Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity
논문 리뷰
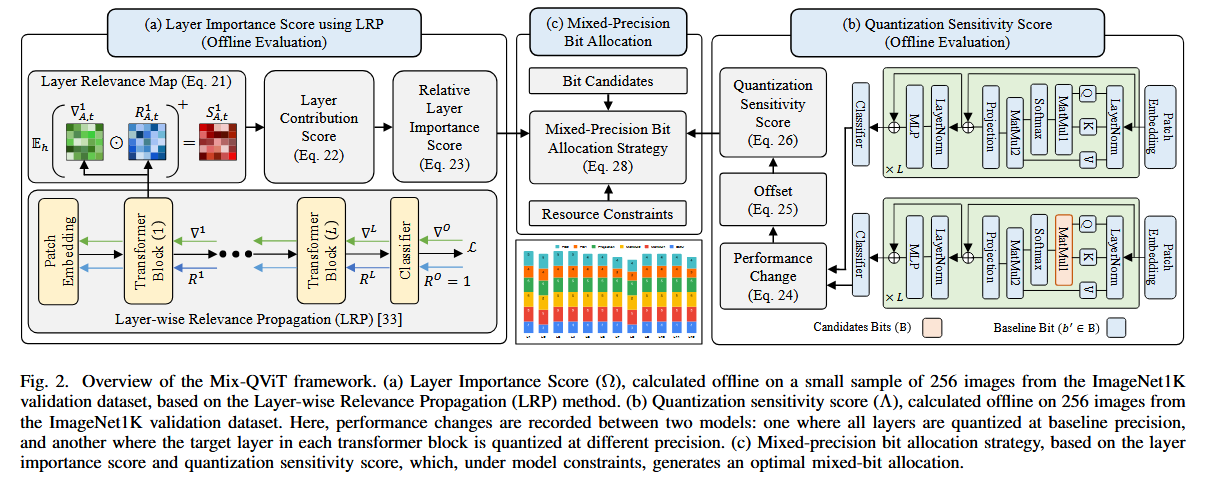
Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity
Mix-QViT에 대한 내용
Abstract
Quantization은 model size를 줄이는 좋은 기법이지만,
전체 network에서 uniform bit-width quantization하는 것은 suboptimal performance임
⇒ MPQ(Mixed-Precision Quantization)
하지만,
1) Exhaustive search algorithms에 의존
2) 각 layer의 특정 역할과 quantization sensitivity를 고려하지 않고, arbitrarily different bit-width로 quantization 함
⇒ Mix-QViT (explainability-driven MPQ framework)
아래 2가지 criteria로 각 layer별로 bit-width를 부여
1) LRP(Layer-wise Relevance Propagation)으로 평가된 layer importance
(각 layer가 final classification에 얼마나 영향을 미치는 지 나타냄)
2) Quantization sensitivity
(다른 layer들을 baseline precision으로 유지하면서, 각 layer를 다양한 precision으로 quantization 했을 때, 성능에 미치는 영향을 평가)
+
추가적으로,
PTQ에서 post-LayerNorm activation에서 발생하는 extreme outliers를 줄이기 위한,
clipped channel-wise quantization 제안
Q1. Exhaustive search algorithms 란?
A1.
예시를 들어 설명하겠다.상황 설정 및 필요한 가정:
- 모델:
비전 트랜스포머(ViT) 모델이라고 가정합니다.- 레이어 수:
간단하게 이 ViT 모델이 총 3개의 레이어(Layer 0, Layer 1, Layer 2)로 구성되어 있다고 가정합시다.- 가능한 비트 너비 집합 B:
모델의 가중치(weights)와 활성화(activations)에 적용할 수 있는 비트 너비 선택지가{2비트, 4비트, 8비트}라고 가정합니다.
즉, 입니다. 여기서 비트 수가 낮을수록 모델 크기는 작아지고 빨라지지만 정확도 손실 가능성이 커집니다.- 각 레이어의 비트 너비 선택:
각 레이어 마다 가중치()와 활성화()에 대해 B에서 비트 너비를 선택할 수 있습니다.
예를 들어, Layer 0의 가중치를 4비트로, 활성화를 8비트로 설정할 수 있습니다. (즉, )- 전체 아키텍처 비트 너비 구성 S:
전체 모델의 비트 너비 구성은 각 레이어의 가중치-활성화 비트 너비 쌍의 집합입니다.
예를 들어, 와 같이 표현됩니다.- 탐색 공간 A:
가능한 모든 의 조합을 포함하는 공간입니다.- 목표:
자원 제약 조건 를 만족하면서 검증 성능(validation performance)을 최대화하는 최적의 비트 너비 구성 를 찾는 것입니다.
Exhaustive Search Algorithm (전수 탐색 알고리즘)의 예시:
전수 탐색 알고리즘은 가능한 모든 조합을 만들고, 각 조합에 대해 모델을 양자화하고, 보정(calibration)하고, 성능을 평가하는 과정을 거칩니다.
가능한 비트 너비 조합 계산:
- 각 레이어는 가중치와 활성화에 대해 각각 가지 비트 너비 선택(2, 4, 8비트)을 가집니다.
- 따라서 한 레이어에서 가능한 조합의 수는 가지 입니다. (예: (2,2), (2,4), (2,8), (4,2), (4,4), (4,8), (8,2), (8,4), (8,8))
- 총 3개의 레이어가 있으므로, 전체 아키텍처에 대한 가능한 비트 너비 구성 의 총 수는 가지 입니다.
전수 탐색 과정:
전수 탐색 알고리즘은 이 729가지의 모든 조합에 대해 다음 과정을 수행합니다:
조합 1: (모든 레이어의 가중치와 활성화를 2비트로)
- 모델을 이 구성으로 양자화합니다.
- 양자화된 모델을 보정합니다.
- 검증 데이터셋으로 성능(예: 정확도)을 평가합니다.
- 자원 제약 (예: 모델 크기 5MB 이하, 추론 시간 10ms 이하)를 만족하는지 확인합니다.
조합 2:
- 위와 동일한 과정을 반복합니다.
... (중략) ...
조합 729: (모든 레이어의 가중치와 활성화를 8비트로, 즉 Full-Precision에 가까움)
- 위와 동일한 과정을 반복합니다.
최적 선택:
- 729가지의 모든 조합에 대한 평가가 끝난 후, 자원 제약 를 만족하면서 가장 높은 검증 성능을 보인 를 로 선택합니다.
전수 탐색의 문제점:
이 예시에서는 레이어가 3개에 불과했지만, 실제 ViT 모델은 수십, 수백 개의 레이어를 가집니다. 예를 들어, 레이어가 12개라면 가능한 조합은 가지가 되어 상상할 수 없을 정도로 많은 계산이 필요하게 됩니다. 이러한 이유로 논문에서는 전수 탐색 방법이 "계산적으로 매우 집약적(computationally intensive)"이며 "높은 비용(high cost)"을 요구한다고 지적하는 것입니다.
Mix-QViT는 바로 이 지점에서 각 레이어의 중요도와 민감도를 체계적으로 분석하여, 비효율적인 전수 탐색 없이도 최적에 가까운 비트 너비 구성을 찾으려는 목표를 가지고 있습니다.
Abstract 요약
Mix-QViT가 제안한 2가지 기법1)
LRP를 이용한 Layer Importance, Quantization Sensitivity.
2가지 criteria를 사용한 Explainability-driven MPQ framework2) Post-LayerNorm activation에서 발생하는 extreme outliers의 영향을 줄이기 위한, severe inter-channel variations 제거 기법 Clipped channel-wise quantization
Q2. Layer importance와 Quantization sensitivity가 뭔 차이지?
A2.
Layer LIS Q. Sensitivity 판단 A 높음 낮음 중요하므로 bit-width 확보 필요 B 낮음 높음 민감하므로 bit-width 확보 필요 C 낮음 낮음 bit-width 줄여도 됨 D 높음 높음 최우선으로 bit-width 확보해야 함 bit-width 줄일 순서 : C -> A -> B -> D
1. INTRODUCTION
문제점 1.
PTQ에서 LayerNorm, Softmax, GELU가 quantization에 sensitive해서, performance degradation에 큰 영향을 준다.
=>
- APQ-ViT
Matthew-effect-preserving quantization을 사용하는 block-wise calibration - FQ-ViT
LayerNorm의 channel 간 변화를 처리하기 위해 Power-of-Two Factor를 도입하고,
Softmax layer quantization을 위해, Log-Int-Softmax 사용 - RepQ-ViT 및 AdaLog
calibration 단계에서는
LayerNorm에 channel-wise quantization을 사용하고 ,
Softmax layer의 경우 RepQ-ViT는 밑이 인 log quantization을,
AdaLog는 적응형 밑 log quantization을 사용하여 표현 능력을 향상.
inference 단계에서는 두 프레임워크 모두 LayerNorm에 layer-wise quantization을,
Softmax layer에 log2 quantization를 채택하여 하드웨어 효율적인 형식으로 전환.
=> 여전히 low-bit(e.g. 4-bit)에서는 FP model과 큰 차이 존재
문제점 2.
Uniform bit precision은 suboptimal
=>
MPQ
-
MHSA, MLP module의 sensitivity를 측정하기 위해,
nuclear norm metirc 사용. -
PMQ는 각 layer를 제거했을 때, 유도되는 오류를 평가
-
Hessian based 방법을 통해 중요도 점수를 측정
=> high computational overhead + fail to explain
해결법
2가지 complementary score를 활용한 mixed-precision quantization strategy
- Explainability-based layer importance score
- Quantization sensitivity score
1. Explainability-based layer importance score
이는 LRP(Layer-wise Relevance Propagation)를 사용하여 도출되며, 각 layer가 최종 예측에 얼마나 기여하는지에 대한 interpretable metirc 제공
2. Quantization sensitivity score
이는 각 layer의 성능이 baseline 대비 다른 bit 구성에서 어떻게 변화하는지 포착
=> 이 2가지를 통해, 주어진 제약 조건 下에서 각 layer의 optimal bit-width를 할당하는 Integer Quadratic Problem(IQP)을 공식화
2. METHODS
A. Vision Transformer Architecture
생략
B. Model Quantization
TBW
C. Clipped Channel for LayerNorm Activations
생략
D. Layer Importance Score using LRP
LRP는 gradient와 relevance scores를 사용하여, 각 feature가 model의 output에 미치는 영향을 측정한다.
gradient 구하기
이 forward에서 앞에 layer input이고,
이 뒤에 layer input.
이 network input, 이 output에 해당할 때,
classifier's output 에 대한
번 째 layer의 gradient는 다음과 같다.
당연히, index 는 의 뉴련이고, 는 의 뉴런이다.
relevance scores 구하기
이 forward에서 앞에 layer relevance score이고,
이 뒤에 layer relevance score.
LRP의 relevance propagation은 DTD에 기반한다.
번 째 layer가 input feature map 과 weight 에 대해 수행하는 연산을 라고 하면, relevance 는 다음과 같다.
Transformer block의 activation function이 GeLU와 같이 양수, 음수 모두 만들 경우,
이런 혼합된 값들로 인해 발생할 수 있는 Relevance score의 부정확성을 해결하기 위해, 음수 요소를 제거한, subset
을 사용하여, relevance score를 정의한다.
Q3.
Transformer Interpretability Beyond Attention Visualization의 LRP는 MHSA module 내 attention layer에 대해, [CLS] token의 relevance와 그 gradient 간의 hadamard 곱을 수행하여, relevance score map을 계산한다. 하지만 이 방식은 [CLS] token을 사용하는 architecture에만 적용 가능하다는 제한이 있다.본 연구에서는 [CLS] token 대신 image tokens를 활용함으로써, transformer의 모든 layer에 대한 relevance mapping을 일반화하고, 이를 모든 transformer architecture로 확장한다.
이게 무슨 말이지?
A3.
🔵 1. CLS 기반 relevance 계산이란?
Transformer 구조에서는 보통 [CLS] 토큰이 전체 입력 시퀀스를 대표하는 요약 정보로 사용되어 최종 분류에 활용됩니다.
따라서 많은 LRP 기반 해석 방법들은 다음처럼 relevance를 계산합니다:✔️ 계산 방식
- 모델의 출력 중에서 **관심 있는 클래스 **에 해당하는 값을 선택
- 그 출력에 대한 **relevance **를 초기화:
- relevance를 역전파할 때, 주로 [CLS] 토큰 위치에 집중해서 relevance를 할당하고 해석
✔️ 한계
- [CLS] 토큰만 해석하므로 **입력 이미지의 공간적인 정보(패치 별 중요도)**를 파악하기 어려움
- 모든 정보를 [CLS]가 대표한다고 가정하는데, 이는 일부 모델에서 적절하지 않음 (예: patch-based 모델들)
🟢 2. Image token 기반 relevance 계산이란?
이 논문에서는 [CLS] 토큰 대신, 이미지 패치에 해당하는 토큰들(image tokens)을 기반으로 relevance를 계산합니다.
✔️ 계산 방식
- 각 attention 레이어의 image token들 전체에 대해 relevance 를 계산
- 예를 들어 개의 image token에 대해 형태로 relevance를 유지
- 이 relevance를 통해 어떤 패치(영역)가 분류에 기여했는지를 파악 가능
✔️ 장점
- relevance가 공간 분포를 가지므로, 시각적으로 어떤 패치가 중요했는지 해석 가능
- [CLS] 없이도 모든 transformer 구조에 적용 가능 (예: Swin Transformer처럼 CLS가 없는 구조)
앞서 Relevance score를 구하는 방법을 설명했다.
이제 결과적으로 Mixed-Precision Bit Allocation Strategy에서 쓰일 layer importance score, 에 대해 알아보자.
Layer Importance Score 구하기
는 번째 block 내의 layer 가 model 중요도에서 차지하는 비중을 의미한다.
그 식은 다음과 같다.
: 블록 의 특정 레이어 의 contribution score
: 블록 에 포함된 모든 양자화된 레이어 집합
그니까 은 QKV, MatMul1, MatMul2, Projection, FC1, FC2 이다.
즉, 모든 블록의 모든 레이어의 contribution score의 총합에 대한 현재 블록의 현재 레이어의 contribution score가 Layer Importance Score 이다.
그럼 이제 contribution score에 대해 알아보자.
Contribution Score 구하기
Contribution score 는
ImageNet1k validation dataset에서 개 샘플을 임의로 뽑아,
하나의 샘플에 대한 relevance score map 를 구하고,
그 relevance score map의 원소 전체 평균 구하고,
그걸 전체 샘플에 대해 반복하여, 평균을 얻은 것이다.
그 식은 다음과 같다.
즉, Contribution Score는 하나의 레이어가 여러 샘플에서 얼마나 일관되게 모델 출력에 영향을 미치는지를 나타내는 값으로,
각 샘플에 대해 생성된 relevance score map의 평균 기여도를 다시 평균내어 계산한 값이다.
그럼 이제 relevance score map에 대해 알아보자.
Relevance Score Map 구하기
Relevance Score Map 는
하나의 샘플 t에 대해,
블록 의 특정 레이어 에서의 gradient 와 relevance 의 hadamard 곱을 하여,
attention head 차원에 대한 평균을 내면된다.
그 식은 다음과 같다.
각 요소의 차원에 대하여...
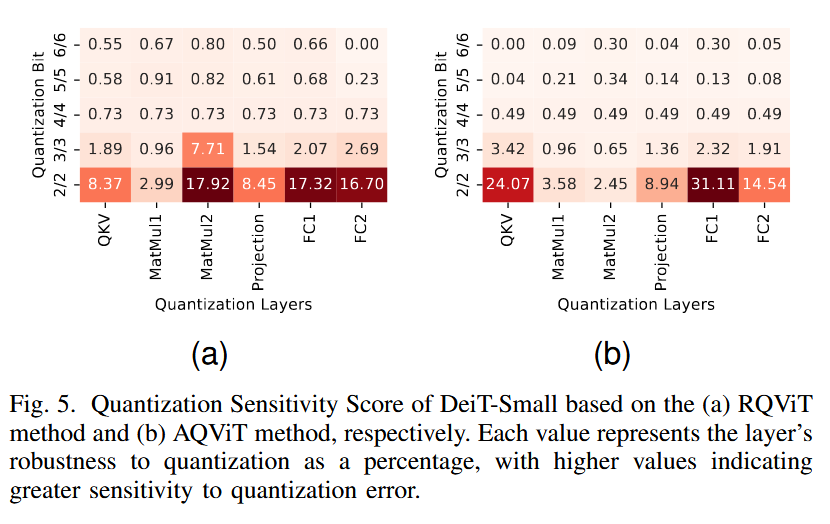
아래 그림은 DeiT-Small의 각 레이어별 Layer Importance Score를 나타낸 것이다.
즉, 출력 분류에 기여하는 정도를 표현한 것이다.

E. Quantization Sensitivity Analysis
PTQ를 사용하여 ViT 내 개별 transformer layer들의 quantization sensitivity를 분석
모든 layer를 동일한 기준 bit(예: 4/4비트)로 설정한 뒤,
특정 layer 하나의 bit만 다양하게 조정(예: 2/2, 3/3, 5/5, 6/6비트)하며 성능 변화를 측정
➡ layer별 quantization sensitivity 측정
그 식은 다음과 같다.
- :
모든 layer가 기준 비트()로 quantization되었을 때의 loss 값 - :
전체는 기준 비트인데, 특정 레이어 T만 다른 비트 폭 로 설정했을 때의 loss - :
음수 값으로 인한 왜곡을 방지하기 위해,
전체 레이어 ()에 대해 관찰된 최소 변화값의 절대값을 더함
아래는 ImageNet-1K validation dataset에서 무작위 256개 image로 DeiT-Small model를 추적한 결과이다.
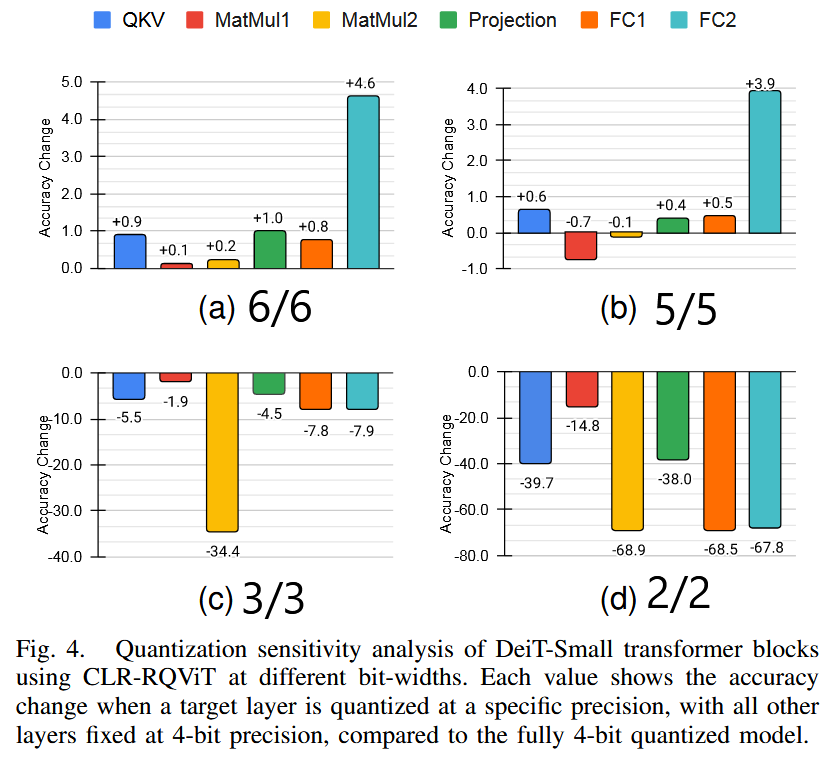
보면,
-
MatMul2 연산의 경우 :
정밀도를 5/5 또는 6/6으로 높였을 때는 성능에 거의 영향을 주지 않았지만,
이를 3/3 이하로 낮췄을 때는 성능이 크게 저하되었다. -
FC2 연산의 경우 :
정밀도를 높이면, 다른 layer 보다 성능 향상이 두드러졌다.
F. Mixed-Precision Bit Allocation Strategy
주어진 레이어 에 대해, weight, activation에 모두 적용 가능한 bit-width 선택지 집합 로부터 다음과 같은 조합이 가능하다.
전체 architecture bit-width 설정은 다음과 같다.
이때, search space 는 가능한 모든 의 조합으로 이루어지는데,
MPQ의 목표는 자원 제약 조건 하에서 검증 성능을 최대화하는 최적의 비트 폭 설정 를 찾는 것이다.
이 과정은 각 후보 S에 대해 quantization, calibration, evaluation이 필요하므로 계산 비용이 매우 크다.
➡ pre-computed indicator를 활용한 mixed-precision bit selection strategy
이며, 는 각 layer의 bit-width 결정이다.
이게 무슨 말이냐면,
-
는
→ 가 **길이 **인 0-1 벡터라는 의미입니다.
→ 즉, 각 원소 -
그런데 그 원소들의 합이 1이어야 하므로,
→ 전체 벡터 중 오직 하나의 위치만 1이고, 나머지는 전부 0인 벡터입니다.
즉, 주어진 조건을 만족하는 는 one-hot 벡터 (one-hot encoding)입니다.
예를들어,
가 (1, 0, 0, 0) 이면 1 bit.
가 (0, 0, 1, 0) 이면 4 bit.
