Less is More: Recursive Reasoning with Tiny Networks
TRM에 대한 내용
Abstract
TRM은 HRM보다 훨씬 더 단순한 재귀적 추론 접근 방식으로, 단 2개의 레이어만 가진 하나의 초소형 네트워크를 사용하면서도 HRM보다 훨씬 더 높은 일반화 성능을 달성.
HRM: 27M
TRM: 7M
1. Introduction
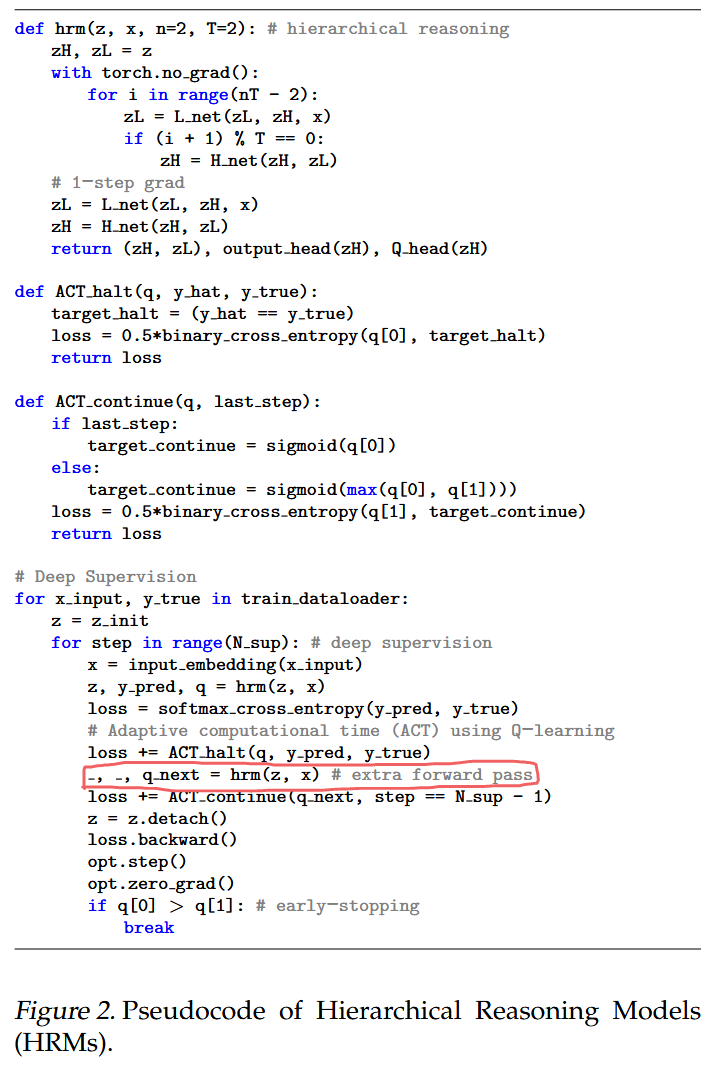
HRM
1) recursive hierarchical reasoning
2) deep supervision
Recursive hierarchical reasoning
(고빈도)와 (저빈도) 두 네트워크가 서로의 잠재 특징()을 입력받아 재귀적으로 작동하며, 이는 뇌의 계층적 처리를 모방
Deep supervision
잠재 특징의 계산 그래프를 분리(detach)하여 다음 단계의 입력으로 재사용하고 단계마다 지도(학습)함으로써, 메모리 폭발 없이 매우 깊은 신경망을 흉내 냄
ARC 벤치마크 분석 결과, HRM 모델의 성능 향상은 모델 내부의 재귀적 순환(H/L 모듈) 때문 X
⇒
모델 전체를 여러 번 반복하며 단계마다 지도(학습)하는 '심층 지도(Deep Supervision)' 방식이 거의 모든 성능을 이끌어낸 핵심 요인
2. Background
2.1. Structure and goal
-
HRM은
입력 임베딩(), 하위() 및 상위() 순환 네트워크, 출력 헤드()라는
4개의 학습 가능한 구성요소를 가짐 -
하위() 및 상위() 순환 네트워크는
RMSNorm, 편향 없음, 회전식 임베딩(RoPE), SwiGLU 활성화 함수를 갖춘
4계층 트랜스포머 아키텍처를 기반으로 함
2.2. Recursion at two different frequencies
# 기울기 없음
# 기울기 없음
# 기울기 없음
# 기울기 없음
# 기울기 있음
# 기울기 있음
2.3. Fixed-point recursion with 1-step gradient approximation
마지막 및 단계만 역전파하여 기울기를 근사하는 데 사용.
6개 중 마지막 두 단계의 기울기만 추적하는 것을 정당화하는 데 사용되며, 이는 메모리 요구량을 크게 줄여줌.
2.4. Deep supervision
유효 깊이(effective depth)를 향상시키기 위해 사용.
⇒ 이전의 잠재 특징( 및 )을 다음 순전파를 위한 초기화로 재사용
2.6. Deep supervision and 1-step gradient approximations replaces BPTT
-
심층 지도 + 1단계 기울기 근사 X:
384계층 전체에 대해 역전파(BPTT)를 한 번에 수행해야 하므로, 메모리 폭발이 일어나고 계산 비용이 엄청나게 비쌈 -
심층 지도 + 1단계 기울기 근사 O:
전체 깊이 대신 L_net과 H_net의 마지막 계산 블록에 대해서만 역전파를 N_sup번 반복하므로, 메모리 문제를 해결하고 계산 비용을 획기적으로 줄일 수 있음.
cf)
2.7. Summary of HRM
생략
3. Target for improvements in Hierarchical Reasoning Models
3.1. Implicit Function Theorem (IFT) with 1-step gradient approximation
HRM은 6번의 재귀(recursions) 중 마지막 2번을 통해서만 역전파를 수행함.
저자들은 '암시적 함수 정리(IFT)'와 '1단계 근사(one-step approximation)'를 활용하여 이를 정당화함.
이 정리는 순환 함수가 고정점(fixed point)에 수렴할 때, 그 평형점(equilibrium point)에서 단일 단계로 역전파가 적용될 수 있음을 의미함.
But,
"고정점(fixed-point)에 도달했다"라고 주장하며 수학적 "꼼수"(1단계 경사도 근사)를 사용하는데,
실제로는 고정점에 도달할 때까지 반복 계산을 하는 것이 아니라,
"단순히 몇 번 순전파"를 실행하고 멈춤
3.2. Twice the forward passes with Adaptive computational time (ACT)
Q-러닝 목표는 정지 손실(halting loss)과 계속 손실(continue loss)에 의존한다.
계속 손실은 HRM을 통한 추가적인 순전파(extra forward pass)를 필요로 함.
⇒
이는 ACT가 샘플당 시간을 더 효율적으로 최적화하는 반면,
최적화 단계(optimization step)당 2번의 순전파가 필요함을 의미
3.3. Hierarchical interpretation based on complex biological arguments
TBW
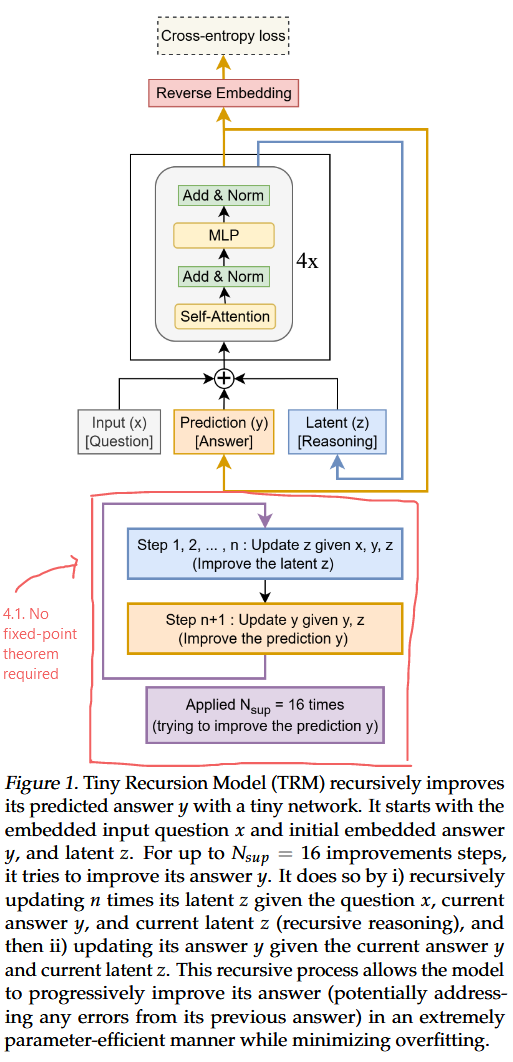
4. Tiny Recursion Models
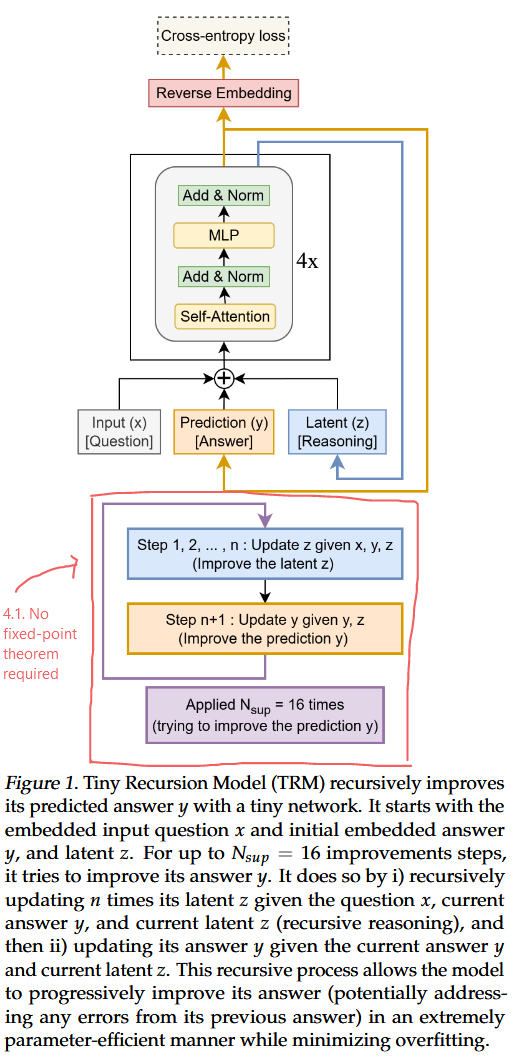
4.1. No fixed-point theorem required
HRM: 1단계 기울기 근사를 활용하기 위해, , 가 고정점에 수렴할 것이라고 가정.
But,
수렴 X
Let, (full recursion process)
일 때,
Full recursion process 번 중 마지막 번째의 과정만 기울기를 계산해서 backward!!!
HRM vs. TRM
-
HRM (1단계 근사 방식):
루프의 각 단계에서, 번의 재귀 중 마지막 1번 재귀의 "마지막 2개 함수()"에 대해서만 경사도를 계산. -
TRM (전체 역전파 방식):
루프의 각 단계에서, 번의 재귀 중 마지막 1번 재귀의 "프로세스 전체(번의 net 호출)"에 대해 경사도를 계산.

4.2. Simpler reinterpretation of zH and zL
-
HRM:
2개의 latent features 사용(H module, L module) -
TRM:
1개의 latent features 사용
그럼 H module의 생성 는?
⇒
즉, 계층 구조는 필요 X
단순히 입력 , 제안된 해답 (이전의 ), 그리고 잠재 추론 특징 (이전의 )가 있을 뿐
입력 질문 , 현재 해답 , 현재 잠재 추론 가 주어지면, 모델은 재귀적으로 잠재 를 개선
⇒
後
현재의 잠재 와 이전 해답 가 주어지면, 모델은 새로운 해답 를 제안
⇒

코드를 보면, n loop(L_cycles)에서 net(z, y+z) 임을 알 수 있음.
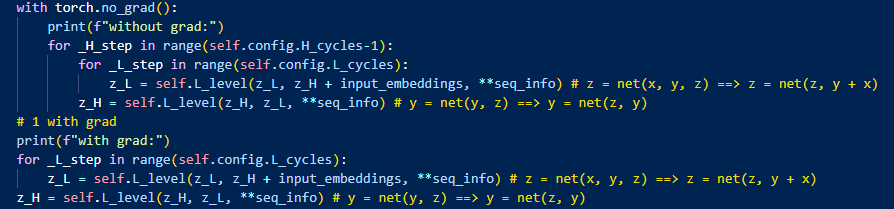
다양한 feature에 대해 실험 해봤는데, 2개 feature가 최적임을 찾음
※ TRM은 1개의 latent feature를 사용한다의 'feature'와 다른 feature임
1개의 laytent feature라는 것은 H module과 L module이 같은 가중치를 쓴다는 거고,
2개의 feature가 최적이라는 것은 z의 개수 1(y 1개, z 1개 ⇒ 2개 latent feature)이 최적이라는 뜻

4.3. Single network
위와 동일한 내용임.
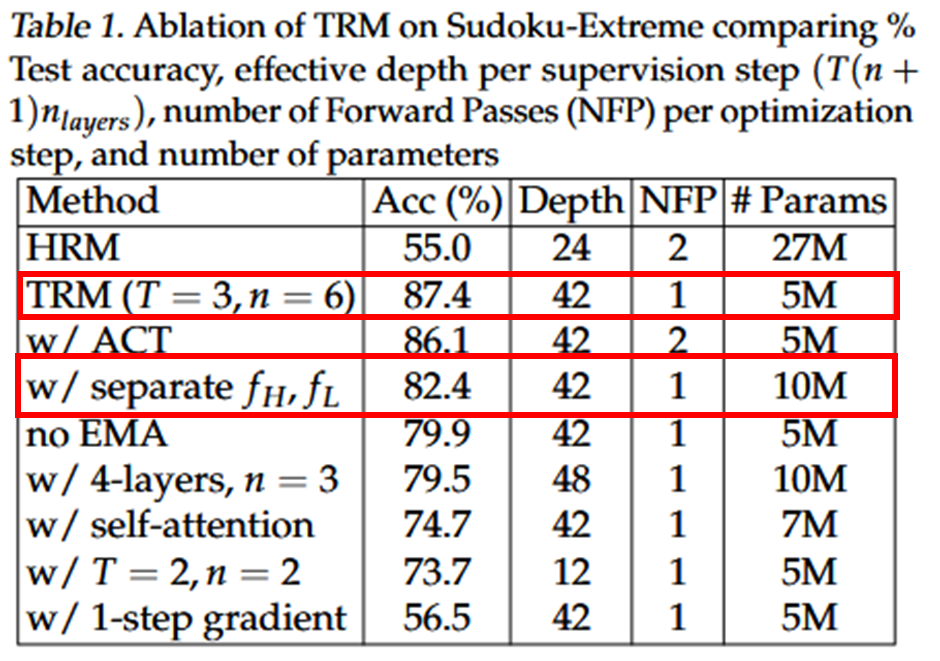
4.4. Less is more
Model 확장을 위해, layer(Transformer block) 수를 늘려 capacity를 늘리려함
⇒ overfitting
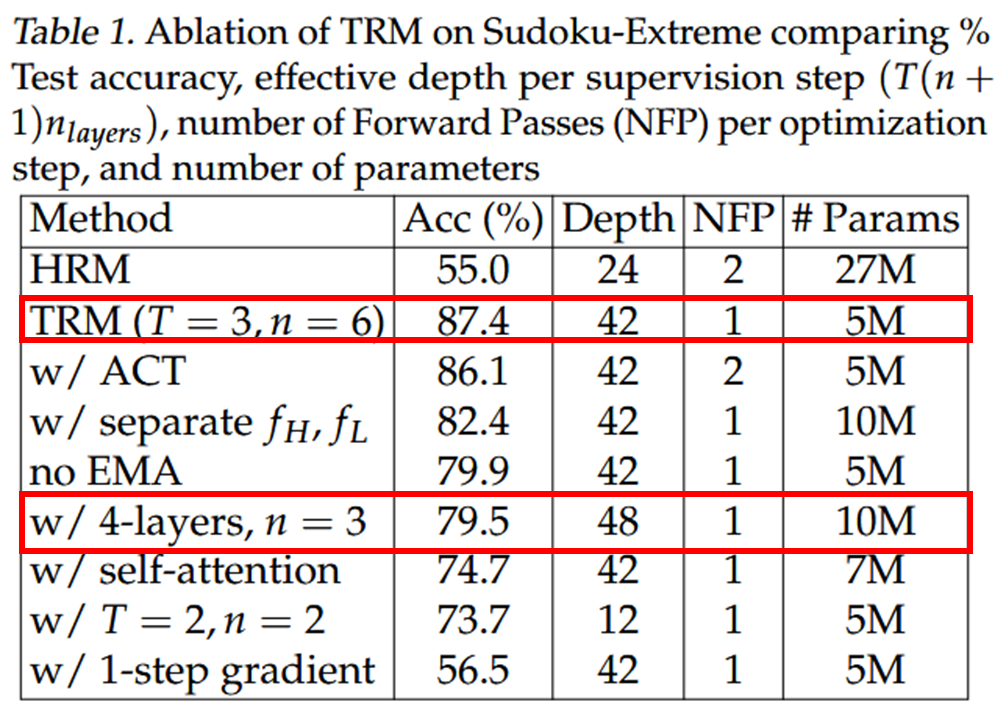
⇒ 재귀 횟수(n)을 비례적으로 늘리면서 block 수를 줄였을 때, 일반화 성능 극대화

⇒
⇒
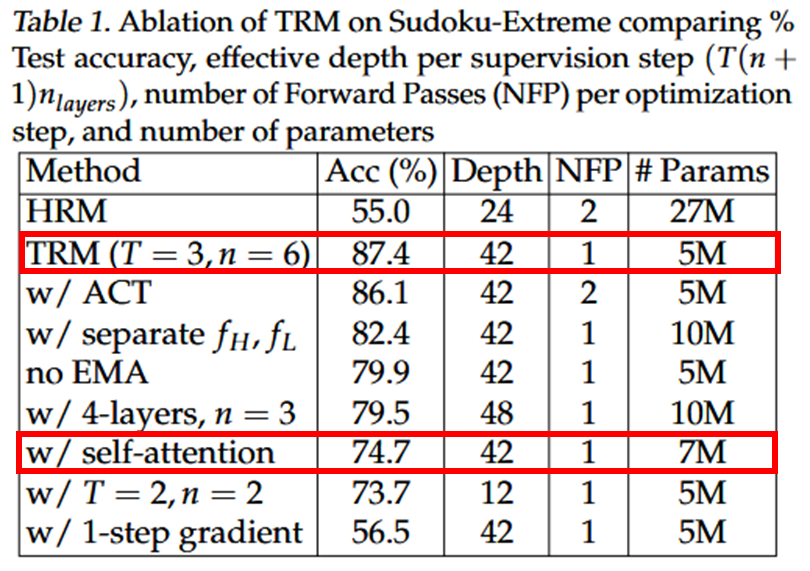
4.5. attention-free architecture for tasks with small fixed context length
Attention의 경우 일 때, 행렬만으로 전체 시퀀스를 설명할 수 있음.
But,
일 때, linear layer는 행렬만 필요로 하므로 더 저렴함. (MLP-Mixer)
⇒ 작고, 고정된 context lenght에서 잘 작동
But,
긴 context suboptimal
4.6. No additional forward pass needed with ACT
HRM의 ACT는 "계속 손실"을 계산하기 위해 비효율적인 2차 순전파가 필요하여 훈련 속도가 느려짐
⇒
TRM은 "계속 손실"을 제거하고 "중단 손실"만 학습함으로써, 비용이 드는 2차 순전파 과정을 없앰

⇒
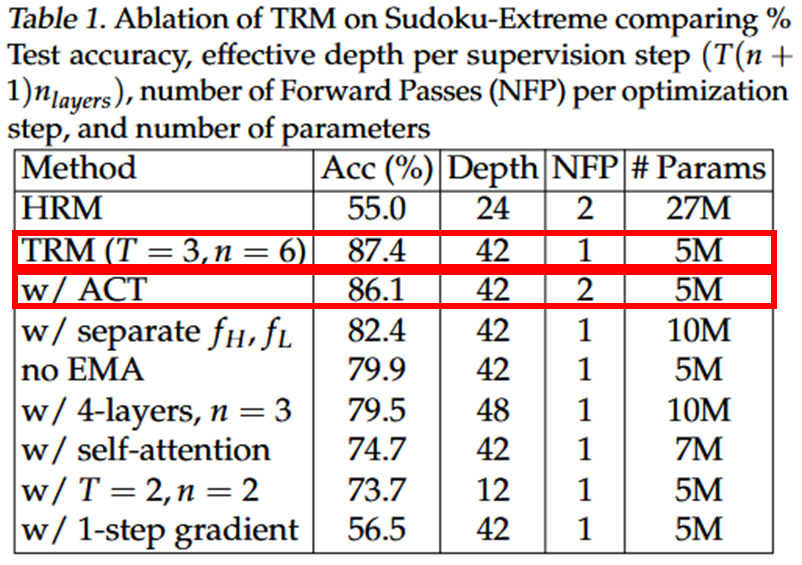
4.7. Exponential Moving Average (EMA)
생략
4.8. Optimal the number of recursion
HRM: 이 최적
TRM: 이 최적
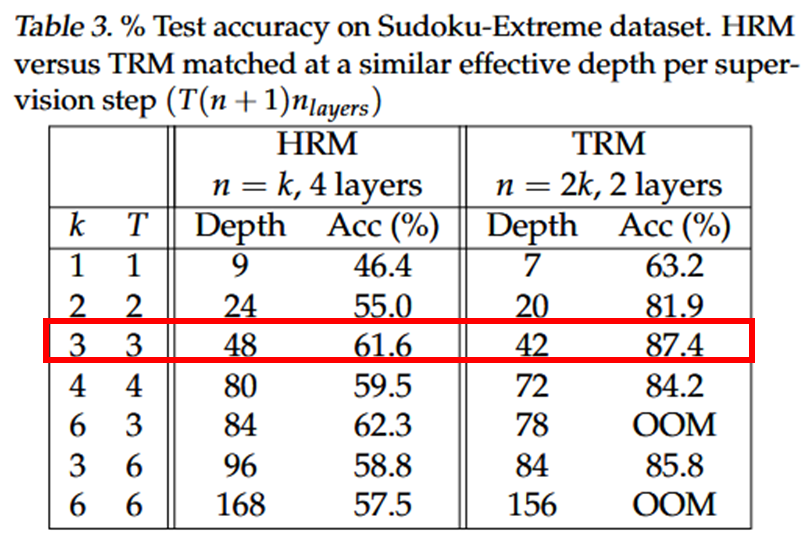
// full recursion process의 gradient를 backward하기에 n이 크면 OOM
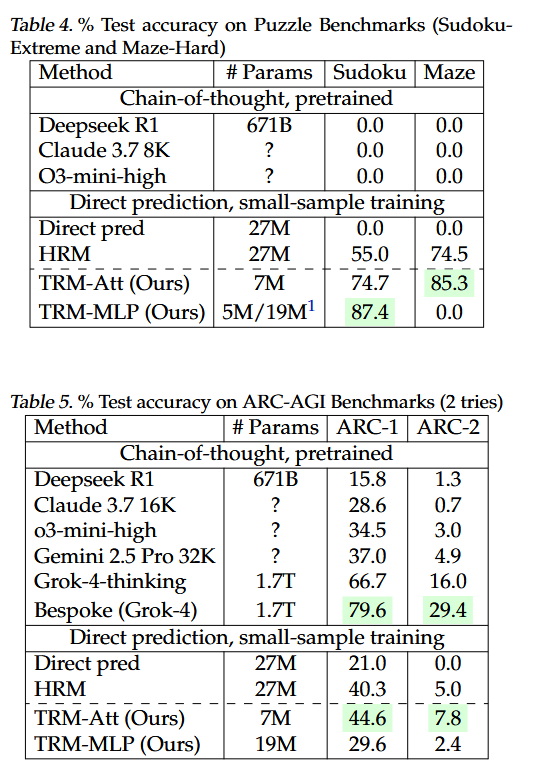
5. Results
Setups
Dataset
-
Sudoku-Extreme
Train: 1K
Test: 423K -
Maze-Hard
Train: 1K
Test: 1K -
ARC-AGI1
-
ARC-AGI-2
Augmentation
Shuffling, dihedral transformations, color permutation, dihedral-group, translations, flips, reflection 등 많이 함
Results