Authors: Yaohui Cai, Zhewei Yao, Zhen Dong
Published Year: 2020
Journal/Conference: CVPR
Keywords: Quantization
Read Status: Completed
URL: https://arxiv.org/pdf/2001.00281
Abstract: ZeroQ 방법을 통해 훈련, 검증 데이터 접근 없이 양자화하는 방법 제시
- 서론
현대 NN 모델들은 많은 메모리 사용량, 계산량 가짐
양자화를 통한 메모리, 계산량 감소의 이점을 가질 수 있음
기존 양자화 방법의 한계 (학습 데이터셋 획득 관점)
- Quantization 시 정확도 저하를 방지하기 위해서 PTQ보다 정확도 저하가 낮은 QAT(Quantization-Aware Training)을 사용하지만, 학습 데이터셋의 접근이 필요함.
- 다만, Amazon AWS/Google Cloud와 같은 MLaaS(Machine Learning as a Service/ 클라우드 제공 업체)에서 원본(학습) 데이터셋을 획득하기 어려움.
- 프라이버시, 저작권, 보안, 데이터의 물리적인 부재 등
- 제안
Zero Shot Quantization 방식의 “ZeroQ” 제안(Zero Shot Quantization: 원본데이터 접근없이 양자화)
목적: 훈련 데이터 없이 pre-trained된 모델()을 혼합 정밀도 구성을 자동으로 계산하여 효율적으로 양자화
- 증류 데이터셋(Distilled Dataset) 생성 (생성하는 최적화 공식)
- 배치 정규화(Batch Normalization) 계층의 통계(평균 및 분산)와 일치하도록 최적화된 작은 합성 데이터셋을 생성
- 자동 혼합 정밀도 양자화(Automated Mixed-Precision Quantization)
- 모델의 각 계층이 양자화에 얼마나 민감한지(정확도 손실에 미치는 영향)를 분석
- 이를 바탕으로 각 계층에 가장 적합한 비트 폭(예: 8비트, 4비트 등)을 자동으로 결정
⇒ 위 두가지 방법을 제안하고, 위 방법들을 통해 원본 데이터셋 없이도 효율적이고 정확하게 양자화
- (기존 제로샷 양자화와의 차이점)
- 증류 데이터셋 (Distilled Dataset) 생성:
- 기존 방법과의 차이점: 많은 기존 제로샷 양자화 방법들은 보정 데이터 없이 통계적 추정(ACIQ), 복잡한 GAN 기반 합성 데이터 생성(DeepInversion), 또는 휴리스틱 기반 접근(DFQ)을 사용했습니다.
- ZeroQ의 기여: ZeroQ는 이러한 방법들과 달리, 미리 학습된 모델의 배치 정규화(BN) 계층의 통계(평균, 분산)에 집중하여 이 통계와 정확히 일치하도록 최적화된 매우 작은 합성 데이터셋을 생성합니다. 이 방식은 복잡한 생성 모델 없이도 모델의 내부 특성을 효과적으로 반영하는 고품질의 가상 데이터를 만들어내며, 이는 양자화 정확도 향상에 크게 기여합니다. BN 통계는 모델 자체에 이미 내재된 정보이므로, 외부 데이터 접근 없이도 활용할 수 있다는 것이 핵심입니다.
- 자동 혼합 정밀도 양자화 (Automated Mixed-Precision Quantization):
- 기존 방법과의 차이점: 기존의 혼합 정밀도 양자화 방법들은 종종 각 계층의 비트 폭을 수동으로 결정하거나, 복잡하고 시간이 많이 소요되는 탐색 알고리즘을 사용해야 했습니다. 또한, 제로샷 환경에서 혼합 정밀도까지 적용하는 것은 더욱 어려웠습니다.
- ZeroQ의 기여: ZeroQ는 생성된 증류 데이터셋을 활용하여 각 계층의 양자화 민감도를 분석하고, 이를 바탕으로 파레토 최적(Pareto frontier) 분석을 통해 정확도 손실과 모델 크기 사이의 최적의 균형점을 찾아 자동으로 각 계층에 가장 적합한 비트 폭을 할당합니다. 이는 수동 설정의 번거로움을 없애고, 제로샷 환경에서도 고성능의 혼합 정밀도 양자화를 가능하게 합니다.
- 증류 데이터셋 (Distilled Dataset) 생성:
- 방법
(논문에서 제안하는 방법에 들어가기에 앞서 전제조건과 방법들을 설명)
- 식 1. : 일반적인 딥러닝 모델의 학습 과정을 나타내는 손실 함수 : L개의 계층을 가진 NN(Neural Network/ 신경망) 모델 : 학습 가능한 매개변수 : 손실 함수(일반적으로 Cross-Entropy loss) : i번째 훈련 입력 데이터, 레이블 : 전체 데이터 샘플 수
가정
- 모델에는 의 L개의 BN 계층 (BN: Batch Normalization)
- : i번째 BN 계층()이전까지의 activation (i번째 컨볼루션 레이어의 출력)
- → 이후 추론 중에 는 의 실행 평균()과 분산()으로 정규화 됨
- 에는 스케일링 및 바이어스 보정() 포함
- 입력 데이터는 표준 정규화 되어있음. (평균: 0, 표준편차 1: )
- 원본 모델은 32-bit precision model(FP32)
- 텐서를 양자화하기 위해 매개변수를 범위로 클리핑하고, 이 공간을 asymmetric quantization(비대칭 양자화)를 통해 개의 간격으로 이산화
- (k-bit로 양자화시 개의 정수값 표현 가능, ex. 2-bit 양자화 → 2^2 = 4개의 값 → 3개의 구간)
- → 간격:
- → 32-bit single-precision value(단위 정밀 값)가 범위의 부호없는 정수로 매핑됨
- 훈련, 검증 데이터셋 접근 불가능
- 논문에서는 uniform quantization(균일 양자화)만 사용 (non-uniform(비균일) 방법은 효율적인 하드웨어 실행에 적합 X)
ZeroQ 방법은 고정, 혼합 정밀도 양자화 지원
- 고정 정밀도 양자화: 모든 layer를 같은 비트 정밀도로 양자화. ex) k-bit 양자화시 모든 Layer를 k-bit로 양자화
- 혼합 정밀도 양자화: 각 layer가 다른 비트 정밀도로 양자화 될 수 있음. 민감한 계층: 높은 정밀도, 덜 민감한 계층: 낮은 정밀도로 양자화하여 전체 모델 크기를 늘리지 않으면서 높은 정확도 달성
- → 4-bit양자화와 같은 초정밀도 설정에서 중요함
- 민감도 측정: 원본 모델과 양자화된 모델의 KL Divergence 발산으로 측정
- 식 2. : i번째 layer를 k-bit로 양자화시의 민감도 : i번째 layer를 k-bit로 양자화한 것 : Distilled dataset에 포함된 샘플의 총 개수
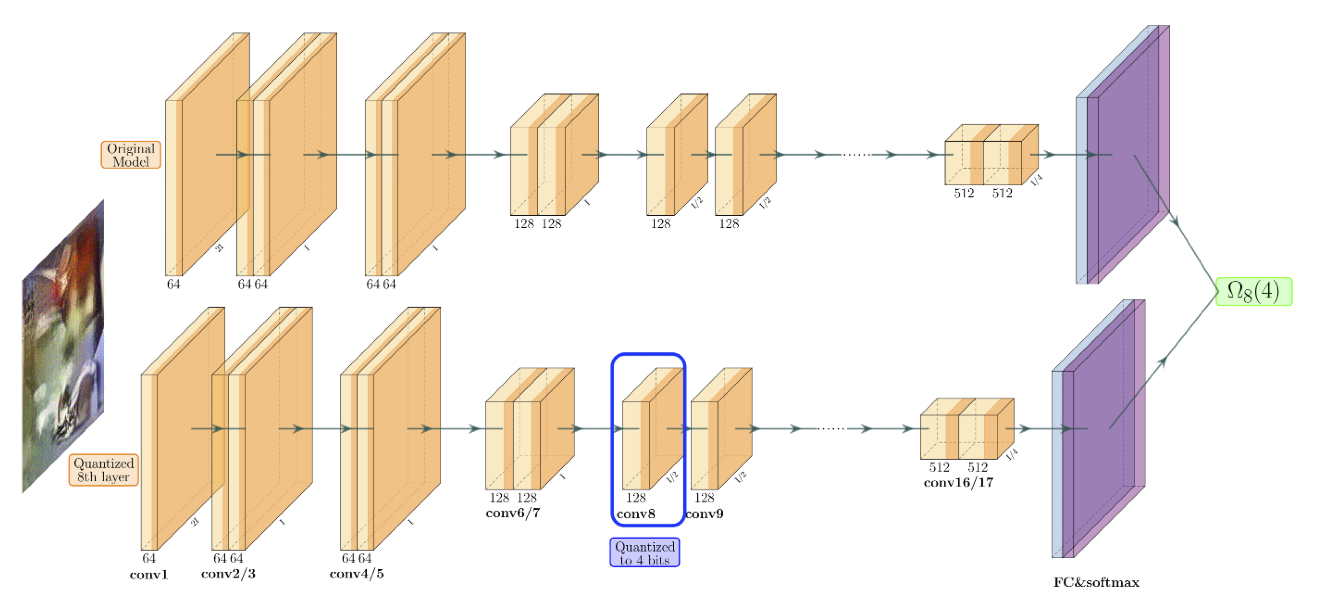
- Fig. 1: 8번째 계층을 4비트로 양자화시의 민감도() 계산
방법 1. Distilled Data (증류 데이터) 생성
-
제로샷 양자화: 원본 훈련/검증 데이터에 접근 못함 → 두가지 문제 존재
- 문제 1. 양자화를 위한 클리핑 범위() 결정 불가능
- 각 계층의 activation 값을 알아야하지만, 훈련 데이터 없이 결정 불가능
- 문제 2. 식 (2)에서 훈련 데이터 확인 불가능
- 문제 1. 양자화를 위한 클리핑 범위() 결정 불가능
-
문제 해결 방법: 평균 0, 단위 분산을 가지는 가우시안 분포에서 추출한 임의의 입력 데이터 생성 및 공급
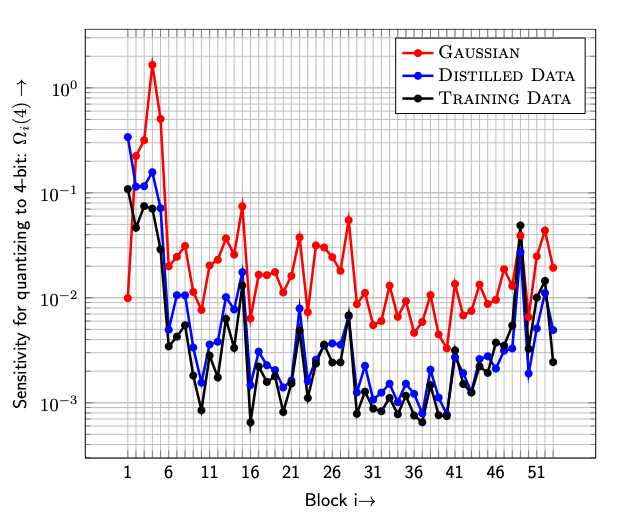
- Fig. 2(일부): 각 데이터에 대한 4-bit 양자화시 민감도

- Fig. 3: 왼쪽: 가우시안/ 오른쪽: Distilled 데이터 시각화한 그림
- 오른쪽 Distilled data에서 더 많은 local structure 확인할 수 있음
- Fig. 2(일부): 각 데이터에 대한 4-bit 양자화시 민감도
-
새로운 문제: activation 값의 올바른 통계를 찾아낼 수 없음 (가우시안 데이터는 모델의 올바른 민감도 포착 못함)
-
문제 해결 방법: NN모델 자체에서 입력 데이터를 증류(distill)
- NN의 속성을 기반으로 합성 데이터 생성
- → 모델의 BN layer에 인코딩된 통계와 가장 잘 일치하는 데이터 분포를 학습하기 위한 Distillation optimization problem 해결
-
증류 최적화 문제 (Distillation optimization problem)
- 식 3. : 증류된 입력 데이터 : i번째 BN 계층의 평균, 표준편차 매개변수 : i번째 계층에서 Distilled Data 분포의 평균, 표준편차
- 식 (3)을 통해 최적화 문제 해결 → 원본 모델과 거의 일치하는 통계 분포를 가지는 입력 데이터 증류 가능
- 식 3. : 증류된 입력 데이터 : i번째 BN 계층의 평균, 표준편차 매개변수 : i번째 계층에서 Distilled Data 분포의 평균, 표준편차
-

- 알고리즘 1. 증류 데이터 생성
-
생성된 Distilled Data를 식 (2)에 넣으면 발생했던 문제 2가지 해결 가능 & 양자화 민감도 얻어냄
-
원본 학습 데이터와 거의 일치하는 모델의 양자화 민감도를 얻어낼 수 있음
방법 2. 파레토 프론티어 (Pareto Frontier)
-
혼합 정밀도 양자화의 주요 과제: 전체 NN에 대한 정확한 비트 정밀도 구성하는 것
-
m개의 정밀도 옵션, L개의 계층 모델일때 혼합 정밀도 검색 공간 S 는 의 크기 가짐
- ex) m=3 ({2, 4, 8} 비트 정밀도), ResNet50의 경우 ( )의 검색 공간 (매우 큼)
-
식 (2)의 민감도 측정 부분을 활용해 검색 공간 줄일 수 있음
-
주요 아이디어: 민감한 계층에는 높은 비트 정밀도, 덜 민감한 계층에는 낮은 비트 정밀도 사용
-
⇒ 정확한 비트 정밀도 설정을 계산하기 위해 파레토 프론티어 방법 제시
-
(목표 양자화 모델 크기)에 대해, 모델 크기를 초래하는 각 비트 정밀도 구성에 대해 모델의 전체 민감도 측정, 전체 민감도가 최소가 되도록 함 ⇒ 최적화 문제
-
(Indepenence Assumption/ 독립성 가정: 각 계층의 민감도는 다른 계층의 상태와 독립적이다.)
-
식 4.
: i번째 계층의 양자화 정밀도 (k-bit로 양자화)
: i번째 계층의 매개변수 크기
: 들의 집합 ⇒ 혼합 정밀도 구성
-
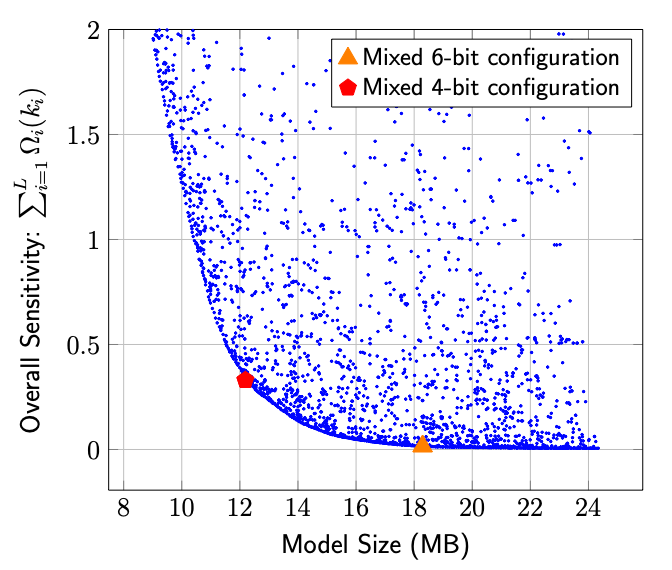
- Fig. 4: ResNet50의 파레토 프론티어/ 각 점: 혼합 정밀보 비트 설정
-
파레토 프론티어 계산 오버헤드 :
m개의 서로 다른 정밀도 옵션에 대해 민감도 계산
⇒ 모든 계층의 모든 비트 조합을 탐색하는 에 비해 작은 계산량 가짐
-
계산 오버헤드를 줄인 방법?
- 독립성 가정
- (에서는 i번째 계층을 k-bit로 양자화시, 다른 계층들이 어떤 비트로 양자화 되어있는지에 영향)
- 식 (2)에서 계산시, 오직 i번째 계층만 k-bit로 양자화, 나머지 계층은 full-precision 상태
- ⇒ 각 계층에 대해 독립적으로 민감도 측정 가능
- 동적 프로그래밍 (DP/ Dynamic Programming)
- (에서는 모든 조합을 만들어 모델 크기와 전체 민감도 계산, 비교 필요)
- DP 사용 → 개별적으로 계산된 민감도 값을 효율적으로 조합 가능
- ex) 배낭 문제, 계층: 아이템, 비트수: 아이템의 무게/부피, 민감도: 가치
- 첫 번째 계층부터 시작하여, 각 비트 옵션(2, 4, 8비트)을 선택했을 때의 (누적 모델 크기, 누적 민감도)를 계산합니다.
- 두 번째 계층으로 넘어가서, 첫 번째 계층의 각 선택 결과에 두 번째 계층의 각 비트 옵션을 조합했을 때의 (누적 모델 크기, 누적 민감도)를 계산합니다. 이때, 모델 크기 제약을 넘지 않는 조합들만 고려하고, 동일한 누적 모델 크기라면 누적 민감도가 더 작은 것만 남기는 식으로 최적해를 유지합니다.
- 이 과정을 마지막 계층까지 반복합니다.
- (부록) 단계적 최적화
- 독립성 가정이 실제로는 명확하게 적용되지 않음 (계층간 상호작용 때문-activation 값의 변화, 누적 오차, 모델의 비선형성)
- L개의 계층을 a개의 그룹으로 나눔 ()
- 그룹 단위로 민감도 계산 (독립성 가정 사용)
- 다음 그룹으로 넘어갈 때 현재 그룹을 양자화했을 때의 누적 민감도 계산/ 넘겨줌 (독립성 가정 완화)
- ⇒ 독립성 가정의 한계를 보완하면서도 낮은 계산 복잡도 가짐 (절충안 느낌)
- 독립성 가정
-
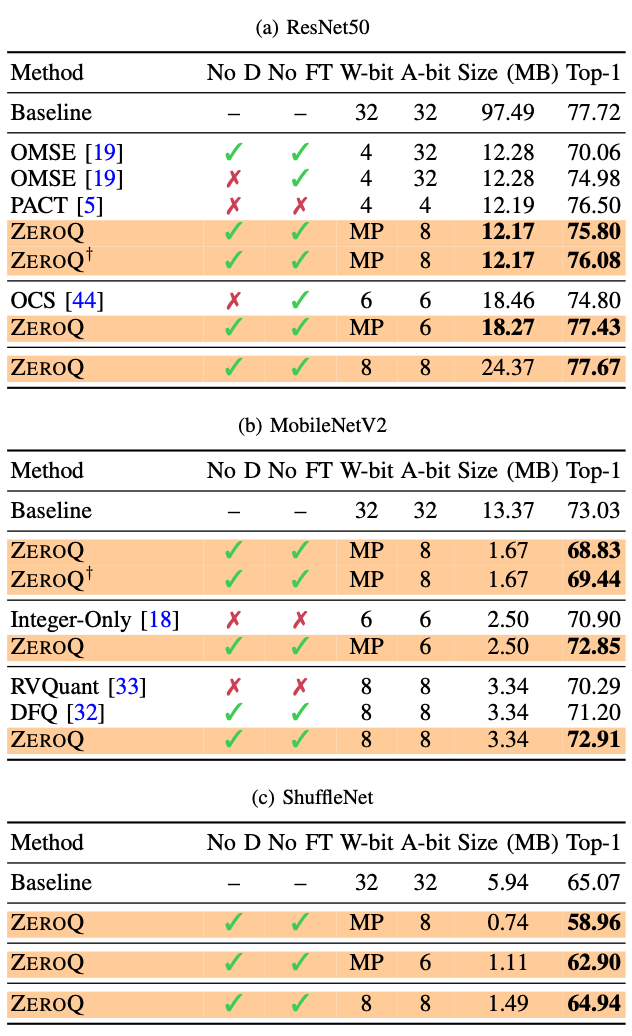
파레토 프론티어 접근 방식을 통해 최선의 구성은 아니지만 매우 작은 성능 손실로 SOTA와 비슷한 성능
- 결론
훈련/검증 데이터가 전혀 필요 없는 새로운 PTQ 방식 ZeroQ 제안.
배치 정규화 계층(BN layer)의 통계와 일치하도록 하는 Distilled Dataset을 생성하여 양자화.
Distilled Data를 통해 원본 모델과 양자화된 모델의 민감도를 잘 찾아낼 수 있음.
Paleto frontier 방법을 통해 mixed-precision(혼합 정밀도) 설정을 위한 bit-precision(비트 정밀도) 구성을 자동으로 선택.
낮은 계산 오버헤드를 가짐.
이전 PTQ 방법들에 비해 비슷하거나 더 낮은 모델 크기로 더 높은 정확도 가짐.
⇒ ZeroQ 방식이 다른 zero-shot quantization 방법들을 능가함을 보여줌
