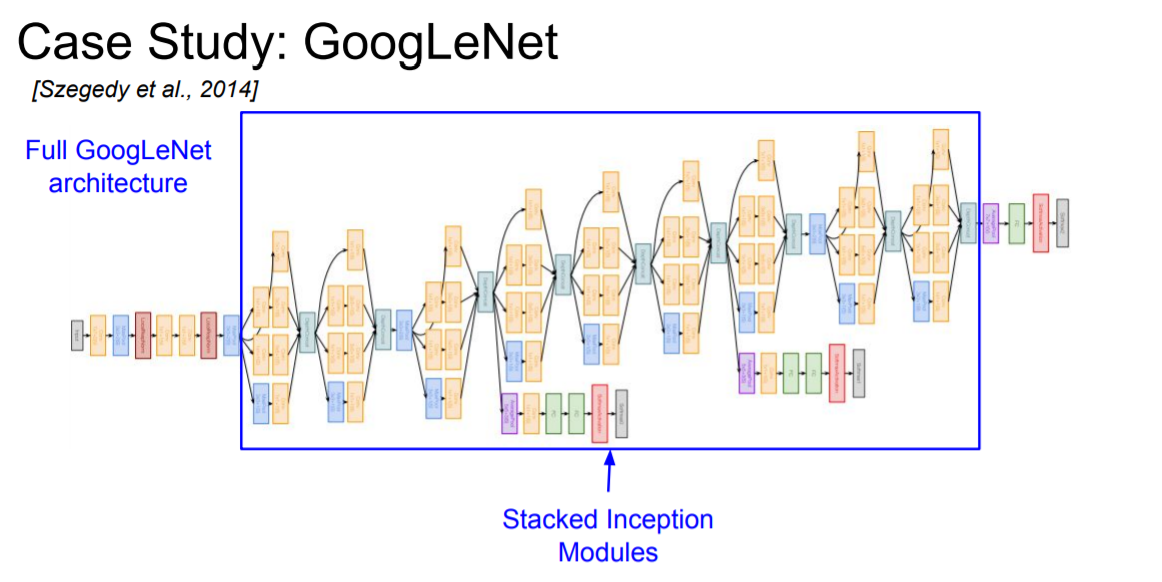
GoogLeNet은 처음엔 다른 CNN 모델과 마찬가지로 conv - pool - conv - pool 을 쌓아나가다가 중간부터 inception module을 쌓아나가고 마지막엔 global average pooling으로 마무리 한다.
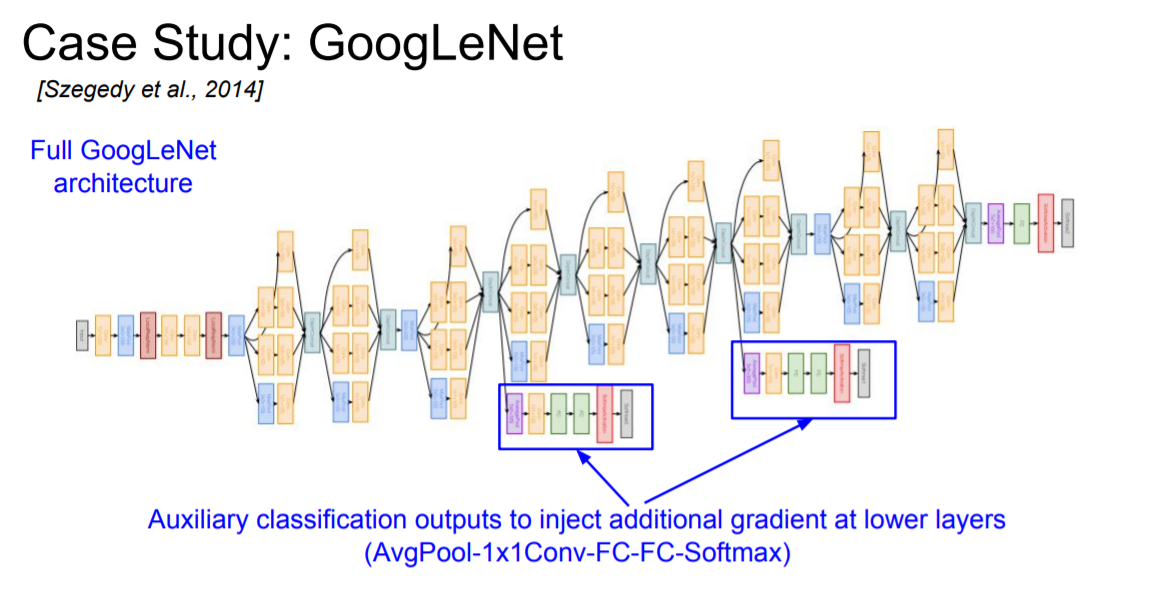
여기서 특이한 점은 위의 그림처럼 중간중간 튀어나온 layer들이 있는 것을 볼 수 있는데 이를 **auxiliary classification이라고 하며 중간 loss를 구하는 지점이라고 할 수 있다. 여기서부터 backpropagation이 또 흐른다고 생각할 수 있는데 그 이유는 network가 너무 깊기 때문에 중간에 gradient가 사라질 수 있는 가능성을 최소화 하기 위함이다.
ResNet
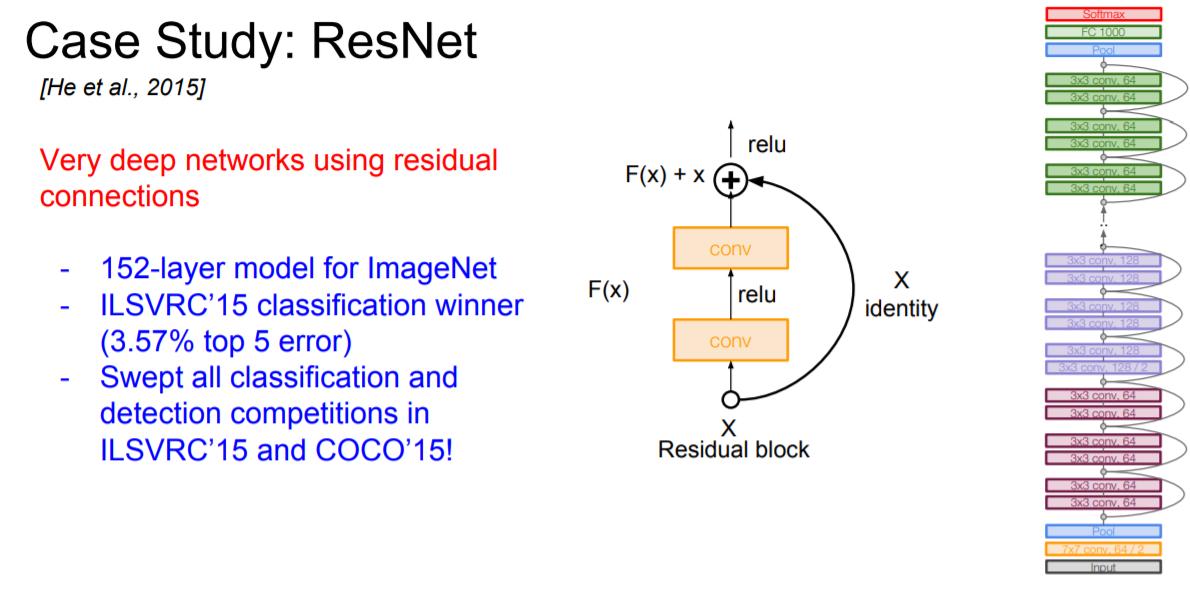
ResNet은 152개의 layer들을 가지고 있는 매우 깊은 network이다. Layer가 깊으면 더 좋은 성능을 가질 것 같다고 생각을 할 수 있지만 너무 깊으면 오히려 backpropagation을 진행할 때 gradient가 끝까지 전달이 안 되는 문제점이 발생하기 때문에 좋은 결과를 내지 못 한다.
따라서 ResNet에서는 이러한 문제점을 해결하기 위해 residual connections이란 방식을 활용한다. 이는 몇 개의 layer 뒤로 입력값을 그대로 보내주는 방식인데 이를 통해서 위의 문제점을 해결할 수 있다고 한다. (아직 이해가 완벽히 되질 않아서 조금 더 공부를 한 뒤에 다시 적어보겠습니다...)
참고자료
