Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
논문 리뷰
목록 보기
23/32
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
MoR에 대한 내용
Abstract
- Parameter sharing (Recursive)
- Adaptive computation (EE)
EE ⇒
- non-RT, RT, RRT: 모든 토큰이 동일한 횟수 만큼 재귀 함 ⇒
EERT(MoR): 각 토큰별로 recursive 깊이가 다름 ⇒ - Active 토큰의 KV만 caching
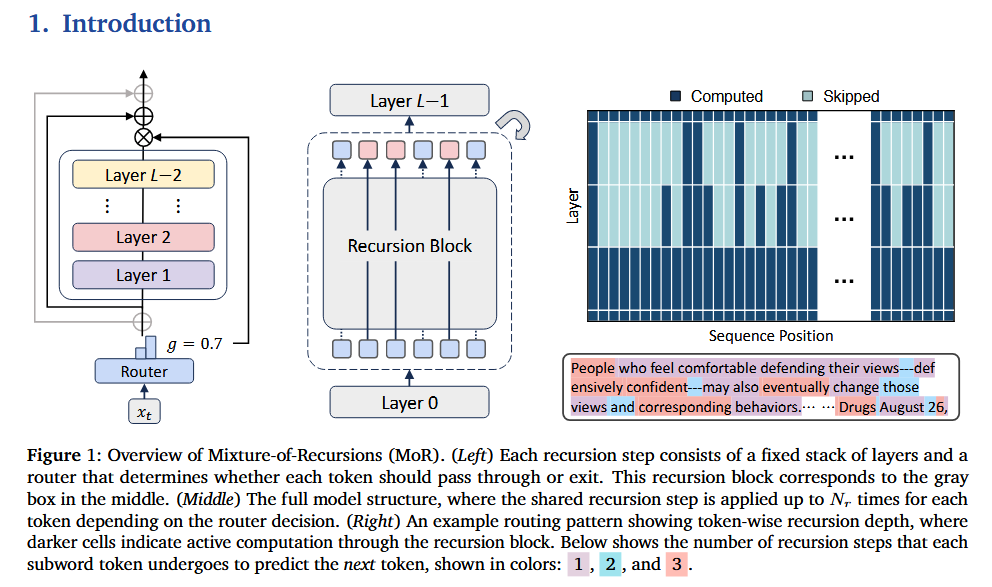
1. Introduction
1) Parameter sharing ⇒ param ↓
2) EE ⇒ FLOPs ↓
3) 재귀별 KV caching ⇒ memory footprint ↓
2. Method
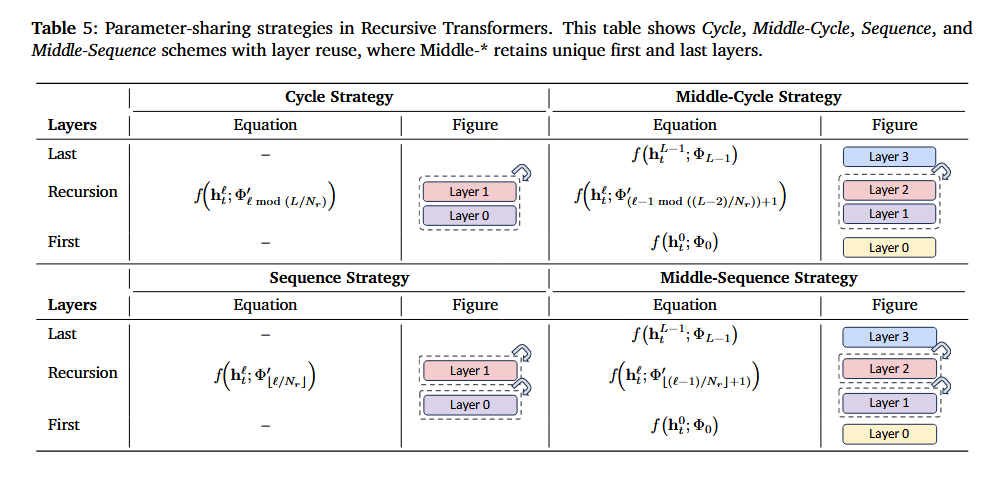
2.1. Preliminary
Parameter-sharing strategies
2.2. MoR
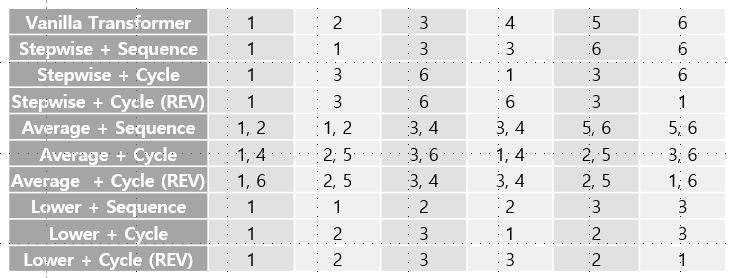
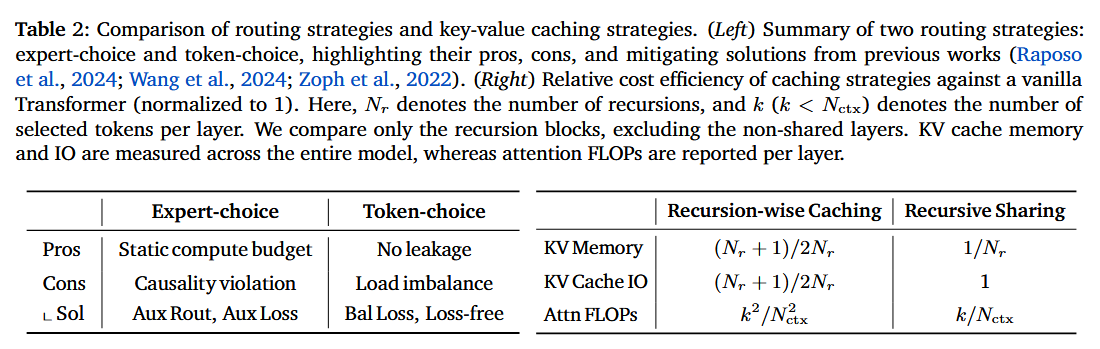
2.2.1. Routing Strategies: Expert-choice vs. Token-choice
Expert-choice routing
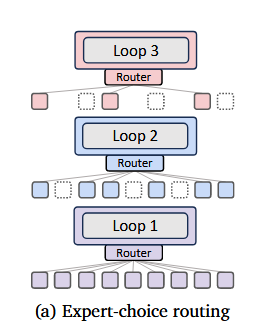
재귀마다 전문가를 다르게 둠.
ex)
일 때, 전문가는 3명.
⇒
에서 Stepwise + Cycle로 예를들면.
임. 즉, 전문가 2명.
1, 3, 6 지난 후에, 전문가 1번이 평가해서,
계산!
: 전문가 1이 평가할 hidden state
: 전문가 1의 채점표(parameter)
전문가 1의 점수가 !
Token-choice routing
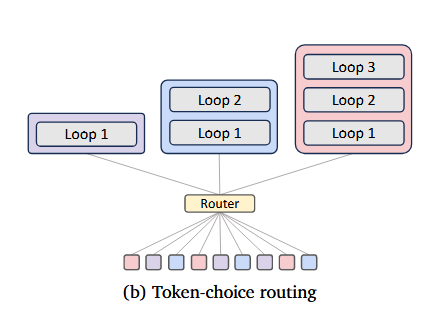
매번 평가하는 것이 아니라, loop에 본격적으로 들어가기 전에 모든 token마다 얼마나 loop를 돌릴지 정하고 가는 형태.
pros & cons
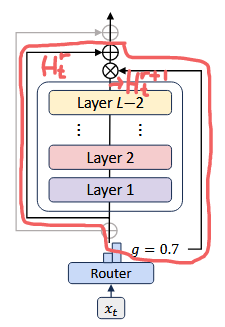
Router가 미래의 정보까지 보고 학습됨
⇒ cheating임
⇒ Auxiliary router or a regularization loss
⇒
미래의 토큰 정보에 접근하지 않고 추론 시 상위 k 토큰을 정확하게 탐지
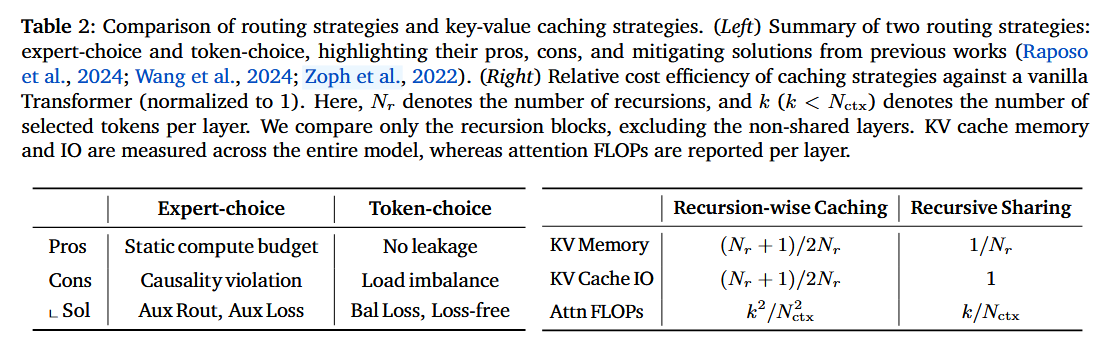
2.2.2. KV Caching Strategies: Recursion-wise Caching vs. Recursive Sharing
예시 상황 요약
입력: 토큰 5개 (),
Hidden Dimension: 10
라우팅 결과: (1회 종료), (2회 종료), (3회 완주)
기법 요약
- Recursion-wise KV caching: 각 재귀 단계에 생존한 토큰의 KV(크기 )만 해당 단계 전용 캐시에 저장함
- Recursive KV sharing: 첫 번째 재귀 단계의 전체 KV(크기 )만 저장하고, 이후 모든 깊은 단계에서 이를 재사용함
예시를 통한 차이점 설명 (Loop 3 시점에서 생성 시)
가 생성되면서 3번째 루프를 돌며 어텐션(Attention)을 수행할 때:
- Recursion-wise:Loop 3 캐시를 참조하는데, 여기엔 생존한 의 정보(크기 )만 저장되어 있음3.탈락한 의 정보는 재계산하지 않고 무시하며, 오직 에만 집중(Attention)함 (문맥 손실 발생)
- Sharing:Loop 1 캐시를 참조하는데, 여기엔 가 모두 저장(크기 )되어 있음 5.탈락한 토큰들도 포함한 전체 문맥을 참조할 수 있음 (단, Query는 Loop 3 수준이나 Key/Value는 Loop 1 수준이라 깊이가 얕음)
pros & cons
3. Experiments