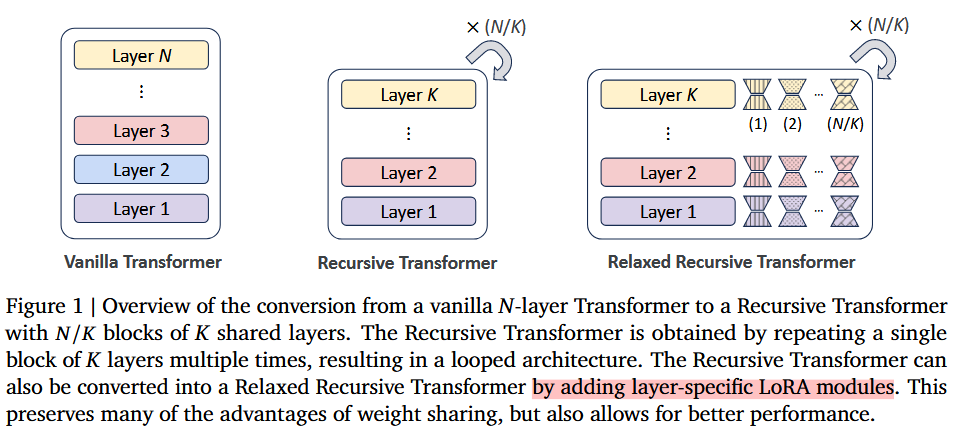
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Relaxed RT에 대한 내용
Abstract
Contribution
- 기존 weight unshared model로 RT를 initialized.
- LoRA를 통한 accuracy 회복.
- Continuous Depth-wise Batching을 통한 inference speedup.
1. Introduction
큰 골조
: 기존 잘 훈련된 non-RT 모델로 shared weight를 잘 초기화
: 약간의 finetune
Relaxed란?
모든 레이어가 동일한 가중치를 공유하는 대신,
각 레이어 LoRA 모듈을 둠
⇒ non-RT와 RT의 중간의 의미로 Relaxed
LoRA
기존 non-RT가 12개 layer이고,
총 4개의 layer로 압축해서 3번 반복하는 RT를 구성하고 싶음
⇒ non-RT의 3개의 layer를 1개로 압축하고 싶은거니
⇒ 3개의 LoRA module을 둠
이때, LoRA 행렬의 rank가 relaxnity가 됨.
LoRA 행렬의 초기화
non-RT의 3개 layer를 1개의 layer로 압축했으니
총 4개의 가중치가 나옴
non-RT에서 3개, RT에서 1개
⇒
로 truncated SVD 적용해서, LoRA 행렬 1을 초기화
로 truncated SVD 적용해서, LoRA 행렬 2을 초기화
로 truncated SVD 적용해서, LoRA 행렬 3을 초기화
Continuous Depth-wise Batching
Continuous Sequence-wise Batching
이 기법은 토큰의 위치(Position) 에 상관없이 모델 파라미터가 동일하다는 점을 이용합니다.
- 예시 상황
- Batch Size: (동시에 2개의 문장 생성 가능)
- 요청 A: "안녕" (3개 토큰 생성 후 종료 예상)
- 요청 B: "오늘 날씨에 대해 길게 설명해줘" (100개 토큰 생성 예상)
- 작동 원리
- Step 1~3: 요청 A와 B가 동시에 토큰을 하나씩 생성합니다.
- Step 4: 요청 A가 작별 토큰(<EOS>)을 내뱉고 생성을 마칩니다.
- 핵심: 기존 방식은 요청 B가 100개를 다 만들 때까지 기다려야 하지만, 이 기법은 요청 A가 비운 슬롯에 즉시 새로운 요청 C 를 투입합니다.
- 이유: 모델의 가중치는 문장의 시작 부분() 을 계산할 때나 중간 부분() 을 계산할 때나 똑같기 때문입니다.
Continuous Depth-wise Batching
이 기법은 Recursive Transformer (RT ) 에서만 가능하며, 가중치가 레이어의 깊이(Depth) 에 상관없이 동일하다는 점을 이용합니다.
이는 조기 종료(Early Exiting) 기법과 결합될 때 극대화됩니다.
- 예시 상황
- 모델 구조: 1개의 가중치 블록을 최대 10번 반복(loop) 하는 RT
- 요청 A (쉬운 질문): "1+1은?" (연산량이 적어 4번의 반복만으로 정답 도출 가능)
- 요청 B (어려운 질문): "양자역학을 설명해줘" (연산량이 많아 10번의 반복이 모두 필요)
- 작동 원리
- Loop 1~4: 요청 A와 B가 동일한 가중치 블록에서 동시에 1~4회차 반복 연산을 수행합니다.
- Loop 5: 요청 A는 이미 답을 찾았으므로 4회차에서 Early Exit 하여 계산을 마칩니다.
- 핵심: 이때 요청 B는 여전히 5회차 연산이 필요합니다. RT 는 가중치가 모든 루프에서 동일하므로, 요청 A가 빠진 자리에 새로운 요청 C의 1회차 연산 을 요청 B의 5회차 연산과 동시에 배치(jointly computing) 로 묶어서 처리할 수 있습니다.
- 결과: 하드웨어는 요청 B의 남은 계산을 처리하는 동시에 새 요청의 시작 계산을 병렬로 수행하게 되어 쉬는 구간이 없어집니다.
사용자님의 질문은 매우 날카로운 지적입니다. "어차피 하나의 토큰을 완성하려면 여러 번( 번) 돌려야 하는 것은 똑같지 않나?"라는 의문이 생길 수 있습니다. 하지만 RT (Recursive Transformer)와 non-RT 의 결정적인 차이는 '조기 종료(Early Exiting)' 시 하드웨어 가용성을 어떻게 활용하느냐에 있습니다.
설정하신 규칙에 따라 강조 표시 와 수식 주변에 공백을 적용하여 설명해 드립니다.
1. 가중치의 특수성 vs. 범용성
가장 큰 차이는 물리적인 가중치() 가 메모리에 로드되었을 때, 어떤 작업을 처리할 수 있는지에 대한 범용성 입니다.
- Non-RT (Weight Specialization): 각 레이어가 서로 다른 가중치() 를 가집니다. 번 레이어 연산을 위해 을 메모리에 올렸다면, 그 시점에는 오직 '3층 연산' 만 할 수 있습니다.
- RT (Weight Universality): 모든 루프가 동일한 가중치() 를 공유합니다. 이 가중치가 메모리에 올라와 있다면, 그것이 누군가에게는 '1회차 루프' 일 수도 있고, 다른 누군가에게는 '10회차 루프' 일 수도 있습니다.
2. Early Exiting 상황에서의 처리량(Throughput) 비교
배치(Batch) 내에 쉬운 질문(A)과 어려운 질문(B)이 섞여 있다고 가정해 봅시다.
Non-RT의 경우 (Sequence-wise Batching)
- Step 1: [A의 1층, B의 1층] 연산
- Step 2: [A의 2층, B의 2층] 연산 (A가 여기서 정답을 찾아 조기 종료함)
- Step 3: [None, B의 3층] 연산
- 문제: 하드웨어는 을 로드했지만, 새로 들어온 요청 C는 이 필요하므로 지금 당장 처리할 수 없습니다. A의 빈자리는 요청 B가 문장을 완전히 끝낼 때까지 비어 있게 됩니다.
RT의 경우 (Continuous Depth-wise Batching)
- Step 1: [A의 1회차, B의 1회차] 연산
- Step 2: [A의 2회차, B의 2회차] 연산 (A가 여기서 조기 종료함)
- Step 3: [C의 1회차, B의 3회차] 연산
- 해결: RT 는 모든 루프가 같은 가중치를 쓰므로, A가 빠진 자리에 즉시 새로운 요청 C의 시작 부분 을 끼워 넣을 수 있습니다. 하드웨어 입장에서는 똑같은 를 쓰기 때문입니다.
3. 결론: 왜 RT가 더 빠른가?
사용자님의 말씀대로 토큰 하나당 필요한 총 연산량은 비슷할 수 있습니다. 하지만 RT 는 가중치의 공유 특성 덕분에 '깊이(Depth)' 라는 차원에서 동적인 그룹화() 가 가능해집니다.
- Non-RT: 문장이 완전히 끝나야 빈자리를 채울 수 있음.
- RT: 어떤 요청이 특정 깊이에서 일찍 끝나면, 그 즉시 다음 요청의 첫 번째 루프를 시작 하여 빈자리를 채울 수 있음.
이러한 유연성 덕분에 하드웨어 유휴 시간이 줄어들고, 이론적으로 의 추론 처리량 향상을 달성할 수 있는 것입니다.
2. Effective Model Compression with Recursive Patterns
2.1. 트랜스포머
이전 레이어 의 출력, 를 입력으로 받아,
현재 레이어 를 지나, 를 출력함.
이때, 는 타임스텝인데, 그냥 번째 토큰으로 이해해도 됨.
결국 가 증가하려면, (즉, 다음 토큰으로 넘어가려면)
모든 레이어를 지나, 를 출력해서,
그걸 다시 에 넣는것 임.
2.2. 기존 non-RT로 RT를 initialized
Looping 전략
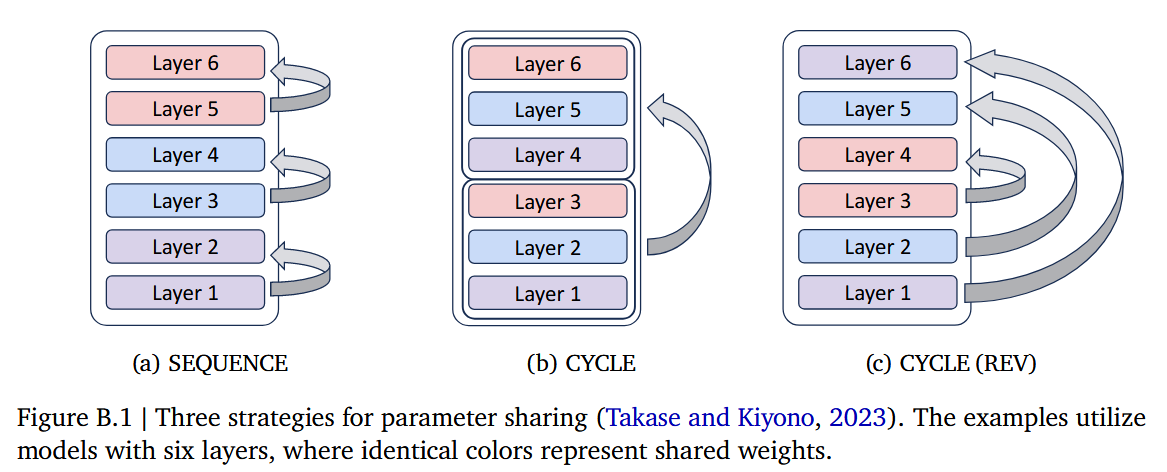
Gemma 2B: 18 layers
를 CYCLE 전략으로 2배 압축
⇒
⇒ 는 loop 횟수
: 사용
: 사용
: 사용
...
: 사용
: 사용
: 사용 (다시 처음으로)
⇒ 즉, loop 도는 주기에 관한 얘기!
초기화 전략
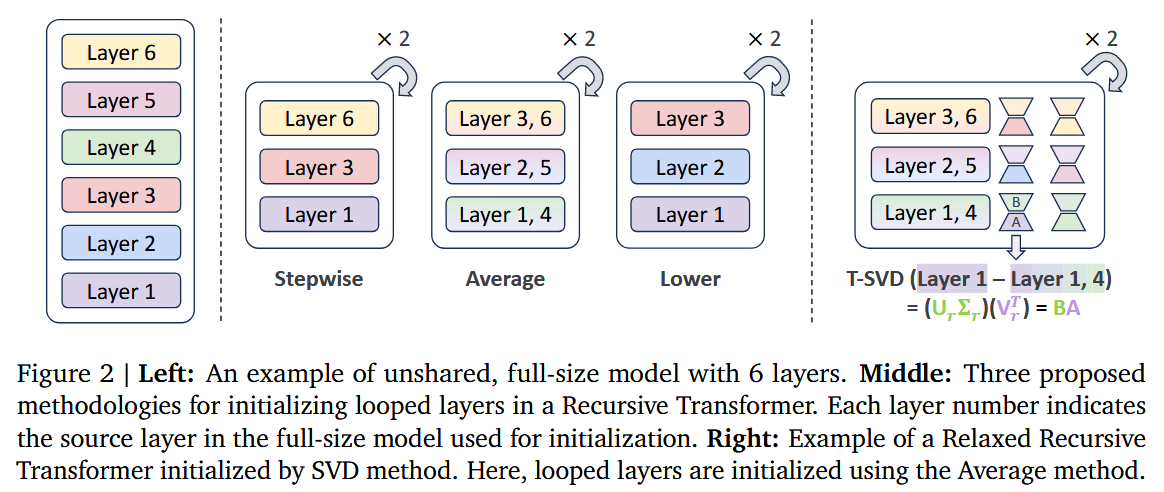
-
Stepwise , Average , Lower 초기화 방식 중 Recursive Transformers 에는 레이어를 특정 간격으로 추출하는 Stepwise 방식이 가장 적합했습니다.
-
반면 Relaxed Recursive Transformers 의 경우에는 가중치 행렬들을 평균 내어 초기화하는 Average 방식이 가장 높은 성능 회복력을 보였습니다.
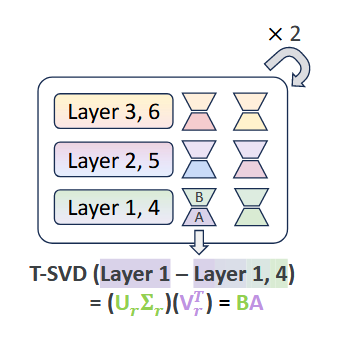
2.3. relaxed via LoRA
: LoRA module 파라미터
non-RT의 2개 레이어를 RT에서 1개로 공유해서 쓸 때,
RRT는 해당 1개의 shared layer에서 2개의 LoRA 모듈이 필요.
그 2개 모듈은 각각의 loop에서 쓰임.
즉,
첫 번째 loop에서, 1번 LoRA 모듈,
두 번째 loop에서, 2번 LoRA 모듈.
첫 번째 루프 (Loop 1): 공유 가중치() 에 첫 번째 LoRA 모듈을 더해 연산합니다.
()
두 번째 루프 (Loop 2): 동일한 공유 가중치() 에 두 번째 LoRA 모듈을 더해 연산합니다.
()
LoRA rank
r ↑ ⇒ non-RT 스러움
r ↓ ⇒ RT 스러움
2.4. Continuous Depth-wise Batching으로 infernece speedup
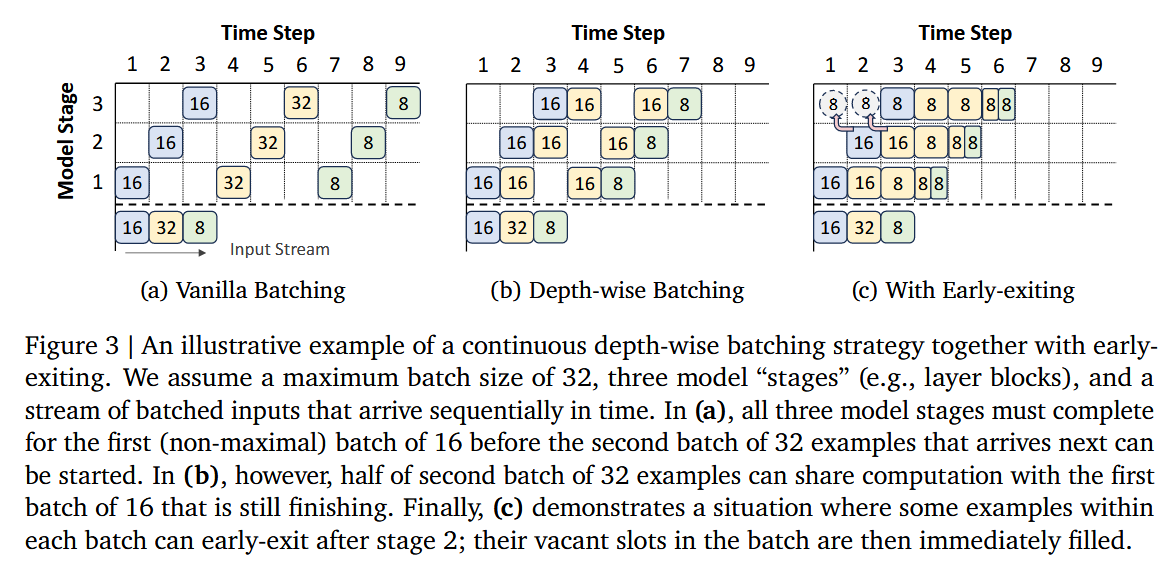
Depth-wise batching은 RT의 특정으로 인해, 더 세밀히 batch control이 가능.
3. Experiments
3.1. Experimental Setup
model
- Gemma 2B
- TinyLlama 1.1B
- Pythia 1B
를2배 압축.
後 SlimPajama로 uptraining.
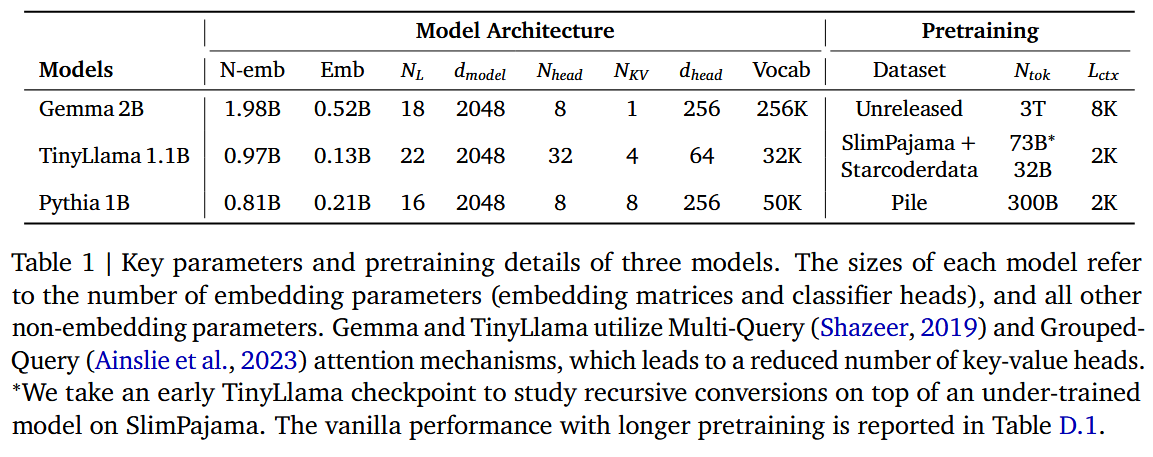
3.2. Non-Recursive Model Baselines
Full-size model
Pretrain dataset과 Uptraining dataset이 다르거나,
Pretrain dataset 품질 > Uptraining dataset 품질
⇒ 성능 저하
⇒ Gemma, Pythia는 dataset 품질이 SlimPajama(Uptraining dataset) 품질보다 좋음
⇒
non-RT를 SlimPajama로 같은 토큰 만큼 uptraining
vs.
RRT를 SlimPajama로 같은 토큰 만큼 uptraining
으로 비교함.
3.3. 결과
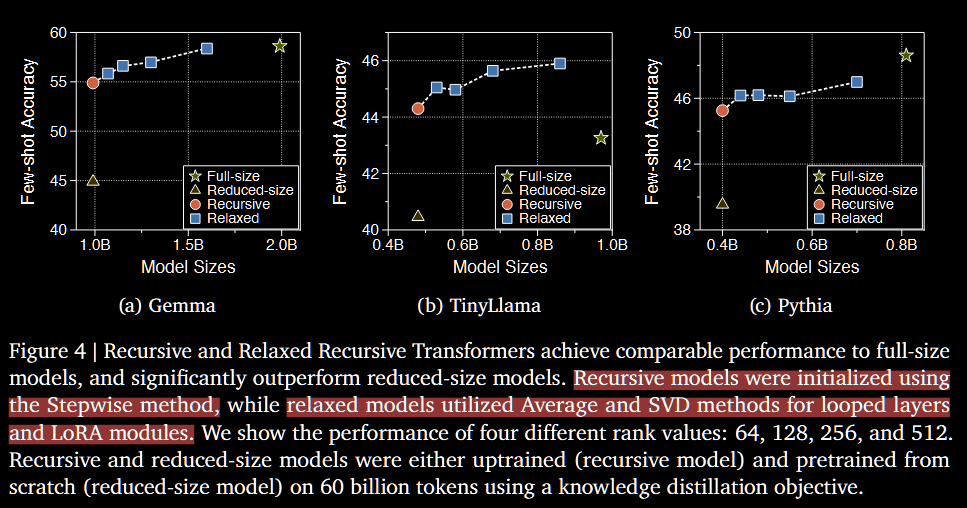
3.4. RT의 초기화 방법
Stepwise가 짱임.
3.5. RRT의 초기화 방법
- Stepwise: Residual ()이 너무 큼
⇒ LoRA로 매꾸기 힘듦 - Average: Residual이 상대적으로 작음
⇒ LoRA로 매꾸기 good
Average가 짱임.
3.6. Uptraining & KD
생략
3.7 EE 가능성
가능
3.8. Continuous Depth-wise Batching
굿.
