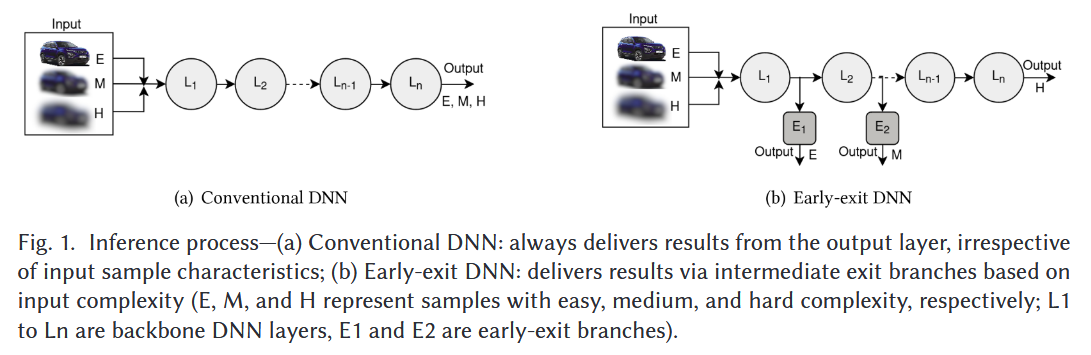
Early-Exit Deep Neural Network - A Comprehensive Survey
EE에 대한 내용
Abstract
EE 장점
- 추론 가속화
- 기울기 소실 문제 완화
- overfitting, overthinking 감소
1 Introduction
생략
2 Motivation and Venefits of Early-exit DNNs
- 추론 가속화
- vanishing gradient problem 해결
- overfitting problem 해결
- 병렬 구현의 어려움 해결
2.1 Speed Up the DNN Inference
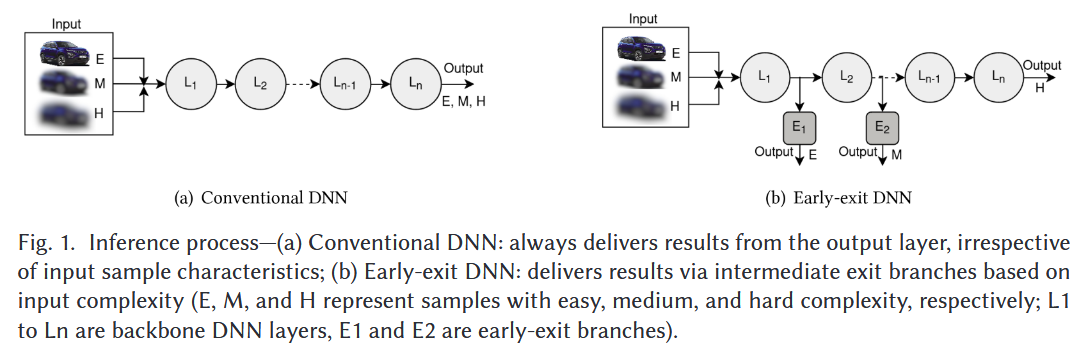
쉬운 입력 ⇒ 초기 layer에서 추출된 특징을 사용 ⇒ 초기 EE
어려운 입력 ⇒ 출력 layer까지 처리 필요
2.2 An Alternate Solution to the Overfitting Challenge of DNNs
- EE의 요소 및 방법:
모든 측면 분기(Side Branches)의 가중 손실(Weighted Losses)을 단일 최적화 문제로 결합하여 공동으로 학습시킵니다. - 해결 과제 및 효과:
각 분기가 상호 정규화 요소(Regularizer)로 작용함으로써 과적합(Overfitting) 문제를 해결하고 모델의 일반화 성능(Genralization) 및 강건성(Robustness)을 향상시킵니다.
2.3 Rectify Overthinking Issue of DNNs
단순 입력 ⇒ EE ⇒ overthinking X
2.4 Mitigate the Vanishing Gradients Problem of DNNs
EEDNN은 네트워크의 심층부까지 가기 전, 중간 종료 지점을 통해 역전파 경로를 단축시키고, 하위 레이어에 즉각적인 판별 목표를 부여함으로써 기울기가 사라지는 것을 방지하고 학습의 효율성을 극대화합니다.
2.5 Provide a Multi-tiered Platform for Training and Deploying DNNs
생략
3. Related Works
생략
4 Early-Exit DNN-Architecture
4.1 Conventional DNN Architecture
생략
4.2 Early-exit DNN Architecture
EE branch: Conv layer, FC layer 또는 이들의 조합
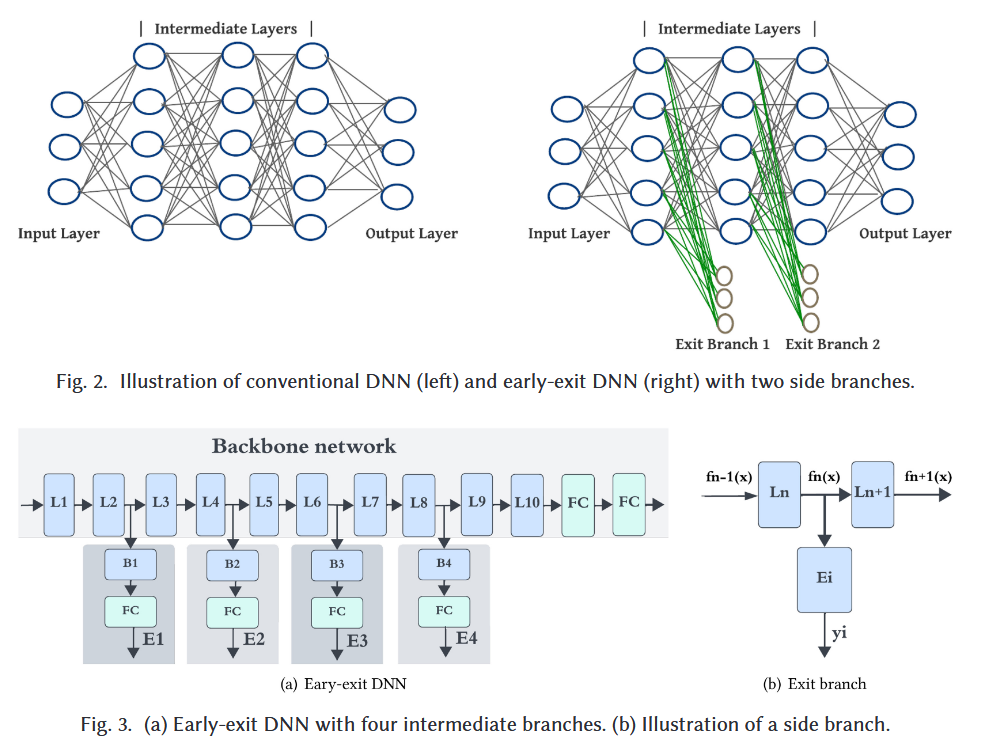
4.3 Design Constraints of Early-exit DNNs
4.3.1 분기 구조
- 분기마다 동일한 구조 (대다수)
- 단일 FC layer (대다수)
- Pooling layer
- Max-pooling layer
- Mixed max-average pooling layer
- 단일 conv layer + fc layer
- 여러 conv layer
- 조합
- 분기마다 다른 구조
- 보통 backbone의 얕은 conv layer는 고차원 특징(이미지 전체에 대한 특징)을 출력하는데, 그래서 더 복잡한 분류기 필요
4.3.2 분기 위치 및 개수
- 균등 분기 배치
- 불균등 분기 배치
4.3.3 조기종료 정책
- 규칙 기반 정적 종료 정책
- 학습 기반 동적 종료 정책
5. 학습
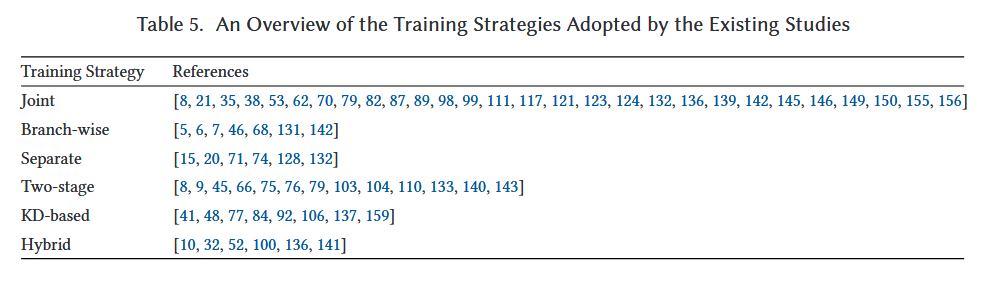
- Joint : Backbone + side branch 포함 전체를 하나로 통합해 학습
- Branch-wise: 각 side branch를 backbone 레이어들과 함께 반복적으로 학습
- Separate: side branch를 독립적인 분류기로 취급하여 각각 별도로 학습
- 2-stage: 먼저 backbone 학습 후 freeze하고, side branch 별도 학습
- KD: side branch가 student, backbone의 최종 출력이 teacher
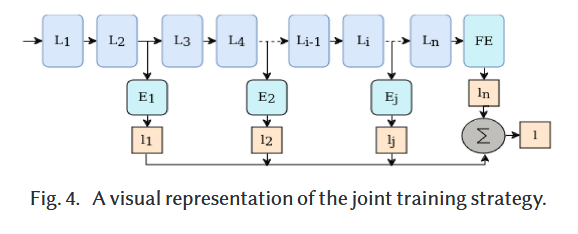
5.1 Joint
5.2 Branch-wise
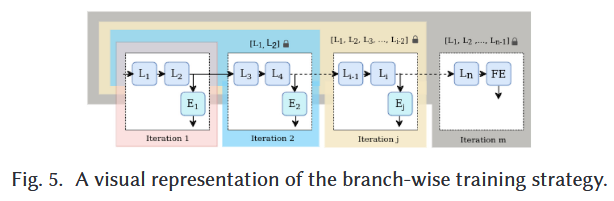
1단계 (초기 학습):
(백본 레이어)와 (첫 번째 측면 분기)을 함께 학습시킵니다.
학습이 완료되면 의 가중치()를 고정(Freeze)합니다. 이제 이 값들은 더 이상 변하지 않습니다.
2단계 (확장 학습):
이제 와 (두 번째 측면 분기)를 학습시킬 차례입니다.이때 는 업데이트하지 않고, 여기서 나온 출력값(Feature map)을 의 입력으로 그대로 사용합니다.
즉, 오차 역전파()가 까지만 일어나고, 와 으로는 전달되지 않습니다.
5.3 Separate
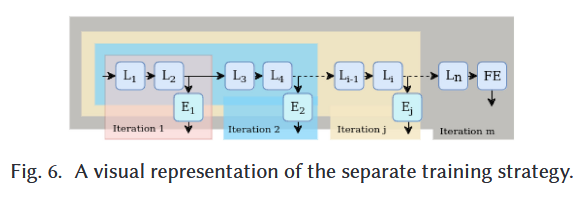
Branch-wise와 달리, freeze 안함
5.4 2-stage
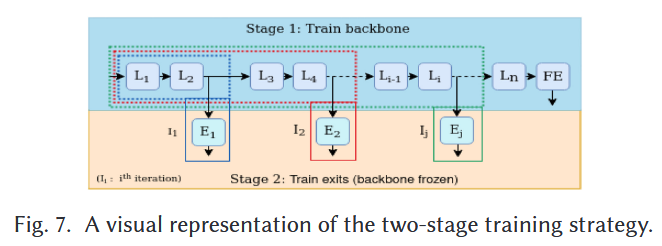
그림 7에 나타난 바와 같이, 백본 레이어(에서 및 )가 먼저 학습됩니다.
그 후 해당 파라미터들은 각 분기를 독립적으로 학습시키는 데 사용됩니다.
예를 들어, 측면 종료 분기 은 고정된 과 의 파라미터를 사용하여 학습됩니다.
마찬가지로, 측면 종료 분기 는 고정된 의 파라미터를 사용하여 학습되며, 이 과정이 모든 분기에 대해 반복됩니다.
backbone이 이미 학습되어 있을 때, ㅈㄴ 유용.
5.5 KD
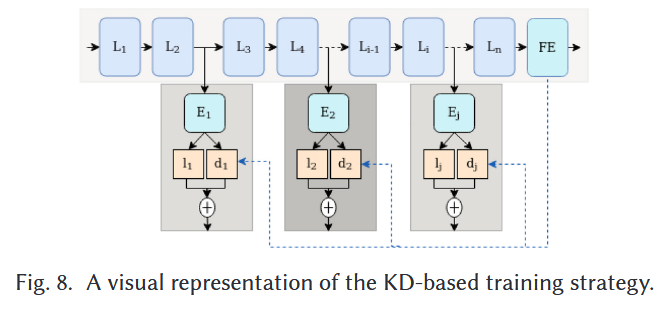
최종 출력 레이어가 높은 acc를 달성했어야, 의미가 있음.
5.6 Hybrid
조합해서 사용.
6 Inference
- 규칙 기반 정적 종료 정책
- 학습 가능 동적 종료 정책

6.1 규칙 기반 정적 종료 정책
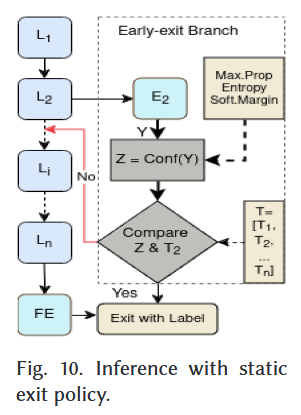
- Entropy
- Maximum softmax probability
- 사용자 정의 점수 함수
를 통해 confidence score 측정
Threshold vector 에서 는 번째 side branch의 threshold를 나타냄.
즉, 특정 시점의 threshold 값 보다 confidence scored와 비교해서, EE!
Entropy
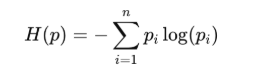
인데, 값의 분포가 skewd 되어 있을수록, 낮은 엔트로피(불확실성)를 갖게됨.
⇒ 이면 EE!

Softmax 기반
각 분기의 fc layer 출력 벡터에 softmax 적용한 것
⇒ 이면 EE!
사용자 정의 점수 함수
6.2 학습 가능 동적 종료 정책

6.3 비교
-
엔트로피 비교 및 소프트맥스 확률 비교와 같은 정적 방법(Static methods)은 미리 정의된 임계값에 의존하기 때문에 학습 복잡도와 추론 지연 시간이 낮습니다. 이는 구현이 간단하고 실행 속도가 빠르다는 장점이 있습니다. 그러나 적응력이 부족하기 때문에 다양한 입력 특성에 대한 강건성은 낮게 나타납니다.
-
반대로 종료 선택 컨트롤러 및 강화 학습 기술과 같은 동적 방법(Dynamic methods)은 정교한 학습 구성 요소로 인해 학습 복잡도가 높습니다. 하지만 최적의 종료 지점을 학습하고 변화하는 입력과 조건에 적응함으로써 강건성 면에서 탁월합니다. 이러한 동적 방법은 계산 집약적이지만, 더 큰 유연성과 맥락에 기반한 의사 결정을 제공하여 다양한 시나리오에서 최적의 성능을 보장합니다.
-
맥락 기반 추론 이력 및 목적 함수 기반 추론 방법은 이력 데이터와 학습된 목적을 활용함으로써 중간 정도의 추론 지연 시간과 높은 강건성 사이의 균형을 맞춥니다.
대부분의 방법은 높은 확장성을 유지하여 다양한 규모에 적응 및 배포가 가능하지만, 동적 접근 방식은 계산 자원 수요가 더 높을 수 있습니다.
