
Intro
Stanford University의 CS231n 강의를 듣고 정리한 내용입니다.
궁금한 점이나 오류가 있다면 언제든지 댓글 남겨주시기 바랍니다.
1. CPU vs GPU
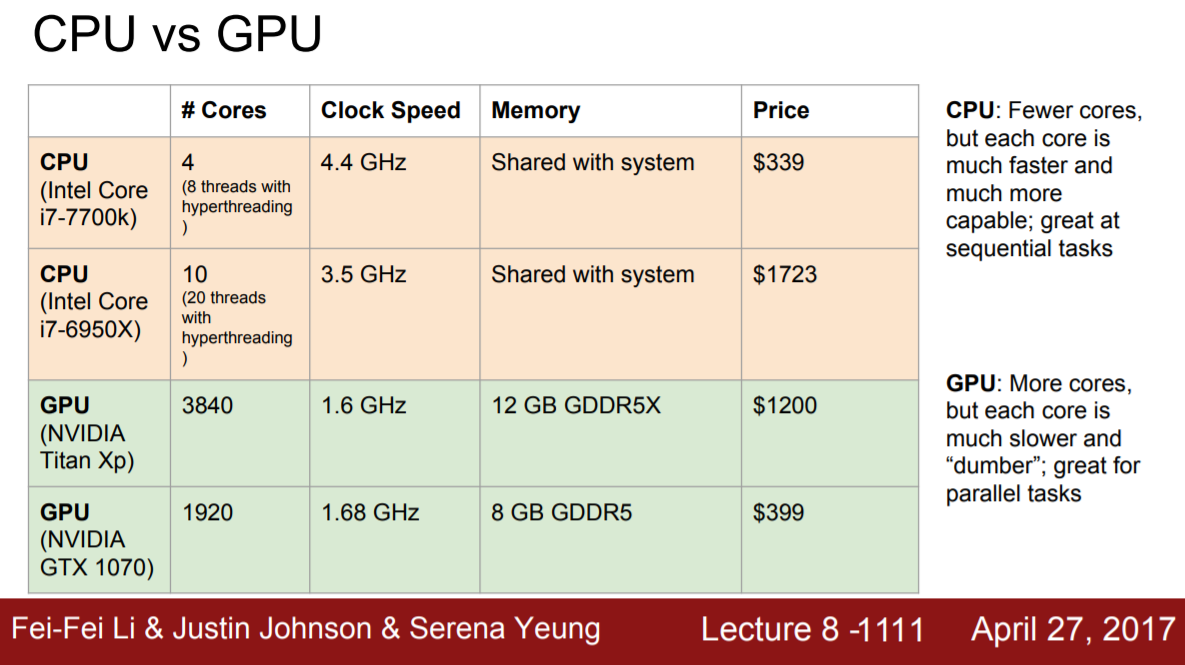
(2017년도에 제작된 강의라는 점을 참고해 주시길 바랍니다.)
-
CPU는 중앙처리장치로 GPU에 비해 적은 수의 core를 가지며 연속적인 작업에 유리하다. 또한 RAM을 시스템과 공유한다.
-
반면에 GPU는 그래픽처리장치로 훨씬 더 많은 수의 core를 가지고 병렬연산에 유리하다. 또한 병목현상을 막기 위해 별도의 그래픽 메모리를 가지고 있다.
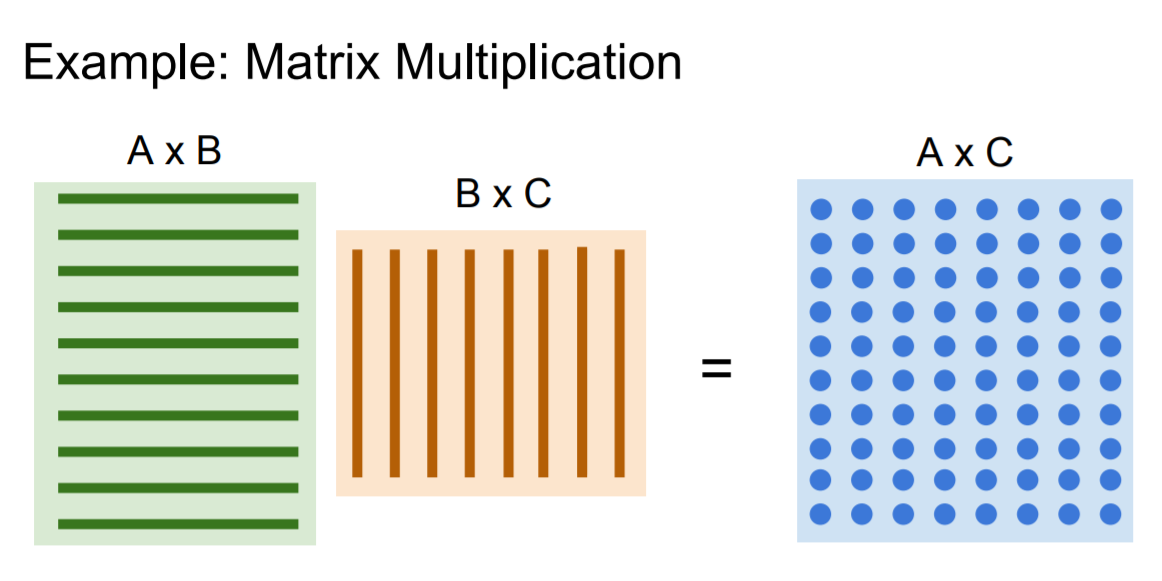
GPU는 병렬연산에 유리하기 때문에 matrix multiplication과 같은 연산을 할 때 매우 빠르게 처리할 수 있다.
위와 같은 점들 때문에 deep learning model을 학습할 땐 CPU보단 GPU를 이용한다.
2. Deep Learning Frameworks
Deep learning을 좀 더 쉽게 할 수 있도록 여러 frameworks들이 나와있는데 그 중 가장 유명하고 많이 쓰이는 것이 바로 TensorFlow와 PyTorch이다. 다만 이 강의가 제작된 시점은 2017년으로 TensorFlow 1.x 버전을 설명하고 있지만 2020년 현재 2.x로 버전이 달라지면서 많은 내용이 바뀌였다.
TensorFlow

TensorFlow는 static한 방식으로 먼저 computational graph를 정의하고 구성한 그래프를 반복적으로 재사용할 수 있다. 처음에 그래프를 최적화 시키는데 오래 걸릴 순 있지만 한번 최적화된 그래프를 만들고 나면 그것을 반복해서 사용할 수 있다는 이점이 있다. 다만 tesorflow 2.0 부턴 static이 아닌 dynamic 방식이 default 값이 되었다.
PyTorch

PyTorch는 3가지의 추상화 레벨로 구현을 해놨다.
- Tensor : GPU에서 돌아갈 수 있는 numpy array 이다.
- Variable : Computational graph를 구성하는 node를 나타내며 data 값과 gradient를 저장할 수 있다.
- Module : Neural network의 layer로 전체 뉴럴넷을 구성한다.
PyTorch는 dynamic graph를 생성한다는 점이 가장 큰 특징이다. 매 학습마다 그래프를 새로 구성하기에 이 그래프를 재사용하기 위해선 원래의 코드가 반드시 필요하다. 다만 인터프리터 언어처럼 오류 발견 및 디버깅이 훨씬 쉽다는 장점이 있고 RNN이나 recursive network 등과 같이 유동적인 것들을 다룰 때 훨씬 유리하다는 장점이 있다.
참고자료
