Digital Video
Basic Concepts
Colour Space 색공간
RGB
R,G,B 세가지 성분으로 색을 표현
각각 8bit 총 24bit
YCbCr
- Y: 휘도
- Cb: 파란색 성분
- Cr: 빨간색 성분
Human Visual System (HVS) 가 휘도에 민감하지만 색상에 덜 민감하다는 점을 이용해서 휘도를 색상보다 더 높은 해상도로 표현
(빛에 반응하는 간상세포가 색에 반응하는 원추세포보다 많기 때문)
ITU-R BT.601 상수를 사용한 RGB-YCbCr 변환
Y = 0.299R + 0.587G + 0.114BCb = 0.564(B - Y)
Cr = 0.713(R - Y)R = Y + 1.402Cr
B = Y + 1.772Cb
G = Y - 0.344Cb - 0.714CrChroma Subsampling 크로마 서브샘플링
J:x:y
J: 수평 샘플링 레퍼런스x: 첫번째 row 크로마 샘플 수 (수평 해상도)y:a픽셀의 첫 번째와 두 번째 row 사이의 크로마 샘플의 변화에 대한 개수
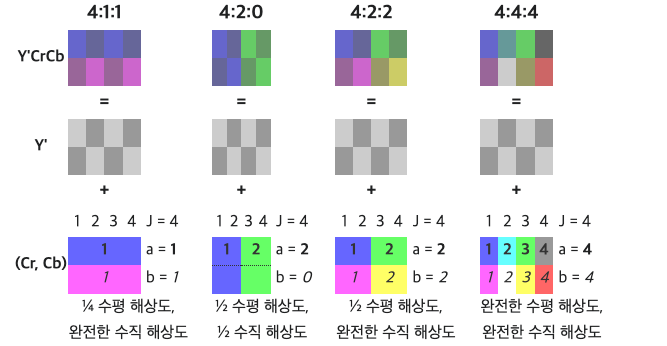
4:4:4가 픽셀 당 24비트를 소모하는 데 비해
4:2:0의 경우 픽셀 당 12비트이다 (절반)
Video Coding Concept
Video Codec
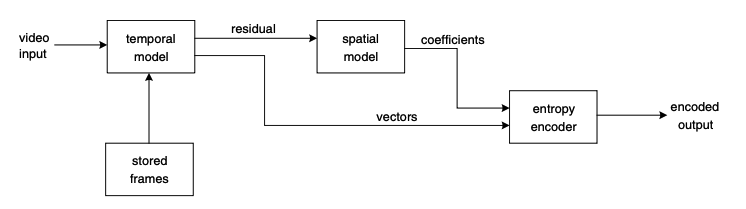
비디오 인코더는 세 가지 주요 기능 단위로 구성된다.
- temporal model
- 이웃한 프레임 간의 유사성을 활용하여 시간적 redundancy 줄이기
- 하나 이상의 과거, 미래 프레임으로부터 예측을 형성하고 프레임 간의 차이를 보상 motion compensated predict
- residual frame 과 모션 벡터 집합을 형성
- spatial model
- temporal model의 output인 residual 프레임을 인풋으로 사용
- 잔여 프레임의 이웃 샘플 간 유사성을 활용해 공간적 redundancy 줄이기
- residual 샘플에 transform을 적용하고 결과를 Quantizing
- entropy encoder
- statistical redundancy 제거 -> 자주 발생하는 벡터와 계수를 짧은 이진 코드로 표현
Temporal Model
예측 프레임을 형성하여 residual 프레임을 output으로
prediction이 정확할수록 용량을 줄일 수 있다
예측 프레임은 하나 이상의 reference 프레임으로부터 생성
Prediction from the Previous Video Frame
이전 프레임을 현재 프레임의 predictor로 사용
현재 프레임에서 predictor를 빼서 형성된 residual 프레임이 중간 회색에서 음수와 양수 의 차이를 각각 저장

여전히 residual 프레임에 에너지가 많이 남기 때문에 두 프레임 사이의 움직임을 compensate (보상) 하는 방식으로 더 나은 예측을 형성한다
Changes due to Motion
비디오 프레임 간 변화 = 프레임 간 픽셀 움직임
연속적인 비디오 프레임 간 픽셀 궤적을 trajectory(추정) 해서 optical flow 픽셀 궤적 필드를 생성
계산량이 많고 전송 데이터가 커 residual 프레임이 작아지는 것보다 오버헤드가 크다

Block-based Motion Estimation and Compensation
프레임의 직사각형 블록을 compensation, MxN 샘플로 구성된 각 블록에 대해
- reference frame에서 일치하는
MxN샘플 탐색- 현재 프레임의
MxN블록 근처의 블록들과 비교하면서 가장 비슷한 블록을 찾음 - 둘의 residual이 가장 작아지는 블록을 선택
- 현재 프레임의
- Motion Compensation
- 찾아낸 블록을 기반으로 prediction 생성
- 만든 예측 블록을 현재 블록에서 빼서 residual
MxN블록 형성
- Encoding and Transmission
- 계산한 residual 블록과 motion vector 전송
Motion Compensated Prediction of a Macroblock
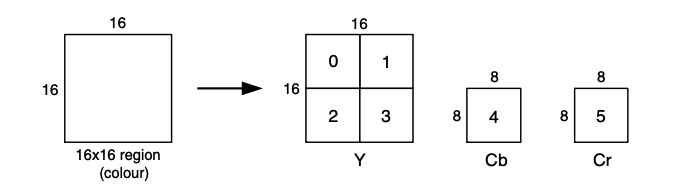
Macro Block: 16*16 픽셀 프레임, Cb, Cr은 8*8 샘플 블록으로 구성
Motion Estimation 모션 추정
- 현재 매크로 블럭에서 가장 비슷한
16x16샘플 영역을 이전 (reference) 프레임에서 탐색 - 현재 매크로 블럭 주변에서 후보군 중 best match를 고르고 매크로 블럭과의 residual만 압축
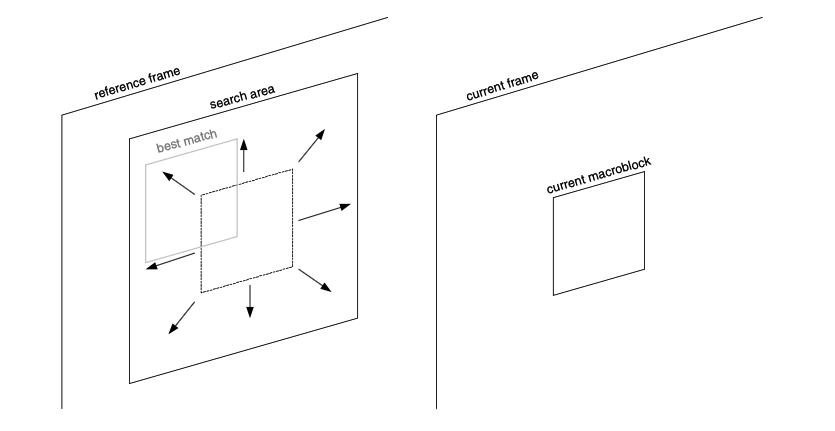
Motion Compensation 모션 보상
reference frame에서 선택한 best match이 현재 매크로 블록에서 빠지고 residual macroblock을 형성
residual macroblock과 best match 영역을 설명하는 motion vector들과 함께 인코딩되어 전송
encoding, decoding 시 동일한 reference frame 사용을 보장하기 위해 인코더는 전송한 residual 블록을 그대로 사용하여 다음 예측을 하는 게 아니라 residual 매크로블록을 다시 디코딩하여 사용
Motion Compensation Block Size
매크로 블록의 사이즈가 작아질수록 residual 에너지는 감소한다
대신 복잡성이 증가하고 전송해야 할 모션 벡터의 수가 늘어난다
H.264에서는 adaptive motion compensation block size를 사용하여 블록 크기를 유동적으로 바꿔가며 압축한다.
Sub-pixel Motion Compensation
reference 프레임의 interpolated (보간된) sample position에서의 예측으로 더 나은 compensated prediction을 형성할 수 있다
1개의 픽셀을 잘게 쪼개 보간하여 예측하면 residual 에너지 절약
vector 필드와 residual 필드 사이의 적절히 상충
Region-based Motion Compensation
자연 비디오 장면의 움직이는 객체는 불규칙한 모양을 가지고 있어 reference 프레임에서 좋은 일치를 찾기 어렵다
임의의 region에 대해 motion compensation을 수행하면 더 나은 성능
Image Model
이미지 또는 residual 데이터를 decorrelate (비상관화) 하고, 엔트로피 코더를 사용하여 효율적으로 압축가능한 형태로 변환
- Transformation
- 데이터를 비상관화, 압축
- 주파수 영역 등으로 변환 - Quantization
- 변환된 데이터의 정밀도 감소 - Reordering
- 중요한 값들을 함께 그룹화 (정렬)
Predictive Image Coding
한 프레임 안에서 주변 픽셀 정보를 이용해 다음 픽셀값을 예측
양자화 등 손실 압축 과정에서 손실이 발생하면 디코딩했을 때 픽셀이 원본과 불일치 할 수 있다
인코더와 디코더가 서로 다른 예측으로 오차가 쌓이는 drift현상 발생
=> 인코더는 자신이 Quantisation 하고 복원한 픽셀을 사용해서 예측을 수행해 drift를 방지한다
Transform Coding
이미지나 motion compensated residual 데이터를 다른 영역으로 변환
- 비상관화 및 압축: 변환 영역의 데이터는 상호 의존성이 최소화된 구성 요소로 분리
- 가역성: 다시 원래대로 되돌릴 수 있어야 한다
- 계산 용이성
변환의 종류에는 두 가지 범주
- Block-based transform
- Karhunen-Loeve Transform
- Singular Value Decomposition
- Discrete Cosaine Transform (DCT) - Image-based transform
- Discrete Wavelet Transform (DWT)
DCT와 DWT를 사용
DCT
NxN 크기의 샘플블록 X를 처리해서 NxN 크기 계수 블록 Y를 생성
Wavelet
블록 단위로 처리하는 DCT와 다르게, 필터링을 통해 이미지를 저주파와 고주파로 분리
Quantisation
Quantiser는 값의 범위가 X인 신호를 범위가 축소된 quantizing된 신호 Y로 매핑
- Scalar quantiser: 한 개의 값을 한 개의 값으로 줄이기
- Vector quantiser: 여러 개 값을 묶어서 한번에 줄이기
Scalar Quantisation
복잡한 변환 없이 하나의 숫자에 반올림이나 자르기 연산을 통해,
값을 규칙적인 간격으로 제한하는 단순한 방법
ex) 소수를 정수로 반올림
Uniform quantiser
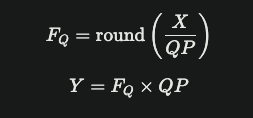
-
X: 원본 값 -
QP: 양자화 step size -
F_Q: 양자화 레벨 -
Y: 복원된 값 -
QP
- 크면 양자화된 값의 범위가 작아져서 더 압축
- 작을수록 원본 신호와 가까움
scalar quantiser에 두 종류가 있다.
- Linear Quantiser: 입력값과 출력값 사이에 선형적인 매핑
- Nonlinear Quantiser: 0 주변에 데드존으로 작은 입력값을 모두 0으로 매핑
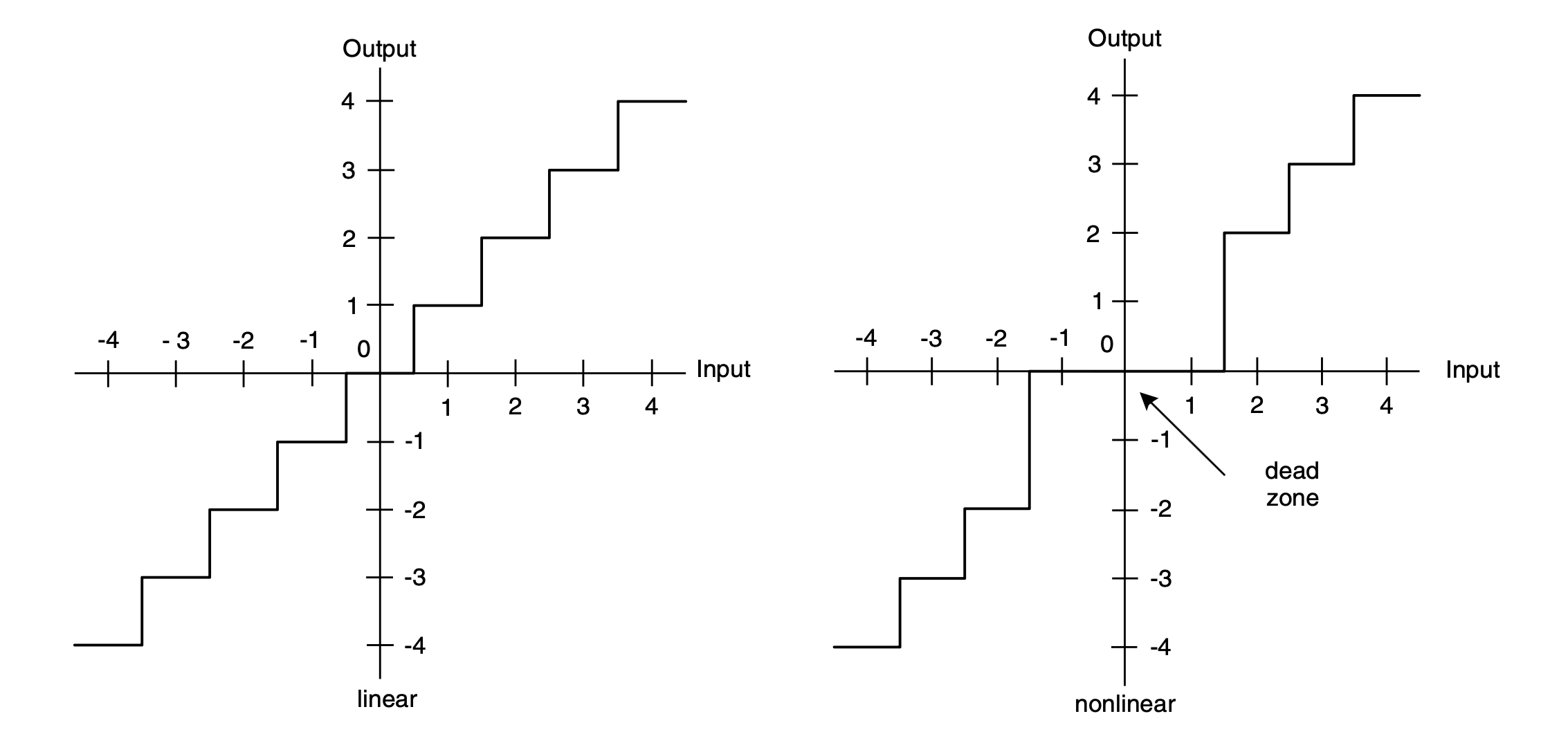
CODEC에서 quantizing 작업은 두 부분으로 구성된다
- FQ (Forward Quantiser)
- IQ (Inverse Quantiser)
Vector Quantisation
여러 값을 한번에 묶어 그룹 (블록, 벡터) 단위로 대표값으로 매핑
- 이미지를 작은 블록으로 나눈다
- Codebook 사전에 여러 대표 벡터 (Codeword) 가 미리 저장돼있음
- 원본 블록과 가장 비슷한 codeword를 codebook에서 고른다
- 고른 codeword의 index만 전송
- 디코더는 전달받은 index를 코드북에 대입해서 원본과 비슷한 블록을 꺼내어 복원
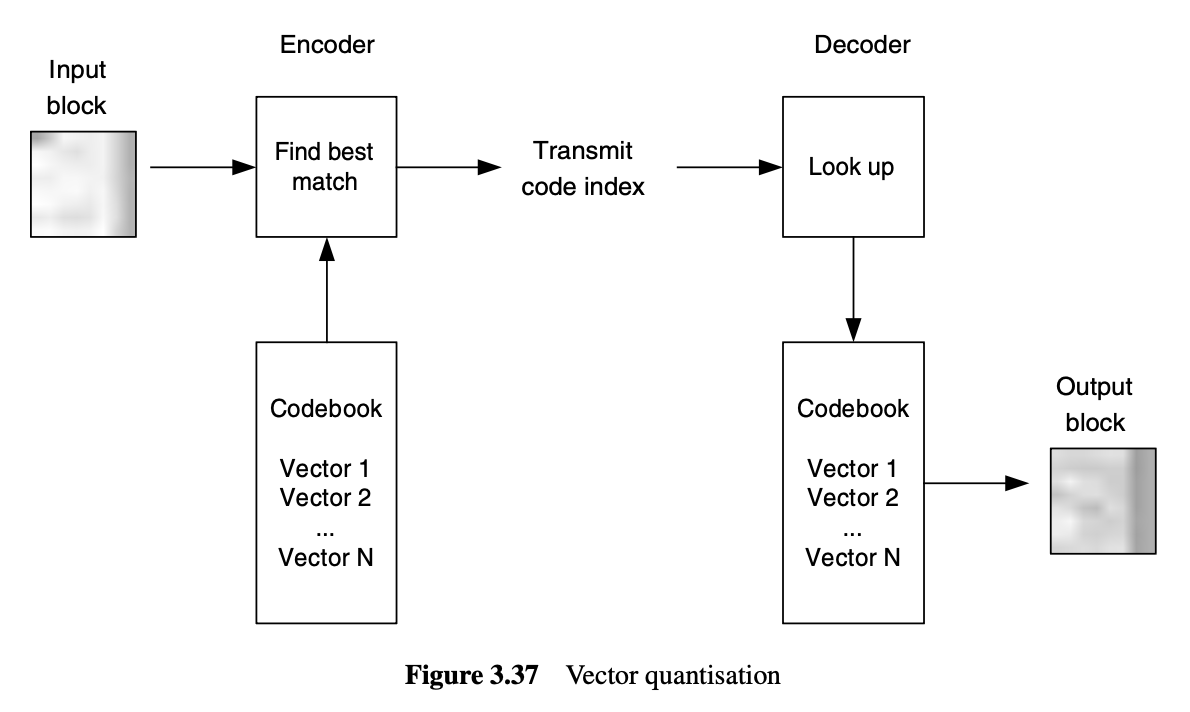
벡터 양자화가 스칼라 양자화보다 압축률이 높다
Reordering and Zero Encoding
Transformation과 Quantization이 끝난 후에는 대부분의 값이 0이고 의미 있는 값은 소수 -> 재배열을 통해 0이 아닌 정보 계수를 한쪽으로 몰아넣기
DCT
Coefficient Distribution
중요한 DCT rPtnsms DC 계수 주변의 저주파 위치에 있음
우측 하단으로 갈수록 중요한 정보가 줄어들고 0에 가까운 값이 많아짐
Scan
zigzag 순서로 스캔을 통해 DC 계수부터 시작하여 각 계수가 1차원 배열로 복사된다.
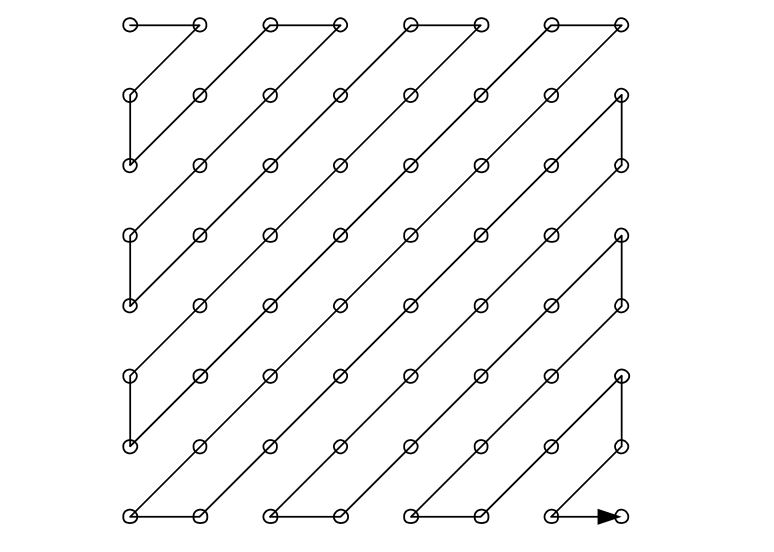
Run-Level Encoding
스캔 이후의 배열은 0이 아닌 계수 뒤에 0이 쭉 이어지는 구조 -> 0을 일일이 하나씩 저장하지 말고 0이 연속으로 몇 개 나오는지를 저장
- 2차원 Run-level encoding
Input: 16,0,0,−3,5,6,0,0,0,0,−7, ...
Output: (0,16),(2,−3),(0,5),(0,6),(4,−7) ...- 3차원 Run-level encoding
Output: (0,16,0),(2,-3,0),(0,5,0),(0,6,0),(4,-7,1)3차원 예시에서 마지막 1은 해당 계수가 블록의 마지막 0이 아닌 계수임을 나타냄 (이 뒤로 0밖에 없음)
Wavelet
Coefficient Distribution
웨이블릿 변환 시 LL, HL, LH, HH 의 sub-bands 가 생기고
상위 sub-band 에는 전체 구조나 배경 등 주요 정보가 들어있고 하위로 갈수록 0에 가까운 정보만 남는다
중요 정보는 비슷한 위치에 계층적으로 이어지기 때문에, 트리 구조로 모델링 할 수 있음
Zerotree Encoding
루트부터 시작하여 계수가 0이면 거기서 뻗어나가는 다른 자식도 0일 가능성이 높다
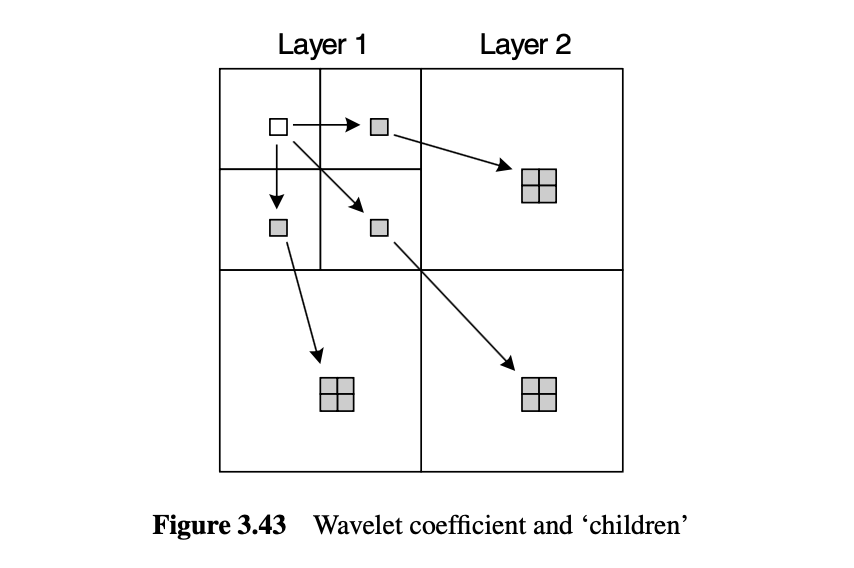
- 루트 계수부터 시작하여
- 0이 아니면 값을 기록
- 0이면 아래 자식도 확인하여 모두 0이면 제로트리임을 표시
- 트리 구조 따라 이동하며 같은 방식으로 체크
Entropy Coder
영상 데이터를 숫자나 기호 단위로 쪼개고 정보의 빈도가 높을수록 짧은 비트로, 낮을수록 긴 비트로 바꿔서 전체 비트를 압축
엔트로피 코더로 다음을 처리한다
- quantizing된 transform 계수
- 모션 벡터
- 마커, 헤더
- 부가 정보
Predictive Coding
이미지나 영상의 이웃한 데이터 (블록, 벡터)는 서로 비슷한 경우가 많다
현재 블록의 요소를 이전의 인코딩된 데이터로부터 예측하고, 예측값과 실제 값이 차이를 인코딩하여 효율 향상
- Motion vector predcition
- 이 전에 인코딩된 프레임의 prediction reference에 대한 오프셋을 나타냄
- 블록의 크기가 작거나 움직이는 객체가 클 때
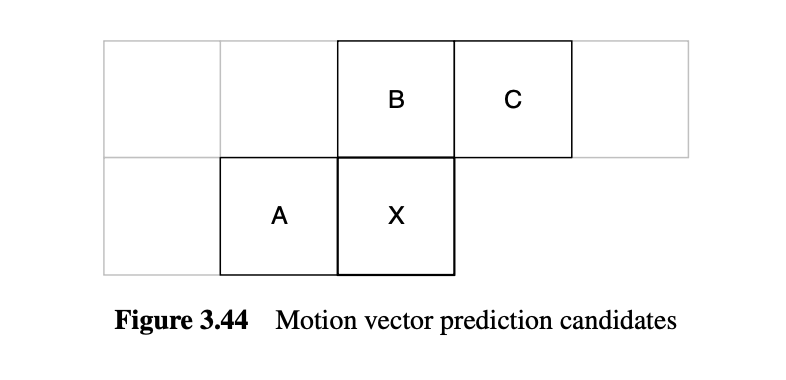
- Quantisation parmeter (QP) prediction
QP 값을 통째로 보내는 대신 델타값을 전송하여 더 적은 비트를 사용
Variable-length Coding (VLC)
- 자주 발생하는 심볼은 짧게 표현
- 덜 발생하는 심볼은 길게 표현
Huffman Coding
- 각 심볼의 등장 빈도 계산
- 허프만 트리 만들기
- 부호 할당
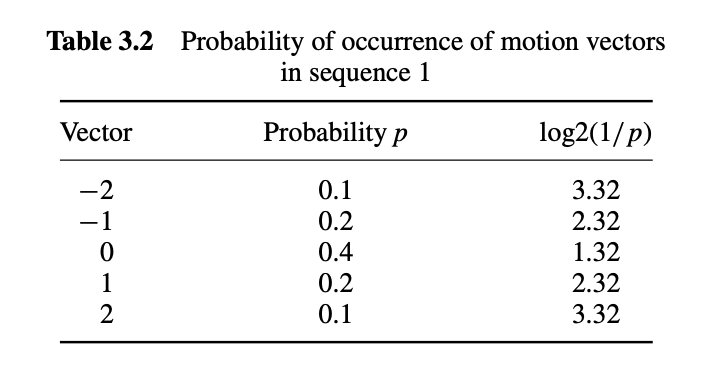
- 등작 확률이 낮은 것부터 나열
- 가장 확률이 작은 두 개를 합쳐서 하나의 노드로 만들고 둘의 함계 확률을 그 노드에 할당
- 확률 순으로 정렬해서 두 개 합치고를 반복
Pre-calculated Huffman-based Coding
기존 허프만 코딩은 문제가 있음
- 인코더와 디코더가 동일한 허프만 코드 테이블을 사용해야 함
- 코드 테이블을 전송하는 게 오버헤드
- 최적의 허프만 트리를 만들려면 전체 등장 확률을 미리 알아야 함
해결책으로 미리 표준화 한 VLC 테이블 사용
인코더와 디코더 모두 같은 표준 테이블을 알고 있으므로 별도로 전송할 필요가 없고, 실시간 영상도 즉시 압축하고 복원하는 게 가능
Transform Coefficient (TCOEF)
MPEG-4에서는 각 quantised coefficient를 (run, level, last) 값 조합으로 표현
- run: 0이 몇번 연속으로 나왔는지
- level: 0다음에 나오는 실제 계수
- last: 블록의 마지막 0이 아닌 값 플래그
자주 나오는 (run, level, last) 조합 102개에 대해
각각 3차원 VLC 코드 할당

표에 없는 조합은 ESCAPE를 먼저 출력하고 고정 길이 코드로 상세 정보 기록
Motion Vector Difference (MVD)
Motion Vector : 블록이 프레임 내에서 얼마나 움직였는가
실제 모션 벡터 값이 아니라 예측된 모션 벡터와의 차이값만 전송
- 각 MVD x, y 성분은 따로 VLC로 변환
0이 가장 자주 나오므로 짧게 표현
Pre-calculated VLC 테이블을 사용하여 표준화

Other VLCs
-
허프만 기반 VLC의 한계
- 비트 스트림 중간에 에러가 생기면 해석이 꼬인다
- 사전에 정해진 코드테이블을 인코더 디코더 모두 holding -
RVLC
- 비트 스트림을 순방향, 역방향 모두 해독 가능
- 중간에 에러 났을 때, 끝에서 해독하면 뒷부분은 살림 -
코드 테이블의 한계와 대안
- On-the-fly 자동 생성 가능한 코드
- Golomb 코드, Exp-Golomb코드 등은 입력값만 알면 코드를 즉석에서 산출 가능
Arithmetic Coding
데이터 심볼 시퀀스(열)을 하나의 소수로 변화
example
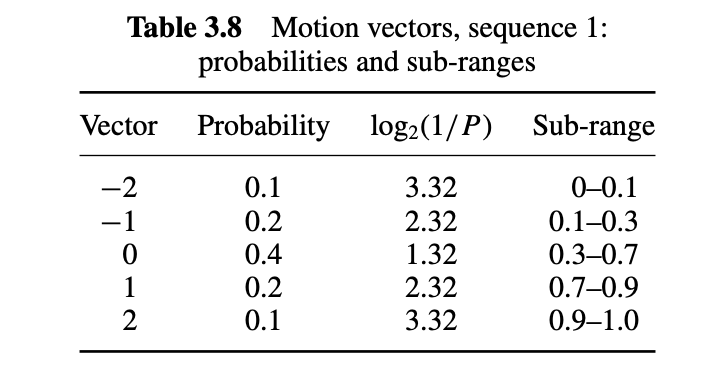
위 표에서 모션 벡터 다섯개마다 등장 확률이 다른데
확률이 높은 값일수록 더 넓은 구간을 할당
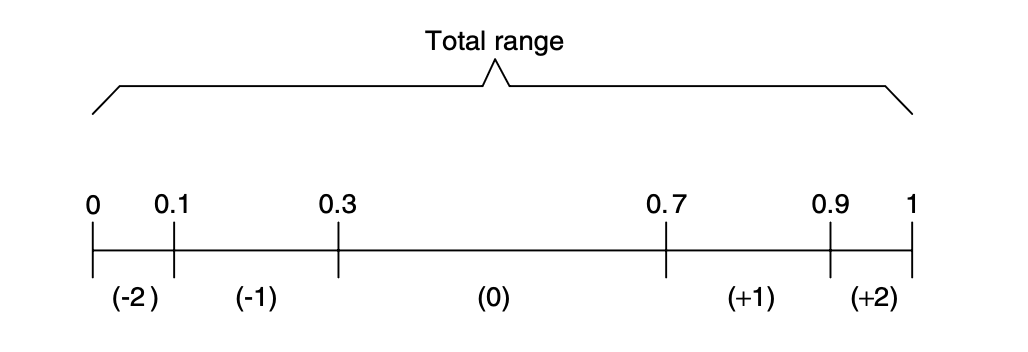
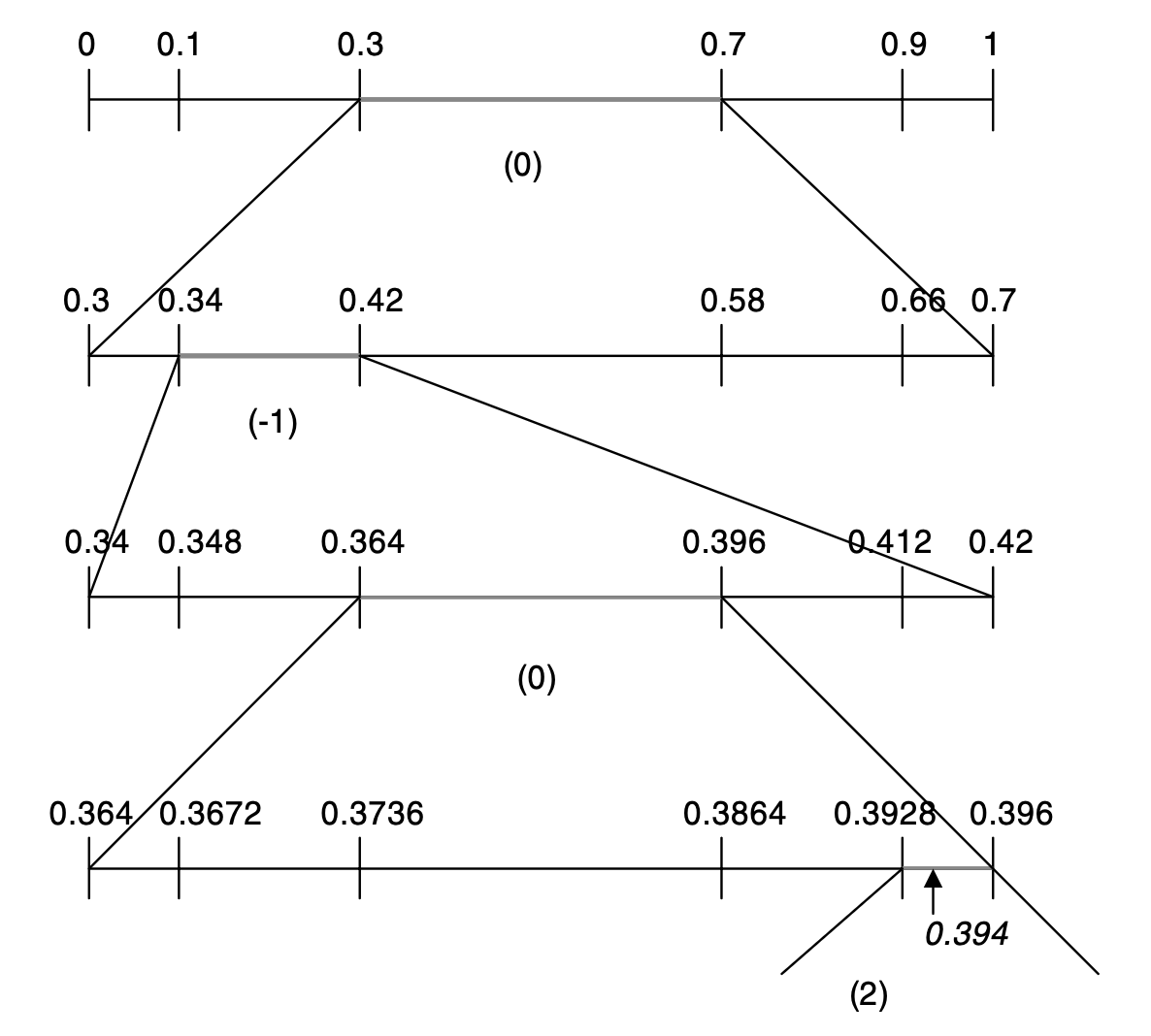
심볼이 0, -1, 0, 2 순서로 등장할 때,
0: 전체 범위를 0.3~0.7-1: -1의 범위는 전체의 0.1~0.3 이므로 0.3~0.7의 sub-range 0.34~0.420: 0.34~0.42의 0.3~0.7 구간인 0.364~0.396 선택2: 0.364~0.396의 0.9~1.0 구간인 0.3928~0.396 선택
산술 부호화는 데이터 시퀀스를 실수 하나로 압축 가능
허프만 코딩은 각 데이터마다 항상 정수 비트만 쓸 수 있지만
산술 부호화는 소수점 단위로 비트를 최적으로 사용
Context-based Arithmetic Coding
매 순간 심볼을 코드화할 때
주변 상태(context)로 이번 심볼의 등장 확률을 측정
- CABAC (Context-Adaptive Binary Arithmetic Coding)
- 주변 비트, transform coef, 움직임 상황 등 문맥에 따라 각각 다른 확률 모델 적용 -> 압축 효율 극대화
The Hybrid DPCM/DCT Video Codec Model
- DPCM (Differential Pulse Code Modulation)
- 프레임 간 모션 추정
- 과거 프레임과 비교해 차이만 계산해서 압축 - DCT
- 남은 오차를 주파수 영역으로 변환해 고주파 버리고 압축
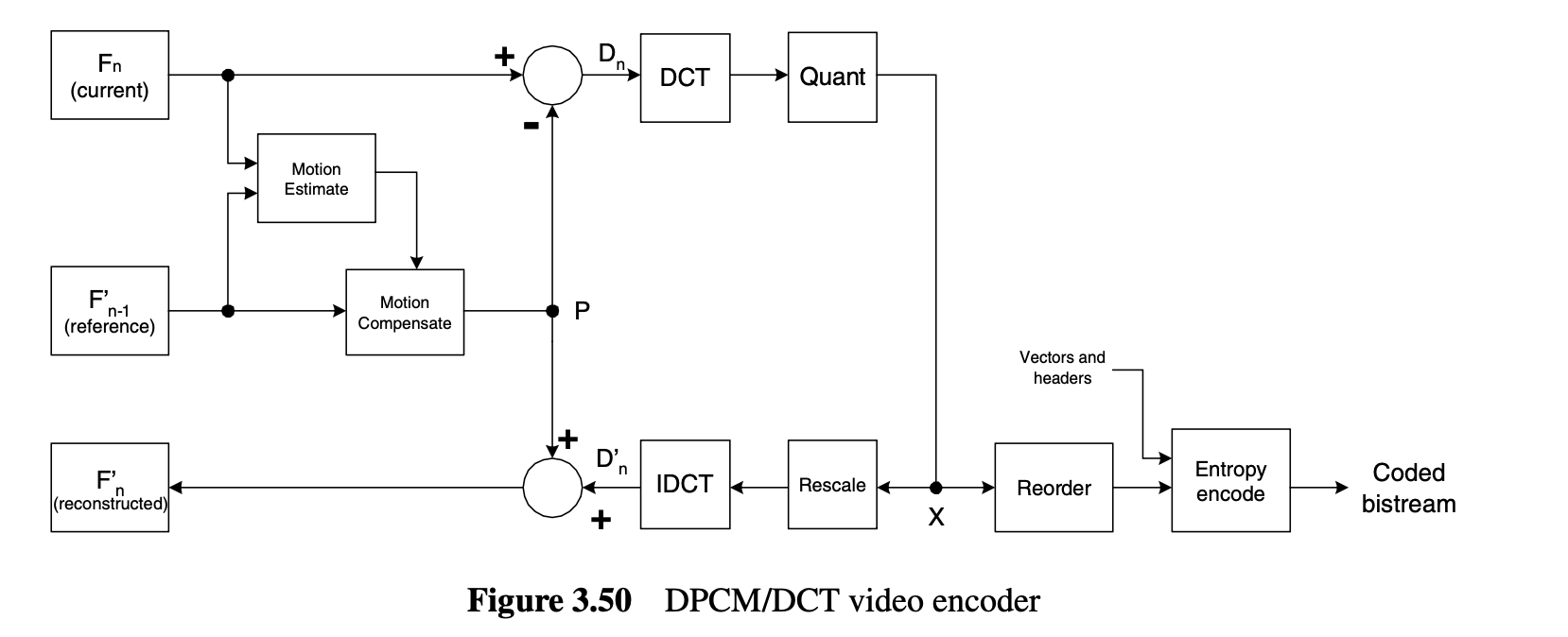
Encoder Data Flow
-
입력 프레임 분할
- 입력 영상을 매크로블록(기본
16x16) 단위로 분해
- 입력 영상을 매크로블록(기본
-
Reference 프레임 비교 (Motion Estimation)
- 다른 프레임과 매크로 블록을 비교
- 현재 블록과 가장 비슷한
16x16혹은 interpolated 영역을 찾아 - 블록 위치 차이 Motion Vector (MV) 로 기록
-
Motion Compensated Prediction
- MV로 지정된 영역이 예측 블록 (P)이 된다
-
예측 residual 계산
- 현재 블록 - P = 오차 블록(D)
-
DCT
- residual D를 다시 소블록 (
8x8,4x4) 로 쪼개서 - 각 소블록에 DCT 적용
- residual D를 다시 소블록 (
-
Quantization
- transform coefficient의 정밀도 줄이기
-
Reordering & Run-level Encoding
- zigzag 스캔 등으로 정렬
- 0이 연속되는 구간을 Run-level Coding으로 변환
-
Entropy coding
- Coefficients, MV, header 등 정보를 등장 빈도에 따라 인코딩
- 최종 비트스트림 생성
Reconstruction Data Flow
-
역양자화 & IDCT
- 양자화된 값 X를 되돌려서
D'로 - 손실이 있으므로
D와D'는 같지 않다
- 양자화된 값 X를 되돌려서
-
에측 블록과 합쳐 프레임을 복원
- 복원된
D'와 에측블록P를 합쳐서 복원 프레임 완성
- 복원된
-
참조용으로 복원된 프레임 저장
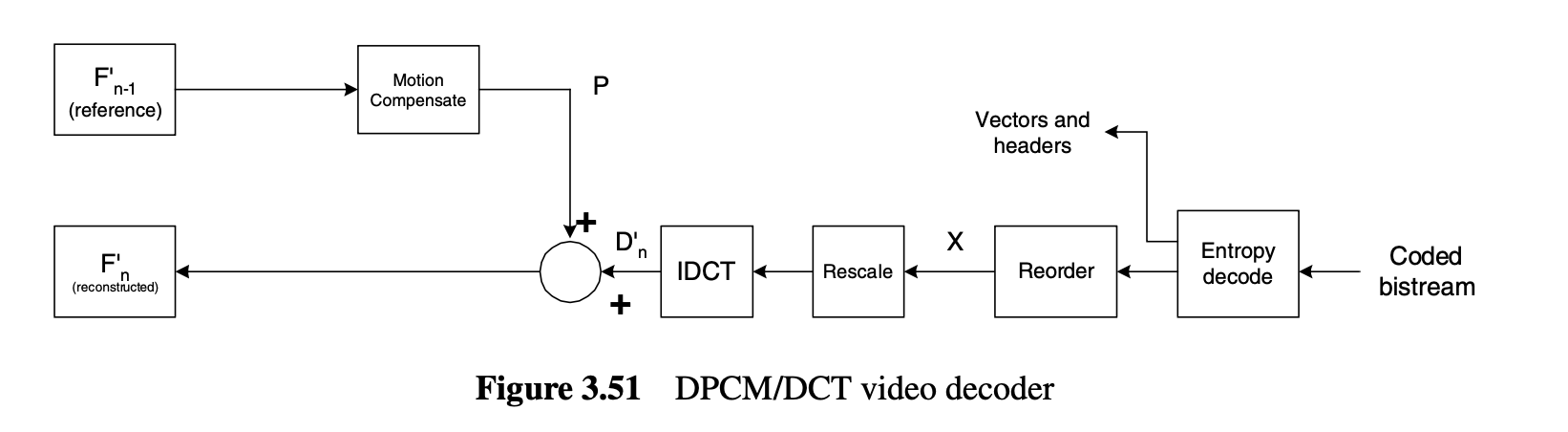
Decoder Data Flow
-
엔트로피 디코딩
- 비트 스트림에서 DCT 계수, 모션 벡터, 헤더 등을 기존 부호표로 복원
-
inverse Run-level/Reorderling
- 양자화된 변환 블록 X 복원
-
역양자화, IDCT
- X를 원래 값으로 rescale(역양자화)
- IDCT 적용해서
D'생성
-
Motion Compensated Prediction
- 복원된 MV로 디코더 자신이 저장해둔 reference 프레임에서 16ㅌ16 영역을 찾아서 예측 블록 P로 삼음
-
복원 블록 생성
P에서D'를 더해서 재구성 매크로 블록 완성
-
프레임 합성 및 reference 프레임 저장
Bit Stream
H.264 Bitstream 구조
