1. 배경
- Transformer 모델의 Self-Attention 연산은 (문장의 길이)에 대해 의 계산 비용을 가짐
- 문장이 길어질수록 비효율적 (추론 시간, 메모리 사용량 증가 등으로 실시간 처리, on-device 배포 어려움)
- Token pruning을 통해 연산량을 줄이는 여러 방법들이 연구되었지만, 입력 길이 변화에 대해 성능이 떨어지거나 여전히 느리다는 문제점들을 가지고 있음
2. 관련 연구
- Transformer의 속도와 메모리 사용을 개선하기 위해 크게 4가지 방법들이 연구됨
- 효율적인 아키텍처, 지식 증류, 양자화, 프루닝
- Transformer Pruning
- Unstructed pruning (비구조적 프루닝)
- 파라미터를 임의의 위치에서 제거(0으로 만듦)하는 방법
- 불규칙한 희소성(중간중간 0이 있어 병렬 처리 비효율) 때문에 하드웨어 가속이 어려움
- Structed pruning
- 네트워크 구조 자체를 단순화(제거)하는 방법
- 하드웨어에 더 친화적임
- 종류
- Head Pruning
- Layer Pruning
- Low-rank Pruning
- Block Pruning
- Unstructed pruning (비구조적 프루닝)
- 모두 모델의 가중치(파라미터)를 프루닝하는 방법
- 논문에서는 Token pruning에 집중
- Token Pruning
- 입력 시퀀스의 토큰을 제거(프루닝)하는 방법
- 기존 방법들
- PoWER-BERT, LAT: 동일한 토큰 수를 가지게 프루닝
- 짧은 문장은 과소 프루닝, 긴 문장은 과대 프루닝 될 수 있음
- SpAtten, TR-BERT: 시퀀스 길이에 비례하게 프루닝
- 시퀀스의 내용에 기반해 프루닝하지 않음
- 강화학습을 사용하는데 추가적인 연산 비용이 발생
- PoWER-BERT, LAT: 동일한 토큰 수를 가지게 프루닝
- 한계점
- top-k 연산에서 top-k engine과 같은 전용 하드웨어가 없다면 병목이 발생함
- top-k 연산이 비효율적인 이유?
- 계산 복잡도: ~ . 매 레이어마다 해당 연산이 필요함
- 메모리 접근 비효율: 데이터가 정렬되어있지 않기에 랜덤 엑세스시 캐시 미스 많음
- 하드웨어 가속 비적합: 비교와 선택 방법, 데이터 종속성이 커 병렬화 효율 낮음
- top-k 연산이 비효율적인 이유?
- 입력 길이 변화에 따라 성능이 떨어짐
- top-k 연산에서 top-k engine과 같은 전용 하드웨어가 없다면 병목이 발생함
3. 방법
-
Background
-
BERT(Transformer)의 구조를 수식으로 아래와 같이 표현
-
Multi-Head Self-Attention
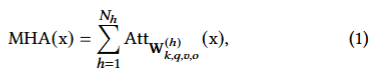
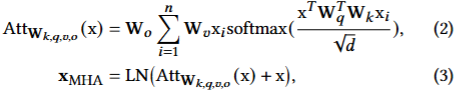
-
Feed-Forward Network & 잔차연결 + 정규화
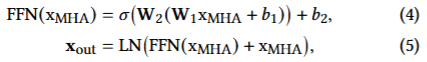
-
-
Threshold Token Pruning
-
어떻게 프루닝을 할 것인지?
-
방법
- Importance score(토큰 중요도)를 이용해 토큰의 프루닝 여부 결정
- 토큰 중요도: 각 레이어에서 다른 모든 토큰들이 해당 토큰을 얼마나 바라보는지를 평균 낸 정보
- 각 레이어에서 임계값보다 낮으면 해당 토큰 제거
- top-k 연산이 아닌 단순 비교 연산(임계값으로 처리)만 하기에 계산량이 적음
-
수식
- 토큰 가 를 얼마나 주목하는지
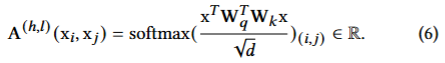
- 의 토큰 중요도(다른 토큰들이 토큰 를 주목하는 평균)
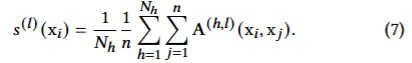
- 임계값보다 크면 1, 낮으면 0(프루닝)
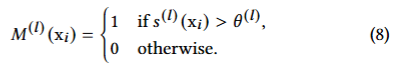
- 토큰 가 를 얼마나 주목하는지
-
문장에서 토큰이 프루닝(제거)되는 과정

-
Learnable Threshold for Token Pruning
-
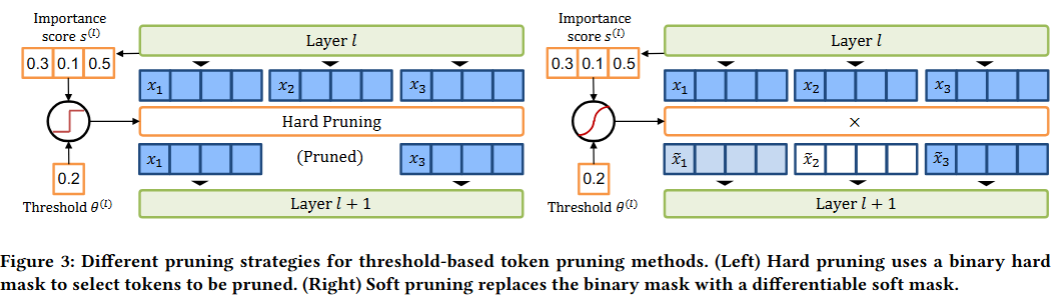
임계값을 기반으로 프루닝을 한다면, 레이어마다 어떻게 임계값을 학습(설정)할 것인지?
-
임계값을 학습하기 위해서는 현재 여러 문제점이 존재함
- 왼쪽 그림과 같이 현재는 0 또는 1으로 하드 마스킹을 함 → 미분 불가능한 마스킹 연산을 가짐
- 지워진 토큰(프루닝되어 제거된 토큰)에는 그레디언트가 흐르지 않음
-
해결법
- 학습 과정에서 소프트 마스킹 사용(시그모이드 함수 사용)
- 소프트 마스킹 출력이 0에 가까운 토큰은 다음 레이어에서도 중요도가 0에 가까운 값을 가짐
- → 하드 프루닝과 같은 효과 (연속적으로 프루닝됨)
-
수식
- 소프트 마스킹 함수
-
토큰 중요도와 임계값의 차를 T(온도)로 스케일링 및 시그모이드 함수 통과
-
T가 작을수록 계단함수와 같아져 하드 마스크에 가까워짐
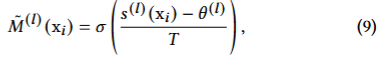
-
- 소프트 마스킹한 값을 레이어 출력과 곱
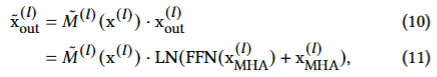
- 소프트 마스킹 함수
-
임계값 학습 방법

-
규제
-
임계값 학습시 모든 토큰을 유지하려는 경향이 생김 (모든 토큰을 남기는 것이 훈련 loss에 유리하기 때문)
-
L1 loss를 통해 pruning 비율을 높이는 항을 추가함
-
수식
-
가 클수록 더 많이 프루닝됨
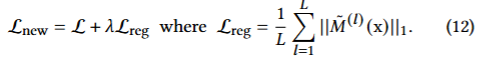
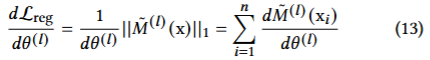
-
-
-
4. 실험
-
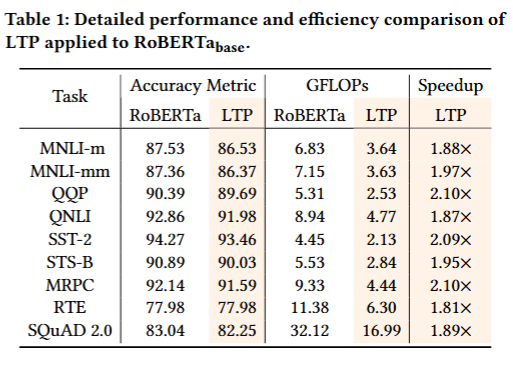
성능 평가 (모델: RoBERTa-base)
-
정확도가 1% 내외로 감소하지만, 1.8배 이상의 속도 향상
-
-
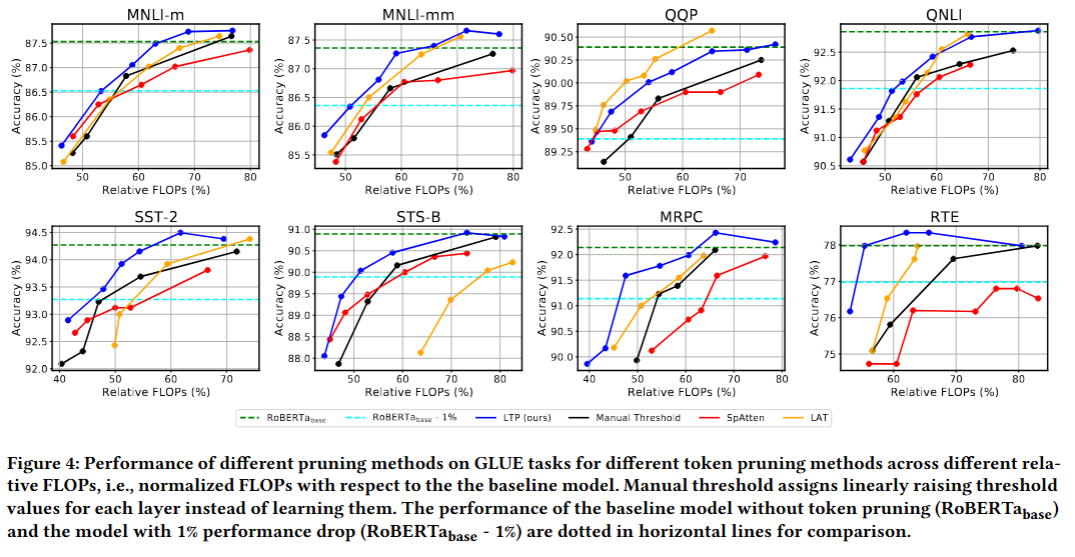
동일한 FLOPs 조건에서의 정확도 평가
-
대부분의 GLUE task에서 SpAtten, LAT 등의 기존 방법보다 높은 정확도 보임
-
QQP 데이터셋에 대해서는 상대적으로 낮은 정확도를 보임
-
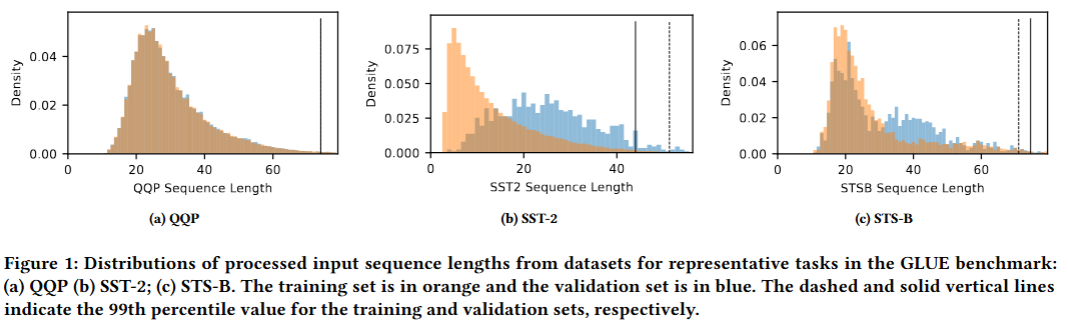
SST-2, STS-B 데이터셋과 같이 훈련, 평가 시퀀스 길이 분포 차이가 큰 경우는 LAT보다 월등한 성능
-
SQuAD 2.0 데이터셋(정답이 있거나 없는 질문)에서 프루닝 비율에 따른 성능 변화
-
프루닝 비율을 높임(FLOPs를 줄임)
- Has Ans 성능은 하락 (중요한 토큰이 잘려 정답의 위치를 못 찾음)
- No Ans 성능은 상승 (불필요한 토큰이 잘려 “답 없음”을 더 잘 예측)
- ⇒ 의 조절이 중요함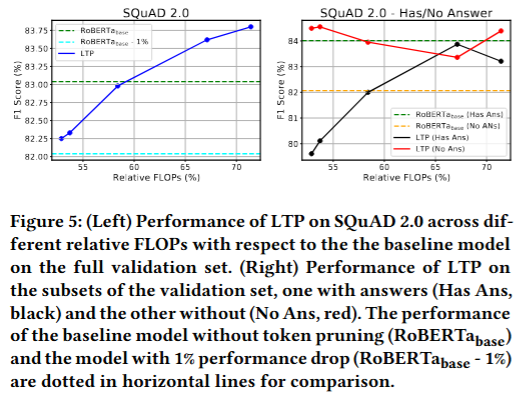
-
-
시퀀스 길이 변동 강건성
-
LAT는 과대 프루닝으로 인해 긴 문장에서 크게 정확도가 떨어지지만, LTP는 정확도가 유지됨
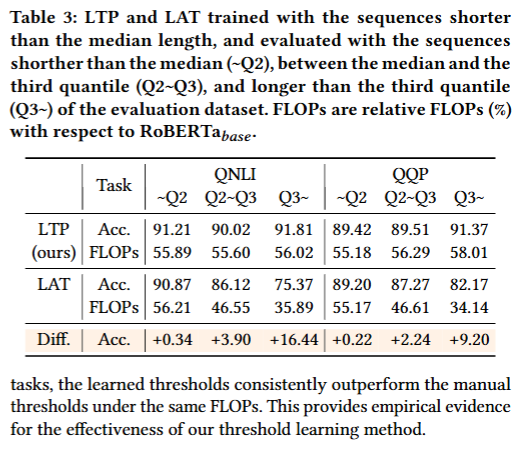
-
-
처리량 실험
-
배치 크기가 커질수록 LTP의 속도 향상이 더 커짐, 2배 정도 처리량 증가
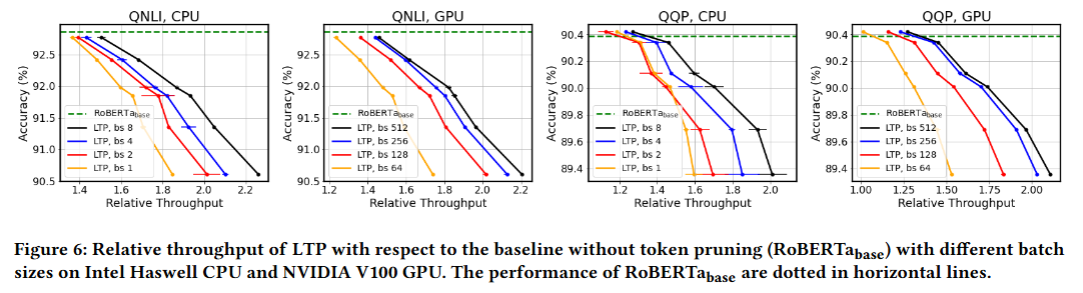
-
-
양자화 적용 실험
- INT8 양자화 적용시 4x BOPs 감
- 지식 증류도 같이 적용하면 10x BOPs 감소, 정확도 손실 2% 이하
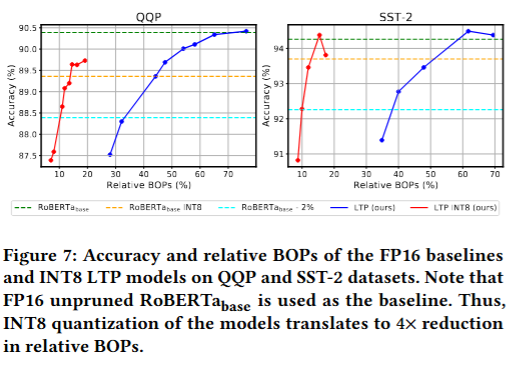
5. 결론
- 큰 추론 비용을 가진 Transformer 모델을 경량화하기 위해 토큰 프루닝 기법이 사용됨
- 기존 토큰 프루닝 기법들은 입력 길이의 변화에 취약하거나 속도가 느린 단점을 가짐
- 학습 가능한 임계값 기반의 토큰 프루닝 기법 LTP(Learned Token Pruning) 방법 제안
- 기존 토큰 프루닝 기법보다 높은 정확도, 빠른 속도를 보임, 특히 입력 길이가 다른 경우에도 안정적인 성능을 보임
