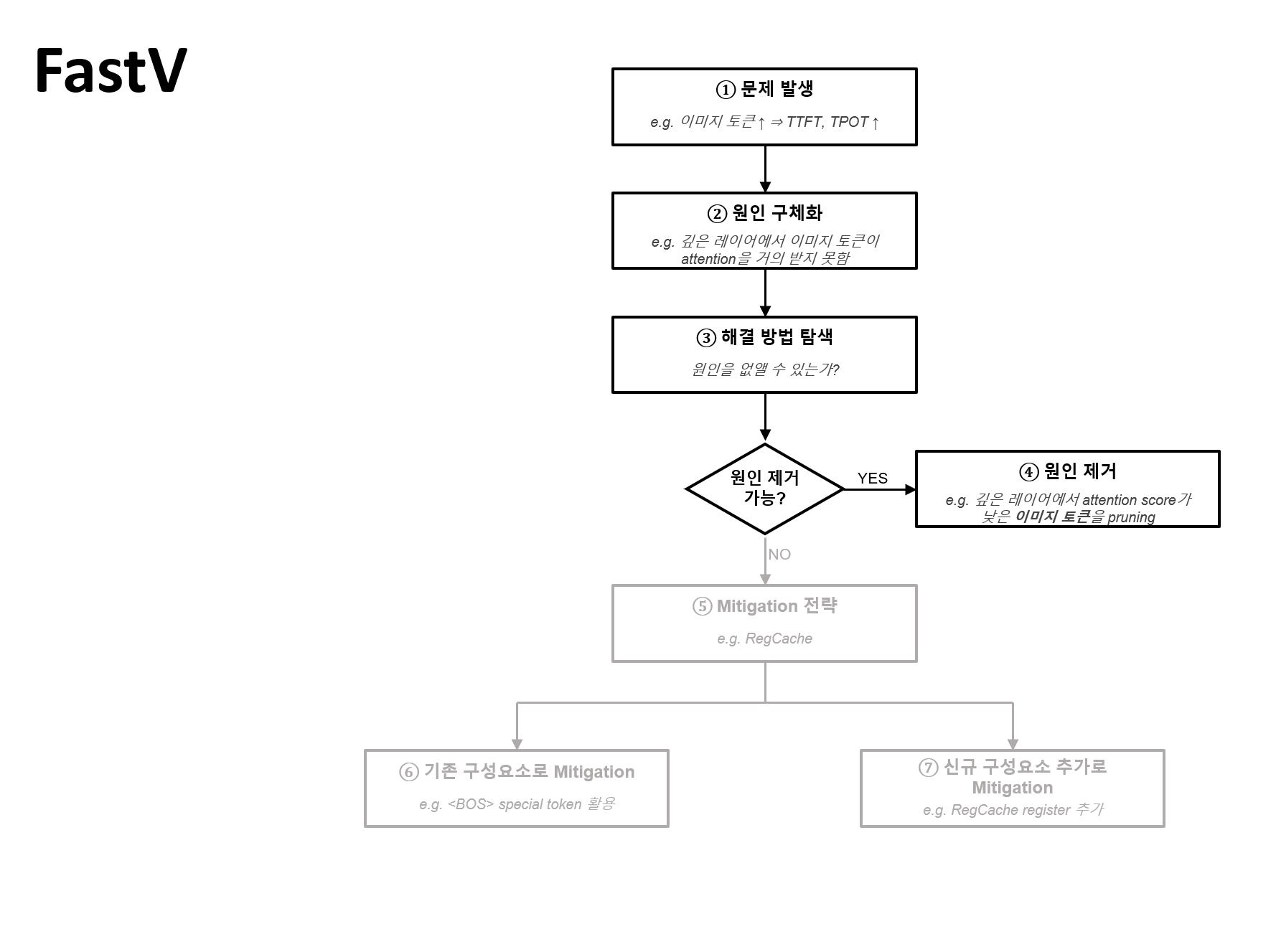
An Image is Worth 1/2 Tokens After Layer 2: Plug-and-PLay Acceleration for VLLM Inference
논문 리뷰

An Image is Worth 1/2 Tokens After Layer 2: Plug-and-PLay Acceleration for VLLM Inference
- 축1 (Modality): Image VLM + Video
- 축2 (압축 메커니즘): Pruning
- 축3 (학습 필요성): Training-free
- 축4 (압축 시점): LLM 내부 layer
- 축5 (Guidance 신호): Attention
- 축6 (적응성): Fixed ratio
- 축8 (타겟 모델): LLaVA / Video LLM / General VLM
의문점 및 발전 가능성
-
Table 7의 (c) 랜덤으로 이미지 토큰 50%를 제거한 것임. 근데 생각보다 acc drop이 없는거 같은데?
⇒ 랜덤으로 이미지 토큰 50%를 제거해도 성능 하락이 매우 작습니다. 이것은 오히려 논문의 핵심 발견을 강하게 뒷받침합니다. 깊은 레이어에서 이미지 토큰이 거의 attention을 받지 못한다는 것은, 어떤 이미지 토큰을 제거하든 출력에 미치는 영향이 작다는 뜻이기 때문입니다. 이미지 토큰 대부분이 이미 깊은 레이어에서 불필요하므로, 랜덤으로 골라도 "중요한 토큰"을 제거할 확률 자체가 낮습니다.
또한 K=2라는 점도 중요합니다. 레이어 2까지는 정상적으로 연산이 진행되어 이미지 정보가 anchor 토큰에 이미 집약된 상태입니다. 그 이후에 제거하는 것이므로, 랜덤이든 attention 기반이든 영향이 제한적입니다.다만 R을 75%나 90%로 올리면 (c)와 (b)의 차이가 더 벌어질 것으로 예상됩니다. 극단적으로 많이 제거할 때는 소수의 중요한 이미지 토큰을 보존하는 것이 중요해지므로, 그때 attention 기반 정렬의 이점이 더 드러납니다.
-
FastV의 속도 이점은 주로 prefill 단계에서 발생하며, 줄어든 토큰이 디코딩 시 계산량 감소에는 기여하지만 시간 감소 효과는 작기 때문에, Table 4 실험에서 디코딩을 한 번만 수행하는 A-OKVQA를 선택하여 prefill 절감을 부각시킨 것은 다소 트리키한 평가 설계이다.
칼
Abstract
LVLM의 심층 레이어에서 visual tokens에 대한 attention 연산이 비효율적
⇒ 초기 레이어에서 adaptive attention pattern을 학습, 후속 레이어에서 visual token을 pruning해서,
computational efficiency를 최적화하는 play-and-play 방식 FastV
FastV 한줄 요약
깊은 레이어에서 이미지 토큰이 거의 attention을 받지 못하므로, 얕은 레이어 이후에 attention score가 낮은 이미지 토큰을 제거해도 성능 손실 없이 계산량을 크게 줄일 수 있다
1. Introduction
아직 충분히 탐구되지 않은 질문
- 언어 모델은 이미지를 어떻게 처리하고 해석하나?
- LVLM에서 훈련, 추론에 대한 최적화 X
문제 발견
LVLM의 깊은 레이어에서 이미지 토큰은 극히 낮은 attention을 받는다. 깊은 레이어에서 이미지 토큰의 평균 attention score는 시스템 프롬프트의 0.21%에 불과하며, 얕은 레이어에서는 50%에 달해 레이어 깊이에 따라 큰 차이가 있다.
가설
얕은 레이어의 self-attention을 통해 이미지 토큰의 정보가 특정 anchor 토큰(시스템 프롬프트 등 텍스트 토큰)으로 집약된다. 이미지의 시각 신호가 높은 중복성을 가지기 때문에 이 압축이 가능하다. 깊은 레이어에서는 모델이 이 anchor 토큰만 참조하므로 이미지 토큰에 대한 attention이 급격히 떨어진다. 결과적으로 이미지 토큰은 출력 생성에 기여 ↓.
해결법(FastV)
특정 레이어 K까지는 정상적으로 연산을 수행하여 정보 집약이 이루어지게 하고, 레이어 K에서 각 이미지 토큰이 받은 평균 attention score를 기준으로 순위를 매긴 뒤, 하위 R%의 이미지 토큰을 이후 레이어에서 제거한다.
2. Related Work
2.1. Large Vision-Language Model
생략
2.2. Inference Optimiation for LLM
Autoregressive 방식의 어려움(attention 연산의 이차 복잡성)의 해결법은 두 가지 범주로 나뉨.
- Attention 모듈의 메모리 소비 최적화
FlashAttention, vLLM, RingAttention - Attention 연산을 프루닝하여, 계산을 단순화
StreamingLLM, FastGen
2.3. Token Reduction for VLMs
이전까지는 ViT 자체에서 토큰을 감소시킴
FastV는 LLM에서 나오는 신호를 활용하여 visual token을 pruning하는 첫 번째 방법
3. Inefficient Visual Attention in VLLMs
3.1. Preliminaries
입력 토큰은 네 종류로 구분된다
- LLM 행동을 제어하는 시스템 프롬프트(sys)
- 비전 인코더에서 나온 이미지 토큰(img)
- 질문을 담은 사용자 지시어(ins)
- 그리고 자기회귀적으로 생성되는 출력 토큰(out)
3.2. Experiment Settings
예시로 이해)
2번째 output 토큰을 생성하는 시점이므로, 이 토큰은 앞에 있는 모든 토큰에 대해 attention을 계산합니다.
앞에 있는 토큰은 sys 3개 + img 4개 + ins 5개 + out 1개(1번째 output) = 총 13개입니다.
hidden dim 10이므로 Q, K 벡터는 각각 10차원이고, Q·K^T로 13개의 score를 구한 뒤 √10으로 나누고 softmax를 취합니다.
softmax 출력이 다음과 같다고 가정합니다:
- sys₁=0.12, sys₂=0.15, sys₃=0.10,
- img₁=0.03, img₂=0.02, img₃=0.01, img₄=0.02
- ins₁=0.08, ins₂=0.09, ins₃=0.07, ins₄=0.06, ins₅=0.10,
- out₁=0.15
α (레이어 j에서 2번째 출력 토큰의 유형별 attention 합)
합계 = 0.37 + 0.08 + 0.40 + 0.15 = 1.0
λ (레이어 j에서 유형별 총 attention 할당량)
현재까지 output 토큰이 2개 생성되었으므로 n=2입니다.
1번째 output 토큰의 α가 다음과 같았다고 가정합니다:
그러면 수식 3에 따라:
ε (레이어 j에서 유형별 attention efficiency)
수식 4에 따라 λ를 각 유형의 토큰 개수로 나눕니다:
3.3. Results
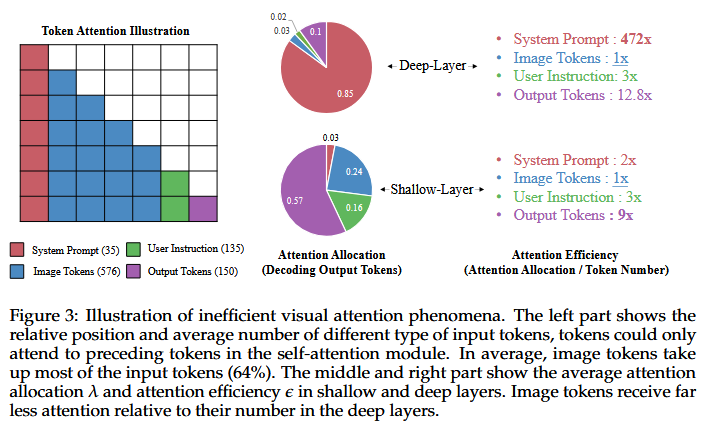
-
어텐션 할당량과 효율성 모두 레이어의 깊이에 따라 서로 다른 정도의 불균형을 보입니다.
레이어별 평균 어텐션 할당 및 효율성은 그림 3에 표시되어 있습니다. 얕은 레이어에서는 어텐션 할당이 깊은 레이어에 비해 상대적으로 더 균형 잡힌 모습을 보입니다. 얕은 레이어에서 출력 토큰은 이전 출력 토큰들에 어텐션을 집중하는 경향이 있는 반면, 깊은 레이어에서는 시스템 프롬프트에 어텐션을 집중하는 경향이 있습니다. -
이미지 토큰은 얕은 레이어와 깊은 레이어 모두에서 가장 낮은 어텐션 효율성을 기록했습니다. 시스템 프롬프트는 깊은 레이어에서 극도로 높은 어텐션 효율성을 보였는데, 이는 이미지 토큰의 472배에 달하며 전체 어텐션 스코어의 를 차지합니다.
3.4. Insights
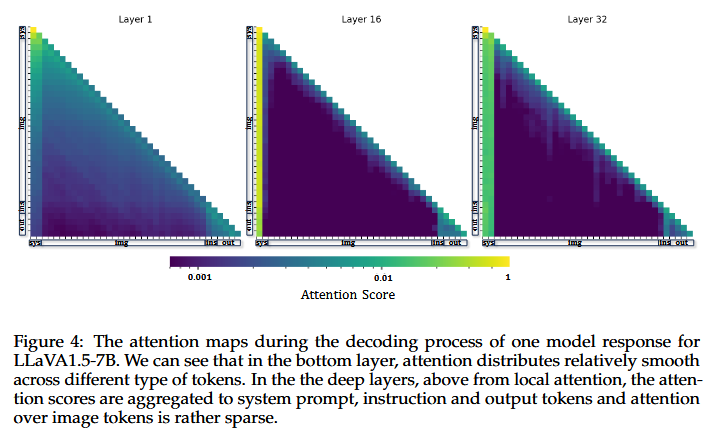
-
이미지 토큰이 입력 토큰의 대다수를 차지함에도 불구하고, 어텐션은 현저히 적다.
-
반대로 의미론적 정보가 최소한으로 포함된 시스템 프롬프트가 어텐션 스코의 대부분을 가져감.
-
얕은 레이어에서는 어텐션 스코어가 서로 다른 토큰들에 걸쳐 비교적 고르게 분포되어 있음을 알 수 있음.
-
깊은 레이어에서는 시스템 프롬프트 영역에 대부분의 어텐션 스코어를 점유함.
⇒ 소수의 anchor 토큰들이 모든 입력 토큰으로부터 정보를 집계하며, 모델은 깊은 레이어에서 이러한 anchor 토큰들에 어텐션을 집중함.
3장 한 줄 요약
특히 깊은 레이어에서 소수의 anchor 토큰(시스템 토큰)들이 모든 입력 토큰으로부터 정보를 흡수함
(시스템 토큰의 attention score가 큼)
4. FastV

4.1. Dynamically Prune Vision Tokens
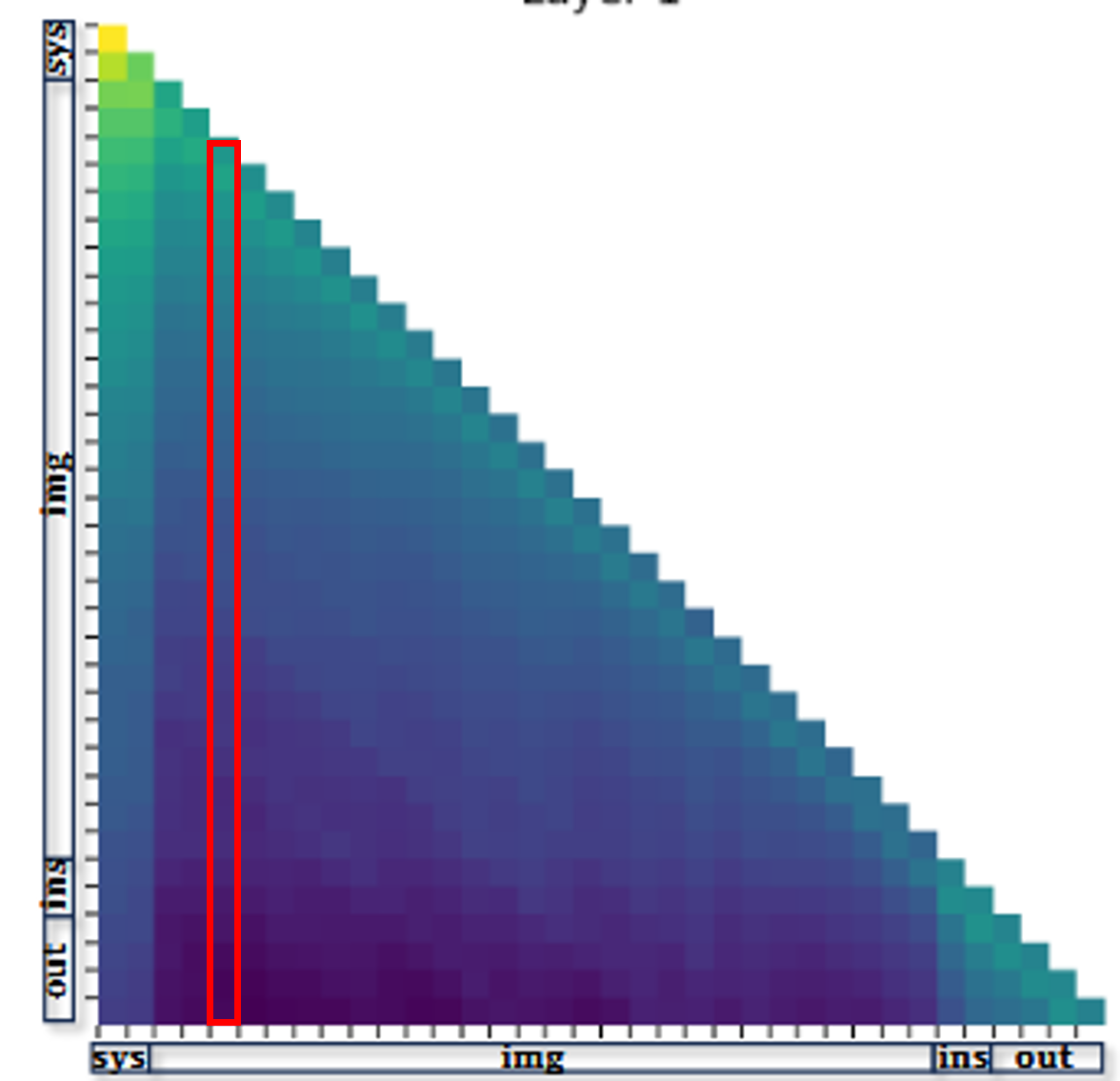
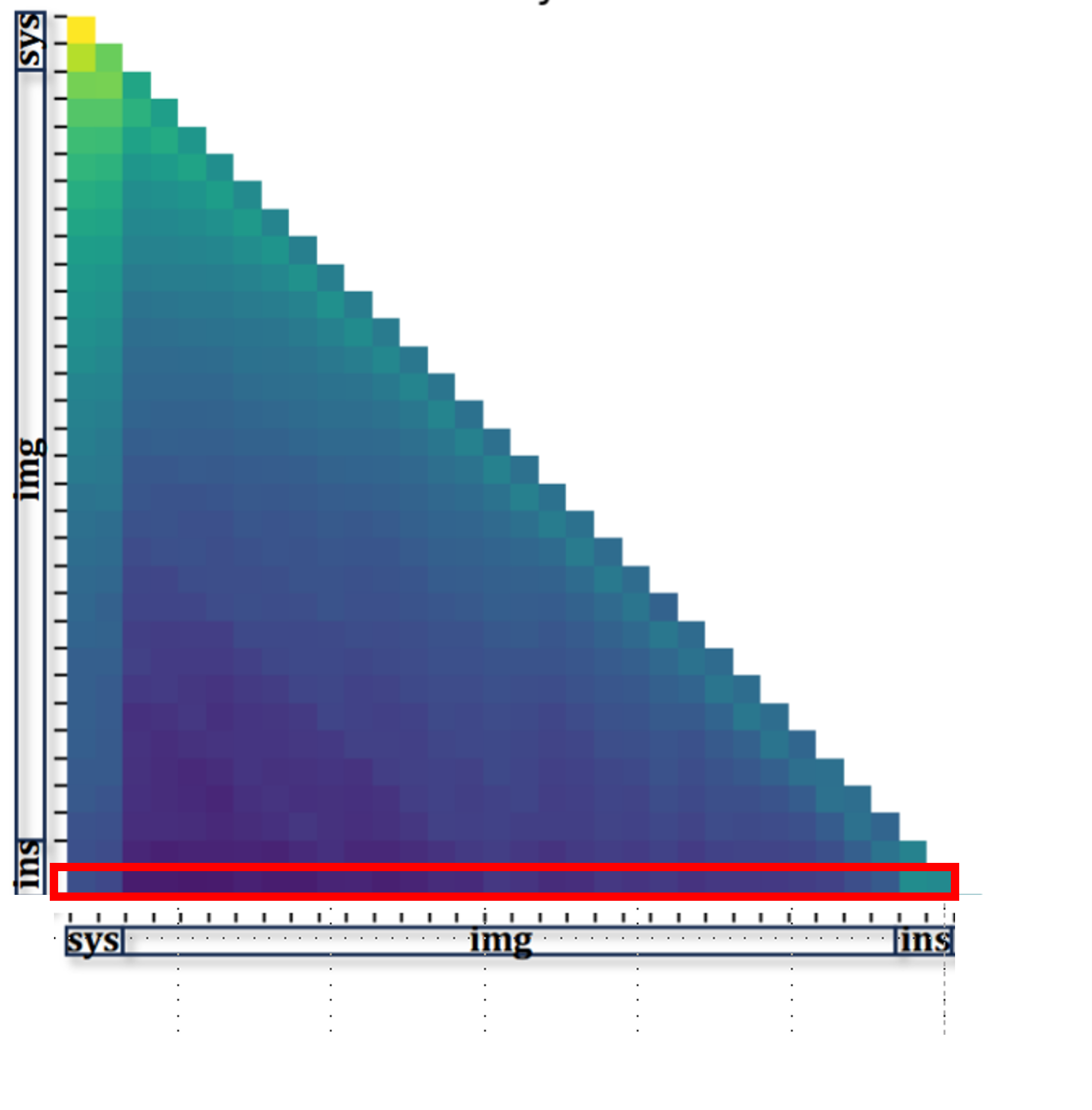
FastV의 핵심 모듈은 레이어 K에서 각 이미지 토큰이 다른 토큰들로부터 받은 평균 attention score(위 그림의 빨간 박스처럼 열 단위 평균)를 기준으로 중요도를 매기고, 하위 R%의 이미지 토큰을 이후 레이어에서 제거하는 것입니다. K=0으로 설정하면 LLM 입력 전에 랜덤으로 제거하는 것도 가능합니다. 별도 학습 없이 어떤 토큰 기반 LVLM에든 바로 적용할 수 있습니다.
(주의) 위 내용은 오류가 있음
논문을 literally 보면, 위 내용이 맞으나, 코드의 구현이 다름
아래 내용이 맞음
use_cache 유무에 따른 FastV pruning 동작 차이
use_cache=True: Prune은 prefill 1번만
-
Prefill: layer K에서 ranking 수행 (빨간 박스는 마지막 텍스트 토큰(ins)이 나머지 토큰에 주는 attention인데, 이중 image 토큰에 주는 attention score로 ranking한다는 뜻) → hidden states 슬라이싱 → layer K부터 줄어든 시퀀스로 forward → 그 결과가 KV cache에 저장됨 (layer ≥K의 K/V는 keep된 토큰들 것만 캐시).
-
Decode step: prefill에서 이미 image 토큰을 잘라냈고 KV cache도 그 세트만 들고 있으니, 남아있는 캐시만으로 토큰 생성. 별도 pruning 로직이 필요 없음.
-
효과: 한 번 정해진 prune 집합이 모든 후속 decode step에 그대로 적용됨. KV cache가 자동으로 줄어든 세트만 들고 있음.
use_cache=False: 매 forward마다 pruning 재계산
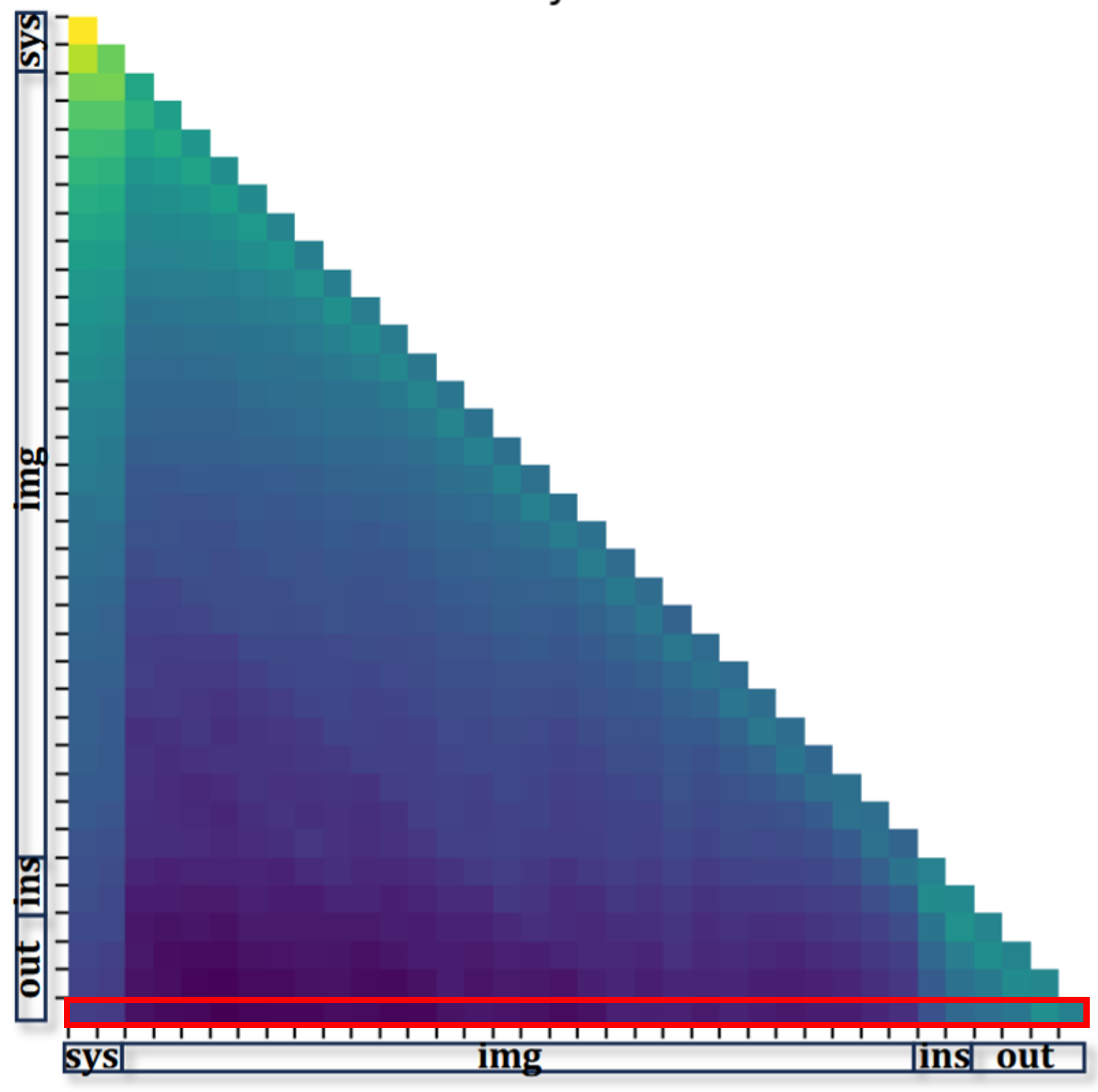
-
매 forward = full re-prefill (캐시 없음).
-
매번 layer K-1의 attention을 다시 보고 → ranking 재계산 → hidden states 다시 슬라이싱.
(e.g. 위 그림에서 현재 생성중인 토큰과 기존 토큰들 + 자기자신 과의 attention score이다. 여기서 image에 해당하는 부분에서 ranking을 하는 것이다.
다음 step에는 ranking의 결과, 즉 순위가 달라져, pruning되야하는 image 토큰 집합이 달라질 수 있다.) -
매 step마다 prune되는 image 토큰 집합이 달라질 수 있음 (그 step의 마지막 query 기준이라).
결과적인 차이 정리

한 줄 요약
-
use_cache=True → "Prefill 시 instruction 끝 토큰의 attention으로 한 번 정하고 끝, 이후 고정"
-
use_cache=False → "매 forward마다 그 시점의 마지막 query 기준으로 재결정 — 매번 흔들리고 비용도 N배"
4.2. Computing Cost Estimation
생략
4.3. Comparison: Training With Less Visual Tokens
FastV(추론 시 토큰 제거)의 대안으로 학습 시 인코더 출력에 pooling을 적용하여 토큰 수를 줄이는 방법이 있으며, 이 둘의 비교는 섹션 5.4에서 다룬다.
5. Experiment
5.1. Evaluation Tasks
생략
5.2. Model Settings
생략
5.3. Main Results
Image Understanding.
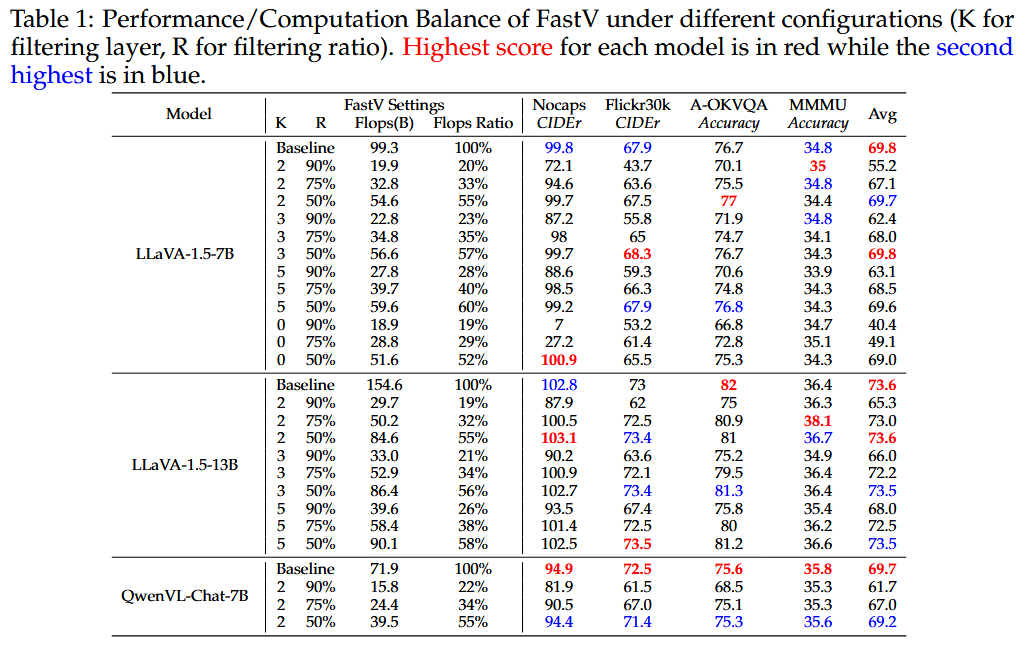
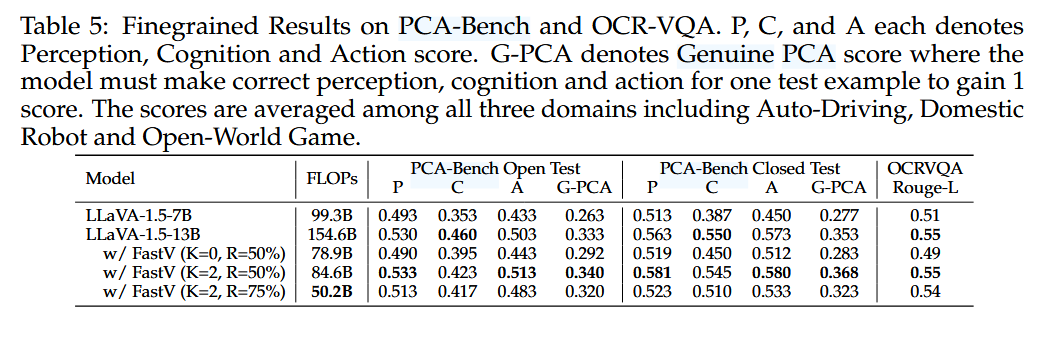
- Table 1, 5:
FastV (K=2, R=50%)는 성능 저하 없이 다양한 LVLM에 대해 약 45%의 FLOPs 절감 달성.
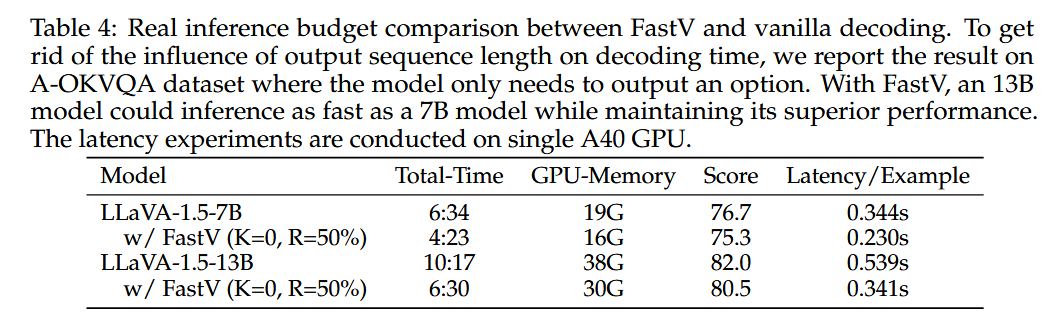
- Table 4:
FastV를 적용한 LLaVA-1.5-13B가 LLaVA-1.5-7B와 비슷한 속도(0.341s vs 0.344s)로 추론하면서도 더 높은 성능(80.5 vs 76.7)을 유지한다.
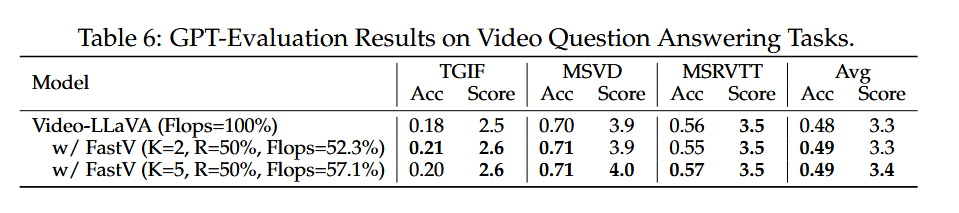
- Table 6: 40% 이상의 연산량 감소에도, 성능이 오히려 향상되었는데, 비디오는 2048개 토큰을 사용하므로 이미지(576개)보다 중복성이 더 심하기 때문이다.
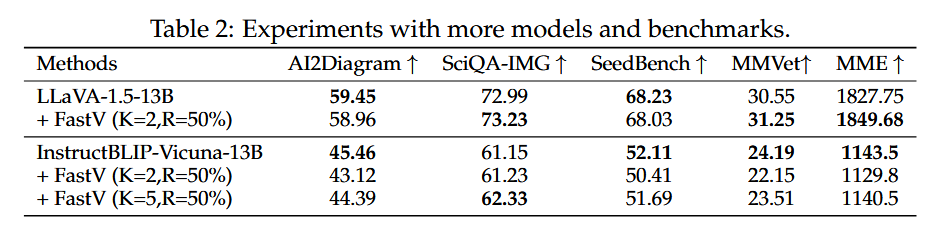
- Table 2:
InstructBLIP-Vicuna는 Q-Former가 이미 토큰을 줄이므로, 동일 설정에서 LLaVA보다 성능 저하가 약간 크지만, K를 5로 올리면 해소된다.

- Table 3:
Fast(K=2, R=50%) 적용 후에도 대부분의 카테고리에서 점수가 유지되거나 소폭 상승했다.
5.4. Ablation Studies
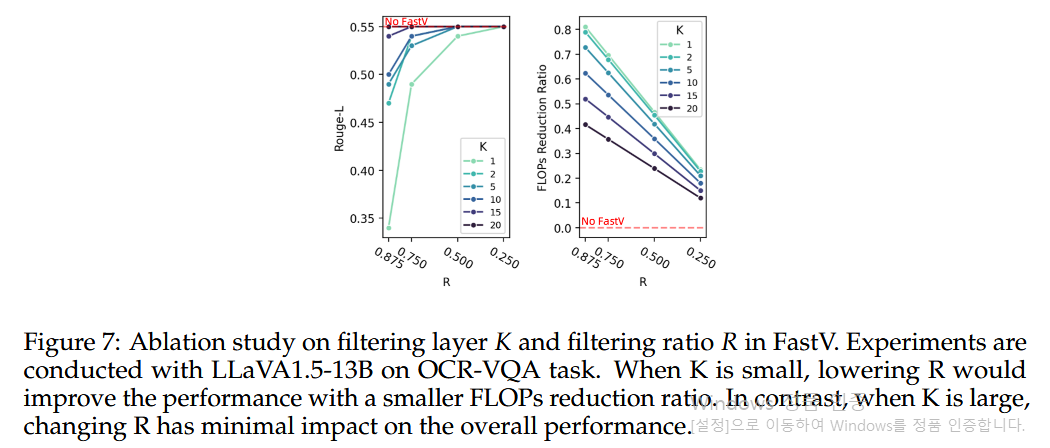
- Figure 7:
- K가 작을 때:
R을 낮추면 성능이 향상됨. - K가 높을 때:
R을 조정해도 성능 변화가 미미함.
- K가 작을 때:
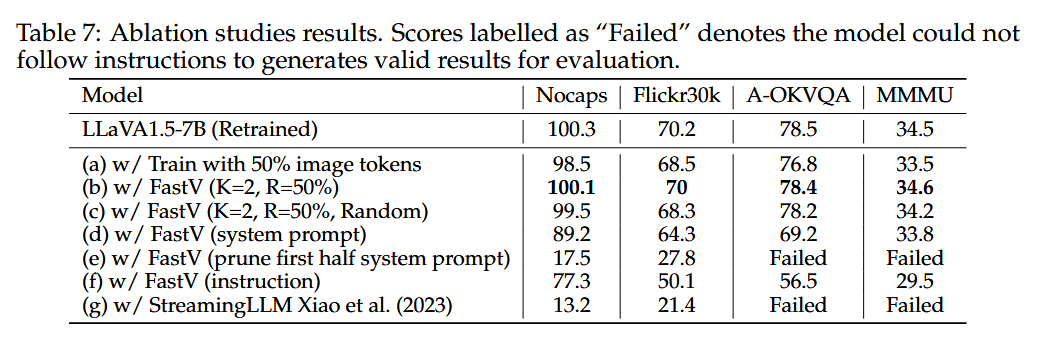
- Table 7:
- (a) 학습 시 pooling으로 토큰 50% 축소:
성능 하락 - (c) 랜덤 프루닝:
성능 하락 - (d) 시스템 프롬프트 프루닝:
큰 성능 하락 - (e) 시스템 프롬프트 전반부 프루닝:
치명적 성능 붕괴 - (f) 지시어 프루닝:
큰 성능 하락 - (g) StreamingLLM:
치명적 성능 붕괴 ⇒ 이미지 토큰이 텍스트 토큰과는 다른 방식으로 LLM 내 정보 처리 과정에 기여.
- (a) 학습 시 pooling으로 토큰 50% 축소:
6. Conclusion
생략

정확한 분석 부탁드립니다... 리뷰 시에 그렇게 오류가 들어가면 듣는 사람도 오해하게 됩니다.. 좋은 리뷰 부탁드립니다. 실수 없는..