Activation Quantization of Vision Encoders Needs Prefixing Registers
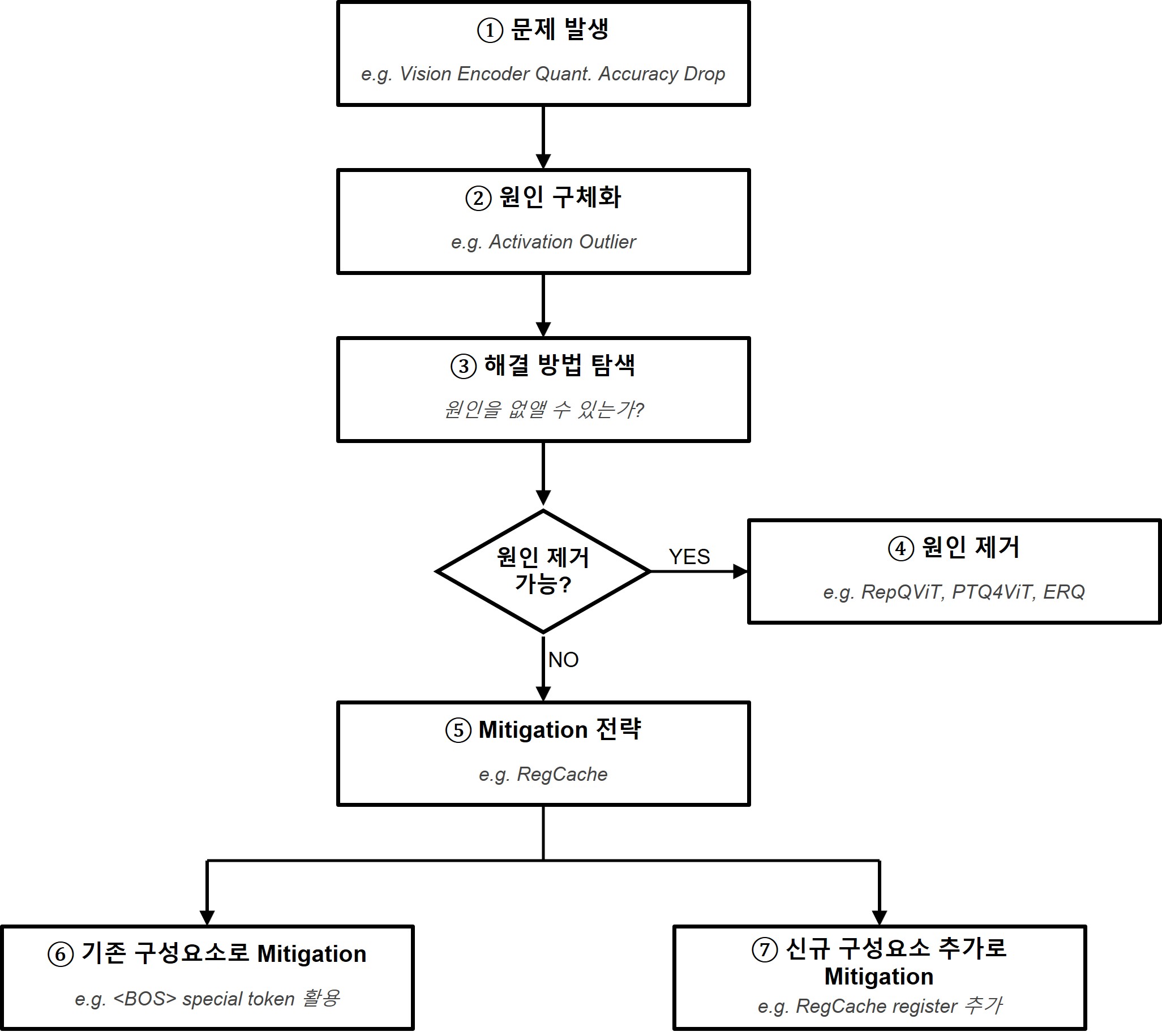
의문점 및 발전 가능성
-
Section 2에서 Outlier control strategy in quantization에서,
기존 PTQ 방법들은 outlier가 존재하는 상태에서 양자화 오류를 줄이는 데 집중하는 반면,
RegCache는 outlier 자체를 사전에 억제한다. 작동하는 단계가 다르기 때문에 기존 기법들과 orthogonal하게 결합할 수 있다.라고 했는데, 그럼 RegCache 적용 이전, 이후의 outlier의 차이는?
-
작은 vision encoder는 왜

가 없을까? -
SigLIP2의 각 레이어를 하나씩 W8A8로 했을 때, 가장 quantization에 민감한 레이어의 입력 토큰이 특히 큼. 왜그럴까?
-
Table 5
Table 2를 보면 저자들도 Naïve 결과는 "excluding the Naïve cases"라고 명시하면서 Best/Average ∆ 계산에서 제외했다.
Naïve quantization은 베이스라인 자체가 너무 낮아서 거기서의 개선은 실질적인 의미가 희석되기 때문인 것 같다.그런데 Table 5 (다양한 데이터셋에서의 universality 실험)는 오직 Naïve + RegCache 조합만 보고하고 있다.
이게 아쉬운 이유는:
-
주장과 실험 설계의 불일치 — Table 5의 목적은 "ImageNet-1k에서 찾은 prefix가 다른 도메인에도 일반화되는가"를 보이는 건데, PTQ4ViT, RepQ-ViT, ERQ 등 실질적인 PTQ 방법들과의 조합에서도 같은 generalization 효과가 나타나는지는 확인이 안 된다.
만약 Table 5에서 RepQ-ViT나 ERQ 같은 강한 PTQ baseline과의 조합도 함께 보고했다면, prefix의 universality 주장이 훨씬 설득력 있게 뒷받침됐을 것 같다.
-
칼
Abstract
Outlier로 인해, 8-bit precision에서도 quantization에 어려움이 있음.
RegCache
1. Training-free
2. 다른 quantization methods 위에 적용할 수 있는 plug-in module
RegCache 한줄 요약
RegCache는 outlier가 발생하기 쉬우면서도 semantically meaningless한 prefix tokens를 vision encoder에 도입하여, 다른 tokens에서 outliers가 발생하는 것을 방지함.
1. Introduction
Vision encoder는 edge device에서 단독으로 쓰이거나 VLM의 visual backbone으로 쓰이는데, 모델이 크다 보니 저장 공간과 추론 비용이 병목이 된다. 특히 고해상도/비디오에서는 전체 latency의 ~45%를 차지할 만큼 부담이 크다.
Vision encoder는 autoregressive LLM과 달리 non-autoregressive 방식이므로 compute-bound임.
⇒ Activation과 weight를 모두 양자화(예: INT8)하면 실제 연산 비용을 효과적으로 줄일 수 있음.
대규모 transformer의 activation 양자화는 일부 채널에 집중되는 outlier 때문에 어렵다. 기존 outlier-robust 방법들은 토큰/채널별로 스케일·정밀도를 동적으로 다르게 할당해서 정확도는 확보하지만, 그만큼 런타임 overhead가 생긴다. 이는 양자화 파라미터를 미리 고정해 하드웨어 효율을 극대화하는 static quantization의 취지와 충돌하므로, 그대로 적용하기 어렵다.
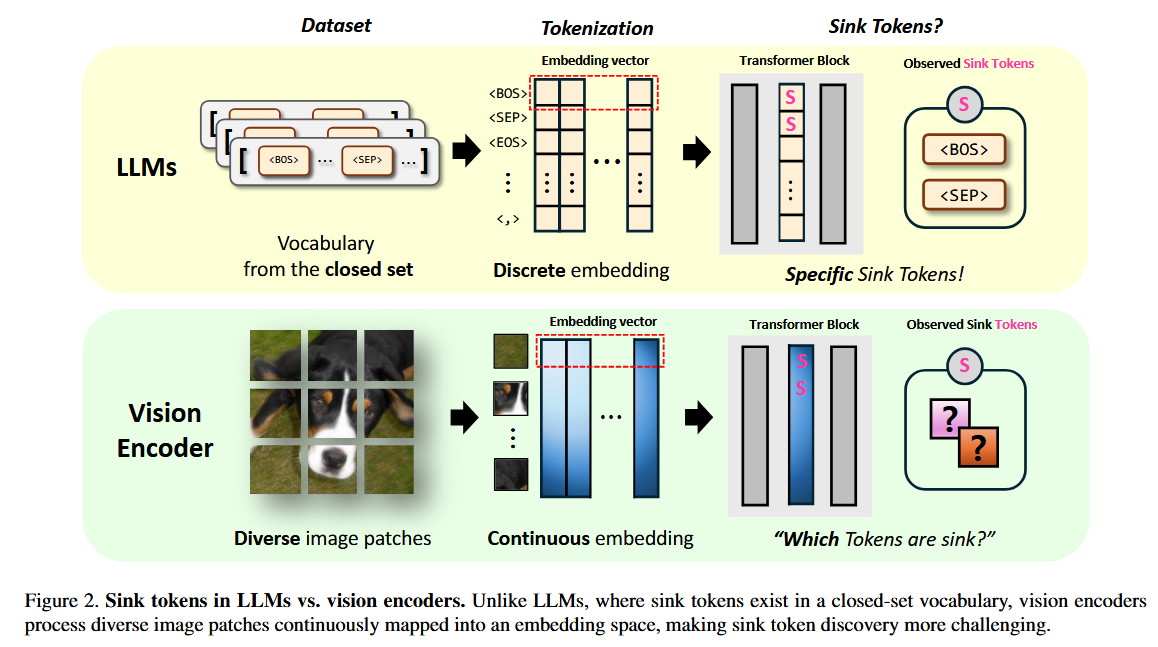
LLM에서는 의미 없는 토큰(⟨BOS⟩, ⟨SEP⟩ 등)이 attention sink 역할을 하므로, 이를 prefix로 삽입해 outlier를 흡수시키는 방법이 있다. 그러나 vision encoder는 애초에 이런 의미 없는 토큰을 포함하도록 설계·학습되지 않아서, 어떤 패치가 그 역할을 할 수 있는지 불분명하다. 최근 register라는 의미 없는 토큰을 학습 중 도입해 ViT의 interpretability를 높이려는 연구[11]가 있지만, 아직 일반적인 방식은 아니다.
RegCache가 영감 받은 관찰
Vision encoder의 중간 레이어부터 특정 토큰들이 다른 토큰들의 큰 activation 값을 흡수하는 sink token 역할을 점진적으로 하게 되며, 그 결과 자기 자신의 activation이 극단적으로 커져 outlier로 나타난다. 이 sink token들은 어떤 이미지를 넣든 activation 패턴이 거의 동일하기 때문에, 미리 추출해두면 테스트 시 아무 입력에나 붙여 쓸 수 있는 universal register로 활용할 수 있다.
주의점
작은 ViT에서는 이런 관찰 X
⇒ 중간 레이어의 registers를 찾아내어, 이를 precomputed KV cache 형태로 prefixing하여, outlier를 완화
주요 차별점
1. Middle-to-final layers insertion: LLM prefixing 과 달리, 이 토큰들은 초기 레이어가 아닌 중간에서 마지막 레이어 사이에만 삽입됨.
2. Token deletion: prefix register로 흡수한 뒤에도 남아있는 자여 sink token을 제거해 outlier를 마저 정리
3. Universal Cache: 내부에서 생성되는 sink tokens 를 외부의 precomputed caches 로 대체하여 activation quantization range 가 팽창하는 것을 방지.
4. Versatility: 별도의 추가 학습이 필요 없으므로 기존의 PTQ pipelines 에 lightweight on-top module 로 쉽게 통합될 수 있다.
Q: Sink token을 삭제하면 안 되는 거 아닌가? 비정상적으로 크다는 건 outlier를 잘 흡수했다는 뜻 아닌가?
A: 맞다, 기존 sink token이 outlier를 흡수한 건 사실이다. 하지만 두 가지 문제가 있다. 첫째, 그 토큰 자체가 극단적으로 큰 값을 가지므로 여전히 양자화 range를 넓혀야 해서 양자화 관점에서 문제가 해소되지 않는다. 둘째, 이 극단적 activation이 이후 레이어로 전파되면서 후속 블록의 activation도 연쇄적으로 커지는 원인이 된다. RegCache는 이 기존 sink token을 삭제하고, 미리 계산해둔 깔끔한 universal cache로 교체한다. 흡수 역할은 새 cache가 대신 하되, activation이 폭발적으로 커지지 않도록 관리된 형태로 삽입하는 것이 핵심이다.
2. Related work
Outliers in large-scale transformers
참고
[46]은 outliers가 LLMs, ViTs 모두에서 self-attention의 softmax operation으로 인해 발생함을 제공함
LLM에서는 outlier가 ⟨BOS⟩ 등 special token에 집중되지만, ViT에서는 배경 패치처럼 정보 없는 토큰에서 나타나며 이미지마다 위치가 달라 어떤 토큰이 일관되게 outlier를 만드는지 불분명했다. 본 연구는 이 outlier 토큰들이 중간 블록에서 나타나고, 이미지나 모델에 관계없이 유사한 feature를 보인다는 것을 발견했으며, 덕분에 미리 계산해두고 PTQ 등에 활용할 수 있게 되었다.
Improving vision transformers via controlling attention sink tokens
문제: ViT에서 sink token은 attention map의 noise로 작용해 visual performance를 저하시킨다.
기존 해결법: [11]은 학습 중 register token을 추가해 sink를 흡수시켰고, [23]은 추론 시 outlier 채널의 max activation을 별도 토큰으로 옮기는 training-free 방식을 제안했다.
본 연구: 미리 계산한 precomputed sink token을 외부에서 삽입해, 이미지별 처리 없이 activation dynamic range를 줄여 PTQ 성능을 개선한다
Post-training quantization for vision transformers
초기 방법들: self-attention에 민감한 블록에 dynamic bitwidth를 할당해 양자화 오류를 완화.
RepQViT, PTQ4ViT: LayerNorm, softmax, GELU 등에서 발생하는 outlier의 영향을 분리·최소화하는 양자화 scheme 제안.
NoisyQuant: noise를 주입해 heavy-tailed activation distribution을 재형성.
FIMA-Q: PTQ를 위한 round-function 최적화 도입.
ERQ: activation과 weight를 순차적으로 양자화하는 2단계 절차로 양자화 오류 감소.
Outlier control strategy in quantization
기존 PTQ 방법들은 outlier가 존재하는 상태에서 양자화 오류를 줄이는 데 집중하는 반면, RegCache는 outlier 자체를 사전에 억제한다. 작동하는 단계가 다르기 때문에 기존 기법들과 orthogonal하게 결합할 수 있다.
3. A closer look at outliers in vision encoders
3.1. Layerwise quantization sensitivity and outliers
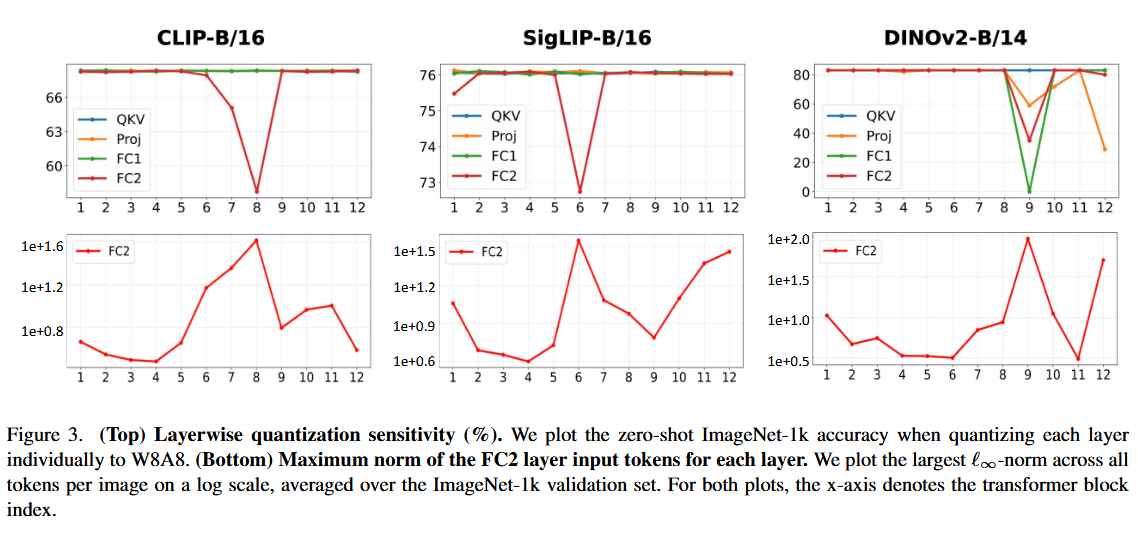
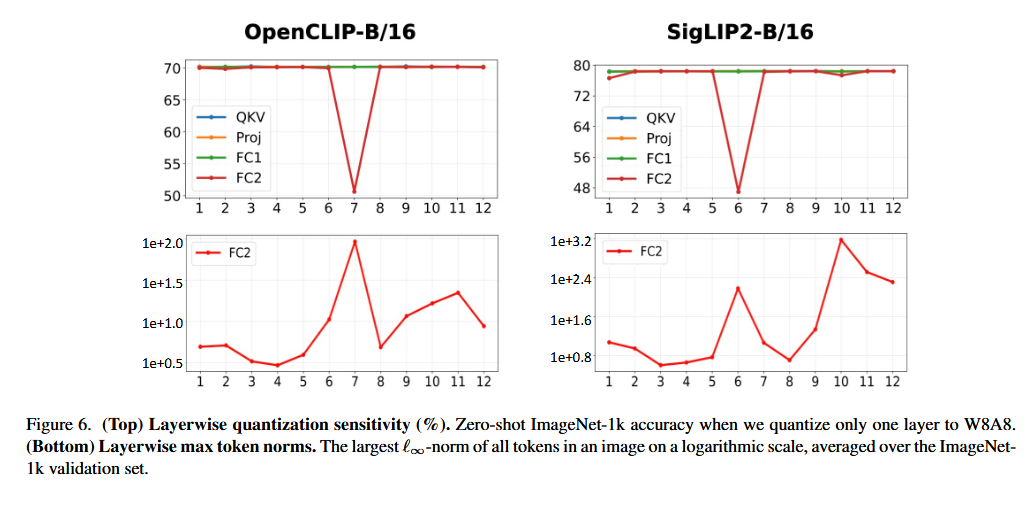
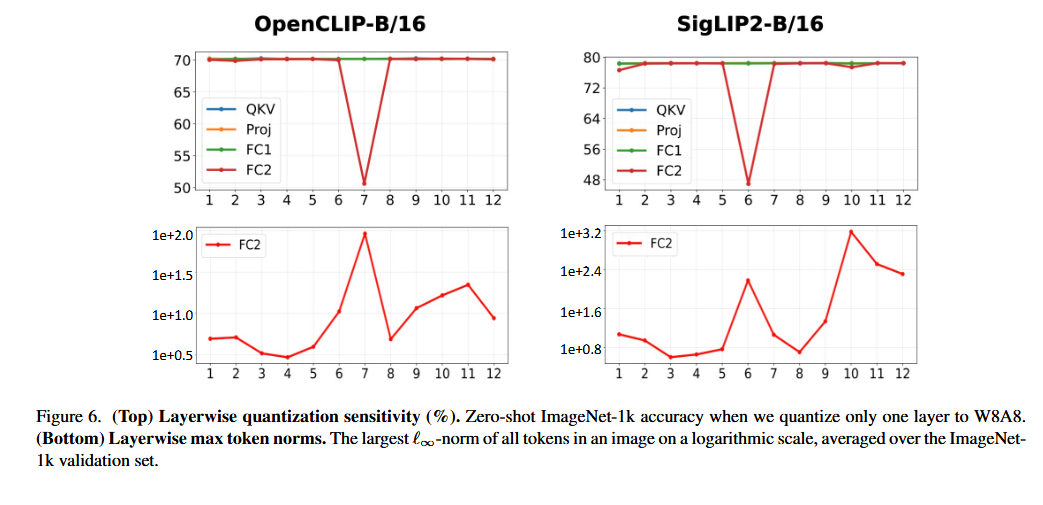
위 Figure 3 에서 볼 수 있듯이,
W8A8 양자화 시 성능이 크게 떨어지는 레이어는 중간 블록의 MLP projection layer에 집중되어 있으며, 이 지점은 activation outlier가 나타나기 시작하는 블록과 정확히 일치한다.
⇒
Outlier가 양자화 성능 저하의 주요 원인임을 보여주며, FC2 activation이나 quantization sensitivity를 모니터링하면 RegCache의 prefixing을 적용할 블록을 식별하는 데 활용할 수 있다.
공격 1: FC2 input만 모니터링하면 충분한가?
- 공격: Outlier 발생 지점을 FC2 input으로 한정했는데, DINOv2의 경우 QKV, Proj, FC1 등 다른 레이어에서도 심각한 성능 저하가 관찰된다. FC2만 보면 놓치는 부분이 있지 않은가?
- 방어: 논문 자체도 FC2 모니터링만을 유일한 방법으로 제시하지 않는다. Quantization sensitivity를 직접 측정하는 것도 prefixing 적용 블록을 식별하는 수단으로 제안하고 있으므로, FC2 모니터링이 불완전하더라도 sensitivity 측정으로 보완할 수 있다.
SigLIP2는 다른 아키텍처 대비 maximum norm이 현저히 커서 RegCache 적용 시 성능 향상 효과가 더 뚜렷했으며, 이 독특한 동작의 원인 분석은 후속 연구로 남겨두었다.
3.2. Why the middle layers?
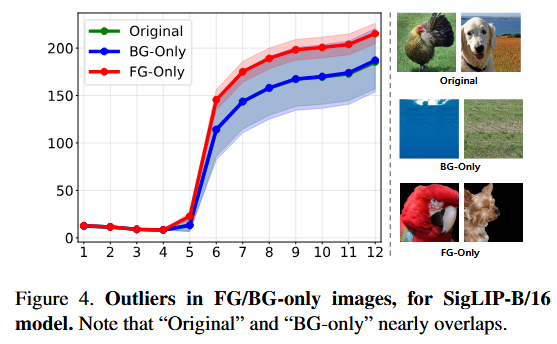
LLM은 ⟨BOS⟩ 등 의미 없는 토큰이 처음부터 명확해서 초기 레이어부터 outlier가 나타나지만,
vision encoder는 raw patch에서 의미 없는 토큰을 식별하려면 여러 블록을 거쳐야 하므로 중간 레이어에서 나타난다는 가설을 세웠다.
검증으로, 배경을 0으로 만든 foreground-only 이미지에서는 의미 없는 패치가 쉽게 식별되어 outlier가 더 일찍·더 강하게 나타났다.
또한, register와 함께 학습된 모델은 LLM처럼 초기부터 outlier가 발생하여 가설을 뒷받침했다.
3.3. Universality of outlier tokens
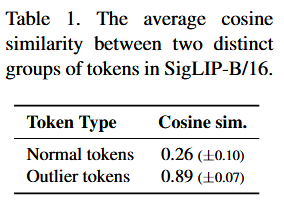
중간 레이어의 outlier token들은 이미지 간 cosine similarity가 0.89로 매우 높아(일반 토큰은 0.26), 입력에 무관한 universal한 특성을 가진다.
⇒ outlier token은 서로 유사하다.
⇒ 이는 outlier token을 미리 계산해두고 범용적으로 재사용할 수 있는 근거가 된다.
중간 레이어의 outlier token들은 이미지 간 cosine similarity가 0.89로 매우 높다(일반 토큰은 0.26).
이 높은 유사도의 원인
-
outlier가 나타나는 채널 인덱스가 이미지 간에 일정함.
-
해당 채널에서 극단적으로 큰 값을 가짐.
결과적으로 어떤 이미지를 넣든 outlier 토큰의 모습이 거의 동일하므로, 캘리브레이션 데이터에서 대표 outlier 토큰을 미리 계산해두면 임의의 새 이미지에도 범용적으로 재사용할 수 있다.
(A 이미지의 outlier 토큰을 알고 싶다...
→ 서로 다른 이미지의 outlier 토큰은 서로 비슷하게 생겼네?
→ 그럼 임의의 이미지 I의 outlier 토큰을 미리 찾자
→ I의 outlier 토큰 ≈ A의 outlier 토큰)
이것이 RegCache의 universal cache가 성립하는 근거이다.
4. Method
3장 정리
-
Vision encoders의 outliers는 중간 레이어에서 부터 나타남
-
중간 레이어에서 발견된 sink token는 이미지 전반에 걸쳐 매우 유사함
추가적인 sink tokens를 prefixing하면, outliers를 완화할 수 있다는 LLMs에서의 선행연구([45])와 결합.
⇒ "한 이미지에서 추출한 중간 레이어의 sink tokens는 다른 이미지를 처리하는 vision encoder에서 registers로 작동하여, outliers를 완화하는 데 도움을 줄 수 있다."는 가설
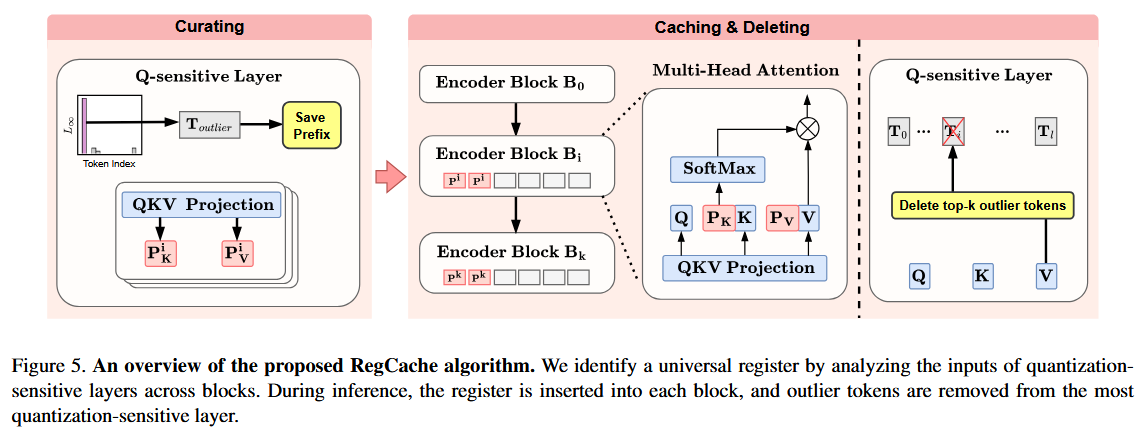
RegCache는 세 단계로 작동한다.
먼저 참조 이미지에서 큰 activation을 가진 register candidate token을 선별(Curating)하고, 이들의 key-value를 sensitive layer에 캐싱(Caching)한 뒤, 기존 내부 sink token을 삭제(Deleting)하여 outlier를 제거한다.
4.1. Curating
Pretrained vision encoder에서 각 레이어를 독립적으로 양자화(함께 쓰일 양자화 기법이 있다면, 그 양자화기법으로 함)하여 가장 큰 정확도 하락을 유발하는 quantization-sensitive layer를 식별한다. 그 뒤 참조 이미지 풀에서 해당 레이어(및 최대 3개 앞선 블록)의 상위 k개 토큰을 선별하여 register candidate set을 구축한다.
예시: SigLIP2-B/16 (12-block)을 segmentation 태스크에 GPTQ로 양자화해서 배포하는 경우
Step 1: Sensitive layer 식별
배포용 양자화 기법이 GPTQ로 정해져 있으므로, 각 레이어를 독립적으로 GPTQ로 양자화한다. 참조 태스크는 ImageNet-1k classification을 사용한다(최종 태스크가 segmentation이라도, outlier 발생 패턴은 모델 구조에 의해 결정되므로 무관). 측정 결과 block 7의 fc2 layer에서 정확도가 가장 크게 하락 → block 7의 fc2 layer가 sensitive layer.Step 2: Register candidate 선별
ImageNet 학습셋 50,000장을 모델에 통과시켜, sensitive block(block 7)과 최대 3개 앞선 block(block 4, 5, 6)에서 각각의 입력 시점의 l∞-norm 상위 100개 토큰을 선별한다. 총 4개의 독립적인 candidate set(S₄, S₅, S₆, S₇)이 구축되며, 각 set에 100개씩 총 400개의 candidate token이 확보된다. 이 토큰들은 해당 블록을 통과하기 전 상태이지만, 앞선 블록들을 거치며 이미 sink 역할을 하면서 activation이 극단적으로 커진 상태이므로 outlier에 해당한다.
4.2. Caching
각 candidate set의 토큰들에 대해 양자화되지 않은 원본 모델로 KV cache를 계산하고(sensitive block 앞 블록부터 마지막 블록까지), set별로 평균 내어 register를 구성한다. 이후 register의 복사 횟수 τ를 1~15 범위에서 탐색하여 ImageNet 정확도가 가장 높은 τ*를 선택한다.
예시: SigLIP2-B/16 (12-block)을 segmentation 태스크에 GPTQ로 양자화해서 배포하는 경우
Step 1: Sensitive layer 식별
배포용 양자화 기법이 GPTQ로 정해져 있으므로, 각 레이어를 독립적으로 GPTQ로 양자화한다. 참조 태스크는 ImageNet-1k classification을 사용한다(최종 태스크가 segmentation이라도, outlier 발생 패턴은 모델 구조에 의해 결정되므로 무관). 측정 결과 block 7의 fc2 layer에서 정확도가 가장 크게 하락 → block 7의 fc2 layer가 sensitive layer.Step 2: Register candidate 선별
ImageNet 학습셋 50,000장을 모델에 통과시켜, sensitive block(block 7)과 최대 3개 앞선 block(block 4, 5, 6)에서 각각의 입력 시점의 l∞-norm 상위 100개 토큰을 선별한다. 총 4개의 독립적인 candidate set(S₄, S₅, S₆, S₇)이 구축되며, 각 set에 100개씩 총 400개의 candidate token이 확보된다. 이 토큰들은 해당 블록을 통과하기 전 상태이지만, 앞선 블록들을 거치며 이미 sink 역할을 하면서 activation이 극단적으로 커진 상태이므로 outlier에 해당한다.Step 3: Register 구성 (KV cache 평균화)
앞서 선별한 4개의 candidate set(S₄, S₅, S₆, S₇)을 실제 사용 가능한 register로 변환한다. 양자화되지 않은 원본 SigLIP2-B/16에 각 candidate 토큰을 통과시켜, 해당 토큰이 자신의 시작 블록부터 block 12까지 각 블록에서 남기는 KV cache를 미리 계산해둔다.S₄의 100개 토큰: 각각 block 4~12에서의 KV (토큰당 9쌍) 계산 → 100개의 KV 궤적을 block별로 평균내어 register R₄ 구성 (9쌍의 평균 KV 보유)
S₅의 100개 토큰: 각각 block 5~12에서의 KV (토큰당 8쌍) 계산 → 평균내어 register R₅ 구성 (8쌍)
S₆의 100개 토큰: 각각 block 6~12에서의 KV (토큰당 7쌍) 계산 → 평균내어 register R₆ 구성 (7쌍)
S₇의 100개 토큰: 각각 block 7~12에서의 KV (토큰당 6쌍) 계산 → 평균내어 register R₇ 구성 (6쌍)결과적으로 4개의 register(R₄, R₅, R₆, R₇)가 만들어지며, 총 30쌍(9+8+7+6)의 평균 KV cache를 보유하게 된다. 블록별로 삽입될 KV 쌍을 정리하면 다음과 같다:
Block 4: S₄의 K₄V₄ (1쌍)
Block 5: S₄의 K₅V₅, S₅의 K₅V₅ (2쌍)
Block 6: S₄의 K₆V₆, S₅의 K₆V₆, S₆의 K₆V₆ (3쌍)
Block 7: S₄의 K₇V₇, S₅의 K₇V₇, S₆의 K₇V₇, S₇의 K₇V₇ (4쌍)
Block 8: S₄의 K₈V₈, S₅의 K₈V₈, S₆의 K₈V₈, S₇의 K₈V₈ (4쌍)
Block 9: S₄의 K₉V₉, S₅의 K₉V₉, S₆의 K₉V₉, S₇의 K₉V₉ (4쌍)
Block 10: S₄의 K₁₀V₁₀, S₅의 K₁₀V₁₀, S₆의 K₁₀V₁₀, S₇의 K₁₀V₁₀ (4쌍)
Block 11: S₄의 K₁₁V₁₁, S₅의 K₁₁V₁₁, S₆의 K₁₁V₁₁, S₇의 K₁₁V₁₁ (4쌍)
Block 12: S₄의 K₁₂V₁₂, S₅의 K₁₂V₁₂, S₆의 K₁₂V₁₂, S₇의 K₁₂V₁₂ (4쌍)이 과정은 한 번만 수행되고 이후 추론 단계에서 재사용되므로, 실시간 오버헤드가 없다.
Step 4: 최적 복사 횟수
τ∗ 탐색
구성된 4개의 register를 GPTQ로 양자화된 SigLIP2-B/16에 삽입하되, 복사 횟수를 달리해가며 검증한다. 값을 바꿔가며 Step 3에서 정리한 블록별 KV 쌍들을 번씩 복사해 삽입한 후, 각 설정에서 ImageNet 학습셋 classification 정확도를 측정한다.
- τ=1: Step 3의 KV 쌍들을 그대로 1번씩 삽입 → 정확도 측정
- τ=2: 각 KV 쌍을 2번씩 복사해 삽입 (예: Block 4에 K₄V₄가 2개, Block 7에 8개 등) → 정확도 측정
- τ=3,4,…,15까지 동일하게 반복
예컨대 τ=5일 때 정확도가 가장 높다면 = 5로 결정. 이때 τ를 무작정 키운다고 정확도가 계속 오르지는 않는다.
너무 적으면 sink token 대체 효과가 부족하고, 너무 많으면 일반 patch token들의 attention 신호가 register 쪽으로 희석되어 오히려 성능이 떨어지므로, 중간 지점에서 최대값이 나타난다.
4.3. Deleting
테스트 이미지 추론 시, quantization-sensitive block 입력에서 l∞-norm 상위 개의 토큰을 선택해 삭제한다. 이는 내부적으로 새롭게 발생하는 sink token을 제거하여 잔존 outlier를 소거하는 역할을 하며, ̃ 값도 참조 태스크로 튜닝된다.
예시: SigLIP2-B/16 (12-block)을 segmentation 태스크에 GPTQ로 양자화해서 배포하는 경우
Step 1: Sensitive layer 식별
배포용 양자화 기법이 GPTQ로 정해져 있으므로, 각 레이어를 독립적으로 GPTQ로 양자화한다. 참조 태스크는 ImageNet-1k classification을 사용한다(최종 태스크가 segmentation이라도, outlier 발생 패턴은 모델 구조에 의해 결정되므로 무관). 측정 결과 block 7의 fc2 layer에서 정확도가 가장 크게 하락 → block 7의 fc2 layer가 sensitive layer.Step 2: Register candidate 선별
ImageNet 학습셋 50,000장을 모델에 통과시켜, sensitive block(block 7)과 최대 3개 앞선 block(block 4, 5, 6)에서 각각의 입력 시점의 l∞-norm 상위 100개 토큰을 선별한다. 총 4개의 독립적인 candidate set(S₄, S₅, S₆, S₇)이 구축되며, 각 set에 100개씩 총 400개의 candidate token이 확보된다. 이 토큰들은 해당 블록을 통과하기 전 상태이지만, 앞선 블록들을 거치며 이미 sink 역할을 하면서 activation이 극단적으로 커진 상태이므로 outlier에 해당한다.Step 3: Register 구성 (KV cache 평균화)
앞서 선별한 4개의 candidate set(S₄, S₅, S₆, S₇)을 실제 사용 가능한 register로 변환한다. 양자화되지 않은 원본 SigLIP2-B/16에 각 candidate 토큰을 통과시켜, 해당 토큰이 자신의 시작 블록부터 block 12까지 각 블록에서 남기는 KV cache를 미리 계산해둔다.S₄의 100개 토큰: 각각 block 4~12에서의 KV (토큰당 9쌍) 계산 → 100개의 KV 궤적을 block별로 평균내어 register R₄ 구성 (9쌍의 평균 KV 보유)
S₅의 100개 토큰: 각각 block 5~12에서의 KV (토큰당 8쌍) 계산 → 평균내어 register R₅ 구성 (8쌍)
S₆의 100개 토큰: 각각 block 6~12에서의 KV (토큰당 7쌍) 계산 → 평균내어 register R₆ 구성 (7쌍)
S₇의 100개 토큰: 각각 block 7~12에서의 KV (토큰당 6쌍) 계산 → 평균내어 register R₇ 구성 (6쌍)결과적으로 4개의 register(R₄, R₅, R₆, R₇)가 만들어지며, 총 30쌍(9+8+7+6)의 평균 KV cache를 보유하게 된다. 블록별로 삽입될 KV 쌍을 정리하면 다음과 같다:
Block 4: S₄의 K₄V₄ (1쌍)
Block 5: S₄의 K₅V₅, S₅의 K₅V₅ (2쌍)
Block 6: S₄의 K₆V₆, S₅의 K₆V₆, S₆의 K₆V₆ (3쌍)
Block 7: S₄의 K₇V₇, S₅의 K₇V₇, S₆의 K₇V₇, S₇의 K₇V₇ (4쌍)
Block 8: S₄의 K₈V₈, S₅의 K₈V₈, S₆의 K₈V₈, S₇의 K₈V₈ (4쌍)
Block 9: S₄의 K₉V₉, S₅의 K₉V₉, S₆의 K₉V₉, S₇의 K₉V₉ (4쌍)
Block 10: S₄의 K₁₀V₁₀, S₅의 K₁₀V₁₀, S₆의 K₁₀V₁₀, S₇의 K₁₀V₁₀ (4쌍)
Block 11: S₄의 K₁₁V₁₁, S₅의 K₁₁V₁₁, S₆의 K₁₁V₁₁, S₇의 K₁₁V₁₁ (4쌍)
Block 12: S₄의 K₁₂V₁₂, S₅의 K₁₂V₁₂, S₆의 K₁₂V₁₂, S₇의 K₁₂V₁₂ (4쌍)이 과정은 한 번만 수행되고 이후 추론 단계에서 재사용되므로, 실시간 오버헤드가 없다.
Step 4: 최적 복사 횟수
τ∗ 탐색
구성된 4개의 register를 GPTQ로 양자화된 SigLIP2-B/16에 삽입하되, 복사 횟수를 달리해가며 검증한다. 값을 바꿔가며 Step 3에서 정리한 블록별 KV 쌍들을 번씩 복사해 삽입한 후, 각 설정에서 ImageNet 학습셋 classification 정확도를 측정한다.
- τ=1: Step 3의 KV 쌍들을 그대로 1번씩 삽입 → 정확도 측정
- τ=2: 각 KV 쌍을 2번씩 복사해 삽입 (예: Block 4에 K₄V₄가 2개, Block 7에 8개 등) → 정확도 측정
- τ=3,4,…,15까지 동일하게 반복
예컨대 τ=5일 때 정확도가 가장 높다면 = 5로 결정. 이때 τ를 무작정 키운다고 정확도가 계속 오르지는 않는다.
너무 적으면 sink token 대체 효과가 부족하고, 너무 많으면 일반 patch token들의 attention 신호가 register 쪽으로 희석되어 오히려 성능이 떨어지므로, 중간 지점에서 최대값이 나타난다.
Step 5: Token Deletion 설정 (k̃ 튜닝)
남아 있는 sink token을 제거하기 위한 최적의 삭제 개수 k̃를 결정한다. 테스트 이미지가 주어지면 block 7(sensitive block)의 입력에서 197개 토큰 중 l∞-norm이 가장 큰 k̃개를 선택해 해당 블록에서 제거한다. k̃ 값을 {1, 2, ...} 범위에서 변화시키며 ImageNet 학습셋 classification 정확도를 측정하여 최적값을 선택한다. 예컨대 k̃=2일 때 정확도가 가장 높다면 k̃*=2로 결정. 이때 k̃가 너무 작으면 잔존 outlier가 남아 양자화 range가 여전히 넓고, 너무 크면 정보 있는 패치까지 지워져 성능이 떨어지므로, 중간 지점에서 최대값이 나타난다.
추론 시 outlier 흐름
1. Block 1~3: 아무 처리 없이 일반 forward pass. 아직 outlier가 발생하지 않은 초기 단계이므로 개입 불필요.
2. Block 4~6 (앞선 블록들):
이 블록들의 attention에 register KV가 prefix로 삽입된다(block 4에 R₄, block 5에 R₄·R₅, block 6에 R₄·R₅·R₆). 일반 패치 토큰들이 attention을 계산할 때, 원래는 특정 배경 패치에 attention이 쏠리면서 그 토큰이 sink 역할을 하게 되는데, 이제 prefix로 들어온 register가 그 attention을 대신 흡수한다. 결과적으로 일반 패치 토큰에 outlier가 누적되는 정도가 크게 줄어든다.
3. Block 7 (sensitive block):
- Attention에는 register KV(R₄·R₅·R₆·R₇)가 prefix로 삽입되어 attention을 흡수
- 그럼에도 여전히 일부 패치 토큰에 잔존 outlier가 남아있을 수 있으므로, block 7 입력에서 l∞-norm 상위 k̃개의 토큰을 삭제하여 제거
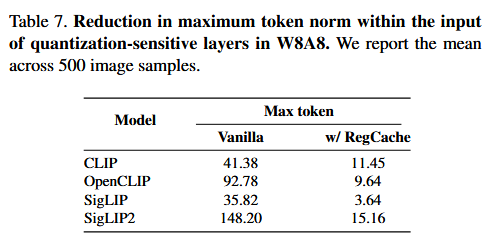
이 두 조치로 block 7의 FC2 입력 activation range가 극적으로 좁아진다(논문 Table 7: SigLIP2의 경우 max token norm 148.20 → 15.16, 약 10배 감소).
4. Block 8~12: Register만 prefix로 유지된 채 forward 진행. Block 7에서 outlier가 제거된 깔끔한 hidden state가 이후 블록으로 전파된다.
결과:
-
Block 7 FC2의 activation dynamic range가 좁아져, GPTQ의 양자화 스케일이 훨씬 촘촘해짐 → 양자화 오차 대폭 감소
-
4-bit처럼 극저비트에서 효과가 특히 큼(Table 2 기준 SigLIP2 W4A4에서 baseline 대비 최대 +18.42%p 향상)
-
추가 학습 없이, 추론 시 오버헤드는 1~2% 수준(Table 6)
-
결국 GPTQ 단독으로 양자화했을 때보다 FP32에 훨씬 가까운 정확도로 segmentation 수행 가능
5. Experiments
DINOv2: self-supervised 학습된 특성상 CLIP/SigLIP과 동작이 달라, prefix를 searched layer에만 삽입할 때 더 좋은 결과 → 이 모델만 예외적 처리
5.2. Main results
ImageNet-1k에서 zero-shot classification acc.
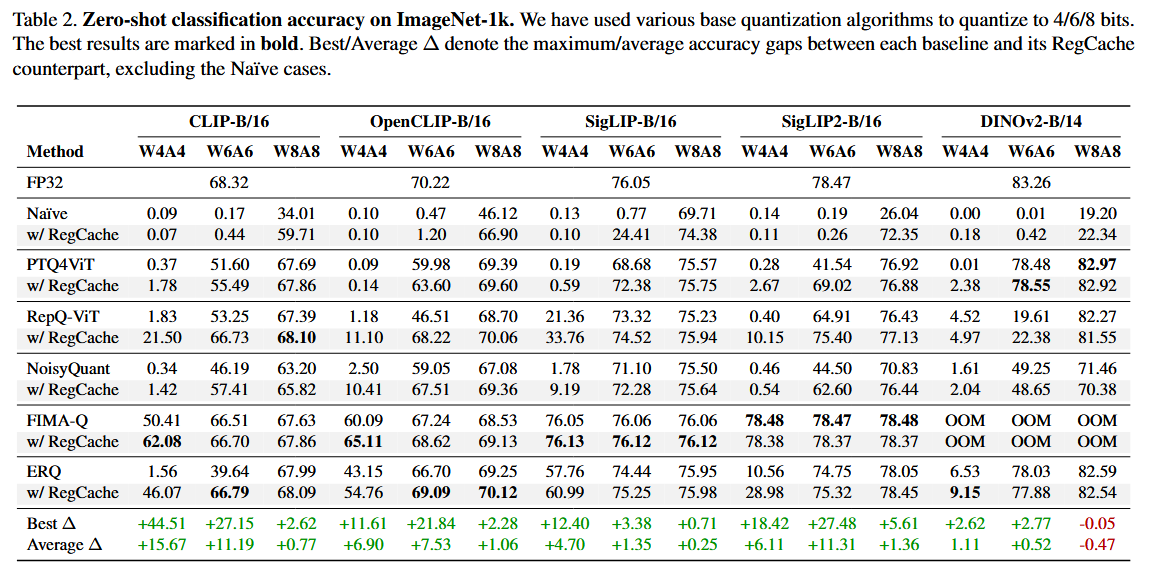
- 4-bit, 6-bit 등 저비트일수록 outlier 영향이 심해져 RegCache의 이점이 더 커진다.
MS-COCO에서 zero-shot image-text retrieval
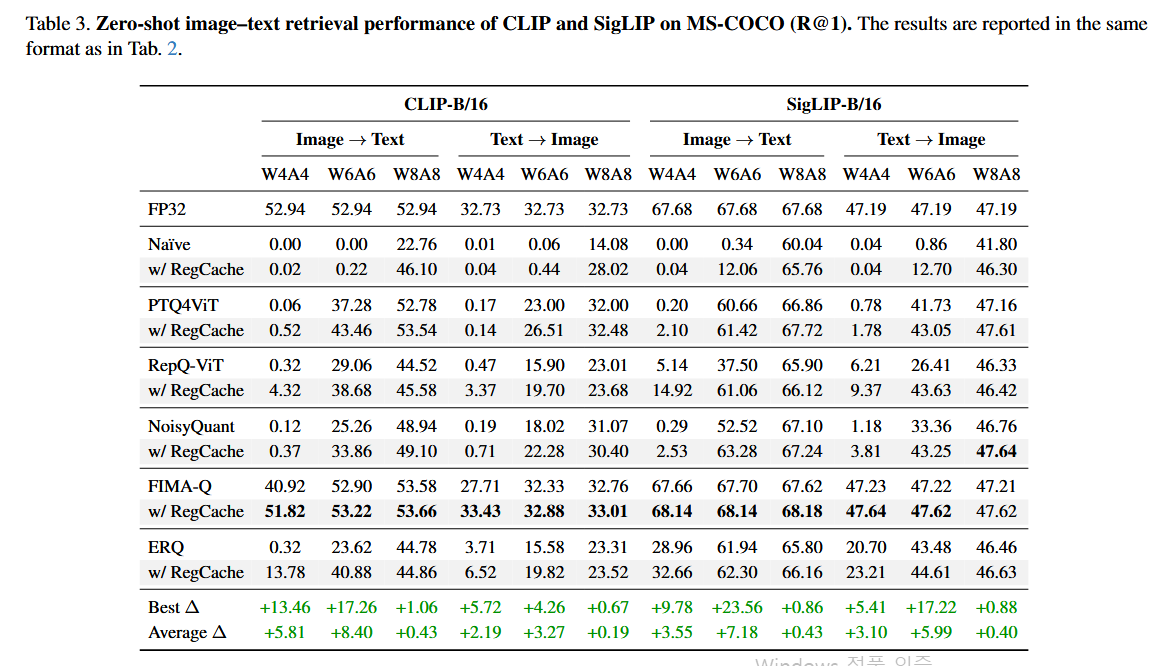
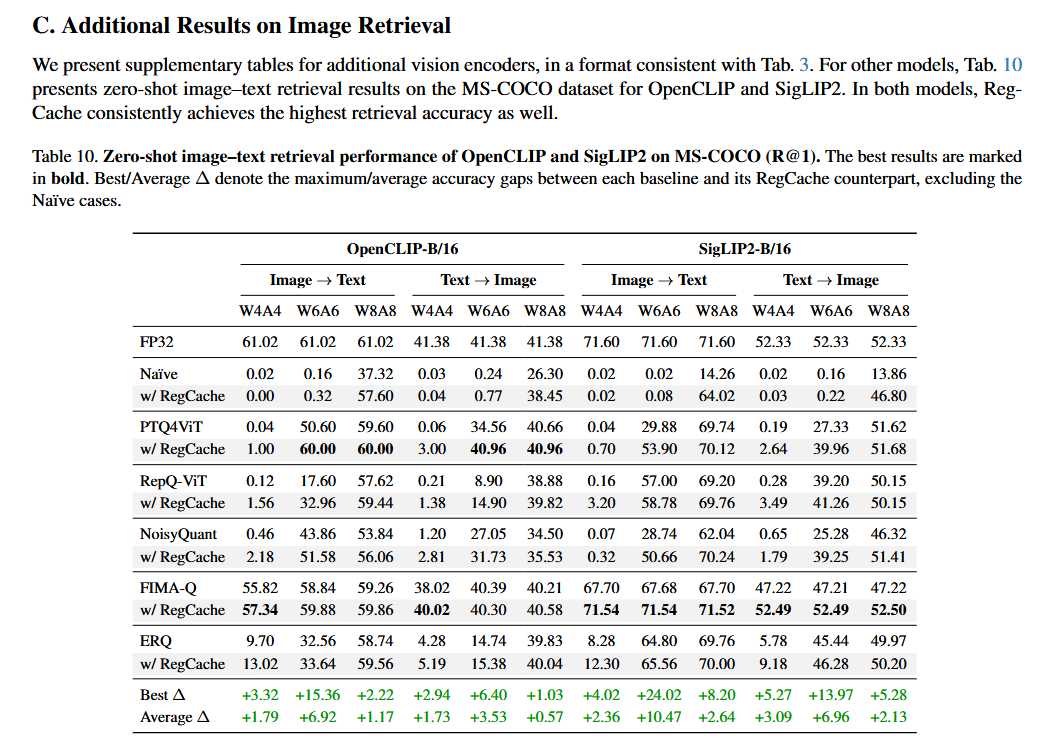
- 4-bit, 6-bit 등 저비트일수록 outlier 영향이 심해져 RegCache의 이점이 더 커진다.
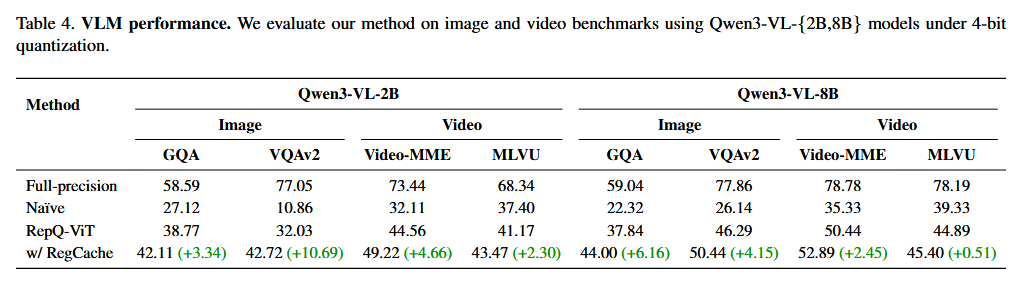
VLM performance
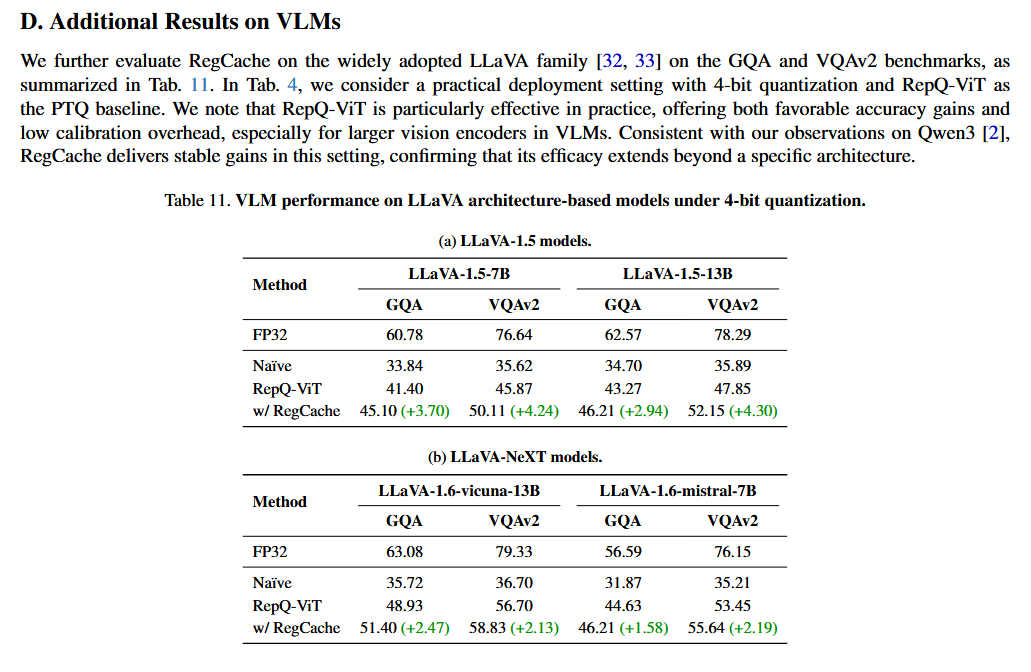
Prefix 탐색 과정에서 ImageNet-1k에 overfit 되어 다른 dataset에서의 generalizability가 떨어지는 지 확인
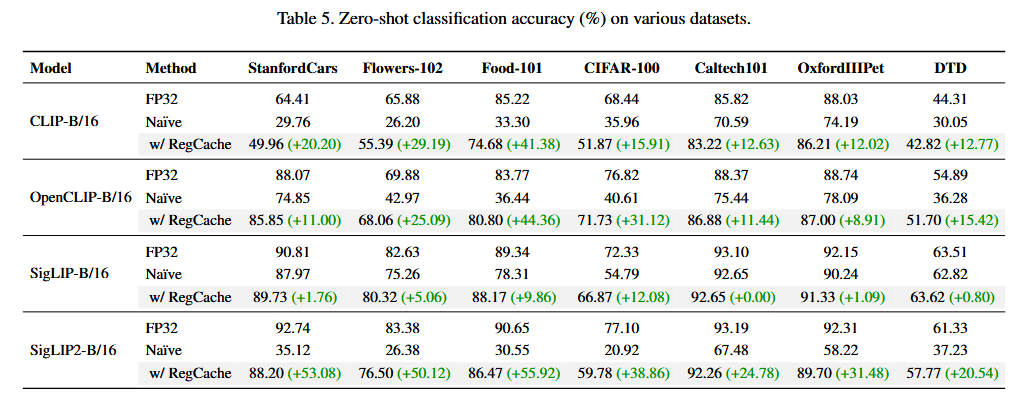
아쉬운 점
Table 2를 보면 저자들도 Naïve 결과는 "excluding the Naïve cases"라고 명시하면서 Best/Average ∆ 계산에서 제외했다.
Naïve quantization은 베이스라인 자체가 너무 낮아서 거기서의 개선은 실질적인 의미가 희석되기 때문인 것 같다.
그런데 Table 5 (다양한 데이터셋에서의 universality 실험)는 오직 Naïve + RegCache 조합만 보고하고 있다.
이게 아쉬운 이유는:
- 주장과 실험 설계의 불일치 — Table 5의 목적은 "ImageNet-1k에서 찾은 prefix가 다른 도메인에도 일반화되는가"를 보이는 건데, PTQ4ViT, RepQ-ViT, ERQ 등 실질적인 PTQ 방법들과의 조합에서도 같은 generalization 효과가 나타나는지는 확인이 안 된다.
만약 Table 5에서 RepQ-ViT나 ERQ 같은 강한 PTQ baseline과의 조합도 함께 보고했다면, prefix의 universality 주장이 훨씬 설득력 있게 뒷받침됐을 것 같다.

이런식의 대충 진행한 리뷰 보고 싶지 않습니다. 정진 부탁드립니다..