DINOv3
DINOv3에 대한 내용
참고하면 좋은 유튜브
Abstract
- 좋은 데이터 준비 + 설계 디자인 ⇒ 데이터 셋, 모델 scale up
- 학습 길어짐 ⇒ 세밀한 특징에 대한 인지 저하 (너무 러프하게 이미지를 봄) ⇒ Gram anchoring
- 모델 유연성 ↑
1. Introduction
SSL: 메타데이터(라벨링) 없는 데이터로 학습
⇒
입력 분포 변화에 견고,
강한 전역/지역 특징 제공
⇒
이미지 내 패턴의 자연스러운 공통 발생 활용
모델 scale up 미해결 과제
- 데이터 수집 어케하지?
⇒ - 코사인 스케줄 사용 X
⇒ - 학습 계속 ⇒ 국소 특징 질 저하
⇒ Gram anchoring
Strong & Versatile Foundational Models
- fine tuning 없이도, 기존 finetuned 모델보다 좋음
- 과학적 응용 good
Superior Feature Maps Through Gram Anchoring
SSL
⇒ data ↑
⇒ 전역적 표현 학습
⇒ 조밀한 특징 질 저하
The DINOv3 Family of Models
Gram anchoring
⇒ 모델 scale up 가능
⇒ 7B 모델 (DINO) 성공
+
distillation
⇒ 더 작은 모델 ㄱㄴ
2. Related Work
SSL
SSL (자기 지도 학습)은 어노테이션 없이 인위적인 학습 과제(Pre-text tasks)를 통해 데이터의 표현을 학습하며,
신호가 연속적인 컴퓨터 비전 분야는 언어 분야보다 이러한 과제 설계의 난도가 높습니다.
이미지의 일부를 복원하는 인페인팅(Inpainting) 기반 방식은 MAE(Masked Auto-Encoder)와 JEPA(Joint-Embedding Predictive Architecture) 등으로 발전하며 고수준의 시각 특징을 추출하는 데 성공했습니다.
잠재 공간을 예측하는 JEPA 의 방식은 iBOT 에 이르러 이미지 간 차이를 식별하는 판별적 손실 함수 와 결합되며 더욱 정교하고 강력한 시각 표현 학습으로 발전했습니다.
1. Summarization
Pixel 기반 방식이 이미지의 외형적인 "복사"에 집중한다면, Latent Space 예측 방식은 이미지 속에 담긴 객체의 본질적인 "의미" (Semantic Representation) 를 추론하는 것이 목적입니다.
2. Example
이 차이를 "고양이의 귀" 부분이 마스킹 된 상황으로 비유하여 구체적인 수치와 함께 설명하겠습니다.
- Pixel-based (MAE): 마스킹 된 영역의 픽셀 값 개 ( RGB) 를 하나하나 맞추려 노력합니다. 만약 조명이 어둡거나 노이즈가 섞여 있다면, 모델은 본질적인 "고양이 귀" 의 형태보다는 픽셀의 어두운 색상 값을 복원하는 데 더 많은 계산 자원을 소모하게 됩니다.
- Latent-based (JEPA / DINOv3): Target Encoder 가 해당 영역을 보고 생성한 차원의 고차원 벡터를 예측합니다. 이 벡터 안에는 "이것은 동물의 귀이며, 뾰족한 형태를 가졌고, 털 질감을 가졌다" 라는 High-level semantic 정보가 압축되어 있습니다. 모델은 픽셀의 미세한 색상 차이보다는, 그 위치에 어떤 특징 (Feature) 이 와야 하는지 그 "맥락" 을 맞추는 데 집중합니다.
3. Conclusion
결론적으로, 픽셀 자체를 복구하는 것은 조명이나 각도 변화 같은 불필요한 정보 (Redundancy) 까지 학습하게 만들 수 있습니다. 반면, Latent Space 를 예측 목표로 삼으면 모델은 이미지의 지엽적인 노이즈를 무시하고 객체의 형태, 구조, 종류와 같은 핵심적인 Visual representation 을 더 효과적으로 학습하게 됩니다. 이것이 DINOv3 가 다양한 Downstream tasks 에서 강력한 성능을 내는 근본적인 이유입니다.
Vision Foundataion Models
생략
Dense Transformer Features
생략
3. Training at Scale Without Supervision
데이터 셋 확장
⇒ 모델 확장
+
SSL ⇒ 특정 작업 국한 X, 범용 vision 분야 가능
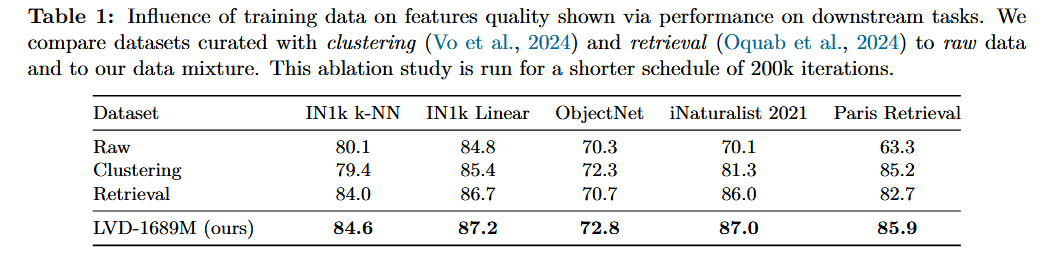
3.1. Data Preparation
단순 양 증가 보단,
좋은 데이터 양 증가
Data Collection and Curation
-
계층적 클러스터링 기반 큐레이션: Vo et al. (2024) 의 계층적 k-means 기반 자동 큐레이션 방식을 적용했습니다. DINOv2 를 이미지 임베딩으로 사용하고, 5단계의 클러스터링을 적용했습니다 (클러스터 수는 최하위부터 최상위까지 각각 2억 개, 800만 개, 80만 개, 10만 개, 2.5만 개). 계층 구조를 구축한 후 균형 잡힌 샘플링 알고리즘을 적용하여, 웹에 등장하는 모든 시각적 개념을 균형 있게 포괄하는 16억 8,900만 장의 큐레이션된 하위 집합 (LVD-1689M) 을 구축했습니다.
-
검색 기반 큐레이션: Oquab et al. (2024) 이 제안한 절차와 유사한 검색 기반 시스템을 채택했습니다. 선택된 시드 (seed) 데이터셋과 유사한 이미지를 데이터 풀에서 검색하여, 다운스트림 작업과 관련된 시각적 개념을 다루는 데이터셋을 생성했습니다.
-
공개 데이터셋 활용: ImageNet1k (Deng et al., 2009), ImageNet22k (Russakovsky et al., 2015), 그리고 Mapillary Street-level Sequences (Warburg et al., 2020) 를 포함한 공개 컴퓨터 비전 데이터셋을 사용했습니다. 이 마지막 부분은 Oquab et al. (2024) 을 따라 모델의 성능을 최적화하는 역할을 합니다.
Q1.
계층적 클러스터링을 통한 자동 정제에서 임베딩 추출 부분에서 DINOv2를 사용해서 image to vector로 변환했다고 하는데, DINOv2는 이미지를 벡터로 만들어줘?A1. DINOv2와 임베딩 (Embedding) 추출
DINOv2 는 비전 트랜스포머 (Vision Transformer) 기반의 자가 지도 학습 모델로, 이미지를 입력받아 해당 이미지의 시각적 특징을 함축하고 있는 고차원 벡터로 변환하는 역할을 합니다. 이를 임베딩 (Embedding) 이라 부릅니다. 즉, 사진이라는 데이터를 컴퓨터가 계산할 수 있는 숫자 나열(벡터)로 바꾸어 주는 것이 맞습니다. 이렇게 벡터화가 되어야만 이미지 사이의 유사도를 계산하거나 클러스터링을 할 수 있습니다.Q2.
계층적 클러스터링을 통한 자동 정제에서 계층적 K-means 알고리즘으로 비슷한 특징을 갖는 데이터를 묶었다고 하는데, 그럼 원시 데이터 170억장을 1단계에서는 2억개의 그룹으로 분류해서 각 그룹에 170억/2억 개의 이미지가 들어있다는 거야?A2. 계층적 K-means 알고리즘의 구조
네, 이해하신 개념이 맞습니다. 다만 계층 구조를 이해할 필요가 있습니다.
- 1단계 (Lowest Level): 억 장의 원시 데이터를 억 개의 매우 세밀한 그룹으로 나눕니다. 산술적으로는 평균 억 억 약 장의 이미지가 각 그룹(클러스터)에 들어가는 셈입니다.
- 상위 단계로 이동: 이후 이 억 개의 그룹들을 다시 비슷한 것끼리 묶어 만 개, 만 개, 만 개, 최종적으로는 만 천 개의 큰 그룹으로 계층화합니다.
- 결과적으로 거대한 이미지 더미가 "대분류 - 중분류 - 소분류 - 아주 세밀한 분류"의 트리 구조로 정리되는 것입니다.
Q3.
계층적 클러스터링을 통한 자동 정제에서 각 계층 구조에서 골고루 뽑았다는 게 뭐지?A3. 계층 구조에서의 균형 샘플링 (Balanced Sampling)
균형 샘플링 이란 특정 카테고리의 데이터만 너무 많이 뽑히지 않도록 조절하는 것입니다. 인터넷 데이터에는 셀카, 풍경, 음식 사진은 엄청나게 많지만, 희귀한 동물이나 특수 장비 사진은 매우 적습니다. 만약 무작위로 뽑는다면 모델은 셀카만 공부하게 될 것입니다. 하지만 앞서 만든 계층 구조(클러스터)를 이용해 모든 그룹에서 골고루 데이터를 추출하면, 흔한 이미지의 비중은 줄이고 희귀한 시각적 개념의 비중을 높여 전 세계의 다양한 시각적 정보를 빠짐없이 학습할 수 있게 됩니다.Q4.
검색 기반 큐레이션에서 결국 170억개 데이터 중에 일부를 추출했다는 거지?A4. 검색 기반 큐레이션의 대상맞습니다. 검색 기반 큐레이션 역시 처음에 확보한 억 장 의 거대한 데이터 풀에서 필요한 것만 골라내는 과정입니다. 전체 데이터 중 우리가 관심 있는 특정 분야와 닮은 것들만 "검색"해서 추출한 것입니다.
Q5.
검색 기반 큐레이션에서 일부 데이터 추출이 어떻게 다운스트림 태스크와 관련된 시각적 개념을 집중시키지?A5. 다운스트림 태스크와 시각적 개념의 집중
다운스트림 태스크 (Downstream Task) 란 모델이 최종적으로 해결해야 할 구체적인 문제(예: 의료 영상 판독, 자율 주행 도로 인식 등)를 의미합니다.
- 시드 데이터셋 (Seed Dataset): 우리가 목표로 하는 태스크와 밀접한 관련이 있는 검증된 데이터입니다.
- 집중 과정: 이 시드 데이터와 유사한 이미지를 억 장 중에서 찾아내면, 모델은 해당 분야의 시각적 특징(질감, 형태, 구도 등)을 더 집중적으로 학습하게 됩니다. 결과적으로 실제 현장에 적용했을 때 더 높은 성능을 내는 최적화된 데이터셋 이 구축됩니다.
Q6. 그래서 결과적으로 총 데이터 수가 뭐야?
A6. 최종 데이터 수 텍스트에 명시된 부분과 수치 관계를 정리하면 다음과 같습니다.
- 첫 번째 파트 (LVD-1689M): 계층적 클러스터링의 결과물인 16억 8,900만 장 () 입니다.
- 두 번째 파트 (검색 기반): 억 장 중 시드 데이터와 유사한 이미지들입니다.
- 세 번째 파트 (공개 데이터셋): ImageNet 등을 포함한 약 만 장 내외입니다.
- 전체 학습 데이터셋: 실제 총합은 억 만 장 + (Part 2) + 약 만 장 (Part 3) 입니다. 하지만 Part 1 의 비중이 % 이상으로 압도적이기 때문에, 논문에서는 최종 결과물을 메인 데이터셋 명칭인 LVD-1689M 으로 통칭합니다.
Data Sampling
ImageNet1k로만 구성된 균일 배치를 전체 훈련의 10%
+
나머지 90%는 다른 모든 구성 데이터셋을 혼합한 불균일 배치
Data Ablation
3.2. Large-Scale Training with Self-Supervision
모델 크기를 키우면서,
전역 및 지역적 특성을 모두 개선하자!
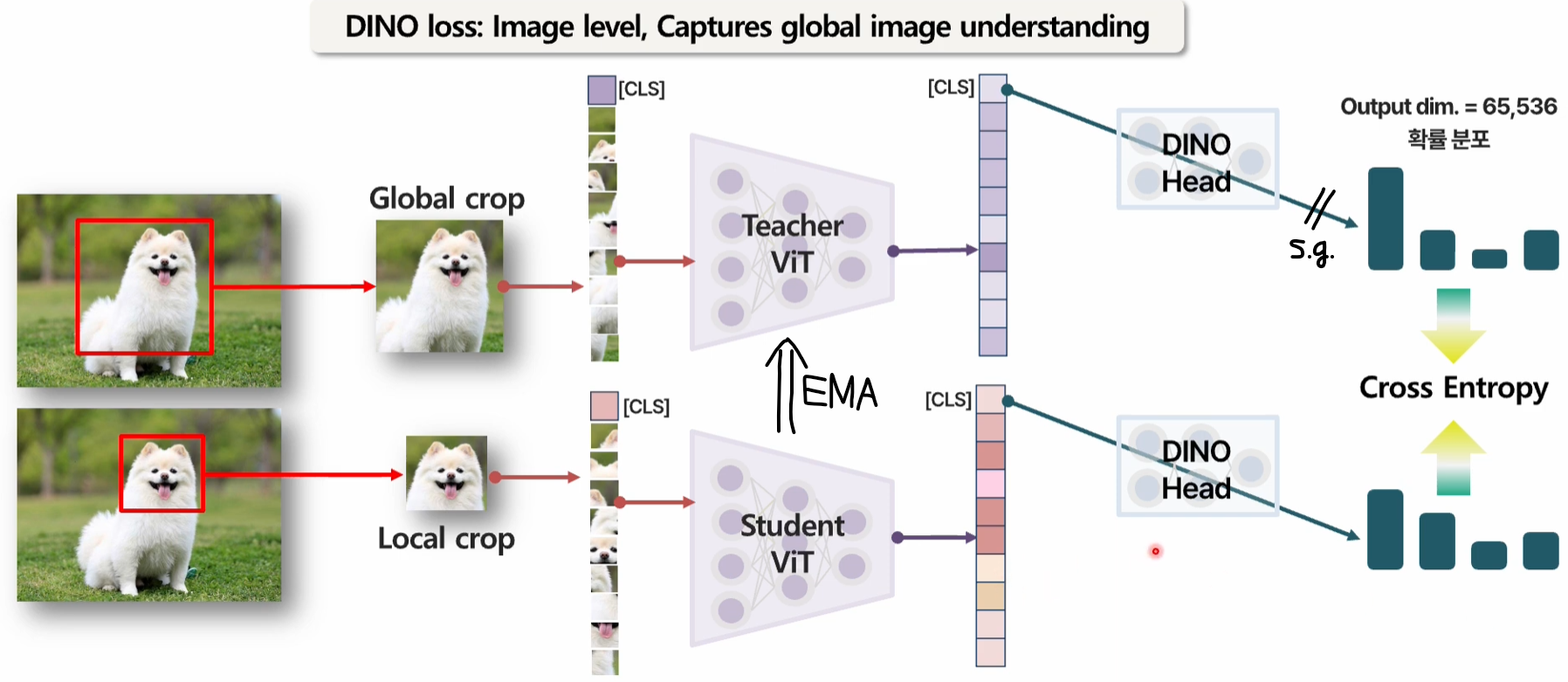
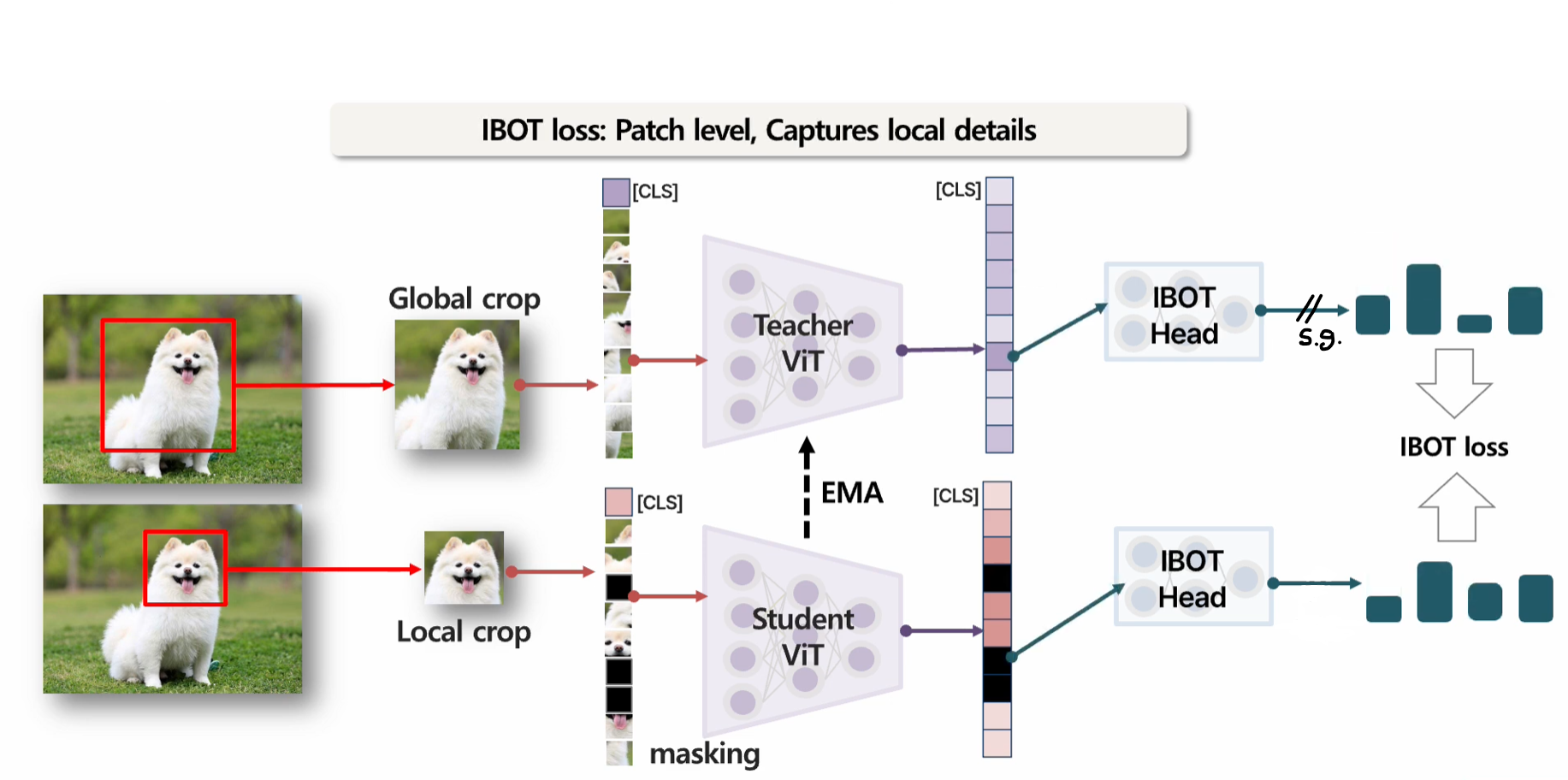
Learning Objective
-
: 이미지 전체의 전역적 특징을 학습하는 이미지 레벨 손실 함수입니다.
-
: 이미지 내부 패치의 국소적 특징을 학습하는 패치 레벨 손실 함수입니다.
-
: 배치 내 특징들을 공간상에 균일하게 분산시켜 특징 붕괴를 방지하는 규제 항입니다.
- (Image-level Objective): 이미지 전체를 대상으로 하는 손실 함수입니다. 이미지의 글로벌 특징(Global Features)을 학습하며, 서로 다른 뷰(View)의 이미지가 유사한 특징을 갖도록 유도하는 이미지 단위 의 목표를 가집니다.
- (Patch-level Objective): 이미지 내의 특정 패치(Patch)들을 대상으로 하는 손실 함수입니다. 이미지의 일부를 가리고(Masking) 이를 복원하는 잠재적 재구성(Latent Reconstruction) 과정을 통해 국소적인 특징 (Local Features)을 학습하도록 돕습니다.
아래 그림에는 student에서 local crop을 사용하는 것 처럼 표현되었는데, 아닌 것 같음...
이때, 동일한 아키텍처, 다른 가중치를 사용함.
교사()와 학생() 모두 동일한 백본(예: )을 사용합니다. 하지만 실시간으로 학습되는 학생 모델과 달리, 교사 모델은 학생 모델의 과거 기록을 바탕으로 만들어진 '복제본' 에 가깝습니다.
- (Koleo Regularizer): 배치(Batch) 내의 특징들이 공간상에 골고루(Uniformly) 퍼지도록 장려하는 규제 항입니다. 특정 특징들이 한곳으로 뭉치는 붕괴(Collapse) 현상을 방지하며, 특징 공간을 효율적으로 활용하게 만듭니다.


Updated Model Architecture
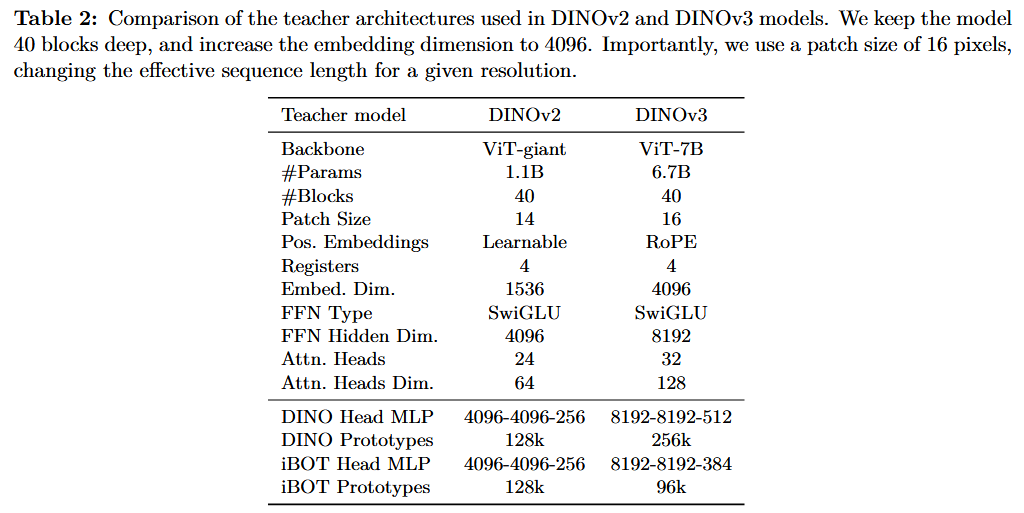
Optimization
-
복잡한 스케줄링 대신 상수 값을 써서 학습 기간을 유연하게 늘릴 수 있도록 설계
-
초기 안정성을 위해 선형 웜업을 사용
-
데이터 이해도를 높이기 위해 글로벌/로컬 크롭을 섞어 씀
-
AdamW
-
10만 회의 웜업
-
0.0004의 일정한 학습률
-
0.04의 가중치 감쇠
-
레이어당 0.98의 학습률 감쇠 계수
-
0.4의 레이어 드롭아웃
-
교사 모델에 대해 0.999의 EMA 계수
우리는 모든 학생 지역 크롭과 두 교사 전역 크롭의 클래스 토큰, 그리고 두 모델의 서로 다른 전역 크롭 쌍 사이에 손실을 적용합니다.
학생이 보는 전역 크롭 패치 토큰 중 사이의 무작위 비율을 50% 의 확률로 마스킹하며, 이들과 교사 EMA 가 보는 가시적 토큰 사이에 손실을 적용합니다.
학생이 보는 첫 번째 전역 크롭의 클래스 토큰 16개로 구성된 소규모 배치에는 손실을 적용합니다.
4. Gram Anchoring: A Regularization for Dense Features
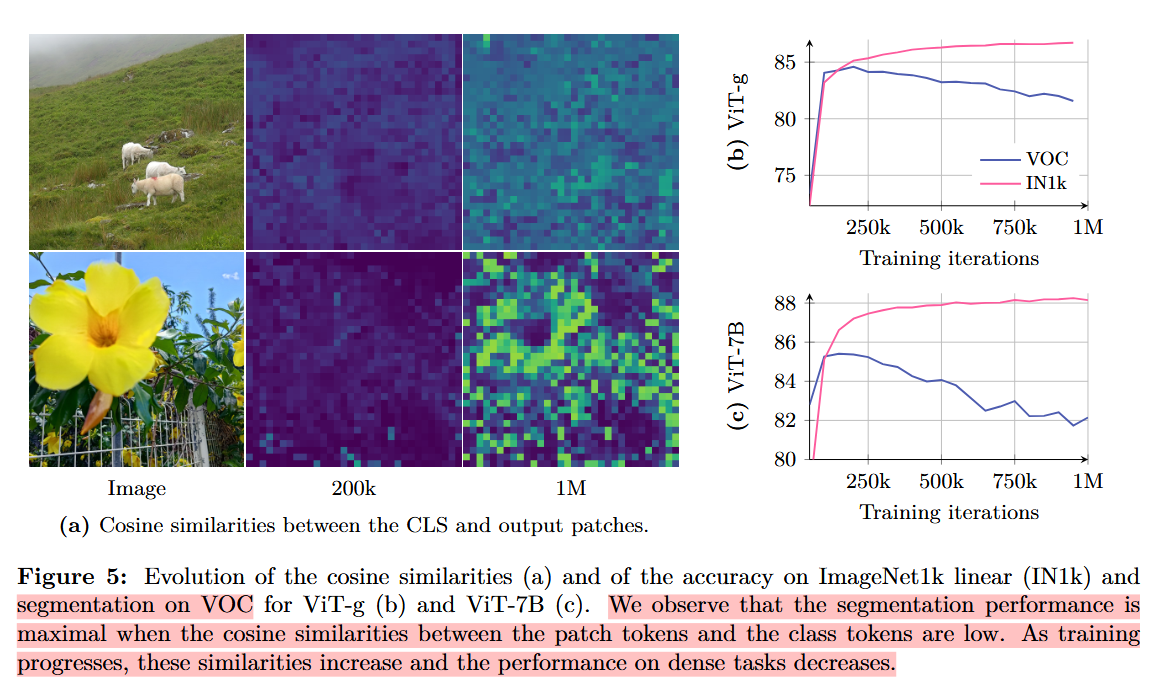
Gram anchoring을 통한 지역적 작업 성능 향상
4.1. Loss of Patch-Level Consistency Over Training

60만 회 이후부터는 유사도 지도가 상당히 모호해짐
⇒
참조 패치와 무관한 패치들이 높은 유사도를 보임
CLS 토큰과 패치 간 유사도 증가가 국소성(Locality) 감소를 의미하는 이유?
CLS 토큰 은 이미지 전체의 정보를 요약하는 전역적(Global) 특징을 담습니다. 이와 패치들 사이의 유사도가 높아진다는 것은 다음과 같은 상황을 의미합니다.
정보의 획일화: 원래 각 패치(Patch) 는 이미지의 특정 부분(국소적 특징)만 선명하게 보여줘야 합니다. 그런데 전역 정보를 담은 CLS 토큰 과 너무 비슷해지면, 각 패치가 자기만의 고유한 지역 정보를 잃어버리고 전체적인 배경 정보만 똑같이 공유 하게 됩니다.
해상도 저하: 결과적으로 모든 패치가 비슷비슷한 전역 정보만 내뱉게 되므로, 사물의 경계를 정밀하게 구분해야 하는 세밀한 작업(Dense tasks, 예: 세그멘테이션) 에서 성능이 떨어지게 되는 것입니다.
4.2. Gram Anchoring Objective
학습 초기의 우수한 조밀 특성을 보이는 교사의 패치간 유사도(Gram matrix)를 학생의 gram이 따라가게함.
그러니까 학습 초기에는 우수한 조밀 특성을 보임
⇒
그 모델의 패치간 유사도를 학생이 따라감
: 학생의 패치간 유사도 행렬
: 선생의 패치간 유사도 행렬
⇒
- 100만 회 반복 학습 이후에 refinement 시작
- 1만 회 반복 학습마다 Gram 교사를 업데이트하여, 메인 EMA 교사와 동일하게 만듦
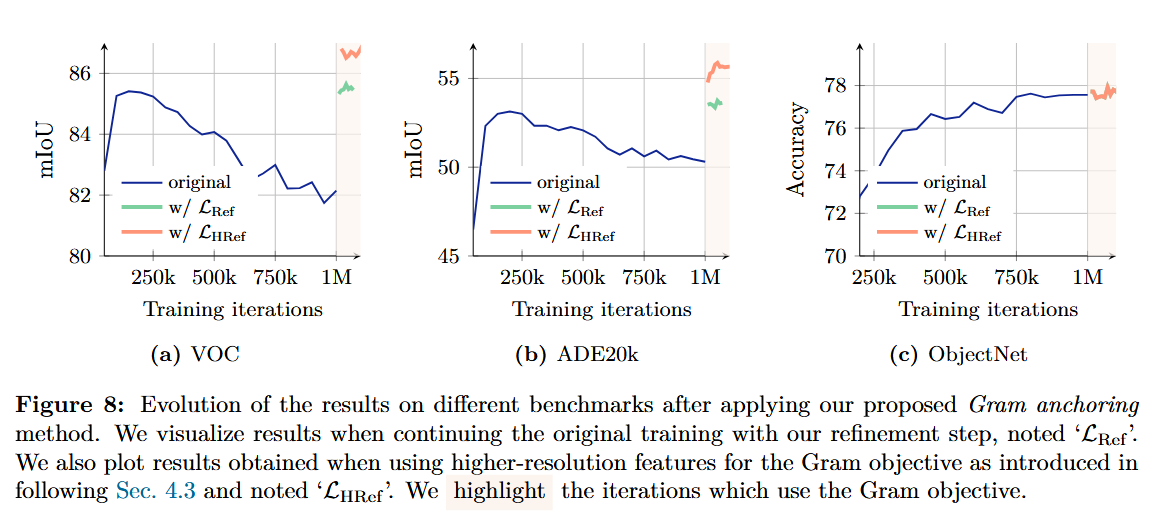
- 첫 번째 훈련 phase (100만 회):
- 두 번째 훈련 phase(refinement) (1만 회 마다 Gram 교사를 메인 EMA 교사와 동일하게 바꿈):
4.3. Leveraging Higher-Resolution Features
Gram 교사를 더 좋게 하기 위해,
Gram 교사에 일반 해상도의 두배인 이미지를 입력
⇒
얻은 특징 지도를 bicubic 보간법으로 2⨉ 다운샘플링하여 학생 모델의 출력 크기와 일치 시킴
⇒
매끄러운 고해상도 특징의 개선된 패치 일관성을 학생 모델로 효과적으로 증류!!!
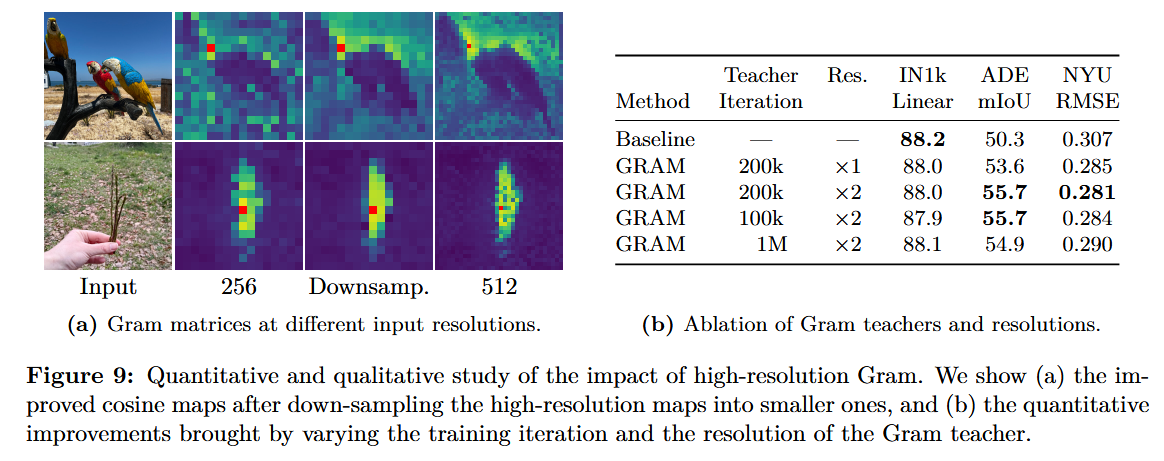

5. Post-Training
5.1. Resolution Scaling
- 메인 훈련: 효율성 위주의 기초 학습
- 설정: 해상도와 패치 크기로 훈련하여 속도와 효율성을 확보합니다.
- 고해상도 적응 단계: 가변 해상도 대응
- 필요성: 현대 비전 응용 분야에서 요구되는 이상의 고해상도 및 가변적인 추론 환경에 대응하기 위해 도입되었습니다.
- 방법: 혼합 해상도(Mixed Resolution) 방식을 사용하며, 전역 크롭()과 지역 크롭()을 섞어 1만 회 추가 학습을 진행합니다.
고해상도 적응 단계는 Gram anchoring에 필수적임.
- 첫 번째 훈련 phase (100만 회):
- 두 번째 훈련 phase(refinement) (1만 회 마다 Gram 교사를 메인 EMA 교사와 동일하게 바꿈):
- High resolution adaptation (1만 회):
- 첫 번째 훈련 단계 (Initial Training Phase)
- 기간: 약 만 회 ()
- 손실 함수:
- 특징: 단일 해상도에서 모델의 기초적인 전역 및 국소 특징을 학습합니다.
- 두 번째 훈련 단계 (Refinement Step)
- 특징: 만 회 이후 시작되며, 망가진 패치 수준 일관성을 '수리'하는 단계입니다.
- 손실 함수:
- 메커니즘: 만 회마다 메인 EMA 교사 의 상태를 Gram 교사 로 복사하여 패치 간 유사도 구조를 고정(Anchoring)합니다.
- 고해상도 적응 단계 (High-resolution Adaptation)
- 기간: 약 만 회 () 추가 학습
- 손실 함수: 가 아니라 (또는 와 유사한 구성)를 사용합니다.
- 논문에서는 고해상도 적응 시 이 필수적이라고 명시하고 있으며, 고해상도 특징을 다운샘플링하여 계산하는 를 사용하여 학습합니다.
- 특징: 등 다양한 크기의 혼합 해상도 를 입력하여 가변 해상도 대응력을 높입니다.
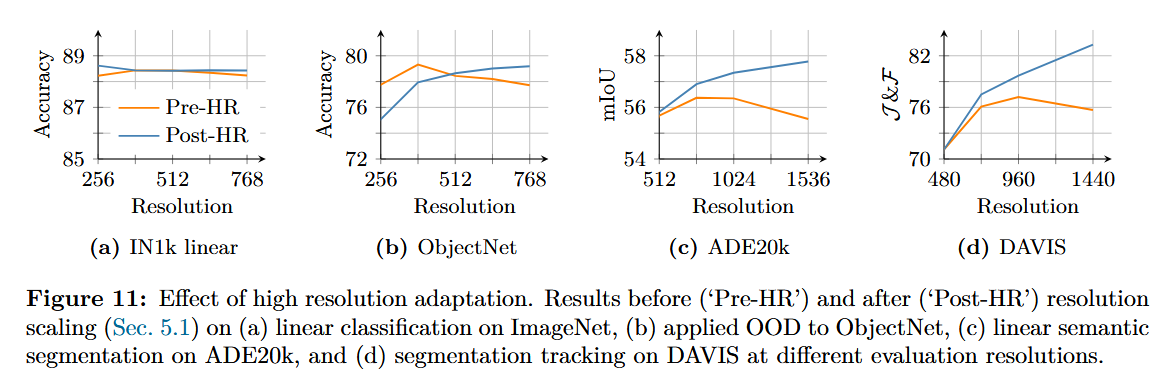
5.2. Model Distillation
A Family of Models for Multiple Use-Cases
ViT-7B를 ViT-S,B,L로 증류함.
증류할 때, 로 100만 번 학습 후, 코사인 스케줄에 따라 25만회 학습률 쿨다운 + high-resolution adaptation
But,
패치 수준 일관성 문제가 없어, Gram anchoring X.
교사를 EMA가 아닌 7B 모델을 직접 사용하여, 고정함.
- 패치 수준 일관성(Patch-level consistency) 문제:
학습이 진행됨에 따라 개별 패치 특징이 고유의 지역적 정보를 잃고 전역 정보( 토큰)와 지나치게 유사해지거나 서로 획일화되어 세밀한 표현력이 떨어지는 현상을 의미합니다.
Efficient Multi-Student Distillation
생략
5.3. Aligning DINOv3 with Text
생략
