
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
1. Fancier Optimization
Optimization : Problems with SGD
앞서 우리는 optimization의 한 방법으로 SGD를 배웠다. 가장 기본적인 방법이지만 실무에서 쓰이기엔 여러 문제점이 존재한다.
1. 학습속도가 느리다.
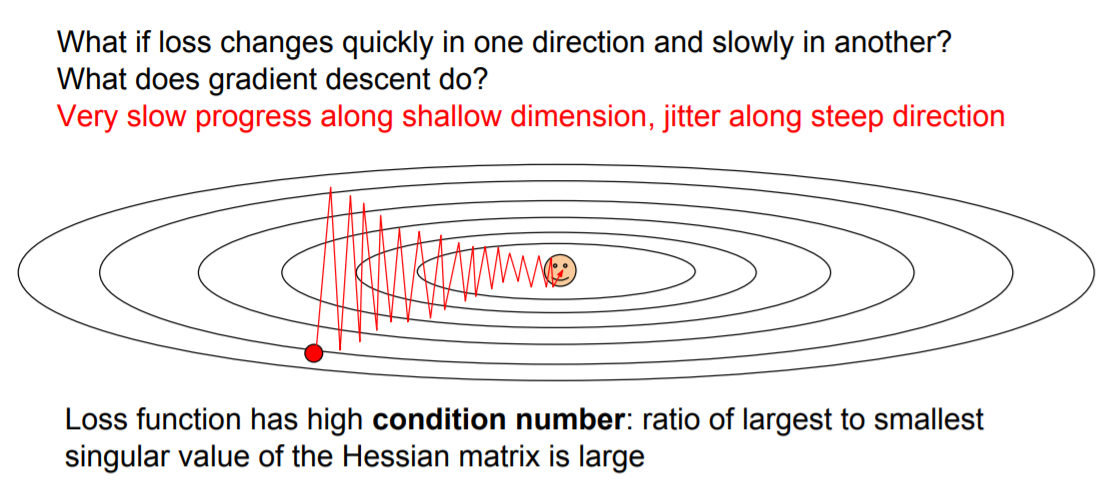
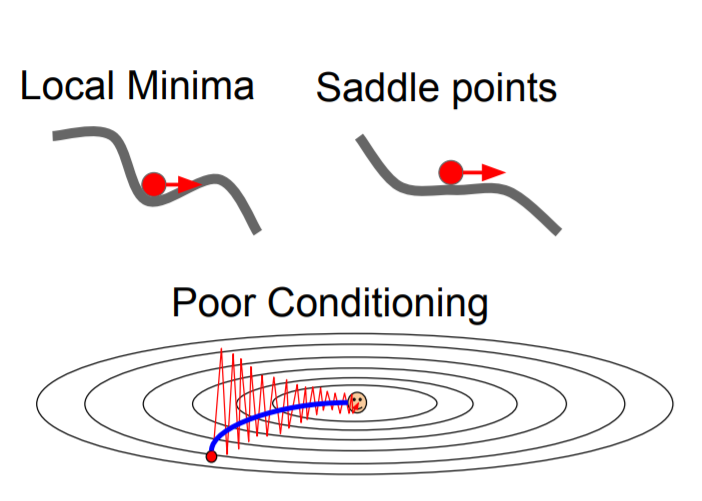
위의 그림에 나와있는 loss function의 등고선 그래프를 보면 세로축은 경사가 급한 반면에 가로축은 경사가 완만하다. 따라서 학습이 진행될 때 경사가 완만한 가로축 방향으로는 작게, 경사가 급한 세로축 방향으로는 크게 움직이기에 지그재그로 움직이게 되는 걸 볼 수 있다.
Neural networks는 parameter의 개수가 매우 많기에 이 모든 parameter들이 위의 그림에서와 같이 서로 다른 방향으로 움직이며 얽히게 되면 학습속도가 매우 느리게 될 수 밖에 없다.
2. Global minima가 아닌 local minima 또는 saddle point에 수렴할 가능성이 존재한다.
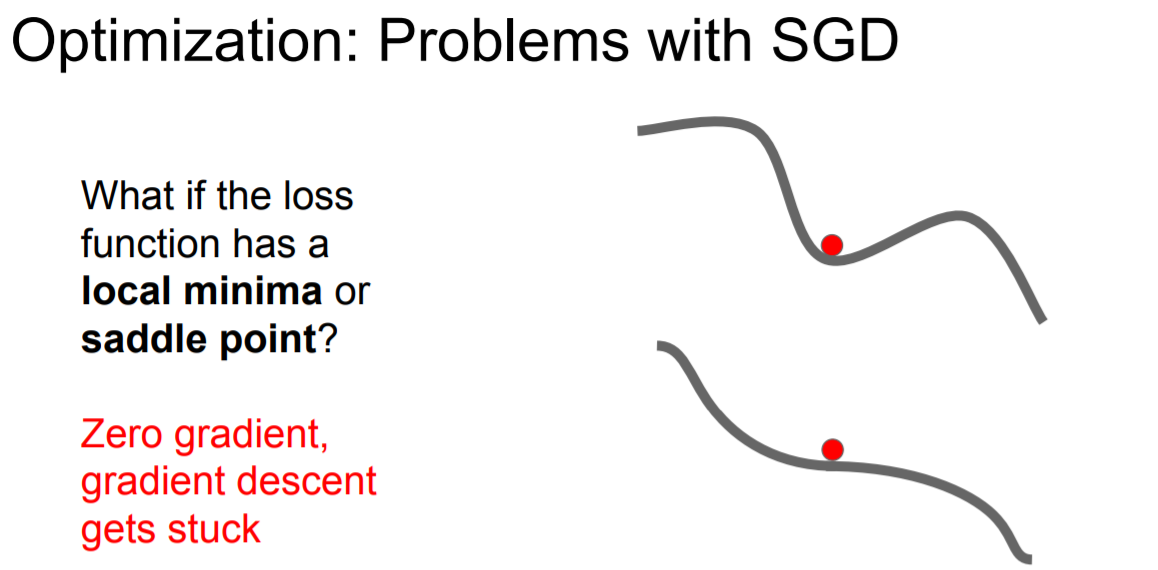
Local minima나 saddle point는 gradient 값이 0이다. 따라서 SGD를 진행하다가 local minima나 saddle point를 만나면 더이상 학습이 진행되지 않는 문제가 발생한다.
Saddle point 근처로 다가갈 때도 gradient가 0에 매우 가까워지기에 학습이 더디게 일어나는 문제가 발생한다. 고차원에서 이러한 saddle point 문제가 더 일반적으로 발생한다.
3. Minibatch를 사용하기에 매 step마다 정확한 gradient 값을 담을 수 없다.
이러한 SGD의 문제점을 해결하기 위해 여러 다른 알고리즘들이 개발되었다.
1) SGD + Momentum

말그대로 관성을 추가해 local minima나 saddle point에서 벗어날 수 있도록 한다.
2) Nesterov Momentum
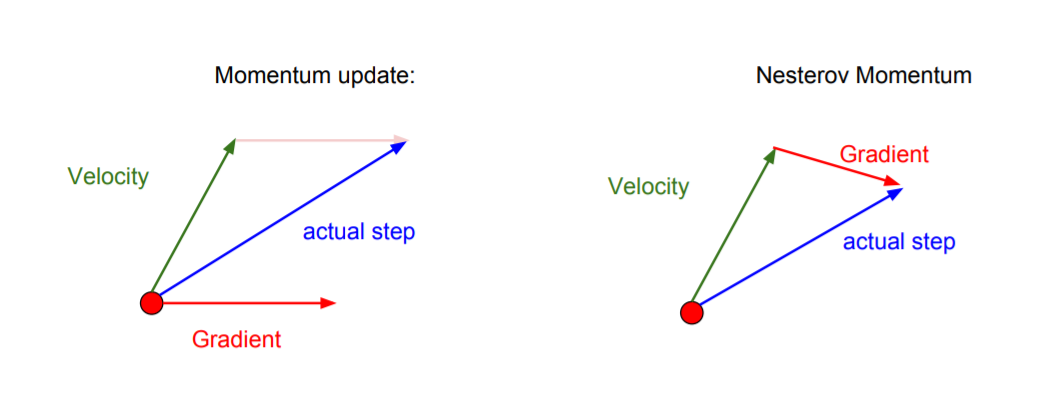
Momentum과 다르게 먼저 velocity를 계산해 움직이고 난 이후의 지점에서 gradient를 계산한다.
3) AdaGrad

업데이트 횟수에 따라 학습률을 조절하는 방식으로 변화가 많이 일어났을 수록 step size를 줄이고 변화가 적게 일어났다면 step size를 키운다.
4) RMSProp
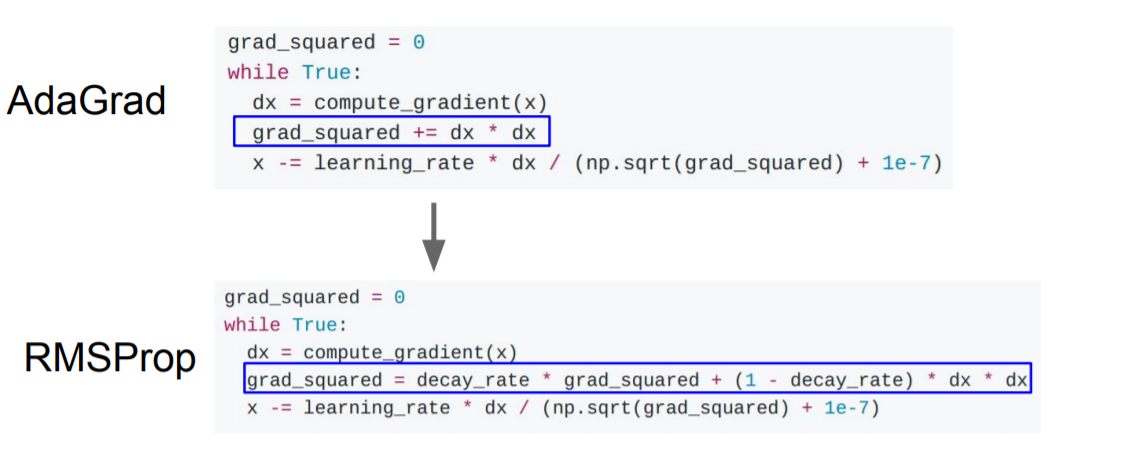
지수평균을 이용해 decay rate를 적용해서 learning rate가 서서히 작아지도록 만들었다.
5) Adam
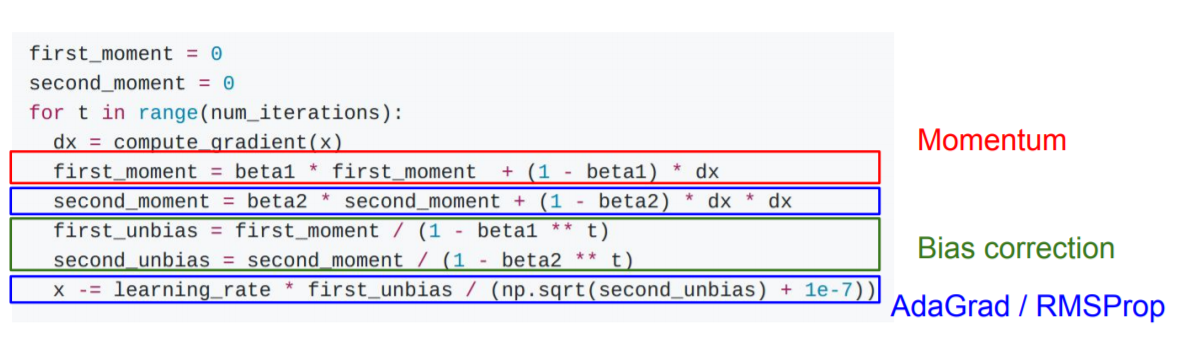
가장 많이 쓰이는 형태로 위에서 배운 momentum과 RMSProp를 합친 형태라고 볼 수 있다.
Learning Rate Decay
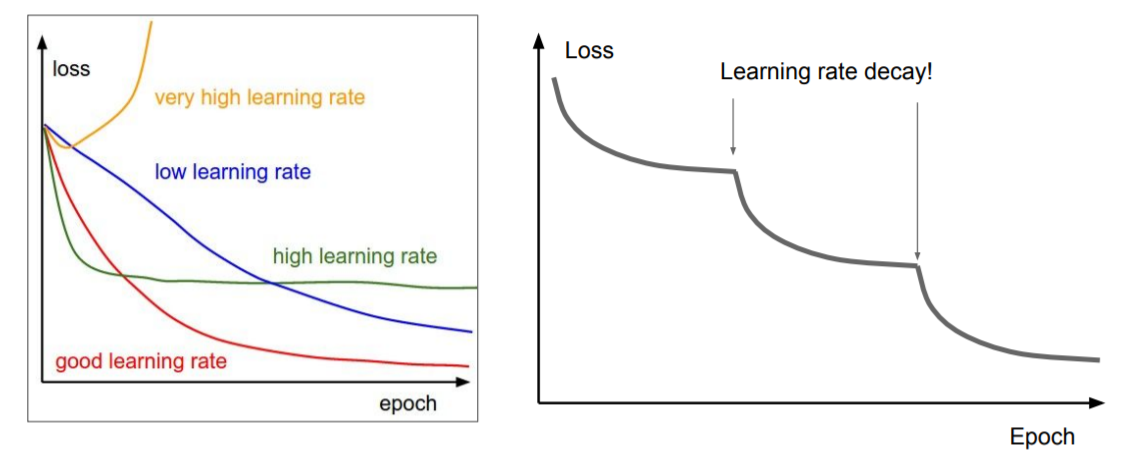
Learning rate는 하나의 최적의 값이 존재한다고 할 수 없다. 위의 그림을 보면 빨간색으로 그려진 learning rate가 가장 최선인 것처럼 보이지만 실제론 학습이 지속될수록 loss 값의 감소가 더뎌지기 때문에 그 때마다 또다시 learning rate를 줄여나가야 한다. 이러한 방식을 learning rate decay라고 한다.
Learning rate를 decay하는 방법은 다음과 같다.

Second-Order Optimization
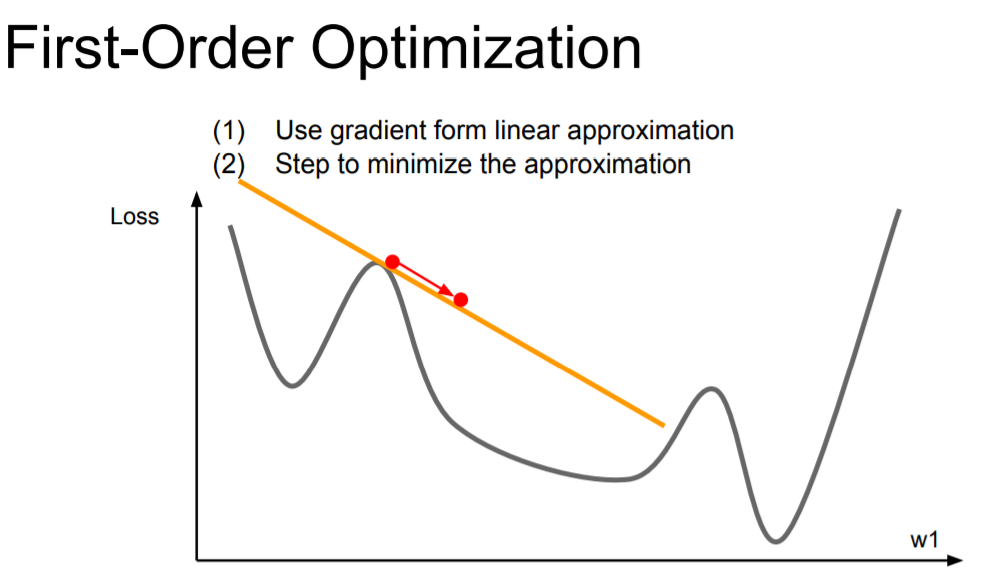
지금까지 위에서 다룬 방법들은 모두 first-order optimization이다. First-order optimization은 linear approximation을 사용하는 방법이다.
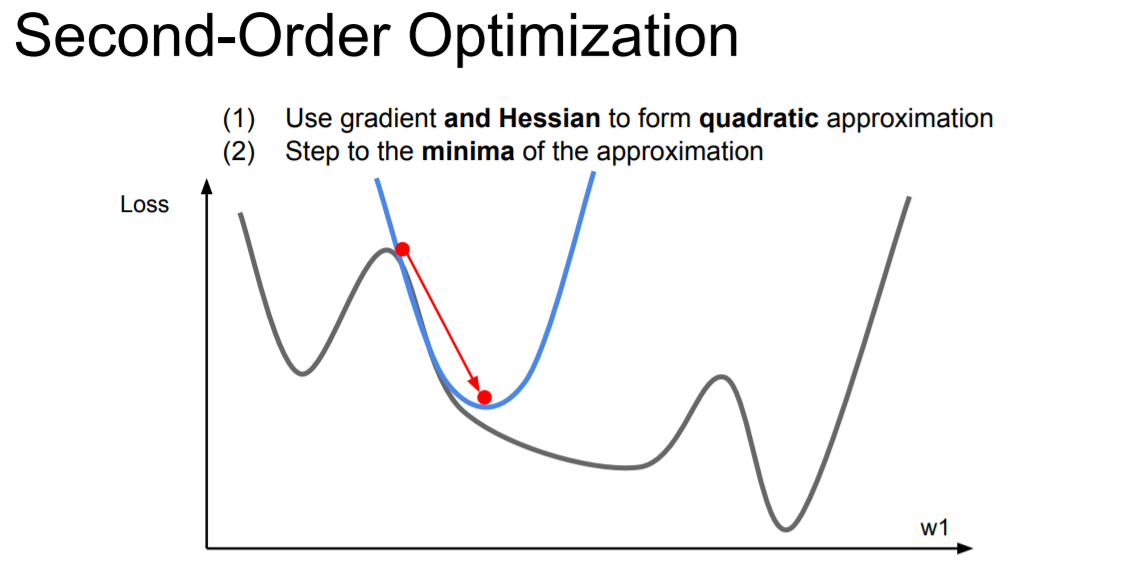
반면에 second-order optimization은 hessian을 이용한 quadratic approximation을 진행한다. first-order와는 다르게 gradient descent를 이용해서 최적의 값을 찾아나가는 것이 아니라 직접 계산을 통해 구한다.

이와 같은 이유로 gradent descent를 이용하는 first-order보다 더 좋은 방법 같지만 deep learning에서는 잘 사용하지 않는다. 위의 식을 보면 inverting을 해야함을 알 수 있는데 deep learning의 경우엔 차원이 매우 크기 때문에 시간 복잡도가 매우 높아지게 된다. 따라서 deep learning에선 잘 사용하지 않는 방법이다.
2. Model Ensembles
Model ensembles이란 같은 학습 데이터로 여러 독립적인 모델을 학습시킨 후 test 시 모델들의 결과의 평균치를 내는 작업이다. 보통 2%의 성능 향상이 있다고 본다.
다만 여러 개의 모델들을 관리해야 하고 그만큼 학습 속도가 저하될 수 있다는 문제를 가지고 있다.
3. Regularization
앞서 배운 regularization으로는 L2 regularization이 있다. 하지만 neural networks에서는 L2가 아닌 다른 걸 사용한다.
Dropout
그 중 neural networks에서 regularization을 위해 쓰이는 대표적인 방법이 바로 dropout이다. 기본적인 컨셉은 forward pass를 할 때 일부 nodes를 랜덤하게 0으로 설정하고 학습을 진행한다. 그렇게 되면 위의 그림처럼 모델이 단순해지게 된다. Node를 0으로 만드는 확률은 hyperparameter이지만 보통 0.5를 사용한다.
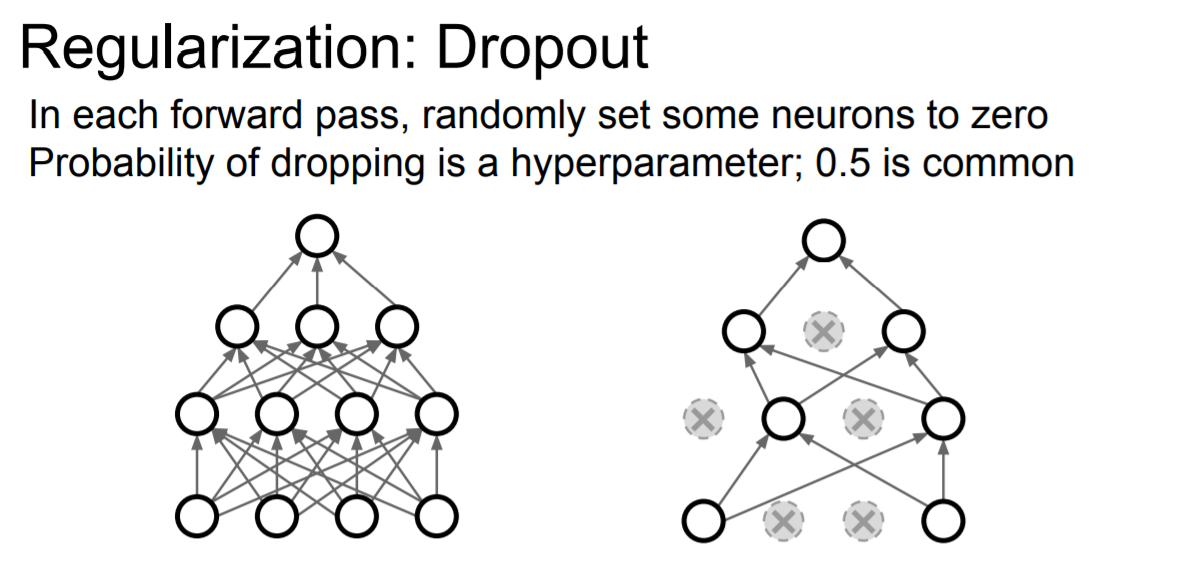
Dropout의 장점
- Neural networks가 redundant representation을 가지게 된다.
- 같은 parameter들을 공유하는 모델들의 ensembles이라고 할 수 있다.
주의할 점

Test time 때 dropout의 확률값을 곱해줘야 올바른 결과가 나오게 된다.
참고자료
