Group Normalization
Group Normalization 논문에 대한 내용
Abstract
Batch Normalization은 batch 차원을 기준으로 정규화를 수행하기에,
문제점 1. batch 크기가 작아질 수록 batch statistics estimation이 정확하지 않게된다.
문제점 2. 메모리 소비 ↑ ==> 소규모 batch를 요구하는 CV 작업에 불리
해결책 Group Normalization
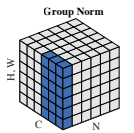
GN은 channel을 여러 group으로 나누고, 각 group의 평균과 분산을 계산하여 정규화를 수행
==> batch 크기에 의존 X
Batch Normalization이란?
배치 정규화(batch normalization, BN)는 층으로 들어가는 입력값이 한쪽으로 쏠리거나 너무 퍼지거나 너무 좁아지지 않게 해주는 인공신경망 기법이다. 여러 입력값을 모은 배치에 대해, 각 층의 입력값의 평균과 표준편차를 다시 맞추어 주어, 입력값이 쏠리는 것을 막는다.
wikipedia Batch Normalization
Introduction
BN 단점
BN이 효과적으로 작동하려면 충분히 큰 batch 크기(32, 16)가 요구된다.
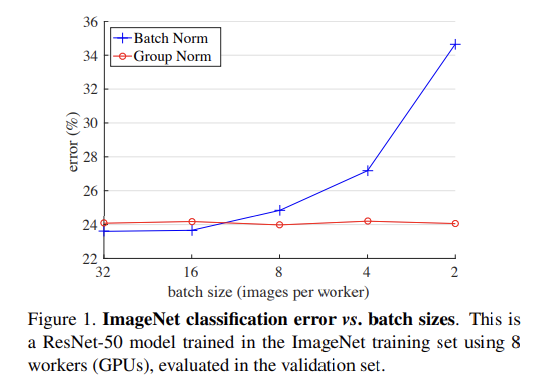
batch 크기가 작아지면 batch statistics estimation이 부정확해지고, 오류 ↑
==> 최근 많은 모델은 메모리를 많이 소비하는 큰 batch 크기로 학습
==> edge device같은 메모리가 작은 곳에서 training 하기 위해서는 BN 불가
GN
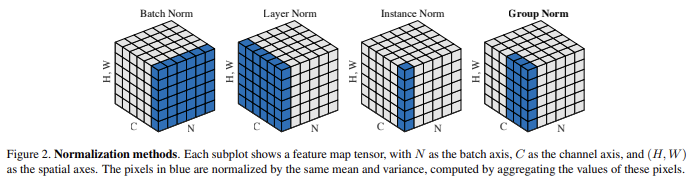
GN은 channel을 group으로 나누고 각 group 내의 특징을 normalization한다.
따라서, GN은 batch 차원을 활용하지 않으므로, 계산이 batch 크기와 무관하다.
(위 사진(Figure 1)을 보면 알 수 있다.)
Related Work
BN 단점
batch라는 개념은 항상 존재하지 않거나, 상황에 따라 변할 수 있다.
예를들어, inference 때에는 BN이 적절하지 않다. 왜냐하면, BN에서 평균, 분산은 training data set에서 pre-compute 되기 때문이다. (Covariate Shift)
따라서 test 시에는 적절치 않는다.
즉, 미리 계산된 통계(평균, 분산)은 test set에서 않맞으니까, test 시점에서 불일치 초래.
위 BN의 단점을 극복하기 위한 시도들
- Layer Normalization : LN은 channel 차원에서 normalization
- Instance Normalization : IN은 각 샘플에 대해 normalization
- Weight Normalizatoin : WN은 feature가 아닌 filter weights에 normalization
small batches 문제의 해결 시도들
- loffe는 작은 배치와 관련된 배치 정규화의 문제를 완화하는 Batch ReNomalization(BR)을 제안.
BR은 BN에서 추정된 평균과 분산을 일정 범위 내로 제한하는 두 개의 추가 parameters를 도입하여, small batches에서의 값의 변동을 줄인다.
하지만
BR 또한 batch-dependent함, batch ↓ ==> accuracy ↓
- 여러 GPU에 걸쳐 평균과 분산을 계산하는 synchronized BN.
하지만
synchronized BN 또한 small batches 문제를 극복 X,
BN에 요구사항에 비례하는 GPU 필요 문제 有
edge device에서의 asynchronous 해법의 사용을 방해
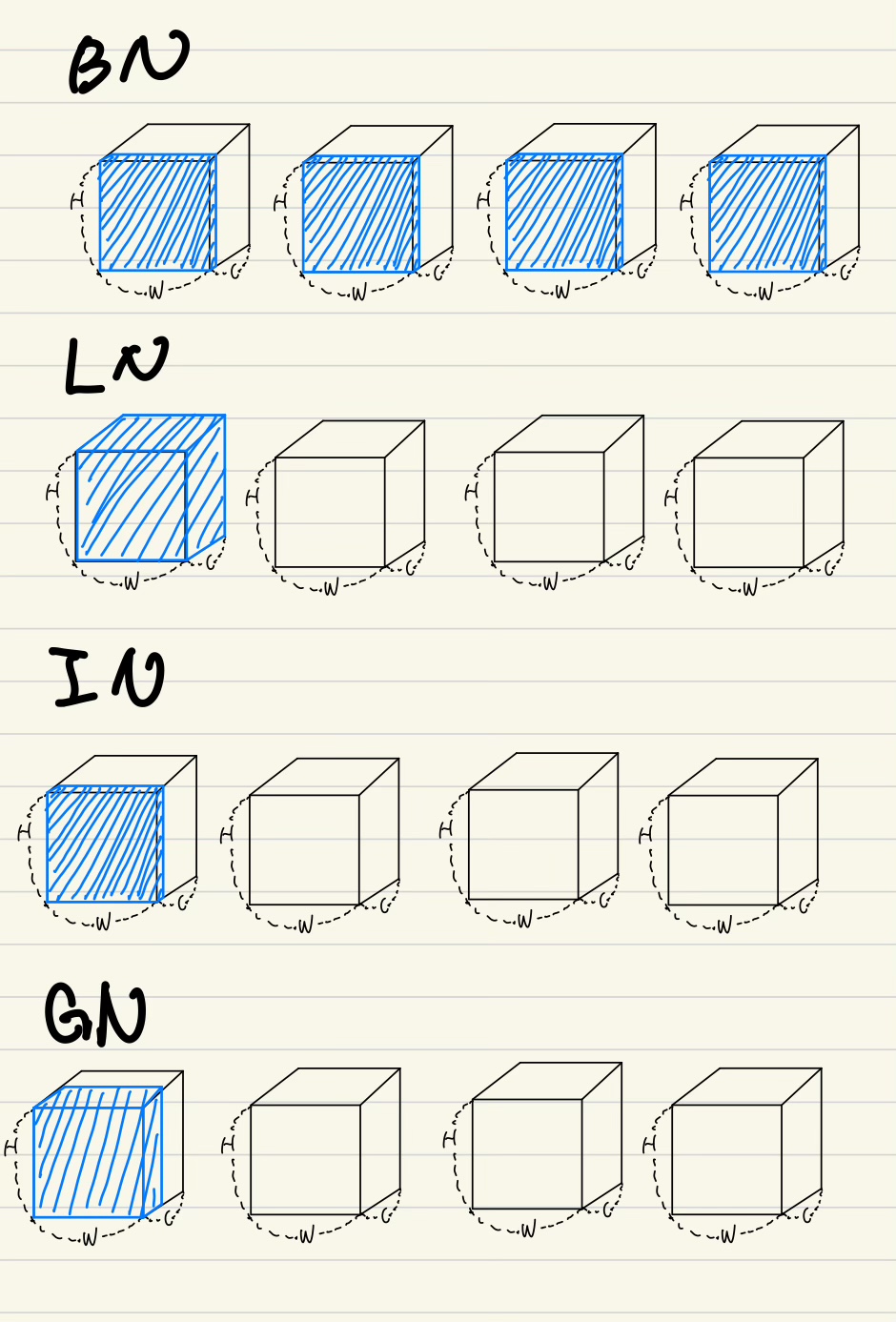
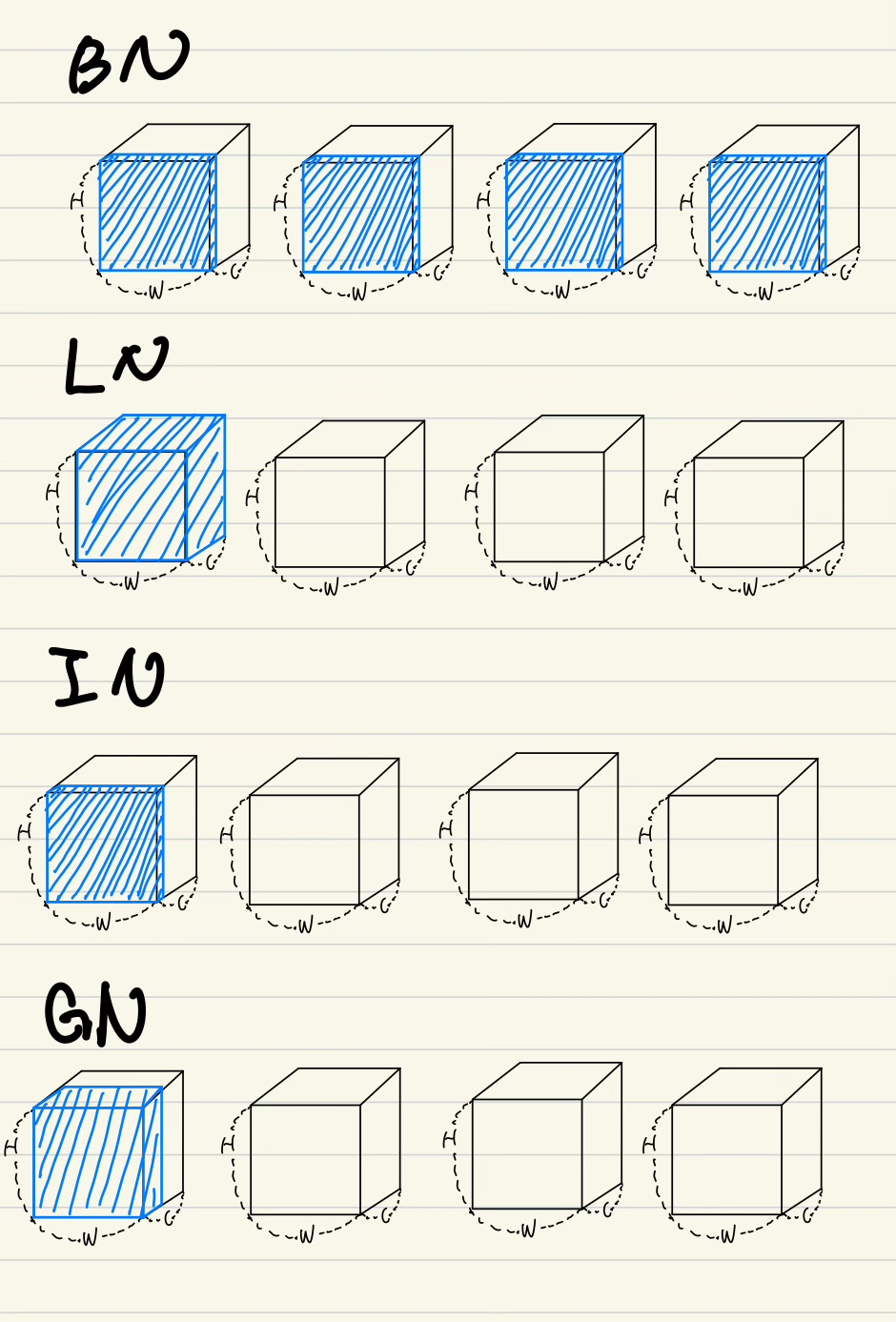
Group Normalization
Formulation
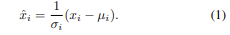
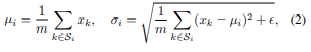
(2)의 에서 에 원소인 가 normalization이 되는 대상을 지정해줌
이것들의 차이가 어떤 normalization기법을 사용할지가 된다.
-
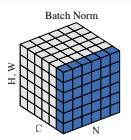
Batch Normalization
동일한 channel index를 갖는 픽셀들이 normalization의 대상이 된다는 뜻
-
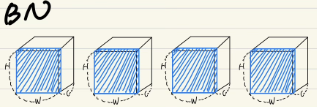
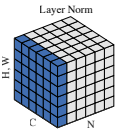
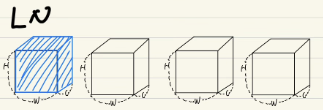
Layer Normalization
동일한 batch index를 갖는 픽셀들이 normalization의 대상이 된다는 뜻
즉 아래 두번째 그림에서 batch size가 4인데, 첫번째 박스가, batch index를 1을 갖고,
첫번째 박스에 있는 모든 channel들은 같은 batch index를 갖게되므로,
하나의 가 normalization의 대상이 된다.
-
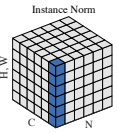
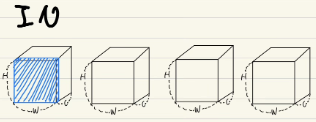
Instance Normalization
동일한 일한 batch index를 갖고, 동일한 channel index를 갖는 픽셀들이 normalization의 대상이 된다는 뜻
-
Group Normalization
동일한 batch index를 갖고, 동일한 group index를 갖는 픽셀들이 normalization의 대상이 된다는 뜻
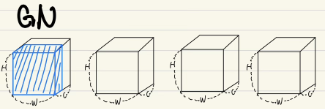
Relation to Prior Work
기본적으로 LN, IN, GN은 모두 batch axis에 따라 독립적으로 계산(정규화)을 한다.
Relation to LN
GN은 그룹 수를 로 설정하면, LN이 된다.
당연하다, GN 공식에서 가 가 되므로, 는 가 된다.
이때 이므로 는 의미가 없게되므로,
최종공식이 이 되어, LN과 같게된다.
Relation to IN
GN은 그룹 수를 로 설정하면, IN이 된다.
당연하다, GN 공식에서 가 이 되므로, 는 가 된다.
그러므로 최종공식이 이 되어, IN과 같게된다.
Experiments
생략
Discussion and Future Work
생략
