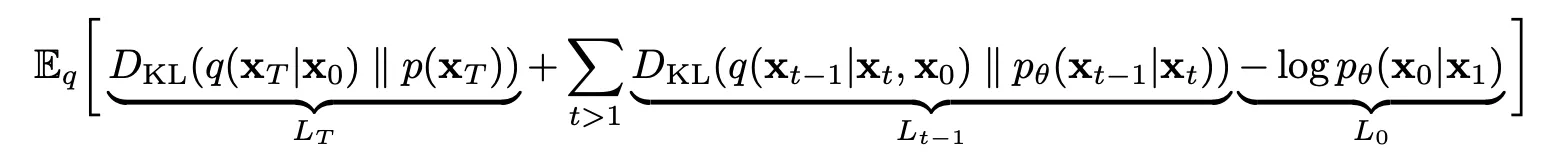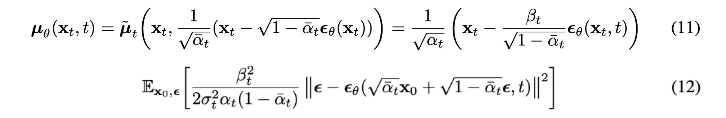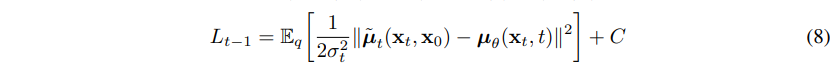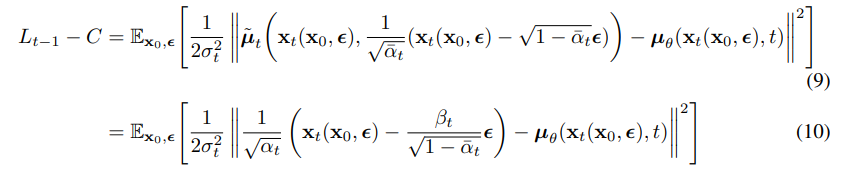Diffusion 모델은 생성 모델 중 하나로, 데이터를 노이즈로 변환했다가 다시 원래 데이터로 복원하는 과정을 학습합니다. 이를 위해 확산(디퓨전, Diffusion) 과정을 거치며 노이즈를 추가하고, 그 반대의 역확산(Reverse Diffusion) 과정을 통해 노이즈를 제거합니다. 수식적으로 살펴보면 다음과 같습니다.
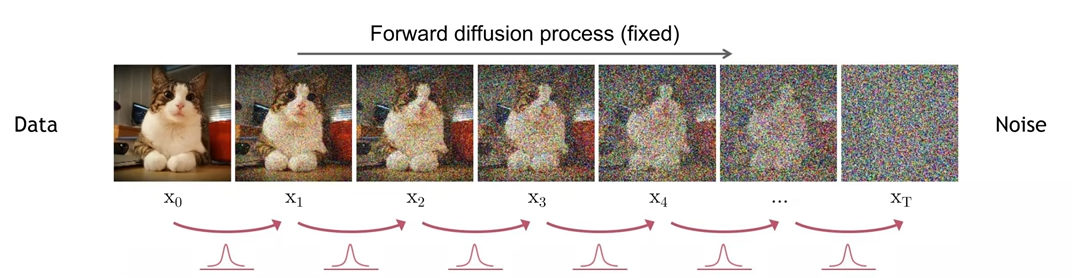
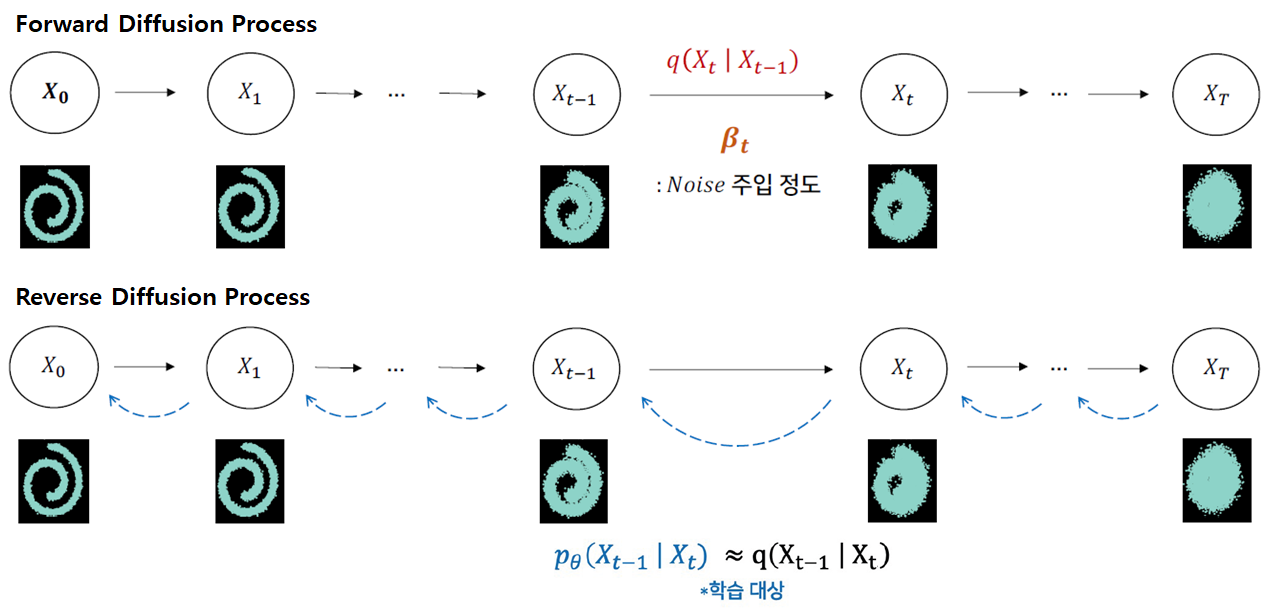
1. 정방향 확산 과정(Forward Diffusion Process)
정방향 과정에서는 원래 데이터 x0에 점진적으로 노이즈를 추가하는 과정을 거칩니다. 이 과정은t 단계에서 노이즈 xt를 생성하며, 노이즈는 주로 가우시안 분포를 따릅니다. 이를 수식으로 표현하면: q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
여기서:
βt 는 각 시간 t 마다 정의되는 노이즈 척도(variance)로, 단계가 진행됨에 따라 증가합니다.
N 은 평균이 1−βtxt−1 , 분산이 βt인 가우시안 분포입니다.
이를 전체 확산 과정으로 확장하면 x0에서 xt 로 직접 가는 확률은 다음과 같이 정의할 수 있습니다:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
여기서 αˉt=∏i=1tαi=∏i=1t(1−βi) 는 누적 노이즈 비율을 나타냅니다.
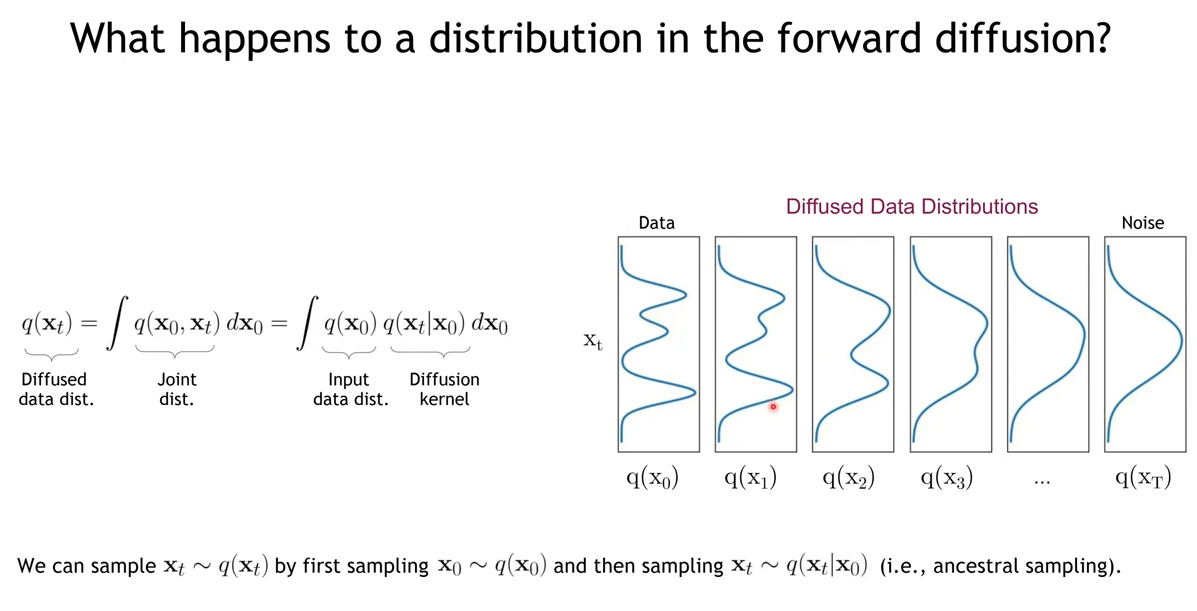
이렇듯 정방향 확산 과정은 x0 데이터 분포에서 가우시안에 가까운 xT를 만들어가는 과정입니다.
xT가 항상 가우시안 분포를 따르도록 하기 때문에 사실상 tractable한 분포이며 q(xT∣x0)는 prior p(xT)와 거의 유사합니다. 또한, DDPM에서는 정방향 확산에서 분산을 상수로 고정시킨 후에 approximate posterior를 정의하기 때문에 posterior에는 학습 가능한 파라미터가 없기에, lost term은 항상 0에 가까운 상수이며, 학습 과정은 무시됩니다.
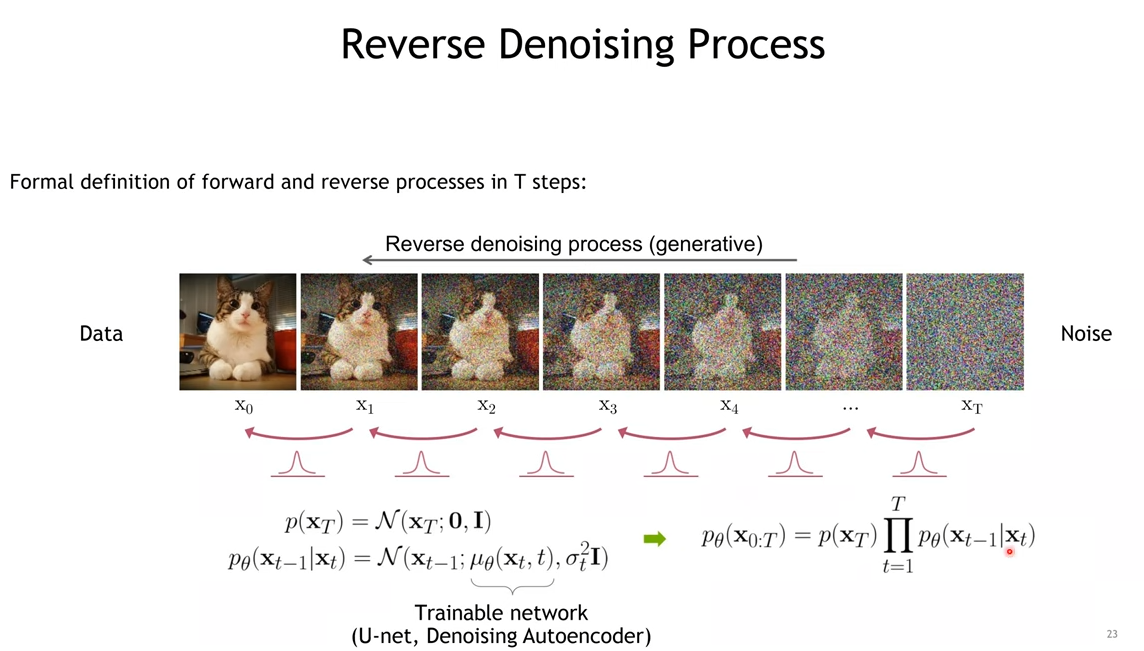
2. 역확산 과정(Reverse Diffusion Process)
생성 과정에서 우리는 노이즈 xT 에서 시작하여 원래의 데이터 x0로 점진적으로 복원합니다. 이 과정은 다음과 같은 확률 분포로 표현됩니다:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
여기서:
μθ(xt,t) 는 신경망을 통해 학습된 평균으로, 이전 단계 t−1의 데이터를 예측합니다.
Σθ(xt,t) 는 학습된 분산입니다.
이 역확산 과정은 학습된 파라미터 θ 를 통해 원래 데이터를 복원하는 것을 목표로 합니다.
정리하면 아래 그림과 같습니다.
3. 손실 함수
Diffusion 모델에서 사용하는 손실 함수는 각 단계에서 원래 데이터에 대한 복원 오차를 최소화하는 방향으로 설계됩니다. 이를 위해 정방향 과정에서 사용된 노이즈 분포 q(xt∣xt−1)와 역방향 과정의 모델 분포 pθ(xt−1∣xt) 사이의 KL Divergence를 최소화하는 방식으로 학습이 진행됩니다.
손실 함수는 다음과 같이 표현할 수 있습니다:
LT는 β를 learnable한 파라미터로 두는게 아니라 상수로서 Fix하기 때문에 고려를 하지 않아도 된다.