RepQ-ViT: Scale Reparameterization for Post-Training Quantization of Vision Transformers
RepQ-ViT에 대한 내용
Abstract
P1. post-LayerNorm activation의 inter-channel variation
S1.
Channel-wise Q @ quantization step.
Layer-wise Q @ inference step.
P2. Power-law distribution을 가진 post-Softmax activation
S2.
Q @ quantization step.
Q @ inference step.
1. Introduction
전통적인 'Q-infernece 종속' paradigm은 유일한 선택일까?
⇒ Q, infernece step을 decoupling
P1. post-LayerNorm activation의 inter-channel variation
S1.
Channel-wise Q @ quantization step.
Layer-wise Q @ inference step.
⇒
Q step에서 channel-wise Q하고,
I step에서 layer-wise로 reparameterization하여,
LayerNorm의 affine factoer, 다음 layer의 weight를 조정해서 acc ↑
P2. Power-law distribution을 가진 post-Softmax activation
S2.
Q @ quantization step.
Q @ inference step.
2. Related Works
생략
3. Methodology
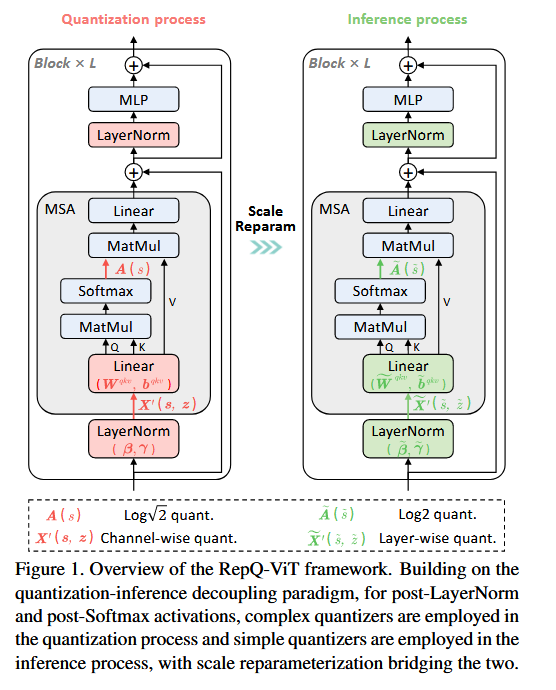

3.1 Preliminaries
Hardware-friendly quantizers
Uniform Q
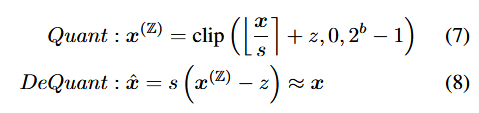
Q
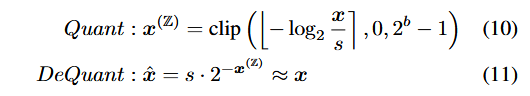
3.2 Scale Reparam for LayerNorm Activations
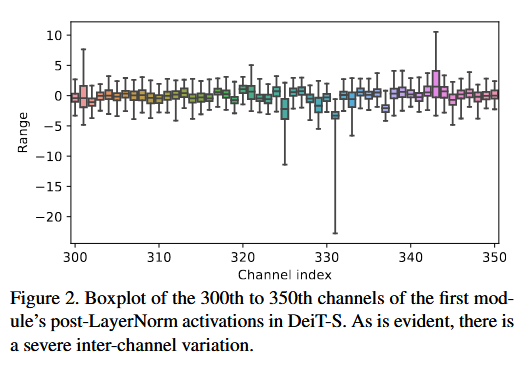
⇒ 단순히 통일된 Q SF를 적용하는 layer-wise Q는 위와 같은 큰 inter-channel variation에서 acc ↓
⇒
Q step:
channe-wise Q ⇒ , 를 얻음
I step:
를 로 reparam.
이때, k는 당연히 미리 계산됨(PTQ니까...)
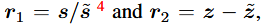
라고 하면,
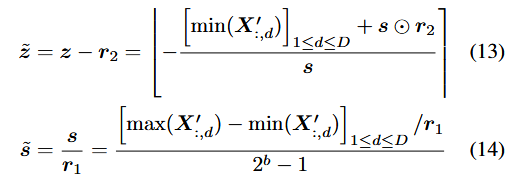
이고,
이러한 연산은 Layernorm의 affine factor를 다음과 같이 조정함으로써 달성 ㄱㄴ.
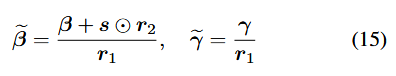
위에처럼 하면, 를 reparam하지만, activation 분포를 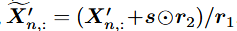
이렇게 이동시킴.
⇒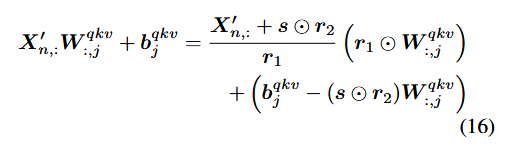
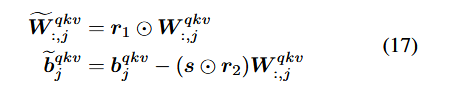
이런 식으로 뒤에 layer의 weight에 오차를 보상하게 함.
3.3 Scale Reparam for Softmax Activations
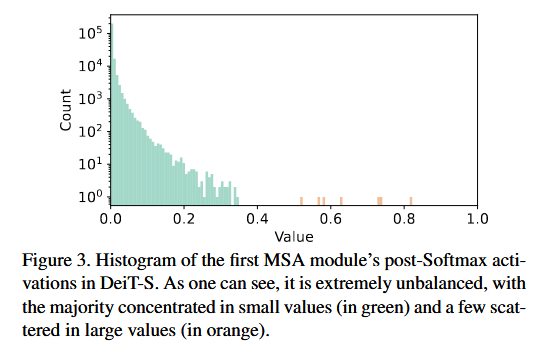
FQ-ViT의 Q는 중요한 소수의 attention 값이 큰 부분에 적은 bin을 할당.
⇒ acc ↓
⇒ Q
But
HW frendly X (∵ Q처럼 bit-shifting 연산 X)
⇒
Q step: Q
I step: Q
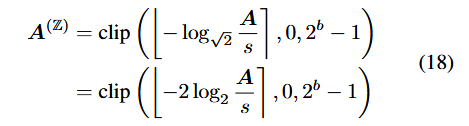
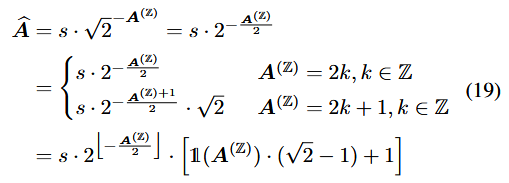
⇒
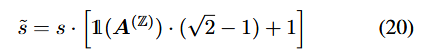
s와 비교할 때, reparam된 는 I step에서 dequant 절차 또한 효율적인 bit-shift로 할 수 있게함!
// 물론 가 홀수일 때, 여서,
// 를 만큼 shift하고, 를 곱하긴 함.
// 짝수일 떄도, 가 FP32이면, fp연산을 하긴 함...
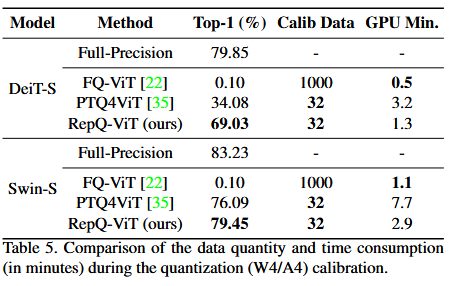
4. Experiments
4.2. Quantization Results on ImageNet Dataset
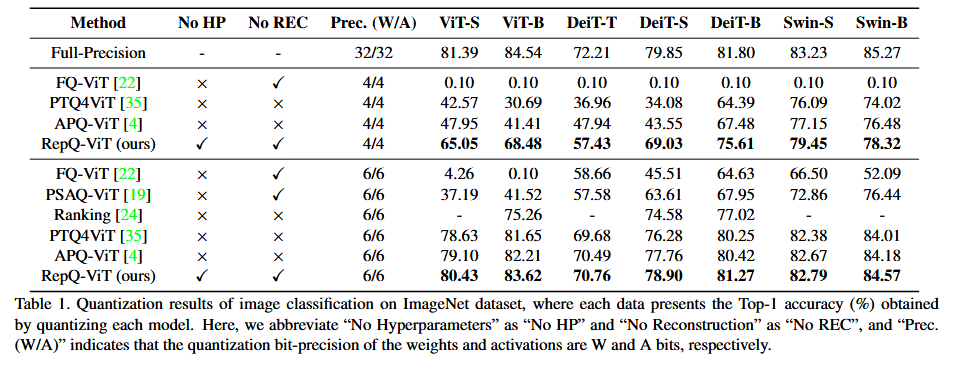
4.3. Quantization Results on COCO Dataset

4.4 Ablation Studies
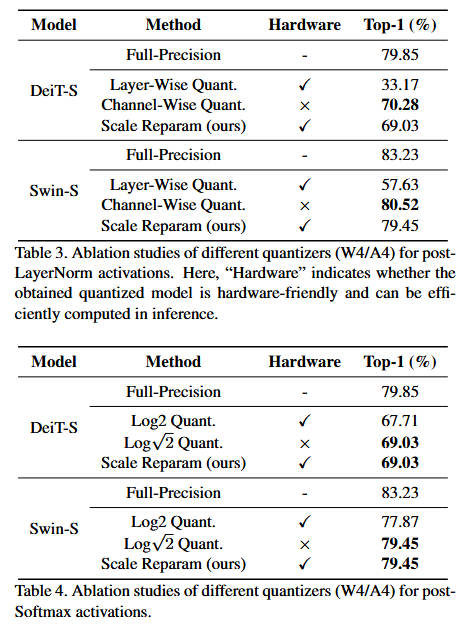
4.5 Efficiency Analysis