On-Device Training Under 256KB Memory
Tiny Training Engine에 대한 내용
Abstract
On-Device Training은 pre-trained된 modle을 fine-tuning하여, 센서로 들어온 데이터에 적응할 수 있게 한다.
사용자는 데이터를 클라우드로 전송하지 않고도 customized AI model을 활용할 수 있어 개인정보를 보호할 수 있다.
But
IoT devie memory resources ↓
==> 256KB만의 memory로 On-Device Training이 가능하게 하는 algorithm-system com-design framework(Tiny Training Engine)를 소개
On-Device Training의 어려움 2가지
- Quantized neural network는 optimize하기 어렵다. 왜냐하면, low bit-precision, normalization의 부족
- full backpropagation을 못할만큼 작은 memory
위 어려움의 해결법
- Quantizaiton Aware Scaling을 통해
gradient scaling을 calibrate하고,
8-bit quantized training을 안정화한다. - Sparse Update를 통해
중요도가 낮은 layer과 sub-tensor의 계산을 생략
by prune the backwark computation graph
1. Introduction
pre-trained된 model을 edge device에서 fine-tuning하면 얻는 이점
- 사용자 맞춤화 : local에서 수집한 데이터를 바탕으로 model을 fine-tuning하게 되면, 나만의 model을 얻게 되는것
- 프라이버시 보호
- lifelong learning
기존의 framework와 algorithm이 IoT에서 사용 불가능한 이유
- 현대의 deep-learning training framework(ex) PyTorch, TensorFlow)는 주로 클라우드 서버용으로 설계되어 있으며, 작은 모델(ex) MobileNetV2-w0.35)을 배치 크기 1로 학습하더라도 300MB 이상의 메모리를 요구(그림 1 참조).

- 엣지 deep-learning inference framework(ex) TVM, TF-Lite, NCNN 등)는 간소화된 런타임을 제공하지만, back-propagation를 지원하지 않는다.
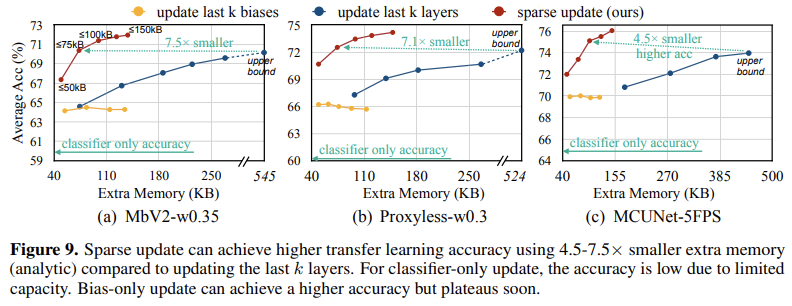
- 저비용 효율적 transfer learning 알고리즘(ex) 마지막 분류기 계층만 학습하거나, 편향(bias)만 업데이트하는 방식 등)이 존재하지만, 이 경우 정확도가 크게 떨어진다(그림 9 참조).
- microcontroller와 같은 device는 bare-metal 환경으로, 운영 체제와 기존 training framework가 요구하는 runtime support가 없다.
Bare-metal 환경이란? 운영체제 없이 동작하는 환경을 의미합니다. 코드는 하드웨어(ex) CPU, 메모리, I/O 장치)에 직접 접근하여 실행된다. 이 경우, 모든 하드웨어 초기화 및 제어는 사용자가 작성한 코드에서 직접 처리해야 한다.
운영체제가 제공하는 메모리 관리, 스케줄링, 드라이버 기능이 없기 때문에, 모든 것을 개발자가 제어해야 한다.
(ex) 특정 레지스터를 직접 조작하거나, 하드웨어 인터럽트를 처리하는 코드 작성)
==> tiny on-device training을 위해서는 alorithm과 system을 같이 설계해야한다.
논문에서 제시한 접근법 3가지
- QAS를 통한 optimization
- Sparse Update를 통한 memory 사용량 감소
- Tiny Training Engine(TTE)를 통한 경량 학습 시스템 구현
이중 TTE를 짧게 설명하자면,
TTE는 code generation에 기반을 두고 있고, auto-differentiation을 compile time에 offload하여 runtime overhead를 크게 줄인다.
TTE는 graph pruning 및 reordering을 통해 Sparse Update를 가능하게 하고, 측정 가능한 memory 절감 및 속도 향상을 달성하게 한다.
2. Approach
Preliminaries
NN은 edge device의 제한된 memory에 맞추기 위해, inference에서 일반적으로 quantization한다.
fp32 linear layer는 아래와 같다.
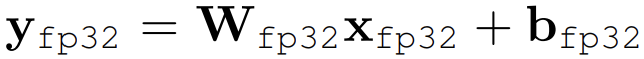
이를 int8로 qunatized할 경우는 아래와 같다.
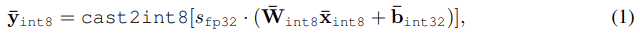
// ⨪ 는 fixed-point number 표현으로 quantized된 tensor
// s는 연산 결과를 다시 int8로 매핑하기 위한 fp scaling factor이다.
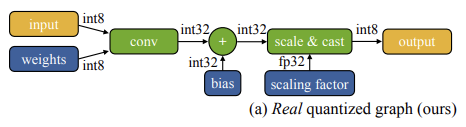
아래 그림은 위 식을 그림으로 표현한 것이다.
weight update 또한 int8 형식으로 유지된다. update된 weight 공식은 아래와 같다.
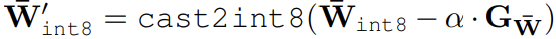 // 𝛼 는 learning rate
// $$G_{ \overline{W} }$$ 는 weight의 gradient이다. gradient 계산 또한 int8로 수행된다.
// 𝛼 는 learning rate
// $$G_{ \overline{W} }$$ 는 weight의 gradient이다. gradient 계산 또한 int8로 수행된다.
이 논문에서의 학습은 실제 양자화 그래프를 업데이트한다. 실제 양자화 그래프는 아래이다.
이는 cloud에서 fake quantized graph를 training한 후 배포를 위해 실제 양자화 그래프로 변환하는 QAT(Quantization Aware Training)과 근본적으로 다르다.
fake quantized graph는 아래 그림에서 (b)에 해당한다.
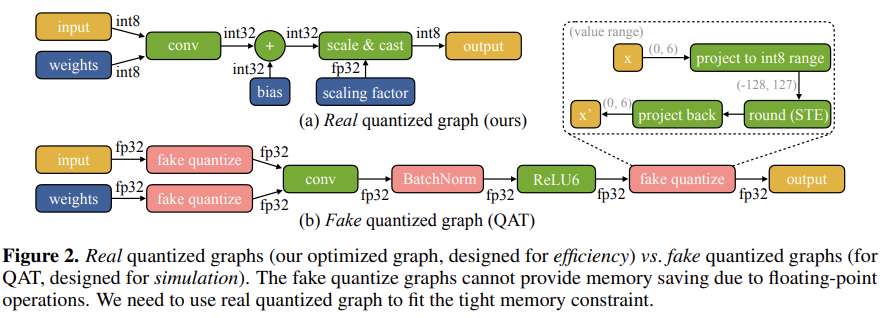
2.1. Optimizing Real Quantized Graphs
실제 양자화 그래프를 학습하는 것은 cloud에서 fp model을 fine-tuning 하는 것 보다 어렵다.
왜냐하면 quantized graph는
1. 서로 다른 비트 정밀도를 가진 tensor를 포함하고 있고(int8, int32, fp32),
2. Batch Normalization layer가 fused 되어 존재하지 않기 때문에 gradient update가 불안정하기 때문이다.
Gradient scale mismatch.
양자화를 하였을 때는 그렇지 않았을 때 보다 정확도가 낮다. 즉, quantization 과정이 gradient update를 왜곡한다. 이를 검증하기 위해, CIFAR dataset에서 학습 초기에 각 tensor에 대한 weight norm ()과 gradient norm ()의 비율 ()를 그래프로 나타냈다.
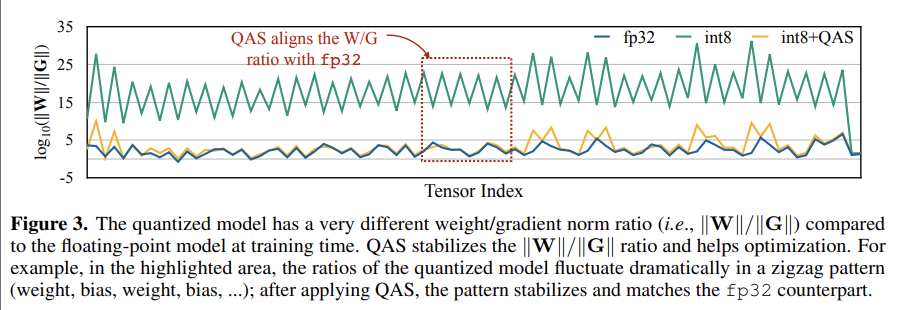
이를통해 알 수 있는 것은
- QAS를 하지 않았을 때(그래프의 int8)는 그 비율()이 훨씬 크다.
- quantized 이후(그래프의 int8) 비율 패턴이 다르다.
==> 정확도 저하
Quantization-aware scaling (QAS).
QAS는 위의 문제(비율 차이로 인한 정확도 저하)를 해결하는 방법이다.
우선 위의 문제가 왜 발생하는 지 살펴보자.
weight matrix를 linear layer의 라고 가정하면,
과 는 각각 input과 output channel이 된다.
per-tensor quantization을 하게 되면,
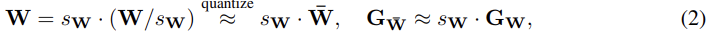
이렇게 되고,
비율 을 살펴 보면,
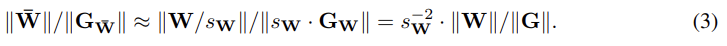
이렇게 되어, weight와 gradient의 비율이 만큼 어긋나 있음을 알수 있다.
이 문제를 해결법은 quantized graph의 gradient를 보정하는 QAS이다.
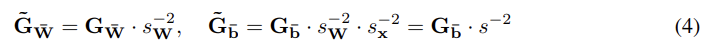
// 는 입력 를 quantized하기 위한 scaling factor이며, scalar 값이다.)
위를 기준으로 를 계산하면 아래와 같다.
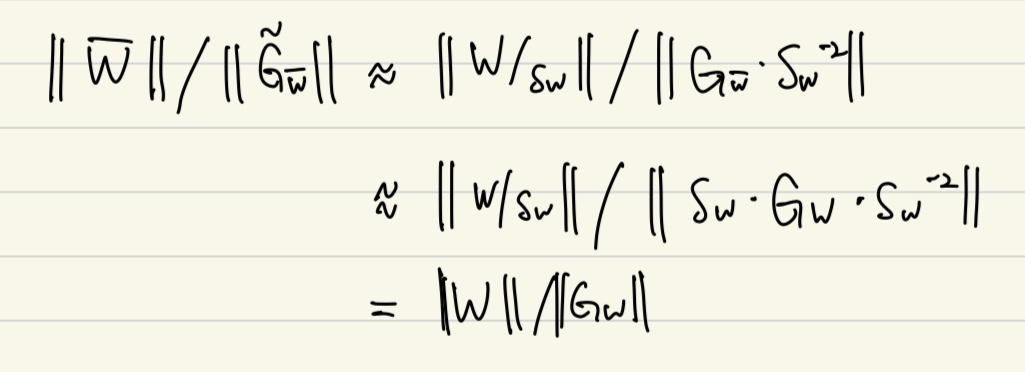
이와 같이되어 figure3의 fp32와 비슷한 그래프가 나오게 되는 것이다.
2.2. Memory-Efficient Sparse Update
QAS를 통해 quantized된 model의 optimized가 가능해졌지만, 전체 model(또는 마지막 몇 개의 블록)을 update하려면 대량의 메모리가 필요하며, 이는 TinyML 환경에서는 감당할 수 없다. 이를 해결하기 위해, layer과 tensor를 sparsely하게 update하는 방식을 도입한다.
Sparse layer/tensor update.
layer과 tensor를 sparsely하게 update한다는 말은
training에서 gradient를 pruning하여 model을 sparsely update한다는 말이다.
즉, 메모리 예산이 매우 제한적인 상황에서, 덜 중요한 parameter의 update를 생략함으로써 메모리 사용량과 계산 비용을 줄인다.
linear layer 의 update를 고려해보면,
이후 layer에서 출력 gradient 가 주어지면,
gradient update는 로 계산된다.
여기서 bias update는 intermediate activation 를 저장할 필요가 없기 때문에 메모리 사용량이 적어진다. 반면, weight update는 더 많은 메모리를 소모하지만 더 높은 표현력을 제공한다.
자세한 내용은TintTL의 Intorduction 참고.
이를 고려해 보면 우리가 update하는 방법으로는 4가지 방법이 존재한다.

그러나 메모리 제한 내에서 적절한 sparse update 방식을 찾는 것은 방대한 조합 공간 때문에 매우 어렵다.
Automated selection with contribution analysis.
위에서 말했듯 '메모리 제한 내에서 적절한 sparse update 방식을 찾는 것은 방대한 조합 공간 때문에 매우 어렵'기에 contribution analysis를 통해 sparse update 방식을 자동으로 도출한다.
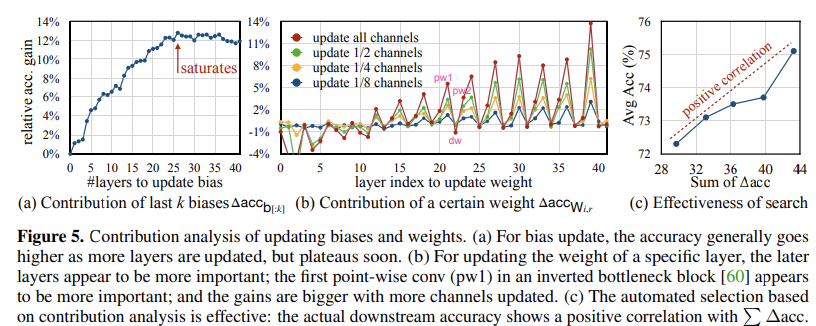
contribution analysis는 말그대로 각 bias, weight가 accuracy에 미치는 기여도를 계한한다. 개의 layer를 가진 conv NN에서, 다음과 같은 정확도 향상을 측정한다.
1. bias :
마지막 개의 bias 를 update(only bias)했을 때 accuracy 향상 정도를 classifier(NN에서 마지막 layer)만 update한 경우와 비교하여 로 정의.
2. weight :
특정 layer의 weight 를 (channel update 비율r로) 추가로 업데이트했을 때, bias만 update한 경우와 비교하여 accuracy 향상 정도를 로 정의.
이후 과 ()를 계산한 후, 다음 optimize 문제를 해결한다.
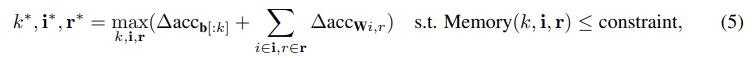
// 는 update 대상 weight를 가진 layer의 index set
// 는 해당 update 비율 (1/8, 1/4, 1/2, 1)
이 optimize 문제를 해결함으로써 bias update layer의 개수, update할 weight의 부분 집합의 조합을 찾아, 총 기여도를 극대화하면서도 메모리 제약 조건을 초과하지 않도록 한다.
contribution analysis 예시는 아래 그림에서 확인할 수 있다.
2.3. Tiny Training Engine (TTE)
2.1. Optimizing Real Quantized Graphs, 2.2. Memory-Efficient Sparse Update에서 이론적으로 예상되는 메모리 절감 효과는 기존 DNN framework의 redundant한 runtime과 graph pruning의 부족으로 인해 실제 측정된 메모리 절감으로 이어지지 않는다.
==> co-designe efficient training system TTE
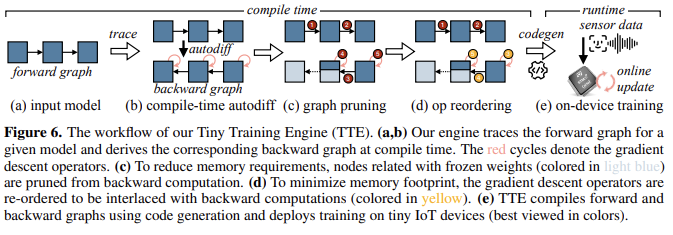
Compile-time differentiation and code generation.
솔직히 잘 모르겠다...
Backward graph pruning for sparse update.
솔직히 잘 모르겠다...
Operator reordering and in-place update.
솔직히 잘 모르겠다...
3. Experiments
생략
4. Related Work
생략
5. Conclusion
생략
