APQ-ViT: Towards Accurate Post-Training Quantization for Vision Transformer
ARQ-ViT에 대한 내용
Abstract
P1. 기존 SF 지표(calibration metric)가 low-bit에 대한 Q 영향을 측정하는데 부정확
S1.
Block-wise로 Q perturbation을 감지
+
중대한 오차에 대한 집중도를 높이기 위해, 사소한 오차를 무시
⇒ Bottom-elimination Blockwise Calibration
P2. 기존 Q 패러다임이 Softmax의 power-law-distribution에 친화적이지 X
S2.
softmax의 power-law-distribution을 유지하기 위해, Matthew-effect Preserving Quantization 설계
1 Introduction
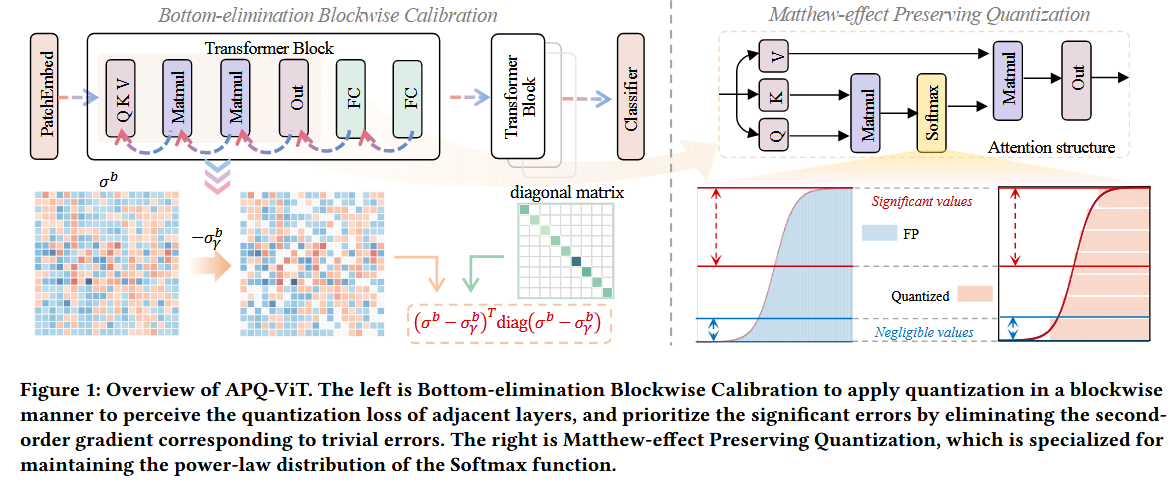
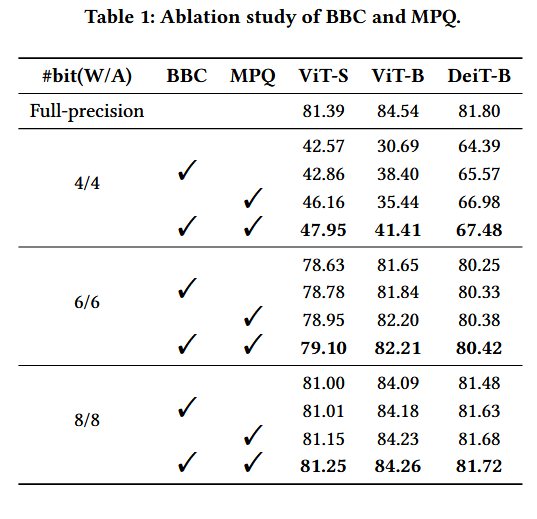
S1. Blockwise Bottom-elimination Calibration, BBC는
block-wise하게 Q error를 감지
+
사소한 error에 해당하는 2차 그래디언트를 생략하여, 중대한 오차에 집중
S2. Mattew-effect Preserving Quantization, MPQ는
softmax의 목적에 맞게, 큰 값(중요한 값)에 더 많은 bin 할당
2 Related Work
생략
3 Method
3.1 Preliminaries
PTQ4ViT는 최적의 SF를 결정하기 위해, Hessian guided metric을 사용.
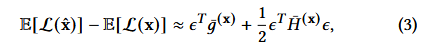
위 Q로 인한 작업 손실의 기댓값을 최소화하는 SF를 찾아야함.
⇒
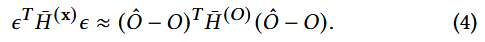
⇒ ≈
이후 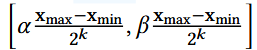
구간을 등분한 의 search space를 순회하며, ≈ 를 만족하는 를 교대 탐색!!!

3.2 Blockwise Bottom-elimination Calibration
PTQ4ViT의 hessian guided metric은 low-bit에서,
layer-wise한 최적화가 block level에서의 Q를 감지할 수 없어, 부정확
+
낮은 비트에서 오차(hessian matrix)가 클 수 밖에 없는데,
dense한 hessian matrix는
사소한 오차'까지 모두 보려다가, '중대한 오차'에 대한 집중도를 잃음
⇒
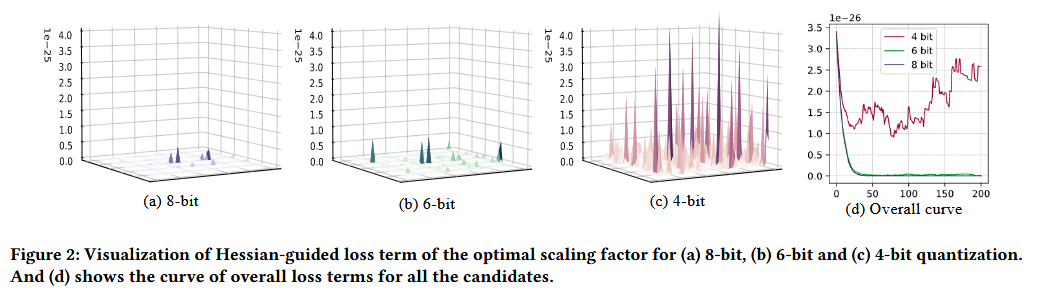
4bit에서 인접한 후보 SF들끼리 loss 차이가 큼
+
너무 뾰족 뾰족해서, 최적 찾기 어려움
⇒ Blockwise Bottom-elimination Calibration
1. Blockwise하다?
어떤 b번째 block의 input/output을 라고 할 때,
이다.
또한 번째 layer가 보정될 때, 번째부터 번째 layer까지의 복합 레이어로 간주될 수 있고, 그 weight와 activation은 다음과 같음
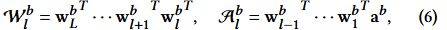
weight 보정을 예로들면, 번째 block의 번째 layer에 대한 2차 항은 다음과 같음
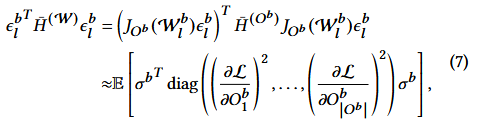
이때,
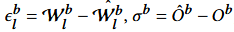
⇒ (7)을 보면, 결국, 어떤 block의 어떤 layer든 해당 block의 2차 정보로 최적의 SF를 결정할 수 있음 ⇒ Blockwise!!!
2. Bottom-elimination?
bit-width ↓ ⇒ Q error ↑ ⇒ '사소한 error' ↑ ⇒ '중대한 error' 관심 ↓
⇒ 최종 출력에 perturbation을 일으키는 큰 error에 더 주목하기 위해, '최하위 제거'메커니즘을 적용한, sparse hessian matrix!!!
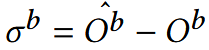
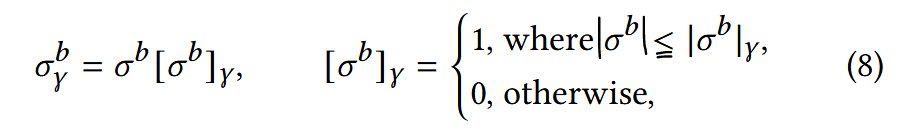
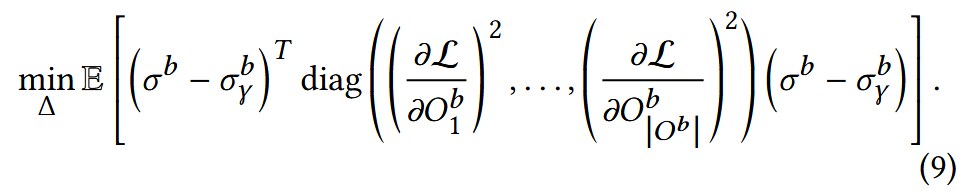
⇒

⇒

3.3 Matthew-effect Preserving Quantization
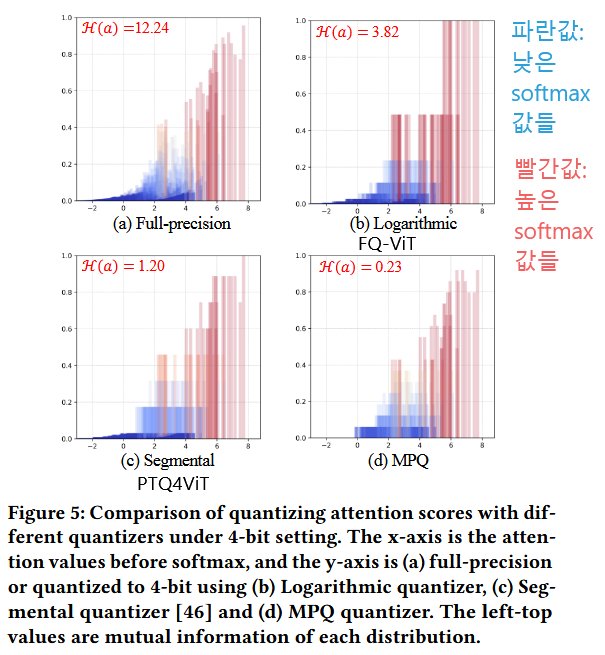
다른 연산들과 달리 softmax의 output distribution은 비대칭적이고 극도로 불균형한 power-law probability distribution을 따름.
이전 많은 연구들 PTQ4ViT(twin-Q), FQ-ViT(log방법)는 모두 낮은 softmax 값(대다수의)에 많은 bin을 부여하고 싶어함.
But
그렇게 되면, softmax의 원래 기능(작은 값은 더 작게, 큰 값은 더 크게(∵exponential function 때문에))을 상실...
⇒ 중요한 큰 값들의 정보 손실...
⇒ Matthew-effect Preserving Quantization, MPQ
이는 양자화 전후의 상호 정보량 최대화를 순수하게 추구하는 대신,
양자화 과정 동안 소프트맥스 출력의 마태 효과를 유지
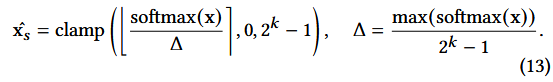
⇒ 즁요한 값은 더 fine하게 Q (그림 5(d))
3.4 Framework of APQ-ViT


4. Experiment
4.1 Settings
생략
4.2 Ablation Study
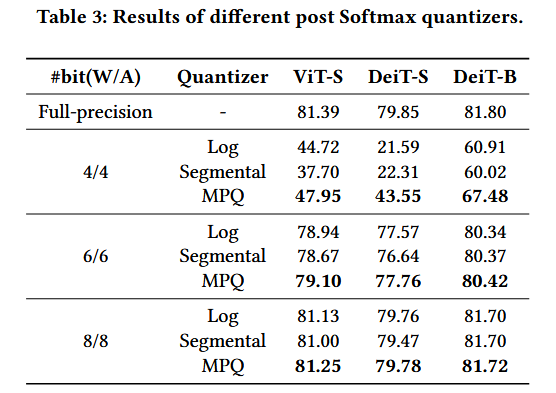
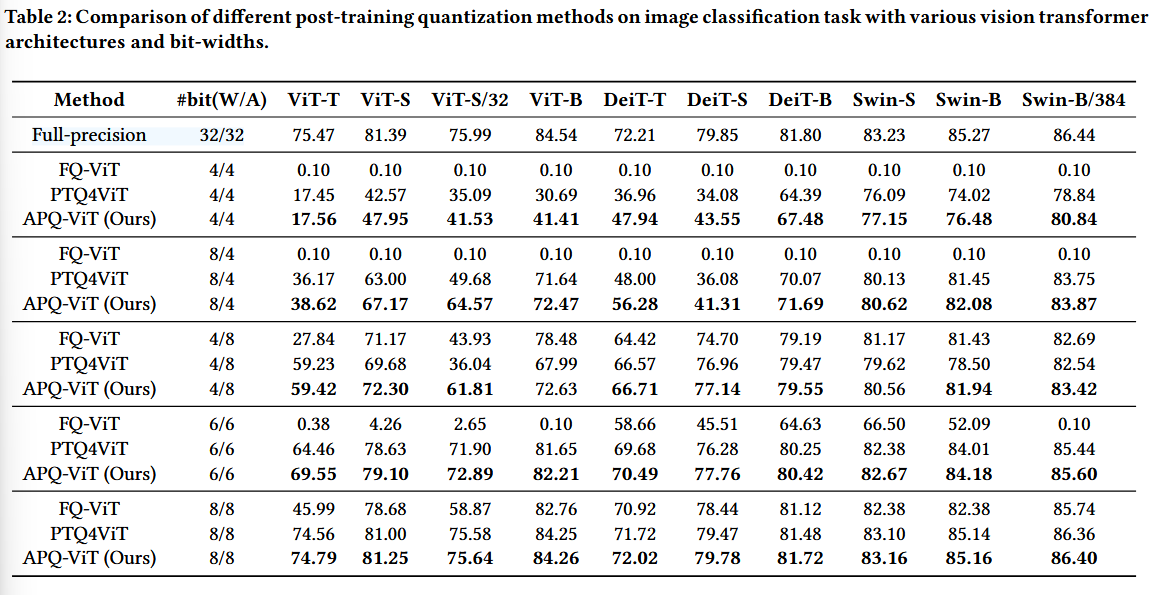
4.3 Comparison on Classification Task
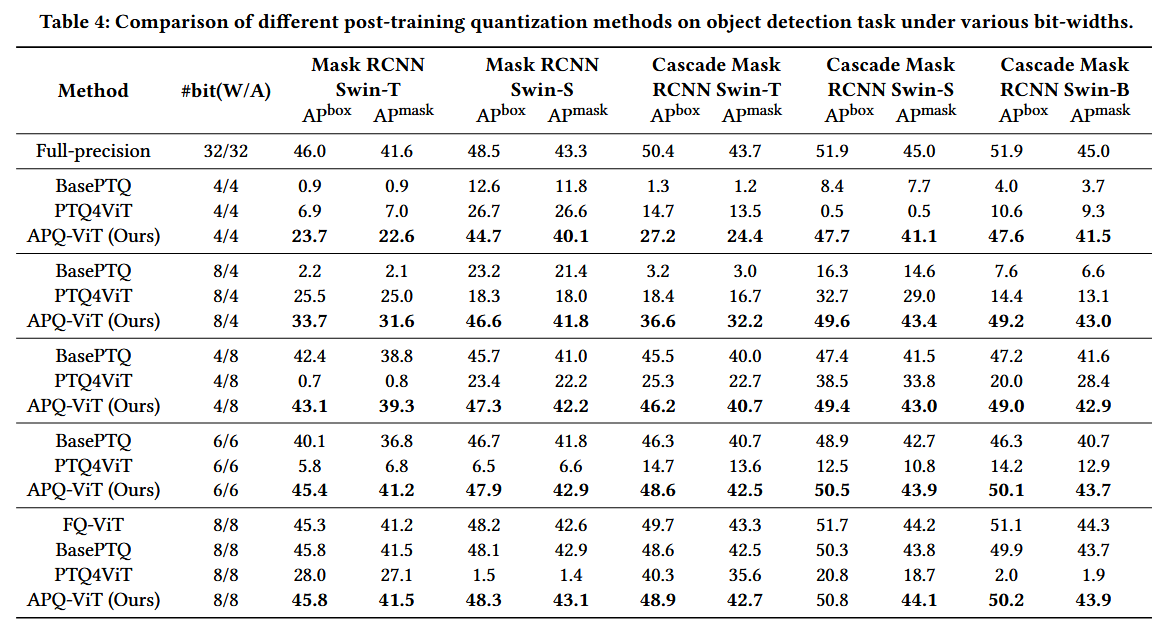
4.4 Comparison on Object Detection Task
5. Conclusion
생략
