[Paper review] GenQ: Quantization in Low Data Regimes with Generative Synthetic Data
Paper review
Authors: Yuhang Li, Youngeun Kim, Donghyun Lee, Priyadarshini Panda
Published Year: 2024
Journal/Conference: ECCV 2024
Keywords: Quantization
Read Status: Completed
URL: https://arxiv.org/abs/2312.05272
- 목적
Quantization error를 완화하기 위해서는 훈련 데이터가 필요함.
ZeroQ와 같이 Distilled Dataset 생성하여 훈련 데이터 대체했던 방법(Data-free Quantization) 존재
But 한계점도 동시에 존재
기존 방식: Image Inversion & GAN 기반으로 data 합성(생성)
한계점
- 계산 효율성이 매우 떨어짐 (계산 비용이 너무 높음)
- Batch Normalization(BN) Layer가 없는 모델은 활용할 수 없음.
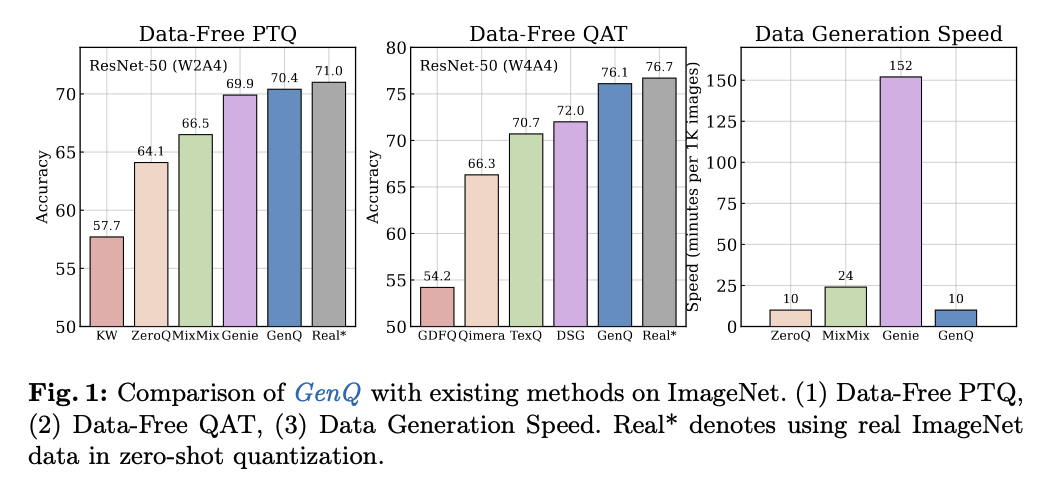
세가지 핵심 기여
- GenQ 방식 제안, text-to-image 모델(Diffusion model)을 데이터 합성(Data-free Quantization)에 활용한 최초의 시도, 합성 데이터와 실제 데이터 간의 분포 차이를 줄이기 위한 “에너지 점수 필터링”, “배치정규화 분포 필터링” 제안
- 데이터가 부족한 경우를 위해 실제 데이터를 이용해 “토큰 임베딩”을 학습하여 학성 데이터 생성
- SOTA 달성, PTQ/ QAT 에서 모두 SOTA 달성
- 사전 지식
- Quantization
- 변수 설명 : 양자화하려는 원본 가중치 (실수) / : 정수화된 가중치 : step size : 반올림 연산 : 제로 포인트 벡터 (실수의 0이 어떤 정수 값에 매핑되는지) : 양자화된 정수 값의 하한/ 상한 (uniform quant→)
- 변수 설명 : 양자화하려는 원본 가중치 (실수) / : 정수화된 가중치 : step size : 반올림 연산 : 제로 포인트 벡터 (실수의 0이 어떤 정수 값에 매핑되는지) : 양자화된 정수 값의 하한/ 상한 (uniform quant→)
- 변수 설명 : 양자화된 가중치 (정수화된 가중치를 실수 스케일로 변환)
- 변수 설명 : 양자화된 가중치 (정수화된 가중치를 실수 스케일로 변환)
- QAT
- LSQ(Learned Step Size Quantization)
- 를 고정된 값이 아닌 gradient descent를 이용해 최적의 값을 찾음
- STE(Straight-Through Estimator)
- 반올림 연산이 미분 불가능하기에, 역전파 과정에서 반올림 함수의 그레디언트를 1로 가정 → 에 대한 그레디언트 계산 가능
- ()
- LSQ(Learned Step Size Quantization)
- PTQ
- 양자화 오차()를 최소화하는 를 찾음
- 추가적으로 weight rounding을 통해 모델 성능 향상
- Stable Diffusion Dataq Generation
- Stable Diffusion → DDPM(Denoising Diffusion Probabilistic Model)을 이용
- 구성 요소 : 텍스트 인코더 : 이미지 인코더 : 이미지 디코더 : Denoising U-Net (노이즈 제거)
- 구성 요소 : 텍스트 인코더 : 이미지 인코더 : 이미지 디코더 : Denoising U-Net (노이즈 제거)
- 추론 과정 (Inference Process)
- 가우시안 분포 에서 무작위 노이즈 잠재 이미지 샘플링
- 텍스트 프롬프트를 라 가정, denoising U-net이 cross-attention layer를 이용해 텍스트 인코더 와 이미지(z) 융합 → 점진적으로 이미지의 노이즈 제거
- 타임스텝 만큼의 노이즈 제거 과정 이후, 이미지 디코더 에 의해 디코딩 되어 고해상도 이미지 생성
- 학습 과정 (Training Process)
- 원본 이미지 를 이미지 인코더 를 통해 잠재 벡터 로 압축
- 잠재 벡터 에 점진적으로 노이즈 추가(Diffusion process), 시점의 노이즈가 추가된 잠재 벡터 → Markov chain process
- : 노이즈의 양을 조절하는 하이퍼 파라미터
- 가 커질수록 (시간이 경과할수록) 완전한 노이즈 에 가까워짐 (
- U-Net 학습, 시점의 노이즈 낀 잠재 벡터 와 를 입력받아, 원본 잠재 벡터에 추가되었던 노이즈 예측하도록 학습
- : positive weighting function
- : 에서 예측한 노이즈 벡터
- U-Net이 예측한 노이즈 가 실제 추가된 노이즈 과 최대한 같아지도록 U-Net의 파라미터 최적화
- 원본 이미지 를 이미지 인코더 를 통해 잠재 벡터 로 압축
- Stable Diffusion → DDPM(Denoising Diffusion Probabilistic Model)을 이용
- 방법
-
Data-Free GenQ
-
실제 데이터가 전혀 없을 때, 클래스 이름만으로 데이터 생성 및 필터링
-
Label Prompt Method
- 형태의 간단현 프롬프트로 이미지 생성
- {C}: 고양이, 개 와 같은 클래스 이름, {D}: nice, dark와 같은 형용사 템플릿
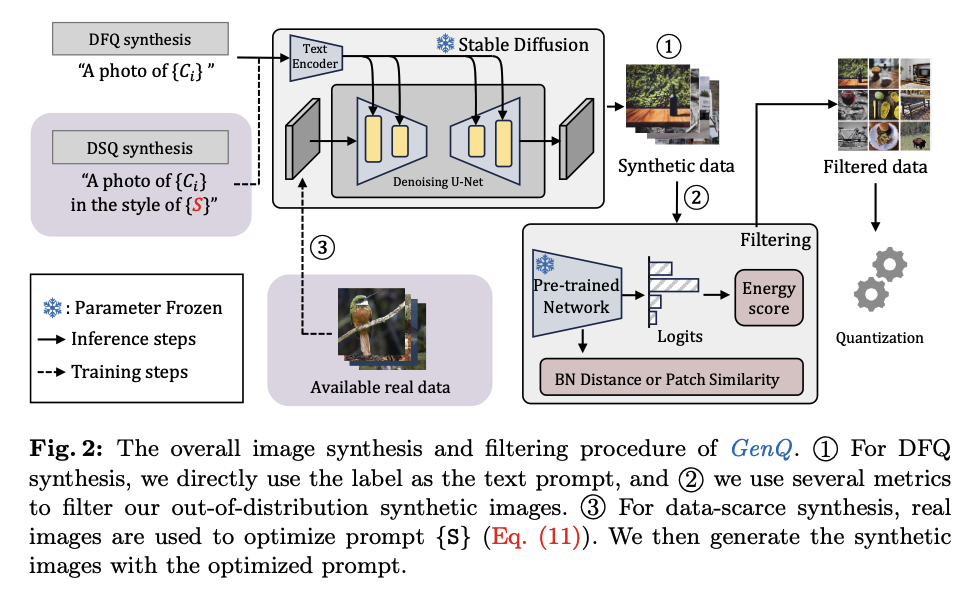
- 문제점: 레이블에만 의존/ 실제 데이터의 분포를 반영하지 못함(분포 불일치 문제(OOD) 발생)
-
Model-Dependent Selection (필터링)
- 위 문제점 해결하고 더 나은 품질의 데이터 얻기 위해 2단계 필터링
- Energy Filtering
- 생성된 이미지를 pre-trained된 모델에 넣어 energy score 계산
- energy score: 생성된 이미지가 얼마나 익숙한지 (낮을 수록 익숙함)
- : 이미지 클래스의 수/ 온도(temperature)
- 모델에게 낯선 데이터(OOD(Out-of-Distribution))는 여러 클래스의 로짓 값이 비슷
- → 전체 합이 커져 에너지 점수 높아짐
- 에너지 점수가 낮은 이미지를 선택하여 1차 필터링
- BatchNorm Distribution Filtering (CNN 모델)
- 목적: 데이터의 일관성 확보
- 기존 방식 문제점
- BN 통계치가 배치 단위로 계산되므로 부정확함
- 제안 방법
- BN sensitivity: 한 이미지가 배치 전체의 통계에 얼마나 큰 영향을 미치는지 (민감도)
- : 전체 배치의 BN 오차에서 i번째 이미지를 뺐을 때의 BN 오차를 뺀 값
- BN sensitivity가 큰 이미지를 이상치로 간주 및 제거
- Patch Similarity Filtering (ViT 모델)
- 데이터의 정보량과 다양성 확보
- ViT 모델은 BN layer가 없기에 다른 필터링 방식 필요
- → 이미지 내 patch들의 다양성을 측정하여 정보의 풍부함 평가
- 제안 방법
- ViT의 출력 피처맵을 패치 단위로 나누고, 모든 패치 쌍 간의 코사인 유사도 계산
- : 출력 피처맵의 i번째 패치
- 위 코사인 유사도 값들의 분포를 이용해 Differential Entropy 계산
- 유사도 낮음(패치들이 서로 다름) → 엔트로피 커짐 → 선택
- 유사도 높음(단조로운 이미지) → 엔트로피 낮음 → 선택 X
- 필터링 정리
- 모든 생성된 이미지에 대해 에너지 필터링 적용
- CNN 모델 → BN Filtering / ViT 모델 → Patch Similarity Filtering 적용
- 최종 선택된 데이터셋을 양자화에 사용
-
-
Data-Scarce GenQ
- 데이터가 한정된 경우(적은 경우) 사용 (ex) 1-shot learning)
- Token Embedding Learning
- 원본 데이터 전체의 고유한 스타일/ 분포 특성을 나타내는 텍스트 토큰 {S} 학습
- 소량의 실제 이미지 와 유사해지도록 텍스트 토큰 {S} 최적화
- 이미지 생성 및 필터링
- 학습이 완료된 텍스트 토큰 {S}를 사용해 모든 클래스에 대한 이미지 대량 생성
- 생성된 이미지를 2단계 필터링에 적용하여 최종 데이터셋 제작
-
Quantization with Synthetic Data from GenQ
- 최종적으로 선별된 합성 데이터를 사용해 양자화 수행
- PTQ: 기존의 SOTA PTQ 방식(reconstruction-based rounding optimization) 적용
- QAT: PTQ로 최적화된 모델에서 시작 → 학습이 더 안정적이고 효과적
- PTQ 과정에서 최적화된 반올림 변수 찾기
- : 반올림 방향 결정
- : 소수점 이하를 버리는 바닥 함수
- QAT를 시작 시 기존 가중치 와 반올림 변수 는 고정/ 0으로 초기화된 새로운 학습 가능한 벡터
- PTQ 과정에서 최적화된 반올림 변수 찾기
- PTQ/ QAT에서 양자화 과정은 오직 GenQ를 통해 생성된 합성 데이터만을 사용해 수행됨
- 실험
-
기존 기법들 보다 명확하고 사물의 특징을 살린 고해상도 이미지 생성된 것 확인 가능

-
재사용 가능 & 실제 데이터의 분포를 잘 모사하고 있음

-
PTQ/QAT 모두에서 SOTA 성능 달성
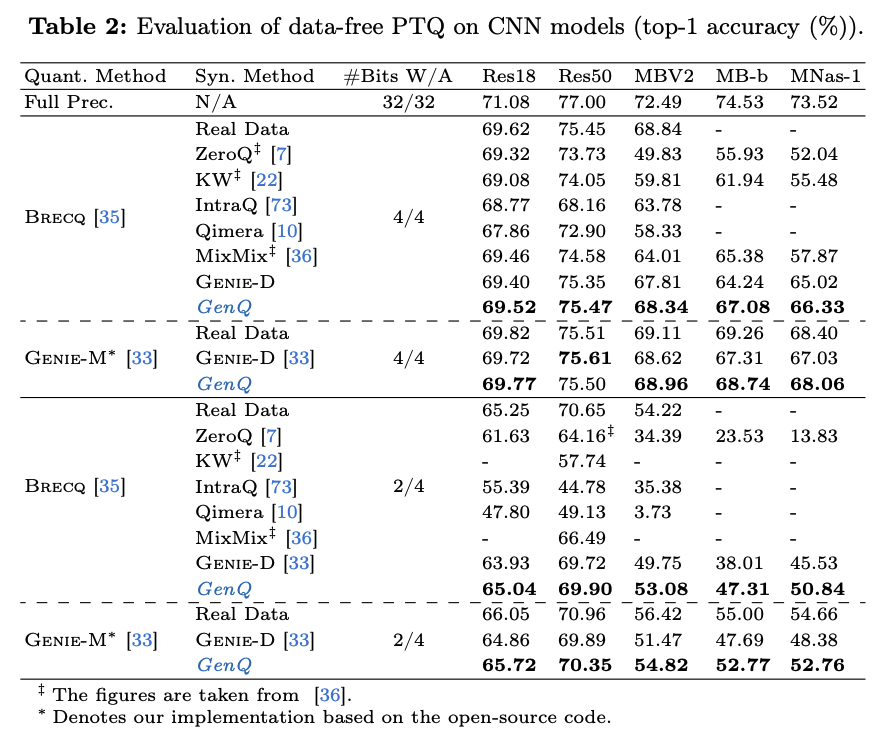
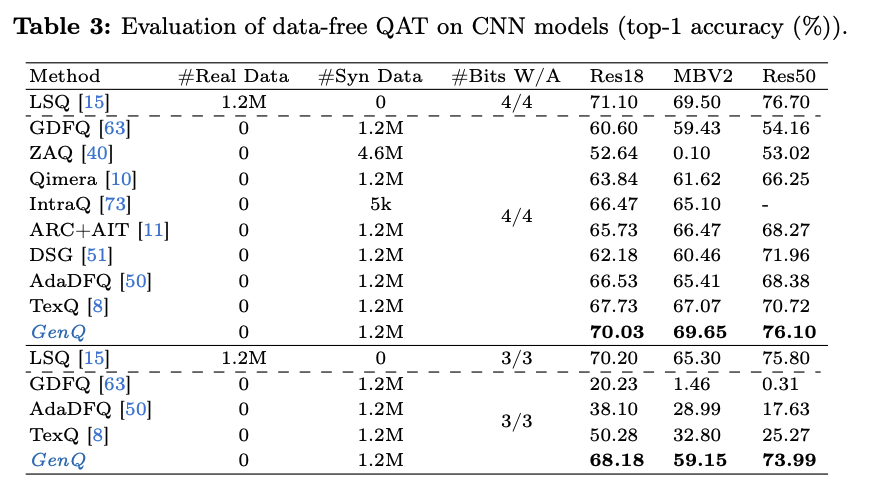
 -
높은 전이성 (한 모델을 기준으로 생성한 데이터를 다른 모델의 양자화에 사용했을 때 성능 유지 정도)

-
Filtering 강도 분석 (r = 0.5일때 가장 높은 성능 & energy score는 filtering ratio에 비례)
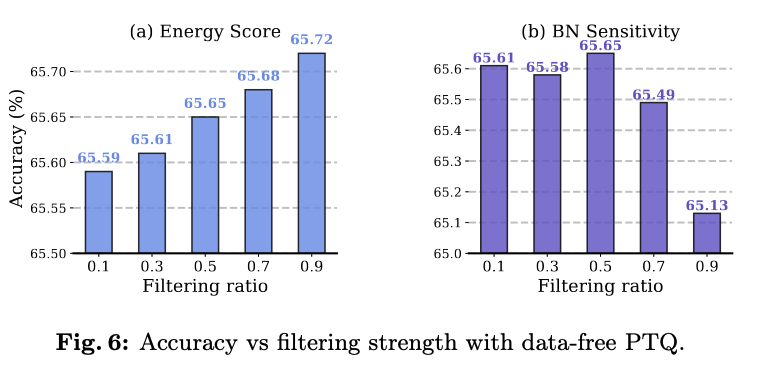
→ 너무 많이 필터링하게 되면 다양성이 줄어들어 성능 감소 (가설)
- 결론
- Data-scarce Quantization을 위한 Text-to-Image model을 활용해 이미지를 합성하는 GenQ 제안
- Data free(no real data) & Data scarce (few real data) 상황 모두에서 이미지 생성 가능
- 여러 필터링 방법과 토큰 임베딩 학습 알고리즘을 통해 생성된 이미지의 품질 개선
- PTQ, QAT 모두에서 SOTA 성능 달성
