Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing
Edge AI에 대한 내용
Abstract
Mobile device와 같은 계산 자원이 제한된 device에서는 computation-intensive한 DNN 기반 작업을 실행하는 것은 어렵다.
전통적인 cloud-assisted DNN inference는 network latency으로 인해 real-time performance ↓
==> device-edge synergy를 통한 DNN 협업 inference를 가능하게 하는 Edgent framework를 제안
Edgent는 두 가지 설계 요소를 활용
- DNN partitioning
DNN Partitioning은 모델을 여러 부분으로 나누어, 각각의 부분을 클라우드와 엣지 디바이 스 간에 적절히 배치하여 병렬적으로 처리합. 이는 특정 연산이 클라우드(고성능)와 엣지 (저성능)의 어느 쪽에서 실행되는 것이 더 적합한지 결정함으로써 효율성을 극대화. - DNN right-sizing
DNN Right-Sizing은 엣지 디바이스의 제한된 자원을 고려하여, DNN의 크기를 조정하는 최적화 기법. 이 과정에서 모델을 경량화하거나 연산량을 줄이는 방법이 적용.
Edgent는 실제 환경에서의 네트워크 변동성을 고려하여, static 및 dynamic network environment 모두에서 최적화되도록 설계되었다.
구체적으로,
대역폭 변화가 적은 static 환경에서는 regression-based prediction model을 사용하여 최적 구성을 도출
대역폭 변화가 큰 dynamic 환경에서는 online change point detection algorithm을 통해 현재 대역폭 상태를 최적 구성에 매핑하여 최적의 실행 계획을 생성
I. Introduction
DNN 계산량 ↑
==> mobile evice에서 효율적 사용 X
==> powerful cloud datacenter or intensive DNN computation
==> a large amount of data (e.g., images and videos) will be transferred between the end devices and the remote cloud datacenter backwards and forwards via a long wide-area network
==> latency ↑ , energy ↑
==> edge computing
==> network core에서 network edge로 cloud-computing을 이전하여 처리
==> on-demand lowlatency DNNs inference framework for supporting real-time
edge AI applications 가능
But
edge-based DNN inference는 여전히 edge server 와 mobile device 간의 available bandwidth에 크게 sensitive하다.
(그 대역폭이 1Mbps에서 50kbps로 감소하게 되면, edge-based DNN inference latencty는 0.123s에서 2.317s로 크게 증가함을 알 수 있다.)
실제 배치에서 불안정하고 변동성이 큰 네트워크 환경을 고려할 때, 다양한 네트워크 환경 하에서 특히 지능형 보안이나 산업용 로봇과 같은 미션 크리티컬 DNN 기반 애플리케이션을 위해 DNN inference를 추가로 최적화할 수 있을지에 대한 자연스러운 의문이 제기된다.
위의 의문을 해결하기 위해, 이 논문은 edgent라는 device-edge synergy를 통한 low-latency co-inference 프레임 워크를 제안
이를 달성하기 위한 두 가지 설계 조건
- DNN partitioning
가용 대역폭에 따라 DNN computation을 mobile device와 edge server 간에 adaptively partition하여 edge server의 computation 능력을 활용하는 방식
But
여전히 mobile device에서 실행되는 모델의 나머지 부분에 의해 성능이 제한
==> - DNN right-sizing
DNN inferenc를 중간 계층에서 조기 종료(Early Exit)하여 inference 속도를 가속화하는 방식
본질적으로, Early Exit 메커니즘은 latency와 accuracy 간의 tradeoff를 수반.
기존 자원을 활용하여 이 tradeoff 균형을 맞추기 위해 Edgent는 DNN partitioning과 DNN right-sizing을 on-demand 방식으로 공동 최적화합니다.
Edgent는 다양한 네트워크 조건을 고려하여, static, dynamic 네트워크 환경에서 더 나은 성능을 추구할 수 있도록 tailored(맞춤형) configuration 매커니즘을 구축
static 네트워크 환경 :
대역폭이 안정적이라고 간주하고, 현재 대역폭을 기반으로 실행 지연 시간 추정을 통해 협력 전략을 수립
이 경우, Edgent regression model을 학습하여,
layer-wise inference latency를 예측하고,
optimal configurations for DNN partitioning 과 DNN right-sizing를 도출한다.
dynamic 네트워크 환경 :
네트워크 변동에 영향을 덜 받기위해, 각 대역폭 상태에서 optimal 선택을 프로파일링하고 기록하여 look-up table을 구축. 또한, runtime optimizer를 통해 대역폭 상태 전환을 감지하고 이에 따라 optimal 구성을 매핑.
이처럼 서로 다른 네트워크 환경에 맞춘 설계를 통해 Edgent는 애플리케이션의 반응성 요구 사항을 위반하지 않으면서 inference 정확도를 극대화할 수 있다.
II. Related Work
low-latency + energy efficient mobile DNN을 위한 기존 3가지 기법
- runtime management
mobile device의 computation 작업을 cloud나 edge server로 오프로드하여 외부 계산 자원을 활용해 성능을 향상시키는 방법 - model architecture optimization
새로운 DNN 구조를 개발하는 것(ex) pruning, NAS...) - hardware acceleration
DNN 계산 작업을 하드웨어 수준에서 설계에 포함시키는 접근법
이 논문에서의 2가지 방법
- DNN partitioning
DNN partitioning은 특정 DNN model을 여러 연속적인 부분으로 분할하고, 이를 여러 참여 device에 배포하는 것
구체적으로, 일부 프레임워크는 DNN 분할을 활용하여 mobile device와 cloud 간의 계산 오프로드를 최적화하는 데 초점을 맞추는 한편, 다른 프레임워크는 mobile device 간에 계산 작업을 분산시키는 것을 목표로 한다. - DNN right-sizing
기존 환경의 제약 하에서 모델 크기를 조정하는 것
이 논문의 목표
partition point와 early exiting point 선택을 신중히 탐색할 수 있도록 결정 최적화 알고리즘을 면밀히 설계해야 하는 것. 이를 통해 accuracy와 lataency 간의 균형을 on-demanded manner 로 효과적으로 달성할 수 있다. 이러한 과정을 통해 사전 정의된 latency 제약 조건 하에서, latency 요구 사항을 준수하면서 DNN inference accuracy를 극대화하는 설계 목표를 실현하는 것이 목표이다.
또한 안정적인 네트워크 시나리오에 초첨을 맞춘 기존 방식들과 다르게, 다양한 애플리케이션 시나리오와 실제 배포환경을 고려한다. (static, dynamic network에서 적합한 configurator와 runtime optimizer를 설계한다는 것)
III. Background And Motivation
A. A Brief Introduction on DNN
생략
B. Insufficiency of Device- or Edge-Only DNN Inference
전통적인 mobile DNN 계산은 mobile device에서만 수행되거나, 전적으로 cloud/edge server로 오프로드되는 방식으로 이루어진다. 그러나 이러한 두 가지 접근법은 종단 간 latency가 높아지는 등의 성능 저하를 초래할 수 있으며, 이는 실시간 애플리케이션의 latency 요구 사항을 충족하는 데 어려움을 겪게 만든다.
이를 설명하기 위해, 라즈베리 파이를 mobile device로, 데스크톱 PC를 edge server로 모사하여 클래식한 AlexNet 모델을 활용한 cifar-10 데이터셋 기반 이미지 인식 작업을 수행했다. 그림 2는 edge server와 mobile device(그림 2에서는 각각 Edge와 Device로 표기)에서 서로 다른 대역폭 하에서 다양한 방법의 종단 간 latency 분포를 보여준다.
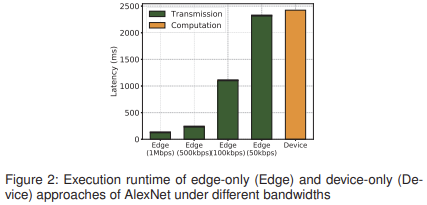
이는 edge-only 방식의 성능이 data transmission latency에 의해 좌우되며, available bandwidth에 매우 민감함을 나타낸다. 실제 네트워크 환경에서는 사용자 및 애플리케이션 간의 네트워크 자원 경쟁으로 bandwidth 자원이 부족하거나 mobile device의 계산 자원이 제한되는 경우가 많다. 이러한 이유로 device-only, edge-only 방법은 엄격한 실시간 요구 사항을 갖는 최신 모바일 애플리케이션을 지원하기에는 불충분.
C. DNN Partitioning and Right-Sizing towards Edge Intelligence
DNN Partitioning
DNN inference 성능 bottleneck을 더 잘 이해하기 위해, 그림 3에서는 라즈베리 파이에서 계층별 실행 latency와 계층별 중간 출력 데이터 크기를 정리하여 보여준다. 그림 3에서 알 수 있듯이, 각 계층의 latency와 출력 데이터 크기는 큰 이질성을 보이며, latency가 높은 계층이 반드시 더 큰 데이터를 출력하는 것은 아닌 것을 볼 수 있다.
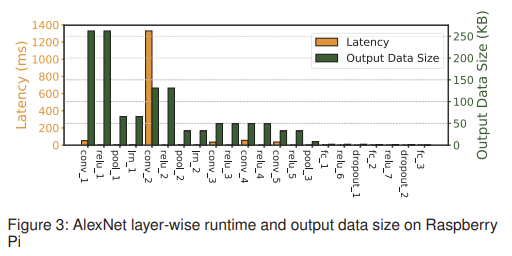
==> 계산 집약적인 부분을 서버에서 계산, 나머지는 device에서 계산
==> 1번의 낮은 transmission cost
==> 그림 3에서 두 번째 local response normalization layer(lrn_2)를 기점으로 이전은 edge에서, 이후는 device에서 계산
==> 이와 같이, device와 edge 간에 model을 분할함으로써, 근접한 위치의 하이브리드 계산 자원을 종합적으로 활용하여 low-latency DNN inference를 달성할 수 있다.
DNN Right-Sizing
DNN partitioning은 latency를 상당히 줄일 수 있지만, 최적의 DNN partitioning을 적용하더라도 device에 남아 있는 계산 작업이 여전히 inference latency를 제한한다는 점에 유의해야 한다.
==> DNN Right-Sizing + DNN Partitioning
DNN Right-Sizing은 Early-Exit Mechanism을 통해 DNN inference 속도를 가속화한다. 예를들어, DNN 모델을 다중 종료 지점(exit points)을 함께 학습시킴으로써, 표준 AlexNet model이 그림 4에서 보여지는 바와 같이 branch를 포함한 Branchy AlexNet으로 변환될 수 있다. 짧은 가지(예: 종료 지점 1로 끝나는 가지)는 더 작은 모델 크기를 의미하며, 따라서 실행 시간이 더 짧아진다.

그림 4에서는 설명을 쉽게 하기 위해 CONV layer와 FC layer만을 표시했다. 이러한 새로운 branch 구조는 새로운 학습 방법을 요구한다. 본 논문에서는 오픈소스 BranchyNet프레임워크를 활용하여 branchy model 학습을 구현했다.
IV. Framework And Design
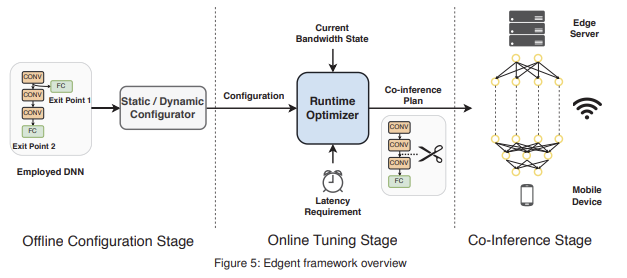
A. Framework Overview
Edgent는 static 및 dynamic bandwidth 환경 모두에서 latency 요구 사항을 충족하면서 accuracy를 최대화하는 optimal collaborative DNN inference plan을 생성한다.
Edgent는 다양한 네트워크 조건에서 더 나은 DNN inference 성능을 추구하는 것을 목표로 한다.
다음 그림과 같이 Edgent는 3가지 단계를 거친다.
1. Offline Configuration Stage
2. Online Tuning Stage
3. Co-Inference Stage
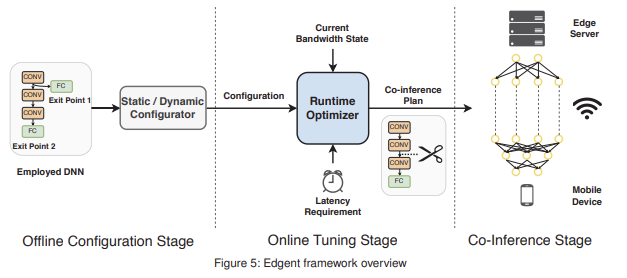
1. Offline Configuration Stage
사용될 DNN을 Static/Dynamic Configurator component에 입력하여, Online Tuning Stage에 사용할 적절할 구성을 생성.
Static Configuration :
trained regression model과 branchy DNN model로 구성되며, DNN infernece 중 bandwidth가 안정적인 경우에 사용된다(자세한 내용은 IV-B 절에서 설명).
Dynamic Configuration :
trained regression DNN model과 다양한 bandwidth 상태에 대한 최적 선택으로 구성되며, bandwidth 상태가 변동하는 경우에 적응적으로 사용된다(자세한 내용은 IV-C 절에서 설명).
2. Online Tuning Stage
Edgent는 현재 대역폭 상태를 측정하고, 사전 정의된 latency 요구 사항과 이전 단계에서 얻은 구성을 바탕으로 DNN Partitioning과 DNN Right-Sizing에 대한 결합 최적화를 수행.
이 단계의 목표는 주어진 latency 요구 사항을 준수하면서 inference accuracy를 최대화하는 것.
3. Co-Inference Stage
이전 단계에서 생성된 협력 추론 계획(즉, 선택된 Early exit point과 partition point)을 기반으로 inference 수행. 구체적으로, partition point 이전의 layer는 edge server에서 실행되고, 남은 layer는 device에 남아 실행.
• Edgent는 Static/Dynamic 네트워크 환경 모두에서 동일한 워크플로우를 따르지만, Configurator와 Runtime Optimizer의 기능은 환경에 따라 다르다
static 대역폭 환경에서는 static configurator가
1. regression model을 학습하여
2. inference latency를 예측하고,
3. branchy DNN을 학습시켜 early-exit 메커니즘을 활성화한다.
offline에서 생성된 static configuration에는
trained regression models과 trained branchy DNN이 포함되며,
이를 기반으로 Runtime Optimizer가 최적의 협력 추론 계획을 도출.
dynamic 대역폭 환경에서는 dynamic configurator가 change point detector를 사용하여 서로 다른 대역폭 상태에 대한 최적 선택을 기록한 Configuration Map을 생성한다. 이 맵은 Runtime Optimizer로 전달되어 최적의 협력 추론 계획을 생성하는 데 사용된다.
B. Edgent for Static Environment
1. Offline Configuration Stage
Static Configurator의 핵심 아이디어는
layer-wise inference latency를 예측하기 위한 regression model을 학습하고,
early-exit 메커니즘을 활성화하기 위해 branchy model을 학습하는 것.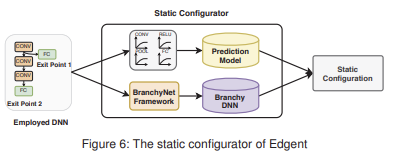
위 그림 6를 보면 static configurator는 2가지 작업을 수행함을 알 수 있다.
profile layer-wise inference latency
모바일 기기와 엣지 서버에서 각각 계층별 추론 시간을 프로파일링하고,
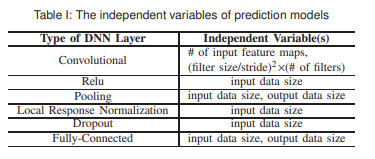
이를 바탕으로, 표 1에 나와 있는 DNN 계층별 특성(예: 입력 크기, 필터 수 등)을 독립 변수로 사용하여,
다양한 유형의 DNN 계층(ex. conv layer, fc layer 등)에 대한 regression model을 학습시킨다.train branchy DNN
BranchyNet 프레임워크를 활용하여 DNN model에 다중 exit points를 학습시키고,
이를 통해 branchy DNN을 생성.
2. Online Tuning Stage
Online Tuning Stage에서는 이전 단계의 결과를 static configuration을 사용하여, Runtime Optimizer가 최적의 exit point와 partition point를 탐색한다.
위 그림을 보면 알 수 있듯이, Runtime Optimizer의 input으로는 다음 3가지가 들어간다.
1. static configuration
2. edge server와 device 간의 측정된 대역폭
3. layency 요구 사항이를 바탕으로 Runtime Optimizer는
1. 모든 exit point를 선형적으로 탐색하며,
2. 각 exit point에서의 latency와 accuracy를 검사하여,
3. latency 요구사항을 만족하면서 가장 높은 accuracy를 제공하는 지점을 선택한다.이 과정은 pretrained된 regression 모델을 사용해 각 지점의 latency를 빠르게 예측하여 효율적으로 수행된다.
(case 1)
인 경우 결과는 아래와 같다.
(case 2)
인 경우 결과는 아래와 같다.
(case 3)







C. Edgent for Dynamic Environment
Dynamic 환경에서 Edgent는
1. Offline Configuration Stage에서 과거의 대역폭 추적 데이터를 활용하여 최적 선택을 기록한 configuration map을 형성하고,
2. Online Tuning Stage에서 이 configuration map을 기반으로 optimal partition plan을 찾는 것이다.
1. Offline Configuration Stage
(1) 과거의 bandwidth traces를 기반으로 bandwidth states(s1, s2, ...)를 추출하고,
(2) bandwidth states, latency requirement, employed DNN을 Configuration Map Constructor에 전달하여 현재 입력에 대한 Dynamic Configuration(최적의 exit point과 partition point)을 획득.// dynamic configurator는 TCP 연결의 특정 구간에서 클라이언트 측 처리량의 평균을 대역폭 상태 s로 정의.
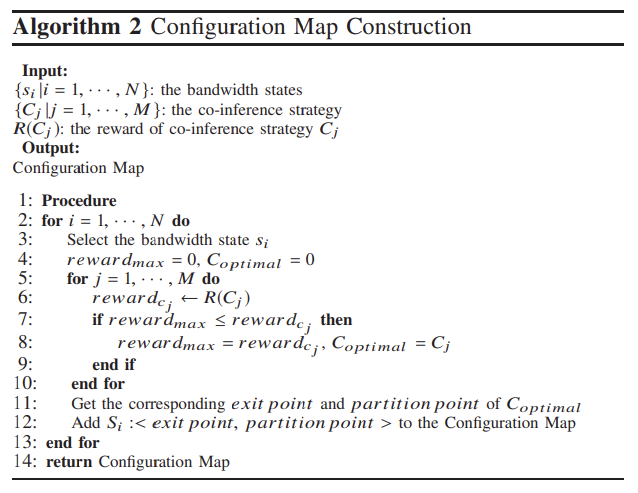
각 대역폭 상태에 대해, 구성 맵 생성기를 호출하여 최적의 공동 추론 계획을 획득하고 이를 동적 구성으로 맵에 기록합니다.Configuration Map Constructor에서 실행되는 configuration map 생성 알고리즘은 아래와 같다.
알고리즘 2의 핵심 아이디어는 reward 함수를 활용하여 exit point와 partition point 선택을 평가하는 것이다.
reward 함수는 아래와 같다.
은 현재 탐색 단계에서의 평균 실행 지연 시간(즉, 현재 탐색 단계에서 선택된 종료 지점과 분할 지점)에 해당하며, 이는 으로 계산된다. 또한 은 지연 요구사항이다.
이를통해 알 수 있는 점은, reward 함수는 지연 요구사항을 우선적으로 평가하는 것을 알 수 있다. 이면, reward가 이 되기 때문이다.
지연 요구 사항이 충족되면, 현재 단계의 보상은 으로 계산된다.
// acc는 현재 inference의 accuracy이다.
이를통해 알 수 있는 점은, reward 함수은 지연 요구사항을 충족한 상황에서 탐색의 정확도를 향상시키는데 중점을 둔다는 것이다. 단, 만약 정확도가 비슷할경우, throughput을 본다.이제 configuration map을 만드는 과정. 즉, 위의 알고리즘 2를 요약하자면 다음과 같다.
1. 각 대역폭 상태()를 순차적으로 선택
2. 선택된 에 대해 모든 co-inference strategy()를 탐색하면서 reward 최고값을 선택
3. 모든 대역폭 상태()에 대해 위 작업 반복
==> 모든 대역폭 상태에 대한 최적의 co-inference strategy가 포함된 cofiguration map을 반환// : 대역폭 추적 데이터에서 추출된 bandwidth state
// : co-inference strategy (exit point와 partition point의 조합)
// : co-inference strategy 에 대한 reward
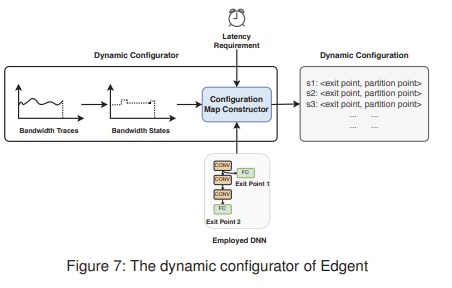
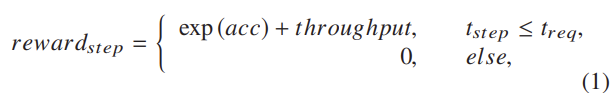
2. Online Tuning Stage
Online Tuning Stage에서는 이전 단계의 결과를 dynamic configuration을 사용하여, Runtime Optimizer가 최적의 exit point와 partition point를 탐색한다.
그냥 읽어보면 이해할 수 있어 생략함.

Performance Evaluation
생략
Conclusion
생략
