FQ-ViT: Post-Training Quantization for Fully Quantized Vision Transformer
FQ-ViT에 대한 내용
Abstract
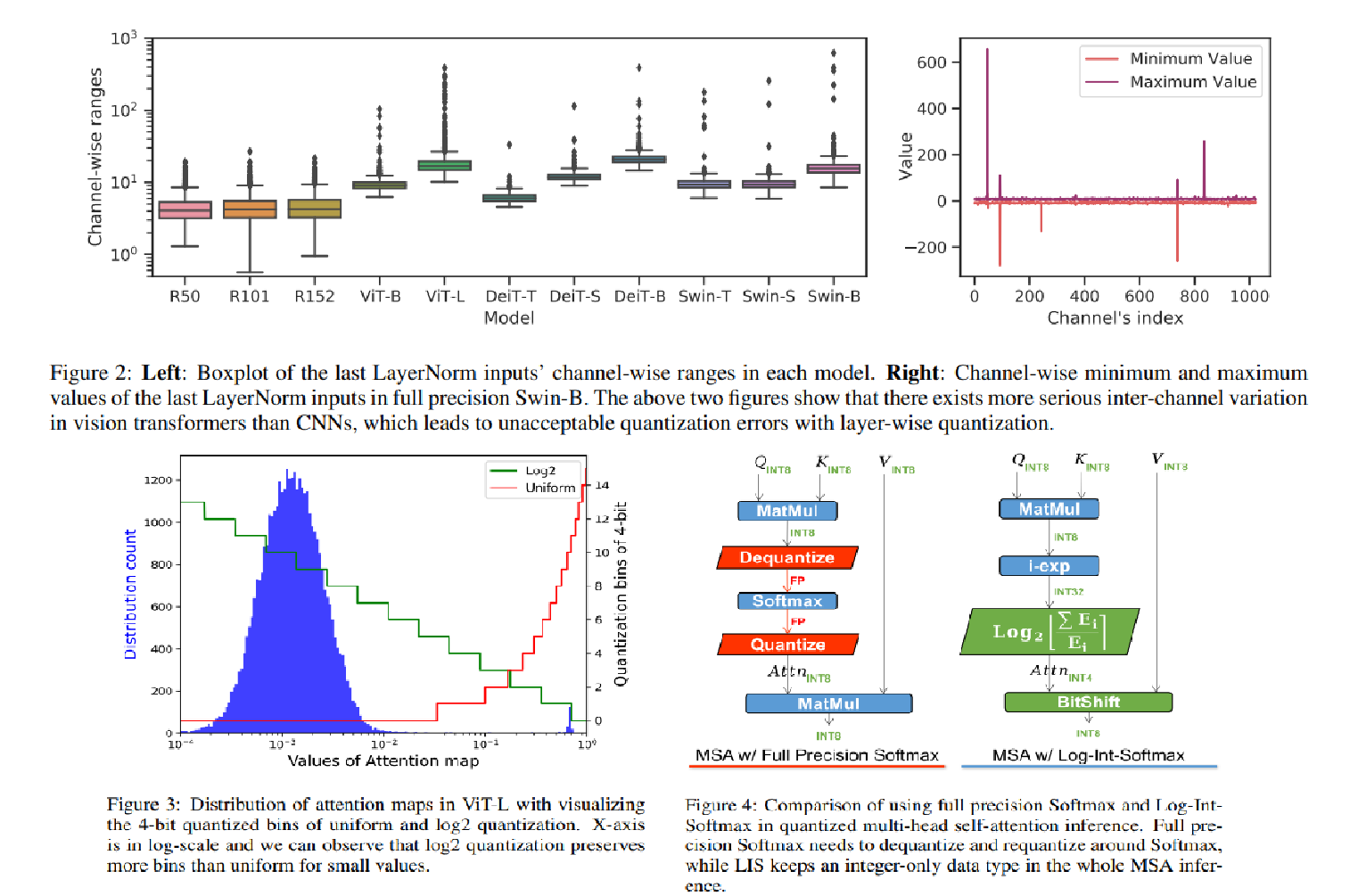
P1. LayerNorm input의 심각한 inter-channel variation ⇒ performance ↓
S1. Power-of-Two Factor
P2. Attention map에서의 extreme skwed distribution ⇒ performance ↓
S2. Log-Int-Softmax
1 Introduction
Post-Training Quantization for Vision Transformer에서 LayerNorm과 Softmax를 Q하는 것은 심각한 acc ↓를 가져옴을 보임.
⇒ Model이 fully Q되지 않아, HW에서 FP 연산 장치를 유지 + resource 소모 ↑ + inference speed ↓
⇒
P1. LayerNorm input에서 significant한 inter-channel variation 발견.
일부 channel의 범위는 median의 40배를 초과
⇒ acc ↓
S1. LayerNorm의 input을 Q하기 위한, PTF
P2. Attention-map 값이 extremely skwed distribution
⇒ 대부분 값 0 ~ 0.01, 소수 높은 attention 값만 1에 가깝
⇒ acc ↓
S2. 대부분의 작은 값에 더 높은 Q 해상도를 제공하기위해, LIS
2 Related Work
생략
3 Proposed Method
3.1 Preliminary
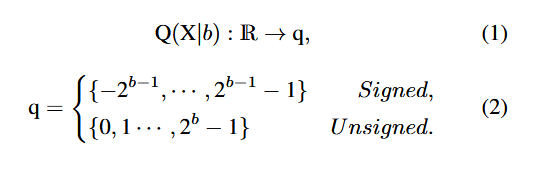
Uniform Quantization
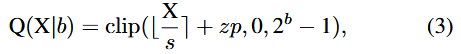
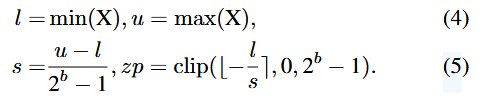
⇒ 는 의 하한()과 상한()에 의해 결정.
Log2 Quantization
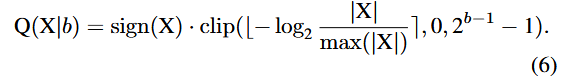
3.2 Power-of-Two Factor for LayerNorm Quantization
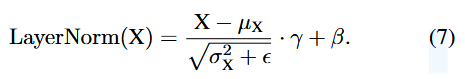
LayerNorm은 forward step에서 를 계산하여, input 를 normalized함.
이후, affine param 가 nomalized된 input을 재조정.
P1. ViT에서 LayerNorm input의 inter-channel variation이 큼.
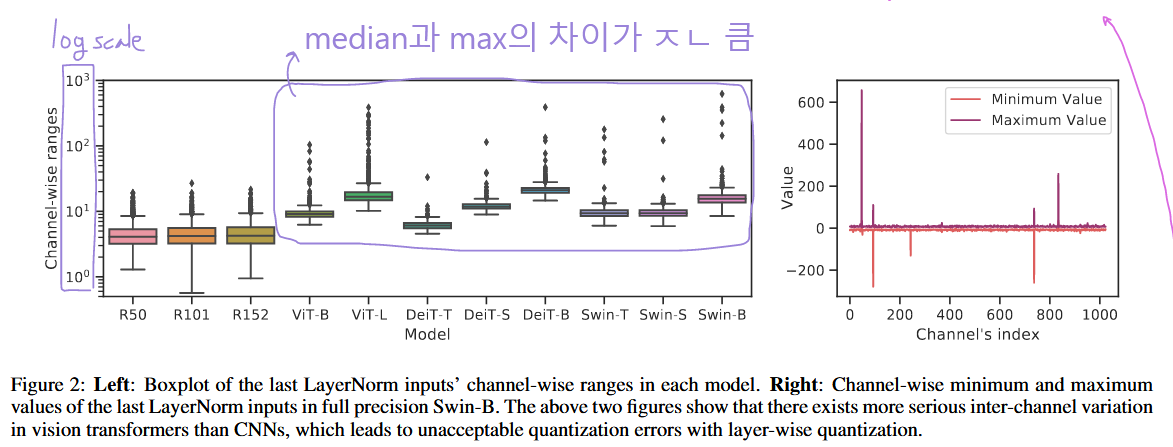
⇒ 모든 channel에 동일한 Q param을 적용하는 layer-wise Q는 acc ↓
⇒ Group-wise, Channel-wise Q
But
여전히 FP 영역에서 평균과 분산 계산...
⇒ Channel-wise하게, factor 를 도입하는, PTF
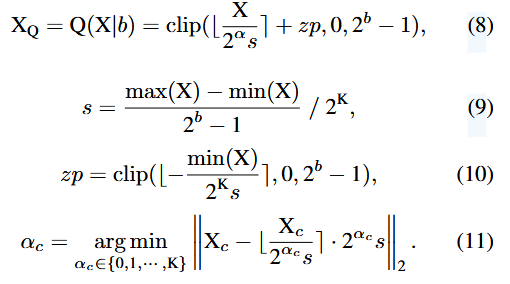
⇒ Channel별 고유한 factor 를 갖고,
layer-wise 고유한 를 갖게됨!!!
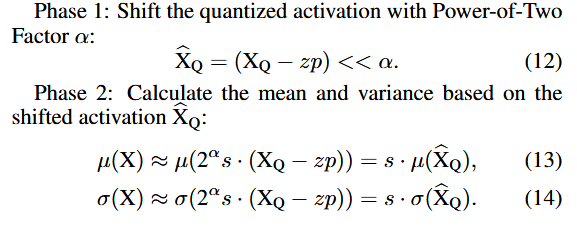
⇒
Infernce시 는 미리 추출될 수 있음
+
LayerNorm input이 Q되서, 평균, 분산이 int 영역에서 계산 됨!!!
3.3 Log-Int-Softmax for Softmax Quantization
P2. Attention map의 상당히 많은 값이 상당히 작은 값에 분포. 1에 가까운 큰 값은 이상치로 소수에 불과.
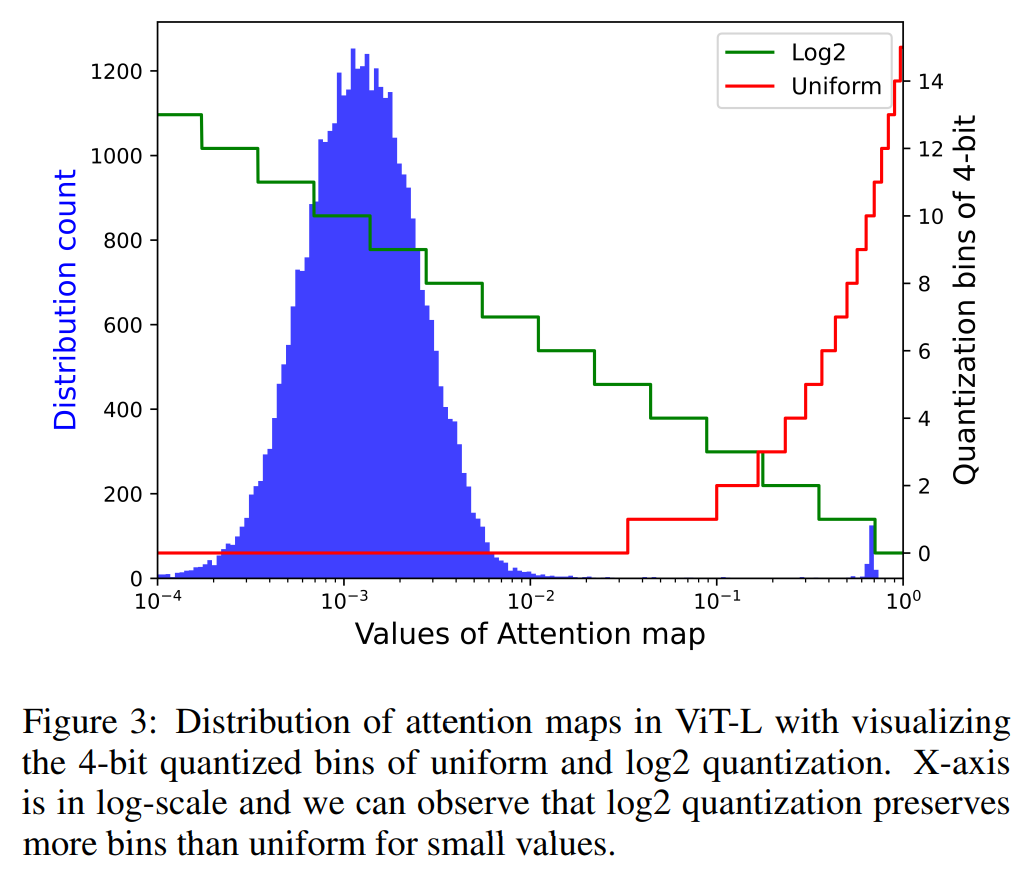
이렇게 많은 값들( ~ 의 값들)에 하나의 구간만 할당하는 uniform Q는 않좋음.
⇒ 방식은 이 값들을 위해, 더 많은 구간을 할당 可能
+
지수 함수 (Softmax의 exp())의 다항식 근사치인 i-exp
⇒ integer-only + fast + low-cost
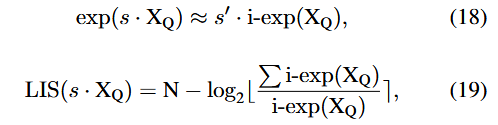
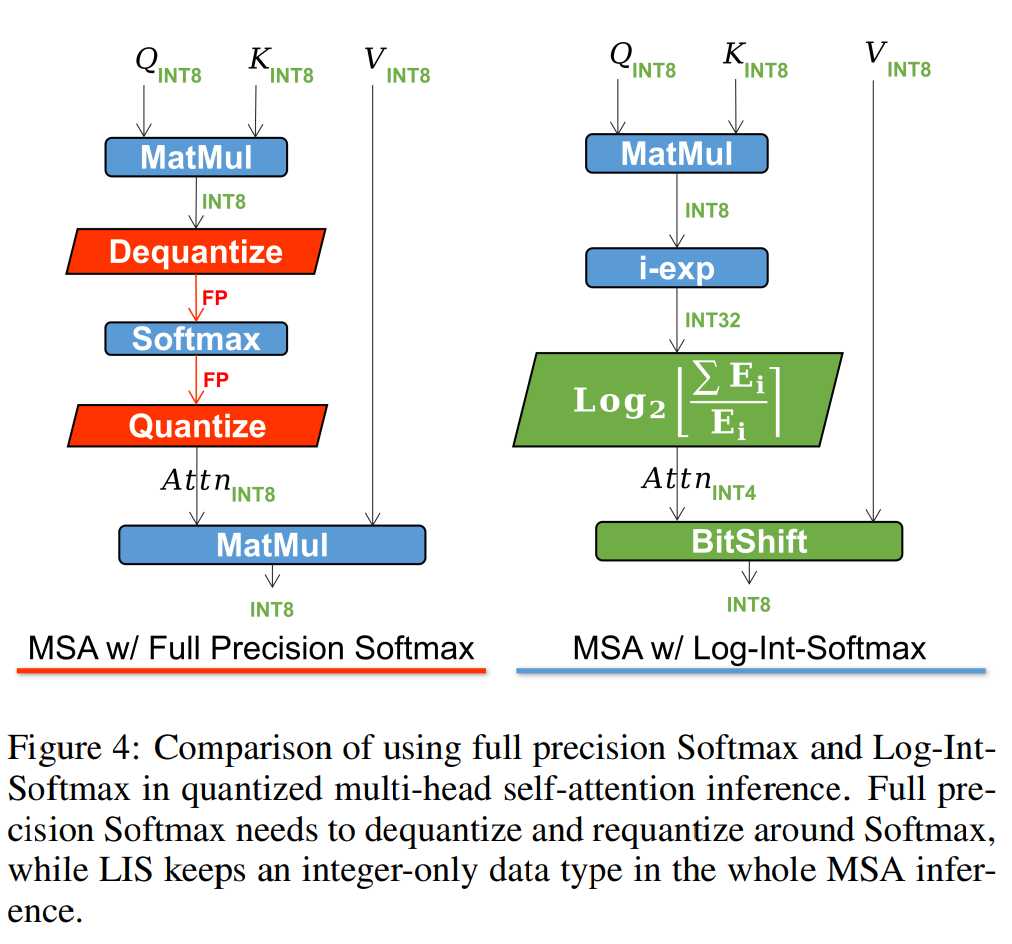
4 Experiments
4.1 Implementation Details
- Calibration: ImageNet, COCO에서 1000개 training images
- Weight Q: symmetric channel-wise MinMax
- Activation Q: asymmetric layer-wise MinMax
- PTF의 K = 3
4.2 Comparison with State-of-the-art Methods
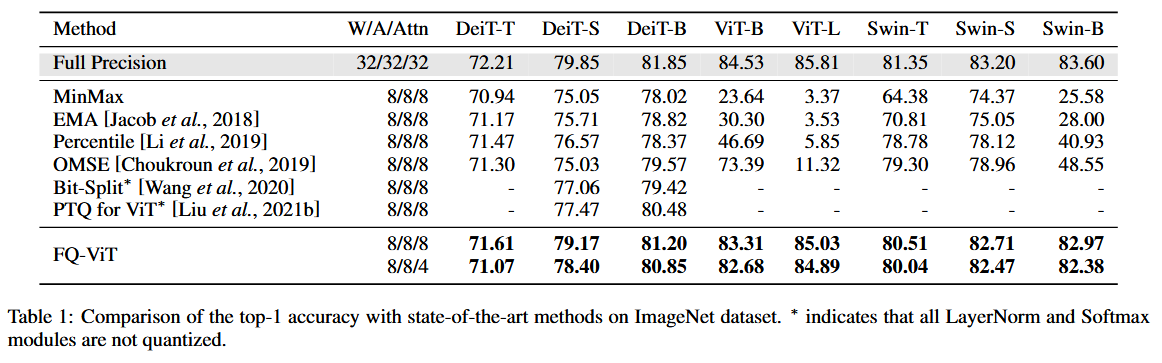
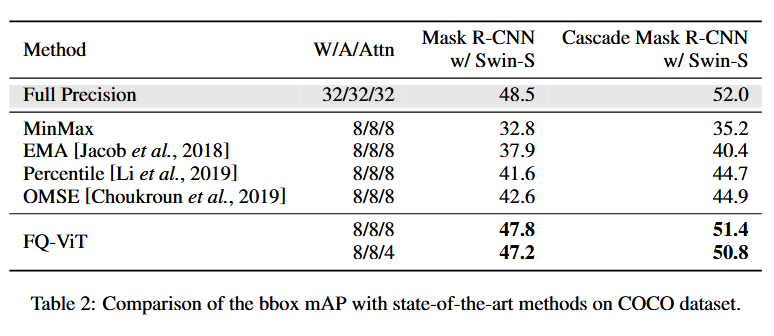
4.3 Ablation Studies
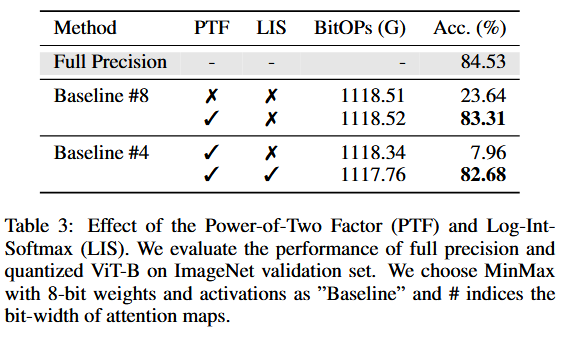
⇒ Softmax를 낮은 비트로 Q 하려면, LIS 必
4.4 Visualization of Quantized Attention Map

⇒ Softmax를 낮은 비트로 Q 하려면, LIS 必
5 Conclusions
생략
