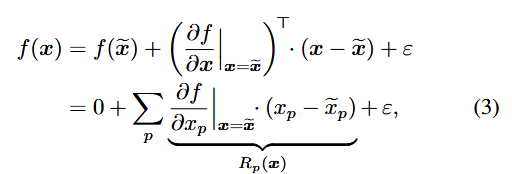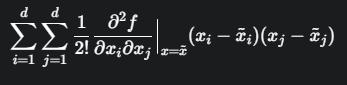DNN은 성능은 good,
but, lack of transparency == limiting the interpretability
==> DNN은 multilayer nonlinear structure 때문에, blackbox 처럼 작동
==> Deep Taylor Decomposition을 통해 분류에 쓰인 입력 요소들의 기여도(ex) 사진의 어느 부분이 사진을 cat으로 분류하는 데 어느 정도의 기여를 함)를 분해하여,
네트워크의 작동 방식을 설명
1. INTRODUCTION
Blackbox처럼 작동하는 DNN은 왜 특정 결정을 내렸는지 설명 못하는 transparent 문제
==> interpretable classifier로 model이 input을 기반으로 nonlinear classification desicion을 어떻게 내리는지 설명
DTD는 interpretable classifier를 만드는 데 사용되는 핵심 방법론
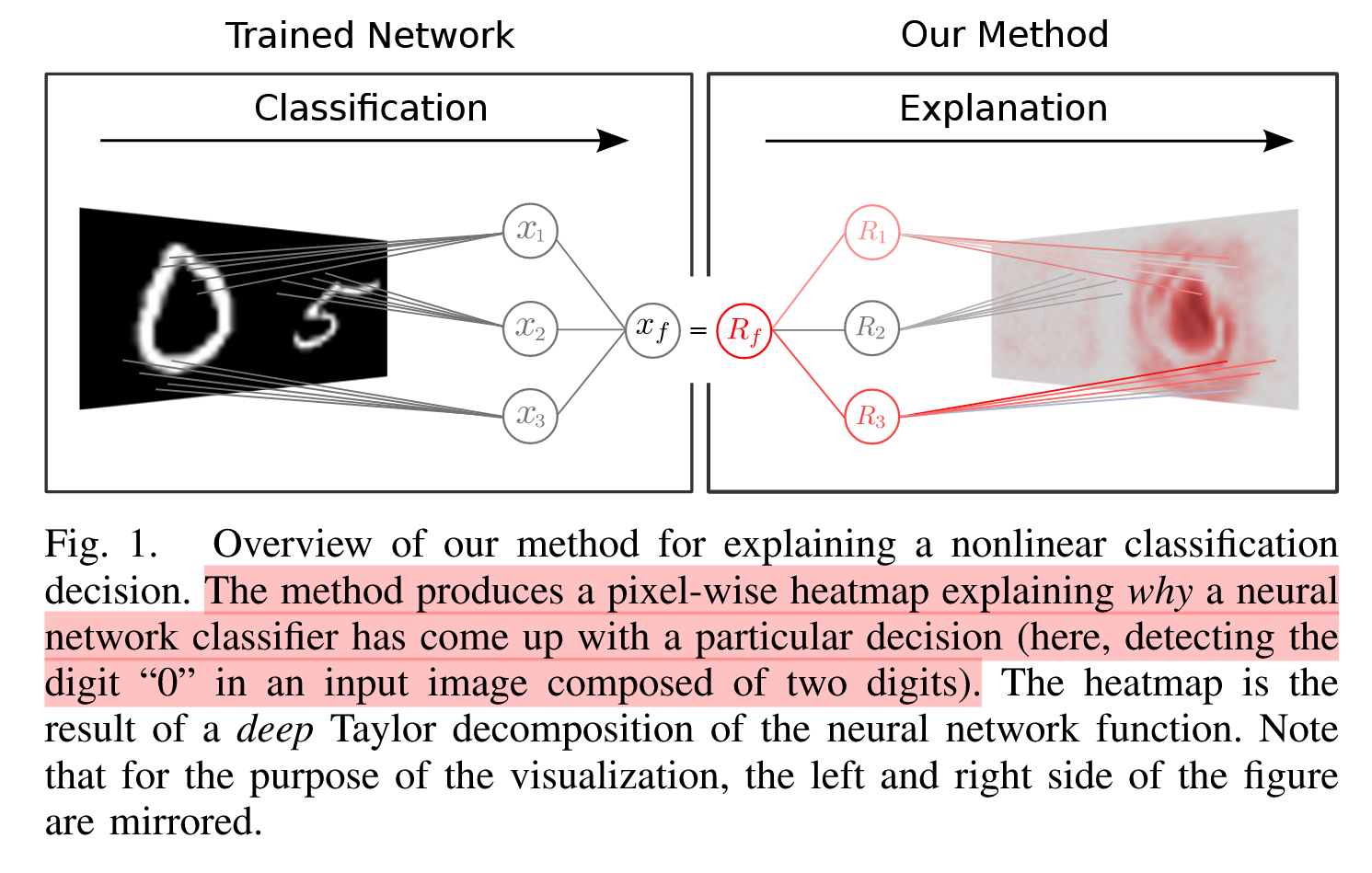
궁극적으로 입력 픽셀 공간에 분류 결정의 기여도를 보여주는 relevance map (heat map)(관련성 지도)를 생성
2. PIXEL-WISE DECOMPOSITION OF A FUNCTION
Heat map은 함수 값(즉, 신경망 출력)을 입력 변수에 redistribution 함으로써 생성
Redistribution 되는 양은 해당 입력 변수가 함수 값에 기여하는 정도!!!
이때, 함수(신경망)는 f:Rd→R+ 이다.
즉, 이미지 x∈RH×W이면, x∈Rd=H×W이고,
이 이미지의 prediction 결과는 고양이일 확률이기에, 0이상의 실수인 것이다.
이미지 x의 각 픽셀 p에 관련성 점수 Rp(x)를 mapping 해야한다.
이는 이미지 x에 대해 픽셀 p가 분류 결정 f(x)를 설명하는 데 어느 정도 기여하는지를 나타낸다.
(그러니까 이 픽셀이 ai의 결정에 어느정도 영향을 미쳤는 지를 나타냄)
우리는 Heatmapping이 아래에서 정의하는 특정 속성을 충족하길 바란다.
Definition 1. conservative(보존성)
∀x:f(x)=p∑Rp(x).
히트맵에 있는 모든 픽셀의 관련성 점수를 합친 값이 신경망 모델이 최종적으로 출력한 값, 즉 모델이 감지한 총 관련성(f(x))과 정확히 같아야 한다.
당연하다. Rp(x)는 f(x)를 분배한 것이기에,,,
Definition 2. positive(양수성)
∀x,p:Rp(x)≥0
히트맵의 모든 픽셀 관련성 점수가 0보다 크거나 같아야 한다. 음수 값이 없어야 한다는 뜻이다.
특정 픽셀이 모델의 결정에 '반대되는 증거'를 제공해서는 안 된다는 것을 의미.
예를 들어, 고양이 사진에서 어떤 픽셀은 '고양이일 가능성을 높이고', 다른 픽셀은 '고양이가 아닐 가능성을 높인다'는 식의 모순된 기여는 허용하지 않는다. 모든 픽셀은 감지된 객체의 존재를 지지하거나(양수 값), 아무런 영향도 미치지 않아야(0 값) 한다.
당연하다. f(X)≥0 이고, 이를 분배한 것이 Rp(x)이고, f(x)는 고양이일 확률이지 고양이가 아닐 확률이 아니기 때문이다.
Definition 3. consistent(일관성)
(f(x)=0)⇒(R(x)=0)
히트맵이 보존성(정의 1)과 양수성(정의 2)을 모두 만족할 때 '일관적'이라고 합니다.
특히, 모델이 이미지에서 아무것도 감지하지 못했을 경우(f(x)=0), 히트맵의 모든 픽셀 관련성 점수도 0이어야 합니다.
이는 객체가 없을 때 히트맵이 완전히 비어있어야 하며, 긍정적 기여와 부정적 기여가 상쇄되어 0이 되는 경우가 아니어야 함을 강조.
이 '일관성'은 논문에서 제안하는 히트맵 기법의 정확성을 평가하는 기준으로 사용.
즉, 이제 Definition 3. consistent를 만족하며, 의미 있는 heatmapping 기법을 정해야한다.
A. Taylor Decomposition
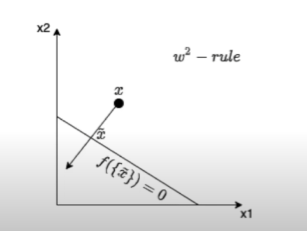
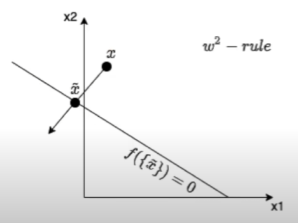
논문에서는 적절한 heatmapping 기법으로 f(x~)=0인 x~에서의 f의 taylor expansion을 선택했다.
이는 아래와 같다.
(∂x∂f∣∣∣∣∣x=x~)⊤
에서 전치가 있는 이유는 x가 벡터이기 때문이다.
또한 R(x)={Rp(x)} 이므로, ∑p∂xp∂f∣∣∣∣x=x~⋅(xp−x~p)는 R(x)가 된다.
이때, x는 벡터이므로, f(x)=R(x)+ϵ=∂x∂f∣∣∣∣x=x~⊙(x−x~)+ϵ
이다.
여기서 ϵ은 2차 이상의 항들인데, 이 항들은 동시에 여러 픽셀의 정보를 포함해서 재분배하기 어렵기에 무시한다.
(자세한 이유는 x가 벡터이므로, 2차 미분일 경우
이런 식으로 되서 그럼)
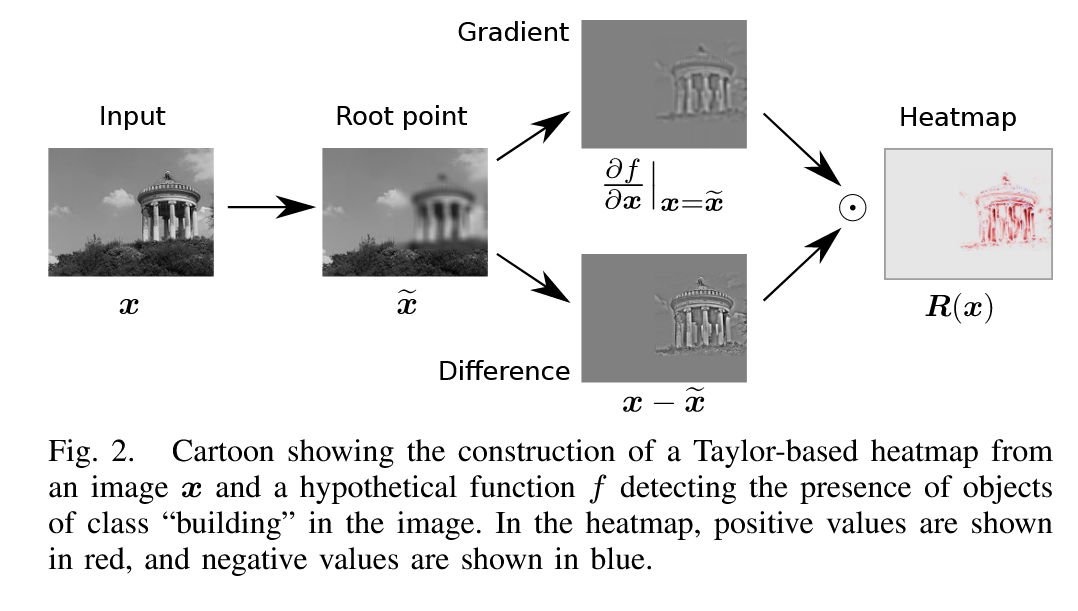
R(x)=∂x∂f∣∣∣∣x=x~⊙(x−x~) 의 각 항을 설명하면, 아래와 같다.
x~ : f(x~)=0 인 이미지 x~ 이므로, 물체를 판별하는 데 쓸모 없는 부분임
ex) 고양이가 아닌 부분
(x−x~) : 물체를 판별하는데 쓸모 있는 부분
∂x∂f∣∣∣∣x=x~⊙(x−x~) : x~의 각 픽셀이 f(x)에 영향을 주는 정도
이제 남은 일은 최적의 x~를 찾는 것이다
좋은 root point는 일부 픽셀에서 정보를 선택적으로 제거하는 동시에 주변 환경을 변경하지 않아야 한다. 즉 고양이 빼고는 정확한 이미지여야한다.
그렇기에, 다음의 ξ를 찾는 것이 목표이다.
ξmin∥ξ−x∥2subject tof(ξ)=0andξ∈X
이때, X는 input domain 이다.
하지만, 위 방법은 시간이 오래 걸리고, non-convexity 문제 발생
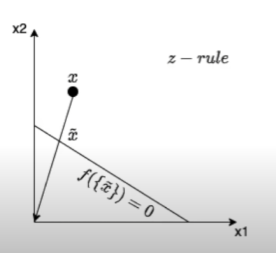
B. Sensitivity Analysis
위의 문제(적절한 root point를 찾는 것이 어렵다.)를 해결하는 가장 간단한 방법은 픽셀에 relevance를 부여할 때, squared derivatives of the classifier에 비례하게 부여하는 것이다.
R(x)∝(∂x∂f)2
이때, 제곱은 아다마르 곱셈이다.
그럼 이때의 root point는 무엇인가?
==> ξ=x−δ⋅∂x∂f
여기서 점 ξ는 실제 점 x로부터 함수 f가 가장 급격하게 감소하는 방향으로 무한히 작은 거리만큼 떨어져 있다.
하지만 여기서 문제가 있는데, ξ를 x에서 아주 살짝 떨어진 이미지로 했기에, f(ξ)가 f(x)와 비슷할 수 밖에 없어, ∑pRpδ(∂xp∂f)2는 작을 수 밖에 없다.
즉, 모든 관련성이 재분배 되지 않는 0차 항(f(ξ))에 흡수되기 때문에 보존적이지 않게 된다.(Definition 1 위반)
C. Deep Taylor Decomposition
Deep taylor decomposition은 divide-and-conquer에서 영감을 받았다. DNN이 학습한 함수가 인접한 layer 간의 값을 연결하는 더 간단한 하위 함수들의 집합으로 구조적으로 분해될 수 있다는 특성을 이용.
즉, input -> output이 아니라, 그 사이에 여러 layer를 하위의 함수로 취급하여, divide-and-conquer하는 것임
==>
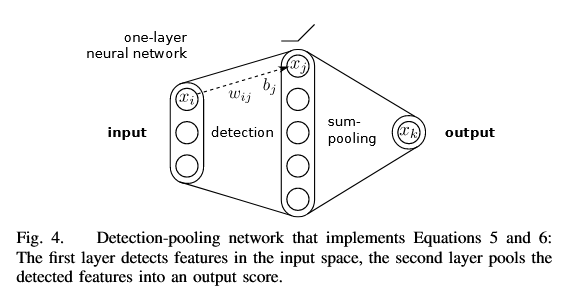
전체 신경망 함수 f를 직접적으로 고려하는 대신, 특정 layer의 뉴런 집합 {xi}을 다음 layer의 뉴런 xj에 할당된 relevance Rj로 mapping하는 국소 문제를 푸는 것임
// forward 방향: i -> j임
그럼 backward로 relevance backpropagation하면 j -> i 인데, 왜 뉴런 집합 {xi}을 xj에 할당된 Rj로 mapping 하지???
==>
그니까 taylor decomposition은 함수를 분해하는 거임
여기서 그 함수는 {xi}을 통해 얻은 xj의 relevance Rj를 분해하는 것이기에 그렇게 표현한 것
즉,
이 두 대상이 특정 함수 Rj({xi})에 의해 함수적으로 연결되어 있다고 가정하면,
이 국소적(local) 함수에 Taylor decomposition를 적용하여 상위 층의 관련성 Rj를 하위 층의 관련성 점수 집합 {Ri}로 재분배하는 것!
이렇게 하면 함수가 더 작아져서 taylor decomposition이 더 쉬워지며, 특히, root point를 찾는 것이 용이