
A Survey of Quantization Methods for Efficient Neural Network Inference
Survey of Quantization에 대한 내용
Abstract
continuous한 real-value 숫자들을 discreted한 숫자 집합에 분배하는 방식을 어떻게 설계해야 최소한의 bit 수로 요구를 충족시키면서도 computation accuracy를 최대화할 수 있을까?'에 대한 내용이다.
이러한 quantization 문제는 memory / computation resource가 심각하게 제한된 경우 중요하다.
1. Introduction
NNs의 accuracy가 크게 개선되었다. 이러한 accuracy 향상은 종종 over-parameterized된 대규모 model을 통해 이루어졌다.
==>
resource가 제한된 많은 응용 환경에서는 이를 배포할 수 없음
위 문제의 해결법
a) Designing efficient NN model architectures
NN model의 micro-architecture 또는 macro-architecture의 optimization에 중점을 둔 연구.
즉, model size, depth, width 등의 주어진 제약 조건 내에서 적합한 NN architecture를 자동으로 찾기위해 AutoML 및 방법을 설계하는 연구이다. 즉, NAS(Nureal Architecture Search).
b) Co-designing NN architecture and hardware together
특정 대상 hardware paltform에 NN architecture를 적응시키고 co-design하는 것.
이는 NN 구성 요소(latency, energy)에 따른 overhead는 hardware-dependent하기 때문이다.
예를들어, 전용 cache hierarchy를 가진 HW는 그런 hierarchy가 없는 HW에 비해 bandwidth 의존적인 연산을 훨씬 효율적으로 실행할 수 있다.
c) Pruning
saliency(중요도)가 낮은 뉴런을 제거하여 spare computational graph를 만드는 것.
// saliency가 낮은 뉴런은 제거하더라도 model 출력이나 loss function에 최소한의 영향을 미치는 뉴런이다.
unstructured pruning
saliency가 낮은 뉴런을 위치에 관계없이 제거하는 것.
대부분의 뉴런을 aggressive하게 pruning할 수 있다.
그러나 이방식은 sparse matrix operation을 초래하며, 이러한 operation은 accelerate하기 어렵고, 일반적으로 memory-bounded하다.
Q1. 왜 sparse matrix operation은 accelerate 하기 어렵고, 일반저으로 memory-bounded한가?
A1.

structured pruning
saliency가 낮은 뉴런을 위치에 관계없이 제거하는 것이 아닌, 특정 parameter group(ex) entire convolutional filters)을 제거하는 것.
이는 layer과 weight matrix의 input, output 형상을 변경하게 되어, 여전히 dense한 matrix operation을 허용한다.
d) Kenowledge distillation
큰 모델을 training 한 후 이를 teacher model로 사용하여 더 간결한(student) model을 training하는 과정을 포함한다.
student model을 training할 때 "hard" class label 대신, teacher model이 생성한 "soft probability"를 활용한다. 이 확률은 input에 대한 더 많은 정보를 포함할 수 있다.
distillation은 다른 quantization, pruning에 비해, 공격적인 compression시 꽤나 큰 accuracy loss를 겪는 경향이 있다.
e) Quantization
Quantization은 NN model의 training, inference에서 모두 뛰어나고 일관된 성공을 보여준 접근법이다.
특히, half-precision and mixed-precision training의 돌파구는 AI accelerator에서 한 차원 높은 troughput을 가능하게 하는 주요 동력으로 작용했다. 그러나 half-precision 이하로 내려가는 것은 상당한 tuning 없이는 매우 어렵다는 것이 증명되었으며, 최근 quantization 연구의 대부분은 inference에 초점을 맞추고 있다.
2. General History Of Quantization
Quantization은 큰 집합의 input 값을 작은 집합의 outpur 값으로 매핑하는 방법으로, 오랜 역사를 가지고 있다. 반올림과 truncation은 전형적인 예이다
A) Quantization in Neural Nets
NN은 quantization 문제에 독특한 도전과 기회를 제공한다.
1. NN의 inference와 trainin은 모두 computationally intensive하여, 수치 값을 효율적으로 표현하는 것이 특히 중요하다.
2. 현재의 NN은 over-parameterized 되어 있어, accuracy에 영향을 미치지 않고, bit precision을 줄일 수 있는 충분한 여지가 있다.
3. NN은 공격적인 quantization과 극단적인 discretization에 매우 robust하다. 이러한 강인성은 NN이 가진 parameter 수에 따른 새로운 자유도를 제공한다.
4. NN의 서로 다른 layer는 loss function에 대해 다른 영향을 미치며, 이는 quantization에 대한 mixed-precision 접근 방식을 고무한다.
3. Basic Concepts Of Quantization
A. Problem Setup and Notations
NN이 학습 가능한 매개변수 을 가지는 개의 layer로 구성되어 있다고 가정하자. 이때, 모든 parameter의 조합을 로 나타낸다. WLOG, supervised learning problem에 초점을 맞추며, 이 문제의 명목적인 목표는 다음의 empirical risk minimization 함수를 최적화하는 것이다.
: input data와 이에 해당하는 label
:loss function
: 전체 데이터 포인트의 수
: 번째 layer의 input hidden activation
: 번째 layer의 output hidden activation
학습된 model parameter 가 fp precision으로 저장되어 있음.
Quantization의 목표는 parameter 뿐만 아니라 intermediate activation map(즉, )의 precision을 낮은 precision으로 줄이면서도 model의 일반화 능력 및 accuracy에 미치는 영향을 최소화 하는 것이다.
B. Uniform Quantization
NN의 weight와 activation을 유한한 값 집합으로 quantization 할 수 있는 함수를 정의해야한다.
==> real value 값을 input으로 받아, 이를 낮은 precision의 범위로 매핑한다. 아래 Figure 1에서 이를 시각적으로 설명하고 있다.

널리 사용되는 양자화 함수는 다음과 같이 정의된다.
: quantization operator
: real value
: 실수형 scaling factor
: 정수형 zero point
: 실수 값을 정수 값으로 매핑
Q1. 위 식(2)의 quantization은 위 Figure 1의 uniform quant인가? 아니면 non-uniform quant인가?
A1.
함수는 실수 r을 정수 값 집합으로 매핑하는 방법이다. 이러한 양자화 방식은 결과적으로 생성된 양자화 값(즉, 양자화 수준)이 균일하게 간격을 이루기 때문에 균일 양자화(uniform quantization)로도 알려져 있다(Figure 1, 왼쪽).
그렇다면 non-uniform quantization은? III-F에서 다룰 것.
quantized된 에서 실수 r을 복원할 수 있는 연산을 dequantization이라고 하고 이는 다음과 같다.
Q2. 여기서 복원된 실수 값 은 과 왜 다를까?
A2.
quantizing 과정에서의 precision loss로 인해서
C. Symmetric and Asymmetric Quantization
uniform quantization에서 중요한 요소 中 하나는 식(2)에서 사용되는 Scaling factor 이다.
scaling factor는 주어진 실수 값 r의 범위를 여러 개의 구간으로 나누는 역할을 한다. (즉, 얼마나 잘게 나눌까?의 문제)
scaling factor는 다음과 같이 정의된다.
: clipping range로 실수 값을 제한하는 유한한 범위를 나타낸다.
: quantization bit width
따라서, scaling factor를 정의하려면, 먼저 clipping range를 결정해야한다. 이 과정을 calibration이라고 한다.
Clipping range 선택
- 기본 접근접 : input의 min,max를 clipping range로 선택하는 것(). 이 접근법은 asymmetric quantization 방식으로 clipping range가 원점에 대해 대칭적이지 않을 수 있다. (). 이는 아래 Figure 2(오른쪽)에 설명되어 있다.
- symmetric quantization : symmetric한 clipping range를 사용하여, 로 설정한다. 일반적인 선택은 input의 min,max를 기반으로 으로 설정하는 것이다. asymmetric quant는 symmetric quant보다 더 좁은 clipping range를 제공하며, 이는 ReLU이후 activation 처럼 항상 양수인 데이터에 유리하다.
Q3. asymmetric quant의 경우 왜 symmetric quant보다 더 좁은 clipping range를 제공하는가? 또한 ReLU 이후 activation 처럼 항상 양수인 데이터에 왜 유리한가?
A3.
input의 range가 [-2.435, 162.624]이라고 하자.
symmetric quant의 clipping range : [-162.624, 162.624]
asymmetric quant의 clipping range : [-2.435, 162.624]
==> asymmetric이 더 좁음
==> 더 좁은 범위를 자르네?
==> 더 잘게 자른다는 거네?
==> quantizing 이후 값이 상대적으로 더 정확하다는 거네?
==> ReLU이후 activation은 결국 양수니까 양수의 범위에서 더 잘게 짜를 수 있는 asymmetric이 더 유리하네!
symmetric quant를 사용할 경우
영점을 식(2)에서 Z를 제거하여 식이 단순화된다.
symmetric quant의 scaling factor 선택
-
full range : 로 설정하여 INT8의 전체 범위([-128,127])를 사용한다.
-
restricted range : 로 설정하여 범위를 [-127,127]로 제한한다.
- 정확도 : full range의 경우가 더 정확하다.
symmetric quant의 실제 적용
-
weight quant : symmetric quant는 주로 weigt를 quantizing 하는 데 사용된다. 이는 zero-point를 0으로 설정하면 inference 중 computatino cost를 줄일 수 있고, 구현이 간단해지기 때문이다.
-
activation quant : asymmetric한 activation으로 인해 발생하는 offset cross terms는 데이터에 독립적인 static term으로 간주되며, bias에 흡수되거나 accumulator를 초기화하는 데 사용할 수 있다.
이렇게 min,max를 symmetric, asymmetric quant 모두에서 사용하는 것은 널리 사용되는 방법이다. 그러나 이 접근법은 activation에서의 outlier에 민감하다. 이러한 outlier는 불필요하게 범위를 증가시켜 quantization resolution(해상도)를 낮춘다.
이를 해결하기 위한 한 가지 방법은 input의 min,max 대신 percentile을 사용하는 것이다. 즉, min,max 대신 i번째로 작은, 큰 값을 로 사용한다.
또 다른 방법은 , KL divergence (Kullback-Leibler divergence) 즉 실제 값과 quantized된 값 간의 정보 손실을 최소화하도록 를 선택하는 것이다.
Summary (Symmetric vs Asymmetric Quantization)
symmetric quant는 clipping range를 대칭적으로 분할한다. 이는 구현이 더 쉬워지는 장점이 있으며, 식 (2)에서 Z가 0이 되기 때문이다.
그러나 범위가 비대칭적으로 skewed된 경우에는 최적의 선택이 아니다. 이러한 경우에는 asymmetric quant가 선호된다.
D. Range Calibration Algorithms : Static vs Dynamic Quantization
Clipping range가 언제 결정되는가의 문제.
Weight : inference시 parameter는 대부분 고정되어 있어, static하게 결정됨
Activation : input sample에 따라 activation map이 달라서, activation을 quant하는데 dynamic, static 두가지 접근 방식이 쓰인다.
Dynamic에서는 clipping range를 run-time 동안 각 activation map에 대해 dynamic하게 계산한다. 이는 real-time으로 signal statistics (min, max, percentile, etc.)를 계산해야 하기에 overhead가 높다. 하지만 input 별로 signal 범위를 정확히 계산하므로 더 높은 accuracy를 갖는다.
Static에서는 clipping range를 pre-calculate 하고, inference 동안 고정한다. pre-calculate에 자주 사용되는 방법 중 하나는 일련의 calibration input을 넣어봐서 activation의 일반적인 범위를 계산하는 것이다.
그 계산법에는 다음과 같은 계산법들이 있다.
- unquantized된 weight의 분포와 해당 quantized된 값 간의 MSE(Mean Squared Error)를 최소화하는 방법
- entropy
- NN training 중에 clipping range를 training하거나 impose하는 방법(LQNets, PACT, LSQ, LSQ+, etc.)
Summary (Dynamic vs Static Quantization)
Dynamic quant는 각 activation의 clipping range를 dynamic하게 계산하며, 일반적으로 가장 높은 accuracy를 달성한다. 그러나 signal 범위를 동적으로 계산하는 것은 비용이 매우 높아 실무에서는 대부분 모든 입력에 대해 고정된 clipping range를 사용하는 static quant를 선택한다.
E. Quantization Granularity
CV 작업에서 한 layer의 activation input은 여러 다른 convolution filter와 함께 convolved된다(아래 Figure 3 참고). 이때 filter마다 값의 분포와 범위가 다를 수 있따. 따라서 quantization시 weight clipping range가 계산되는 범위(Granularity)가 중요하다. 이는 주로 Layerwise quant, Channelwise quant로 나뉘며, 각 방식은 quantization resolution, accuracy에 영향을 미친다.
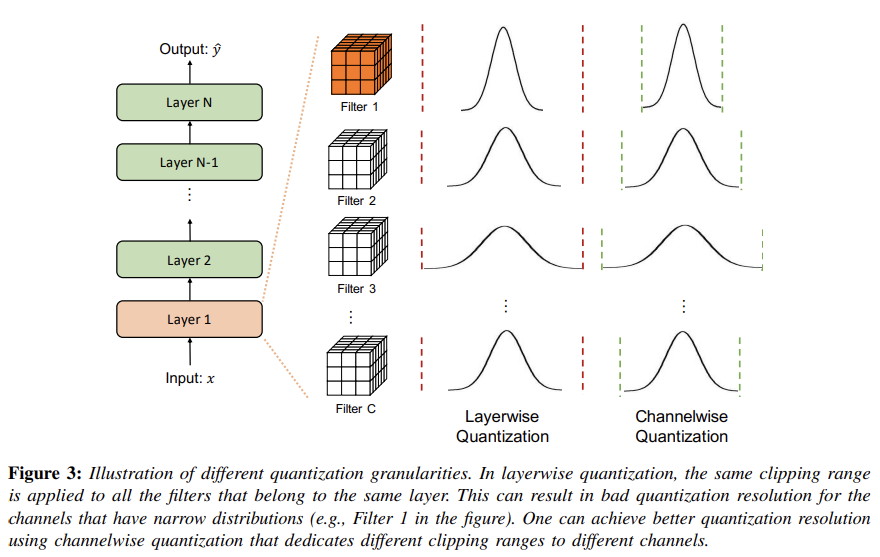
a) Layerwise Quantization
한 layer의 filter 전체 weight를 고려하여 clipping range를 결정(Figure 3을 보면 빨간색 점선, 초록색 점선의 폭이 다름을 볼 수 있음). layer내 모든 parameter 통계(min, max, percentile, etc.)를 분석한 후, 동일한 clipping range를 layer의 모든 conv filter에 적용하는 것.
But
각 conv filter 마다 범위가 크게 다를 수 있어, 최적의 accuracy를 달성하지 못함
그니까 쉽게 말해서, Layerwise는 Figure 3의 Filter 1 ~ Filter C 까지의 모든 filter에 대해 paramter 통계를 내고, 그 통계 하나를 가지고, 모든 conv filter에 동일한 clipping range를 적용하는 것.
예를 들어, 상대적으로 좁은 범위의 parameter를 가진 conv kernel(filter)은 동일 layer 내 넓은 범위를 가진 kernel 때문에 quantization resolution이 손실될 수 있다.
b) Groupwise Quantization
layer내 여러 channel을 그룹화하여 clipping range를 계산하는 것(activation이나 conv kernel 모두 가능). 이는 하나의 conv 또는 activation 내에서 parameter 분포가 크게 달라지는 경우에 유용하다. 예를들어, Transformer의
fully-connected attention layer를 quantize하는데 Q-BERT에서 이 방법이 유용함을 발견함. 그러나 당연히 이 방법은 서로 다른 scaling factor를 처리해야한다.
c) Channelwise Quantization
다른 channel과 독립적으로 각 conv filter에 고정된 값을 사용하는 방식. 즉, 각 channel마다 전용 scaling factor를 할당한다.
d) sub-channelwise Quantization
channelwise quant를 더욱 세분화하여 conv 또는 fc layer 내의 모든 parameter 그룹에 대해 clipping range를 결정하는 것.
Summary (Quantization Granularity)
channelwise quantiztaion은 현재 conv kernel을 quantize하는 표준 방법. 이는 각 개별 kernel에 대해 clipping range를 조정할 수 있도록 하면서도 무시할 만한 수준의 overhead만 발생.
F. Non-Uniform Quantization
quantization step, quantization level이 균등하게 분포되지 않는 방식.
Non-Uniform Quant의 정의는 다음(식 6)과 같다.
: discrete quantization level
: quantization step (threshold)
실수 r의 값이 quantzation step 와 사이에 위치하면, quantizer Q는 quantization level 에 매핑된다. 이때, 와 는 모두 non-uniform하게 분포한다.
Non-Uniform Quant의 특징
-
고정된 bit-width에서 더 높은 accuracy를 달성한다. 왜냐하면 중요한 값 영역에 집중하거나 적절한 동적 범위를 찾음으로써 데이터 분포를 더 잘 포착할 수 있기 때문.
예를들어 bell-shaped distribution 또는 긴 꼬리를 가지는 weight, activation에 대해 설계된 non-uniform quant방법이 많이 있다. -
rule-based non-uniform quant는 logarithmic distribution을 사용하는 방법이 일반적이다. 이는 quantzation level과 step이 linera하게 증가하는 대신 exponent하게 증가하게된다.
-
binary-code-based quant는 실수 vector 을 binary vector로 quant하는 방식이다. 이는 다음과 같이 표현된다.
: scaling factor
: binary vector
이후 생략...
G. Fine-tuning Methods
Quantization 후에는 NN의 parameter를 조정해야한다.
이는 model을 retraining하는 QAT로 하거나, retraining 없이 수행하는 PTQ 방식으로 진행할 수 있다.
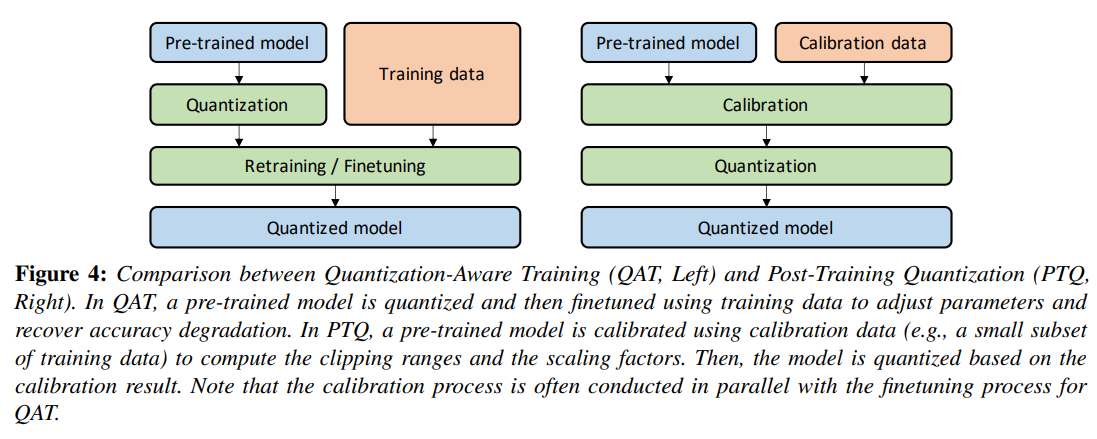
1) Quantization-Aware Training
trained model에 quant를 적용하면 parameter에 섭동이 발생하여 fp precision으로 training된 수렴 지점에서 벗어날 수 있다.
이를 해결하기 위해, quantized된 parameter로 model을 retraining하여 수렴 지점에서 벗어나는 정도를 회복할 수 있다.
이러한 방법들 중 QAT는 fp precision으로 forward pass, backward pass를 하고, 각 gradient update 후에 parameter를 quant하는 방식으로 진행된다. 이 과정에서 weight update는 반드시 fp precision으로 수행한 후에 quant를 적용해야한다. 그렇지 않을 경우 low-precision 환경에서는 0-gradient나 높은 error가 발생할 수 있다.
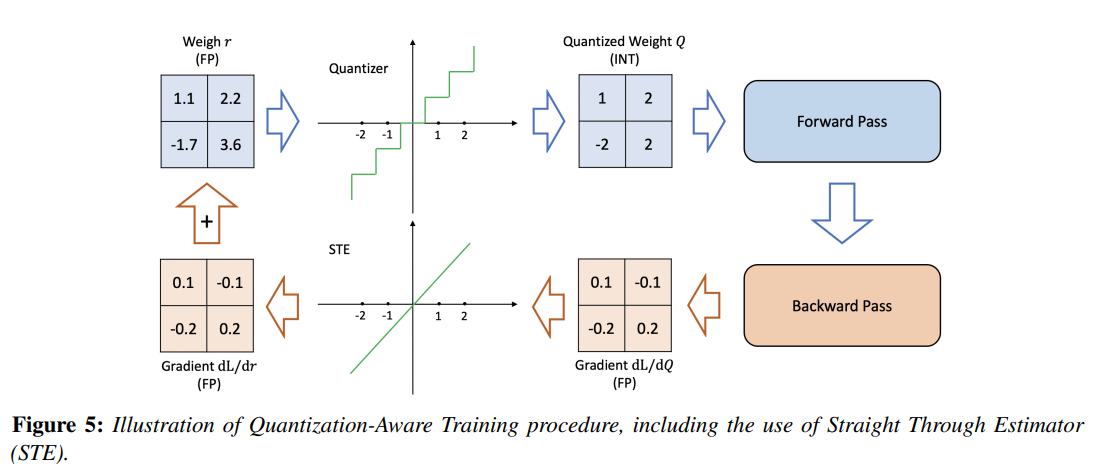
backpropagation에서 non-differentiable인 (식 2)을 어떻게 처리할까?
만약 별다른 approximate 없이 의 gradient를 계산하면,
의 Round 연산이(Int()에 있음) 조각별로 평탄한 연산자이기 때문에 거의 모든 구간에서 gradient가 0이 된다.
==>
STE(Straight Through Estimator)
STE는 round 연산을 무시하고, 이를 항등 함수로 근사하는 방식으로 작동하며, 이를 위 Figure 5에서 보여주고 있다.
STE는 coarse한 approximate임에도 불구하고, 대체로 잘 동작.
model parameter 조정 이외에도, 이전 연구들은 QAT동안 quantization parameter를 학습하는 것이 효과적임을 발견했다. PACT는 uniform quant에서 activation의 clipping range를 training하며, QIT는 non-uniform quant에서 확장하여 quantization level과 step을 학습.
Summary (QAT)
QAT는 STE의 거친 근사에도 불구하고 효과적으로 작동하는 것으로 나타났습니다. 그러나 QAT의 주요 단점은 NN model을 retraining하는 데 드는 높은 계산 비용이다. 특히 low-bit precision quant의 경우 accuracy를 회복하려면 수백 epoch 동안 retraining이 필요할 수 있습니다.
만약 quantized된 model이 오랜 기간 배포될 예정이고 효율성과 accuracy가 특히 중요하다면, 이러한 retraining에 대한 투자는 가치가 있을 가능성이 높습니다. 그러나 모든 경우에 해당하지는 않으며, 일부 model은 상대적으로 짧은 수명을 가질 수 있다. 다음으로, 이러한 오버헤드가 없는 대안 접근법을 논의합니다.
2) Post-Training Quantization
빠름 but accuracy ↓
==>
quant이후 weight의 mean과 variance에서 발생하는 고유한 bias를 보정
+
서로 다른 layer나 channel 간의 weight 범위를 균등화하여 quant error를 줄임
ACIQ는 PTQ를 위해 최적의 clipping range와 channel별 bit width 설정을 분석적으로 계산.
But
channel별 activation quant는 HW에서 효율적으로 구현하기 어렵
==>
OMSE activation에 대한 channel별 quant를 제거하고, quantized된 tensor와 fp tensor간의 L2 distance 최적화를 통해 PTQ
+
outlier로 인한 문제점을 완화하기 위해, OCS(Outlier Channel Splitting). OCS는 oulier를 포함하는 channel을 복제하고 절반으로 나누어 처리.
3) Zero-shot Quantization
위에 G. Fine-tuning Methods에서 살펴보았듯이 qauntization후 accuracy 저하를 최소화하기 위해서는 전체 또는 일부 training data를 이용해야한다.
- 값을 clip하고, 적절한 scaling factor를 찾기위해(calibration)activation의 범위를 알아한다.
- quantized model은 param을 조정하고 accuracy 저하를 회복하기 위해 fine-tuning이 필요하다.
But
training dataset은 배포하기에 너무 크거나, 개인정보의 문제, 보안의 문제등으로 인해, quantization procedure 중에 original training data에 접근하는 것은 불가능하다.
==> ZSQ
ZSQ의 2가지 level
- Level 1 : No data and no finetuning (ZSQ + PTQ)
- Level 2 : No data but requires finetuning (ZSQ + QAT)
ZSQ의 인기있는 연구 분야 중 하나는 pre-trained model이 training된 실제 데이터와 유사한 synthetic data를 생성하는 것이다.
Synthetic data는 calibrating 및 finetuning에 쓰인다.
Summary (ZSQ)
ZSQ는 training/validation data에 접근하지 않고, 전체 quantization 과정을 수행한다. 이는 특히 고객의 데이터셋에 접근하지 않고 workload 배포를 가속화하려는 MLaaS(Machine Learning as a Service) 제공없체에게 중요하다. 또한, 보안 또는 프라이버시 문제로 이냏 trianing data 접근이 제한되는 경우에도 중요한 방법이다.
H. Stochastic Quantization
inference 중에는 quantization scheme이 deterministic하게 이루어진다. 그러나 이것이 유일한 가능성은 아니다. 몇몇 연구에서는 QAT 및 reduced precision training을 위해 stochastic quantization을 연구했다.
deterministic한 quant는 작은 weight update가 weight 변화를 일으키지 않을 수 있다. 왜냐하면, rounding 연산은 항상 같은 값을 리턴하기 때문이다.
하지만 stocahstic quant는 NN에게 그런 rounding 연산의 단점을 escape할 수 있는 기회를 주어, parameter를 update할 기회를 제공할 수 있다.
Stochastic quant는 weight update에 따라 fp를 올림하거나 내림하는 확률로 mapping한다. 이게 무슨말이냐는 그냥 아래 식 (8)을 보라.
가 3.7인경우
30%의 확률로 3으로 quantized 되고,
70%의 확률로 4로 quantized 된다.
==> 즉 deterministic X, Stochastic O
But
binary quant에는 적용될 수 없다.
이것들 말고도 많음...
But 모든 weight update마다 random number를 생성하는 데 드는 overhead가 있어, 실무 채택 X.
4. Advanced Concepts : Quantization Below 8 bits
A. Simulated and Integer-only Quantizaiton
Quantized 된 NN model을 배포하는 데는 2가지 방법이 있다.
-
simulated quant(fake quant) : model param이 low-precision으로 저장되지만, 연산은 fp 연산으로 수행. 그래서 dequantization 필요.
아래 Figure 6 중간 그림. -
integer-only quant : 모든 연산이 low-precision의 integer 연산으로 수행. 이른 아래 Figure 6 오른쪽 그림.
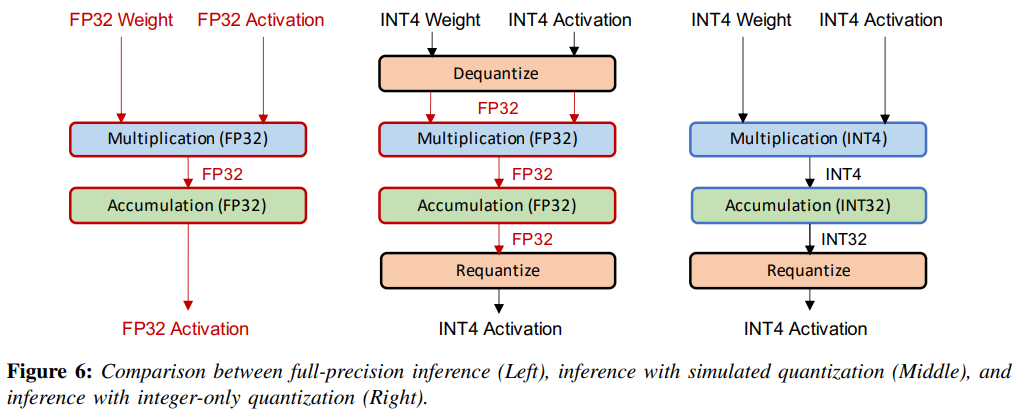
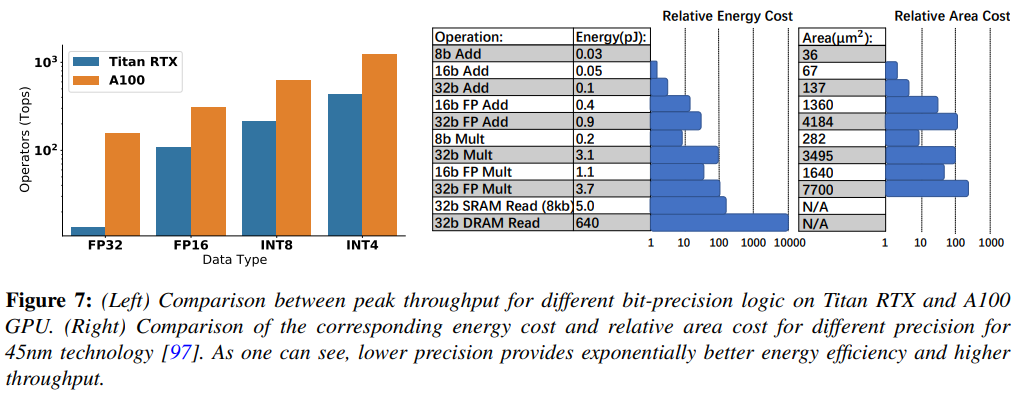
low-precision logic은 latency, power consumption, area efficiency 측면에서 full-precision 보다 여러 이점이 있다. 아래 Figure 7 왼쪽을 보면, 많은 HW processor들이 low-precision 산술의 빠른 처리를 위해 inference throughtput과 latency를 향상시켰다.
또한, Figure 7 오른쪽을 보면 45nm 기술을 기준으ㅗㄹ, low-precision logic은 power, energy면에서 훨씬 효율적임을 보여준다. 예를들어 INT8 덧셈은 FP32 덧셈보다 energy cost가 30배, area cost가 116배 뛰어나다.
B. Mixed-Precision Quantization
low-precision quant를 사용할수록 하드웨어 성능이 향상된다는 것은 명백하다.
그러나 모델을 균일하게 ultra low-precision으로 quant하면 accuracy가 크게 저하될 수 있다.
이를 해결하기 위해 mixed-precision quant가 제안되었다.이 방법에서는 각 계층을 서로 다른 bit precision으로 quant하며, 이는 아래 Figure 8에 도식적으로 나타나 있다.
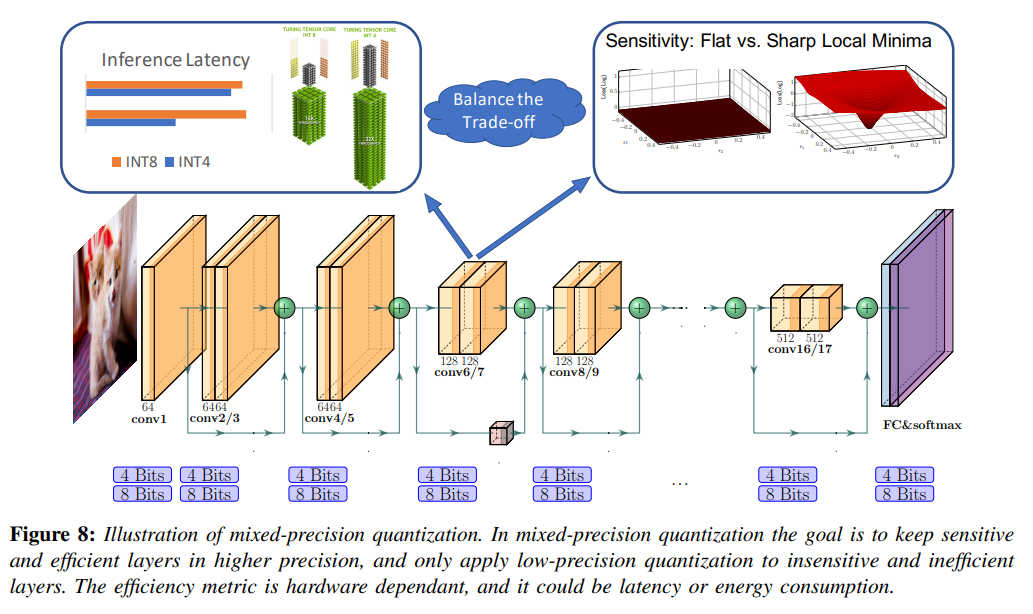
mixed-precision searching problem
어느 layer를 어떤 precision을 할지 찾는 문제이다.
탐색 기반 해결법
- RL을 활용한 자동 qauntizztion policy 결정 + HW accelerator의 feedback를 RL agent의 feedback에 반영.
- mixed-precision configuration searching problem을 NAS문제로 공식화하고, Differentiable NAS방법을 사용하여 search space를 효율적으로 탐색.
이런한 탐색 기반 방법의 한 가지 단점은 대규모 계산 자원이 필요하며, hyperparam과 initializaion에 민감하다는 것이다.
주기적 함수 정규화 해결법
periodic function regularization을 사용하여 mixed-precision model을 training 하는 것. 이 방법은 자동으로 서로 다른 layer과 accuracy에 대한 중요도의 차이를 구별하며, 각 층의 bit width를 학습하는 방식으로 동작한다.
C. Hardware Aware Quantization
Quantization의 목표 중 하나는 Inference Latency를 향상시키는 것. 그러나 모든 하드웨어가 특정 layer 또는 연산이 quantized된 후 동일한 속도 향상을 제공하지는 않는다. 실제로 quantization의 이점은 하드웨어에 따라 다르며, on-chip memory, bandwidth, cache hierarchy 구조와 같은 다양한 요인이 quantization에 의한 속도 향상에 영향을 미친다.
==>
하드웨어 친화적 quantizaitno을 통해 최적의 이점을 얻는 것이 중요.
특히, RL agent를 사용하여, 각 layer의 bit width에 따른 Latency 정보를 포함한 look-up table을 기반으로 하드웨어 친화적 mixed-precision configuration을 결정
그러나 이 접근 방식은 하드웨어 latency를 시뮬레이션하여 계산.
이를 해결하기 위해 최근 연구에서는 quantized된 연산을 실제 하드웨어에 직접 배포하여, 각 layer에 대해 다양한 quantization bit precision에서의 실제 배포 latency를 측정하는 방법을 제안.
D. Distillation-Assisted Quantization
model distillation은 더 높은 accuracy를 가진 대형 모델(Teacher)을 활용하여 소형 모델(Student)의 학습을 돕는 방법.
학생 모델을 학습하는 동안, 단순히 실제 클래스 레이블(Ground-Truth Class Labels)만 사용하는 대신, distillation은 Teacher가 생성한 Soft Probabilities를 활용하는 것을 제안. 이 Soft Probabilities는 입력 데이터에 대한 추가 정보를 포함할 수 있다.
즉, 전체 loss function은 student loss와 distillation loss를 결합하여 다음과 같이 공식화 한다.
- : 학생과 distillation loss간의 가중치를 조정하는 계수
- : 실제 클래스 레이블
- : cross entropy loss function
- : 학생, 선생 모델이 생성한 logits
- : softmax temperature
E. Extreme Quantization
F. Vector Quantization
5. Quantization And Hardware Processors
Quantization는 모델 크기를 줄이는 것뿐만 아니라 속도를 높이고 전력 소비를 줄이는 데도 유용하다. 특히 저정밀 로직을 지원하는 하드웨어에서는 그 효과가 두드러진다. 그러므로 IoT와 모바일 애플리케이션에서 엣지 배포(edge deployment) 시 중요한 역할을 한다.
엣지 디바이스는 보통 계산 능력, 메모리, 그리고 전력 예산(power budget) 같은 자원이 매우 제한적이다. 이러한 제약으로 인해 많은 딥 뉴럴 네트워크(Deep Neural Network, DNN) 모델을 실행하는 데 높은 비용이 들거나 실행이 어려울 수 있다.
게다가 많은 엣지 프로세서는 부동소수점 연산(Floating Point Operations)을 아예 지원하지 않으며, 특히 마이크로컨트롤러(micro-controllers)에서는 이러한 연산이 불가능한 경우도 많다. 이러한 환경에서는 양자화가 필수적인 기술이 된다.
양자화는 다양한 하드웨어 플랫폼에서 NN 모델을 최적화하고 배포하는 데 중요한 역할을 한다. ARM Cortex-M은 저비용, 저전력 임베디드 디바이스를 위해 설계된 32비트 RISC ARM 프로세서 코어군이다. 예를 들어, ARM Cortex-M 코어를 기반으로 한 STM32 마이크로컨트롤러는 엣지 NN 추론에 널리 사용된다. 일부 ARM Cortex-M 코어는 전용 부동소수점 연산 장치를 포함하지 않으므로, 모델을 배포하기 전에 반드시 양자화를 진행해야 한다. ARM의 CMSIS-NN 라이브러리는 이러한 코어에 NN 모델을 양자화하고 배포하는 과정을 돕는 도구로, 비트 쉬프팅(bit-shifting) 연산을 활용한 고효율 고정소수점 양자화와 복원 과정을 지원한다. GAP-8은 엣지 추론을 위한 CNN 가속기를 내장한 RISC-V SoC로, 정수 연산만 지원하는 또 다른 사례이다.
한편, Google Edge TPU와 같은 목적 기반 프로세서는 소형 저전력 디바이스를 위해 설계되었으며 8비트 연산만 지원한다. 따라서 TensorFlow 모델을 사용할 경우, 양자화 인식 학습(quantization-aware training) 또는 학습 후 양자화(post-training quantization)가 필요하다. 최근 몇 년간 엣지 프로세서의 계산 성능이 크게 향상되면서, 이전에는 서버에서만 실행 가능했던 복잡한 NN 모델도 엣지에서 배포하고 추론할 수 있게 되었다. Figure 9는 상용 엣지 프로세서들의 처리량 변화를 보여주며, 이는 양자화, 저정밀 로직, 그리고 전용 딥러닝 가속기의 발전이 크게 기여했음을 나타낸다.
양자화는 엣지 프로세서뿐만 아니라 비 엣지 하드웨어에서도 유용하며, 예를 들어 99번째 백분위 지연(latency)과 같은 서비스 수준 협약(SLA) 요구사항을 충족하는 데 큰 도움을 줄 수 있다. NVIDIA Turing GPU, 특히 T4 GPU는 이를 잘 보여주는 사례이다. Turing Tensor Cores는 저정밀 행렬 곱셈을 효율적으로 수행하도록 설계된 전용 실행 유닛으로, 현대 NN 모델 최적화에 있어 양자화의 폭넓은 활용 가능성을 보여준다.
6. Future Directions For Research In Quantization
생략
7. Summary And Conclusion
생략

좋은 정리 감사합니다