
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
Convolutional Neural
1강에서 computer vision에 대한 역사에 대해서 살펴봤을 때 과거에는 이미지를 인식하기 위해서 특징값을 추출하는 것에 주목했다고 배웠다. 하지만 이러한 방식은 같은 것을 가리키는 이미지라도 공간 상의 변형이 생기면 변형된 이미지에 대한 또 다른 모델을 만들어야 한다는 단점이 있었다. 이러한 문제를 해결하기 위해서 Convolutional Neural Networks이 등장하게 되었다.
Convolution Layer
Convolutional Neural Networks이 computer vision 분야에서 각광을 받는 이유는 특징을 직접 추출하지 않고 스스로 학습하기 때문이다. 또한 공간 정보를 유지한 채 학습이 진행된다는 특징이 있다.
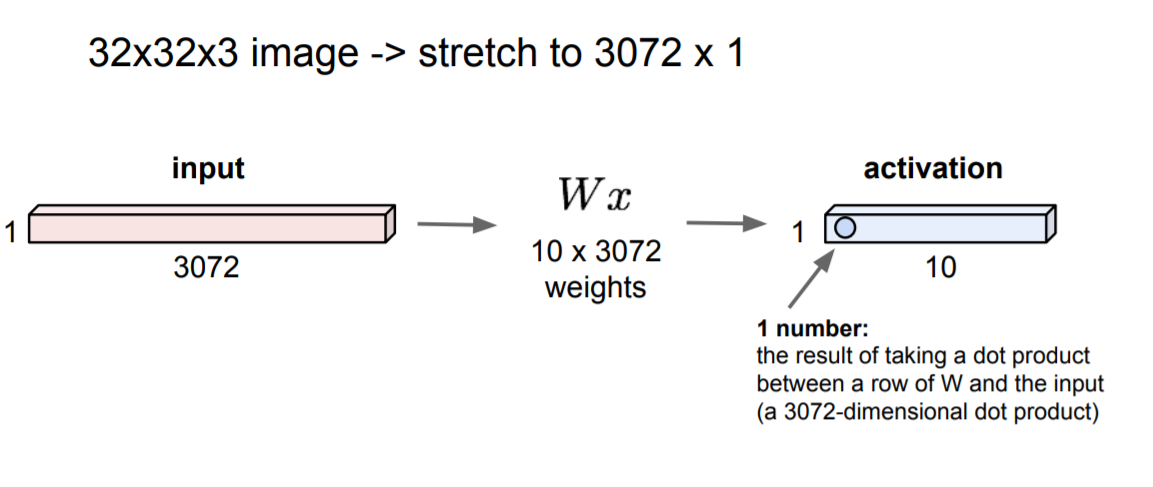
기존에는 위의 이미지와 같이 input image를 길게 늘여서 계산했기 때문에 공간 정보가 유지되지 않았으며 이렇게 계산된 값은 하나의 특징만을 나타내게 되었다.
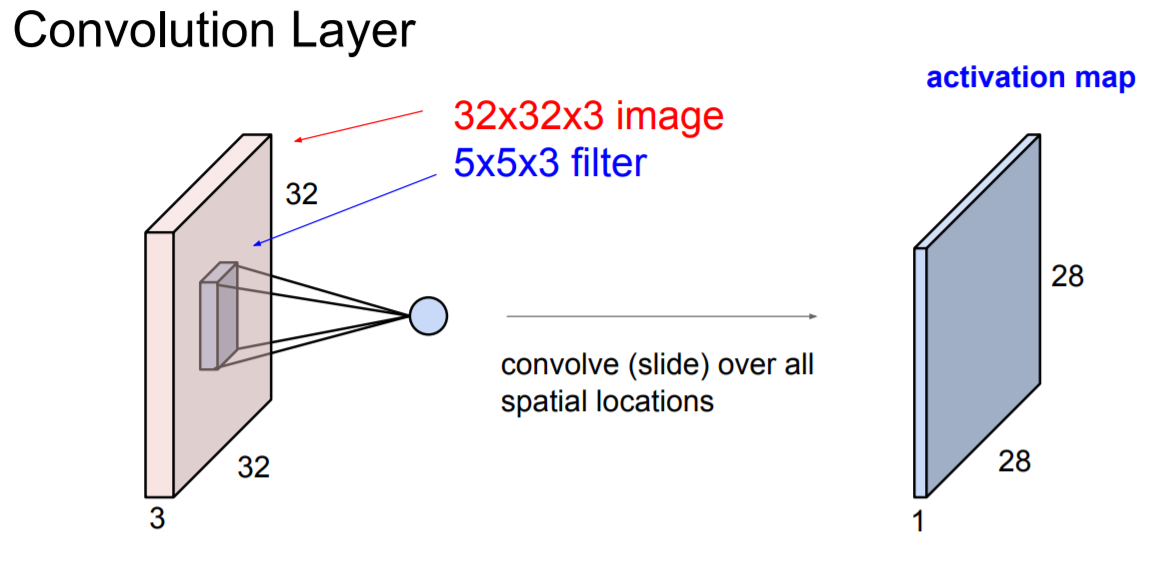
하지만 CNN에서는 convolution layer를 도입해 공간 정보를 유지한 채 convolution을 진행한다. 여기서 convolution이란 합성곱을 의미하는데 처음에는 이 말이 잘 와닿지가 않을 것이다. Convolution을 이해하기 위해선 우선 위의 그림 속에 있는 filter에 대해서 집중해보자. 이미지보다 작은 filter를 정의한 뒤 이미지의 좌측 상단부터 차례대로 dot product를 진행한다. Dot product를 통해 나온 하나의 값은 activation map의 하나의 값을 구성한다. 이 filter가 옆으로 정해진 칸수만큼 이동하면서 차례대로 dot product를 진행하여 activaiton map을 완성시키는 것이 바로 convolution layer이다.
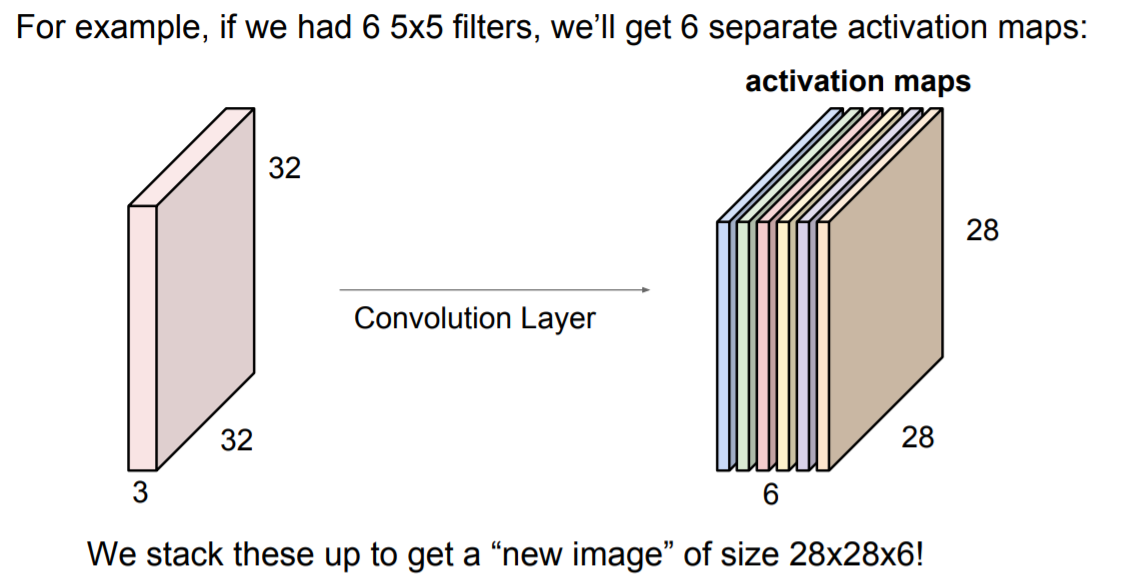
Filter의 개수만큼 activation map이 형성되고 convolution layer를 쌓아나가면서 CNN을 완성시킨다.
Preserve Spatial Structure
위에서 CNN은 공간 정보를 유지하면서 진행된다고 했는데 이는 filter가 한번 dot product를 진행할 때 filter가 속한 공간에 있는 특징을 추출하여 값을 내보내고, 이러한 방식으로 이미지의 모든 구역을 다 훑고 난 뒤 생성된 activation map은 각 공간에 대한 특징값들의 모임으로 생각하면 된다. 따라서 이미지 전체의 특징을 추출하는 것이 아닌 공간 별 특징을 추출하여 표현하기 때문에 공간 정보를 유지한다고 하는 것이다.
Stride
Filter가 합성곱을 진행할 때 몇 칸 씩 움직일 지 그 기준을 정하는 값을 바로 stride라고 한다. 아래 그림은 stride가 1인 상황이다.
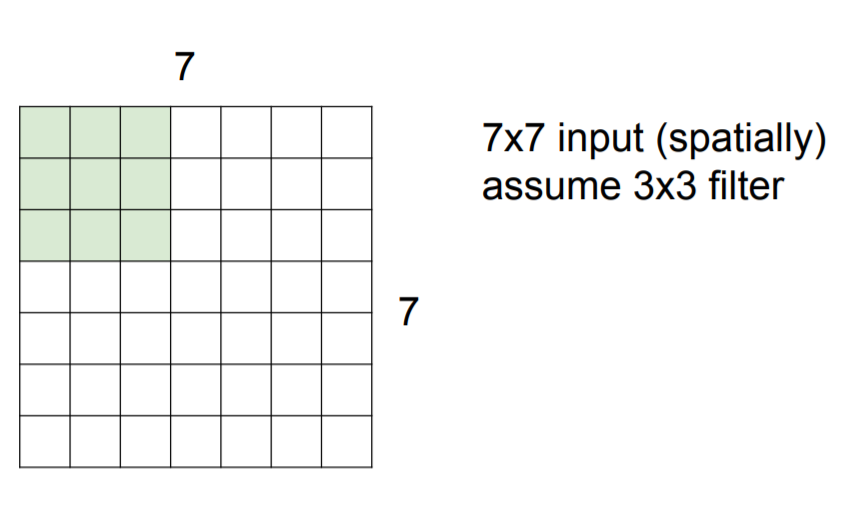
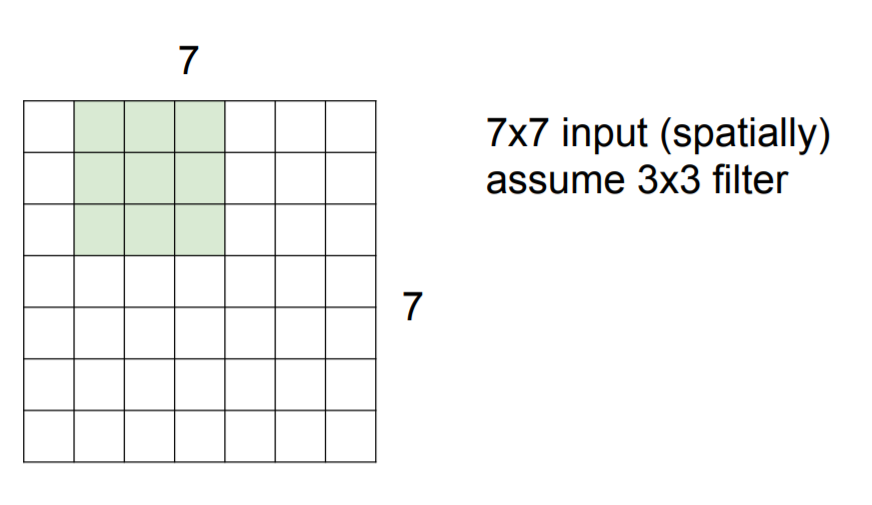
위에서 볼 수 있듯이 stride의 값만큼 칸을 옮기며 합성곱이 진행되는 것을 볼 수 있다.
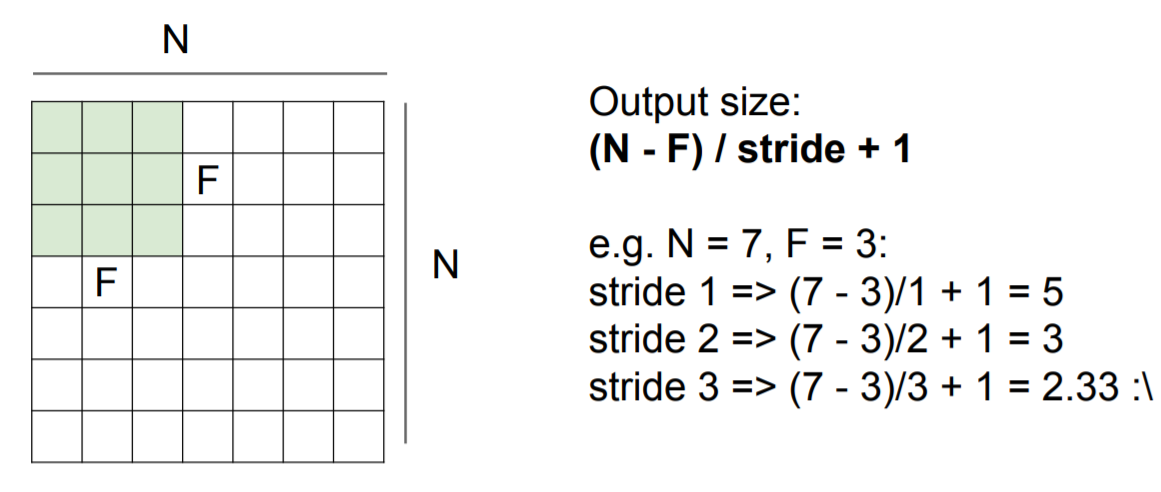
Stride 값에 따라 output size는 달라지며, stride 값이 커질수록 output size는 작아진다.
Zero Pad the Border
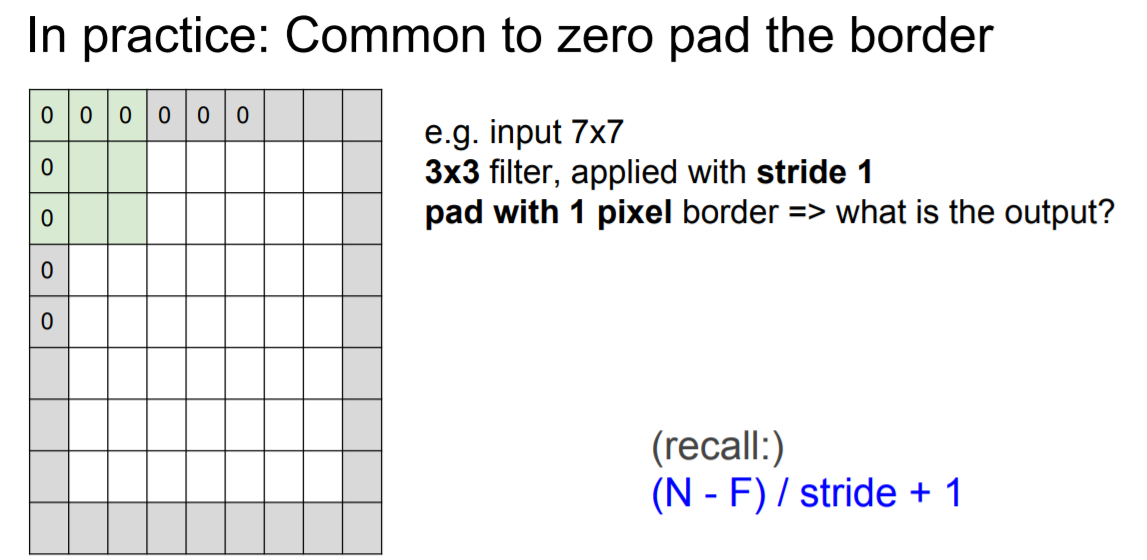
합성곱을 진행하고 나면 output size가 원래보다 작아지는 문제가 발생한다. 따라서 이를 방지하기 위해서 input image를 0으로 둘러싼 뒤에 합성곱을 진행하게 된다.
Pooling Layer
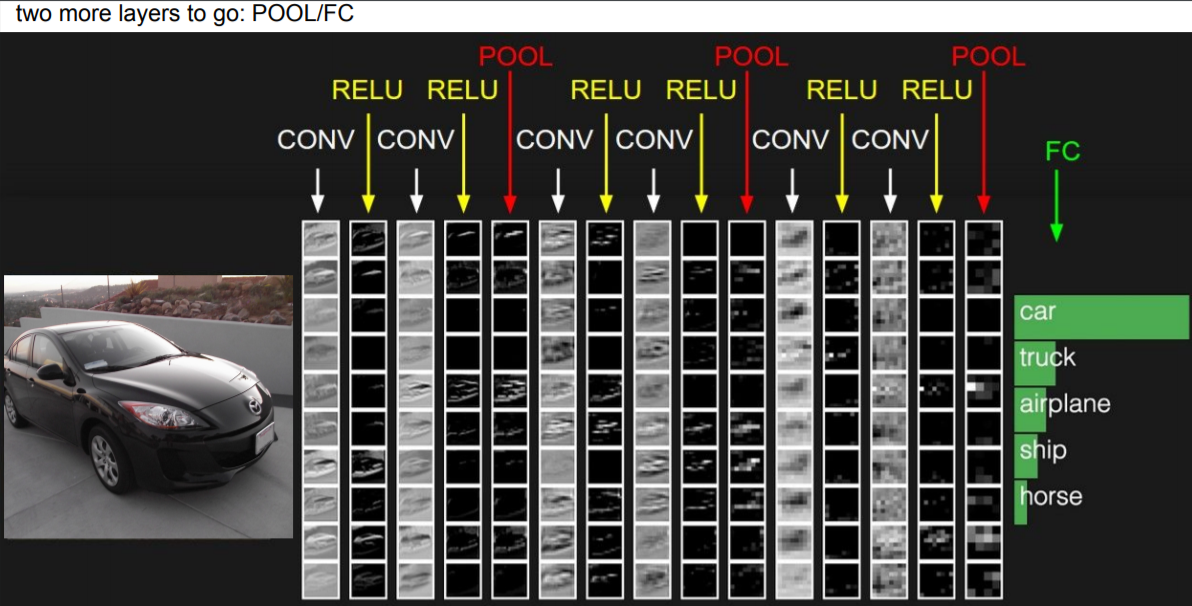
CNN은 단순히 convolution layer로만 이뤄진 것이 아니라 convolution layer, ReLU, 그리고 Pooling layer가 한 세트로 이뤄져 있으며 이것들을 차례로 적층시킨 후 마지막은 fully connected layer로 구성이 되어있다. 그렇다면 pooling layer 무엇일까?
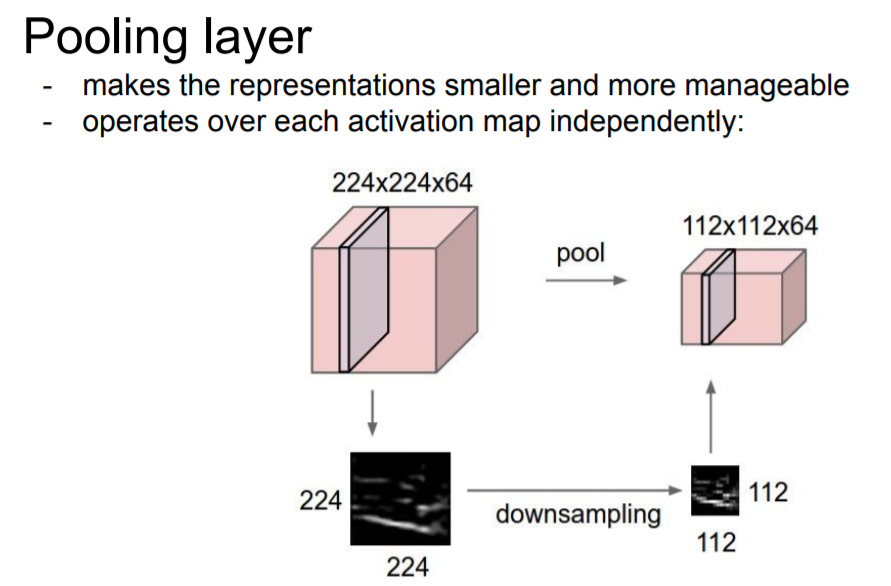
Pooling layer란 추출한 특징은 최대한 유지한 채 이미지의 크기를 줄여주기 위한 장치이다. 이미지의 크기를 줄이는 이유는 좀 더 다루기 쉽게하기 위함인데 downsampling이라고도 불린다.
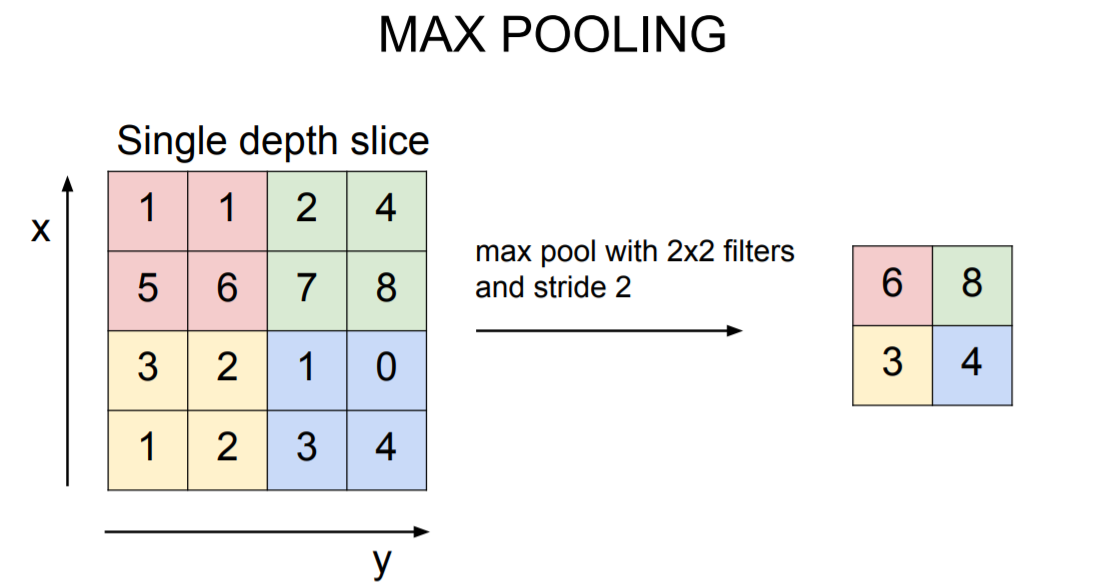
가장 많이 사용되는 방식은 Max Pooling 방식이다. Pooling layer에서 사용할 filter의 크기와 stride 값을 정한 뒤 filter가 합성될 때 이전처럼 dot product를 진행하는 것이 아니라 max 값만 산출하는 것이다. 이렇게 하면 가장 큰 특징을 살리면서 이미지의 크기를 줄여나갈 수 있다.
Fully Connected Layer

마지막으로 fully connected layer에 집어넣어 각 class 별로 예측치를 산출하면 CNN이 완성이 된다.
참고자료
