Hierarchical Reasoning Model
HRM에 대한 내용
Abstract
기존 CoT는 방대한 data 요규량, 높은 latency
⇒
인간의 hierarchical하고, multi-timescale한 처리 과정에서 영감을 받아, HRM
HRM은 한 번의 forward pass로 interdependent한 recurrent module 2개를 씀.
1. High-level module: 느리고, 추상적인 계획
2. Low-level module: 빠르고, 상세한 실행
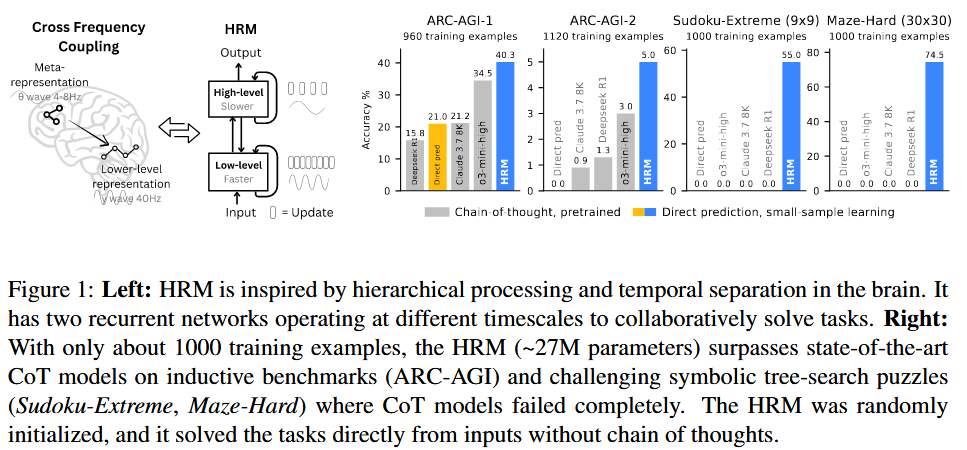
1. Introduction
Reasoning 이 ㅣ필요한 작업에서, model depth를 증가시키면, 성능 ↑
But, 매우 깊더라도, 성능 최적 X
아래 Figure 2에서 볼 수 있듯, Scaling Depth를 늘려도, 109M 정도 부터 saturate됨.
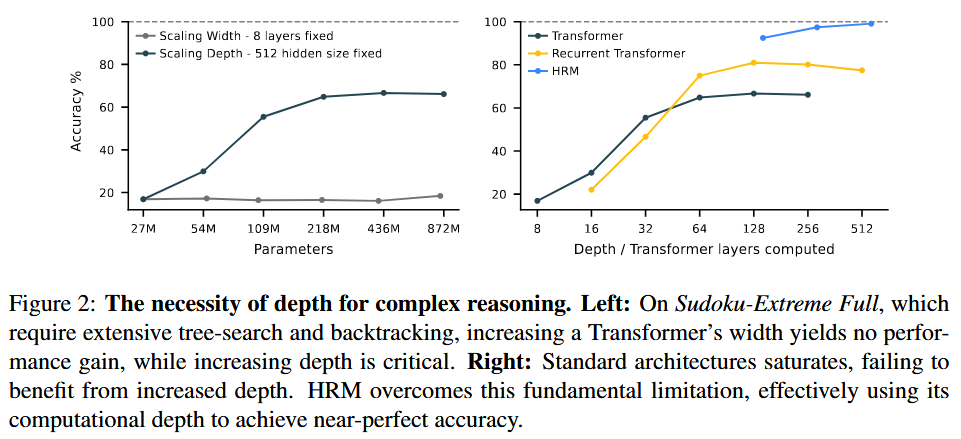
⇒ CoT prompting
CoT prompting: 복잡한 문제를 간단한 중간 언어 단계로 분해하여 순차적으로 해결.
문제점: 단 한 번의 실수로도 전체 추론이 실패할 수 있고, 많은 토큰을 생성하여 느리고 비효율적.
⇒ latent reasoning
Latent reasoning은 언어가 인간 의사소통을 위한 도구일 뿐, 생각 그 자체의 기질(substrate)은 아니라는 이해와 일치.
즉, 마지막에 출력만 언어로 하면 되지, 중간 언어 단계(CoT prompting)는 필요없다는 뜻.
⇒ 단순히 층을 쌓는 것
⇒ vanishing gradient 문제
⇒ Recurrent architectures
⇒ early convergence ⇒ 후속 계산 단계를 비활성(inert) 상태로 만듦 + BPTT⇒ 층 多 + without BPTT
⇒ HRM
- 두 개의 coupled된 recurrent module(H, L module)
- One-step gradient approximation (BPTT 제거)
2. Hierarchical Reasoning Model
Let, input vector , output prediction vector
Learnable component, input network 에 의해, input vectoer 는 가 됨.
Let, time step .
( N: 의 recurrent 횟수,
T: 의 순환 주기 )
H module은 해당 사이클(N번의 recurrent)이 끝날 때의 L module의 최종 상태를 사용하여, 사이클당 한 번만 H의 hidden state 를 update.
전체 번의 사이클(의 time step)이 끝난 후, H module의 hidden state 을 output network 에 넣어, 얻음.
이 과정 한 번이 forward 한 번임.
Hierarchical convergence
표준 RNN의 문제점:
Hidden state가 너무 빨리 고정점(fixed point)으로 수령하여, 후속 계산이 중단되고 NN의 유효 깊이가 제한.
⇒ 계산 능력을 보존하기 위해 hidden state가 매우 느리게 수렴하도록 NN를 설계.
But,
수렴 속도를 억지로 늦추면, 시스템 전체가 불안정해질 위험 有.
⇒
-
H module:
하위 계산 결과()를 통합하여, 전반적인 전략을 지시하고, L module이 새로운 계산을 시작하도록 컨텍스트()를 업데이트. -
L module:
H module이 설정한 컨텍스트() 내에서 '국소 평형'에 도달할 때까지 집중적인 탐색 또는 정제 계산을 수행.
⇒ Early convergence를 방지 + 표준 RNN( 단계)보다 훨씬 깊은 단계의 향상된 유효 깊이를 안정적으로 확보.
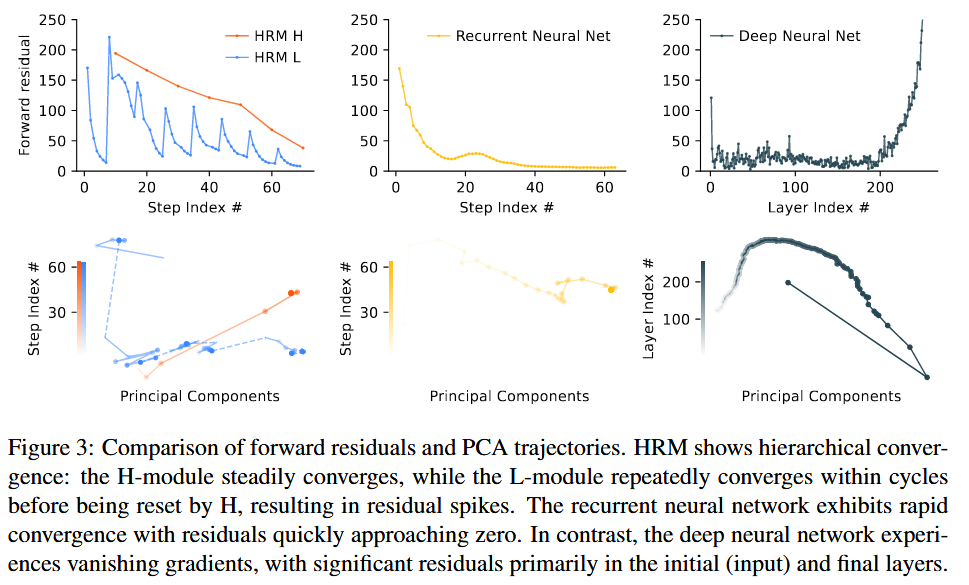
⇒ HRM이 (표준 RNN처럼 활동성이 급격히 감소하는 것과는 대조적으로) 많은 단계에 걸쳐 높은 계산 활동성(forward residual)을 유지하면서도 + 안정적인 수렴을 누릴 수 있음을 보여줌.
Approximate gradient
RNN은 BPTT를 사용.
BPTT는 forward pass에서 얻은 모든 hidden state를 저장했다가, backward pass 중에 gradient와 결합해야함.
⇒ memory 부담 ↑
BPTT 참고자료
만약, RNN이 fixed point로 convergence된다면, 그 equilibrium point에서 단일 단계로 backward해서, BPTT 피할 수 있음(왜?...)
⇒ 즉, 아래 그림의 빨간 포인트들에서 단일 단계 backward할 수 있다는 뜻.
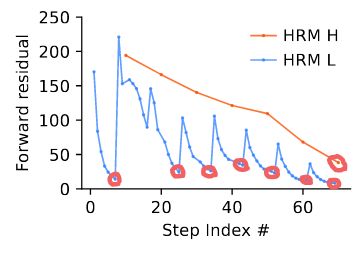
⇒ one-step approximation
⇒ 각 module의 마지막 hidden state의 gradient만 사용하고, 다른 hidden state는 상수 취급
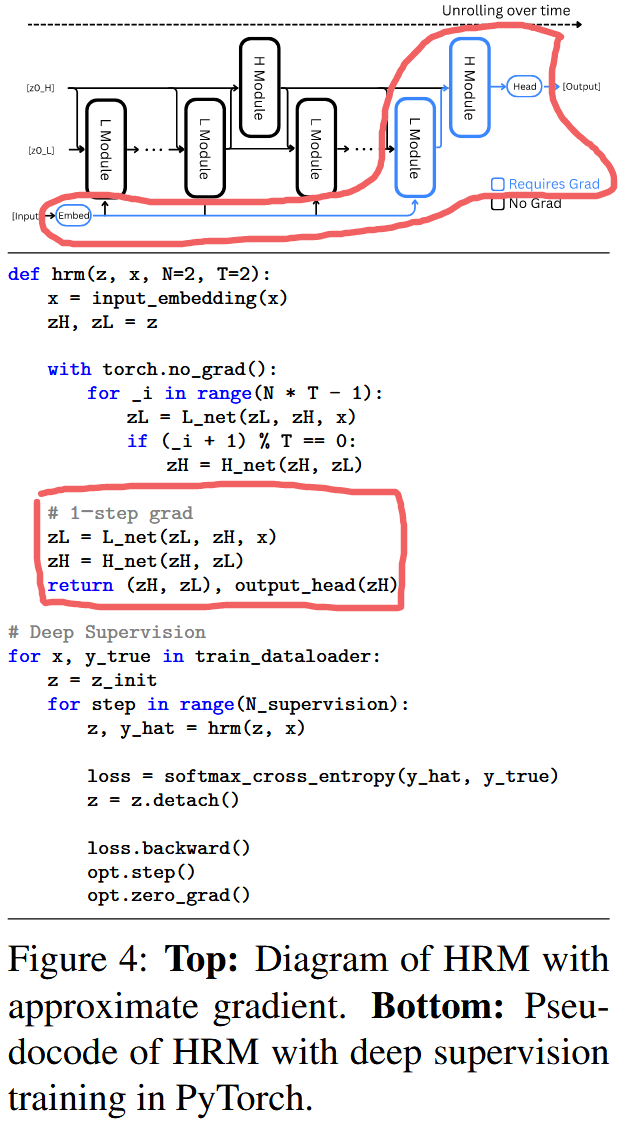
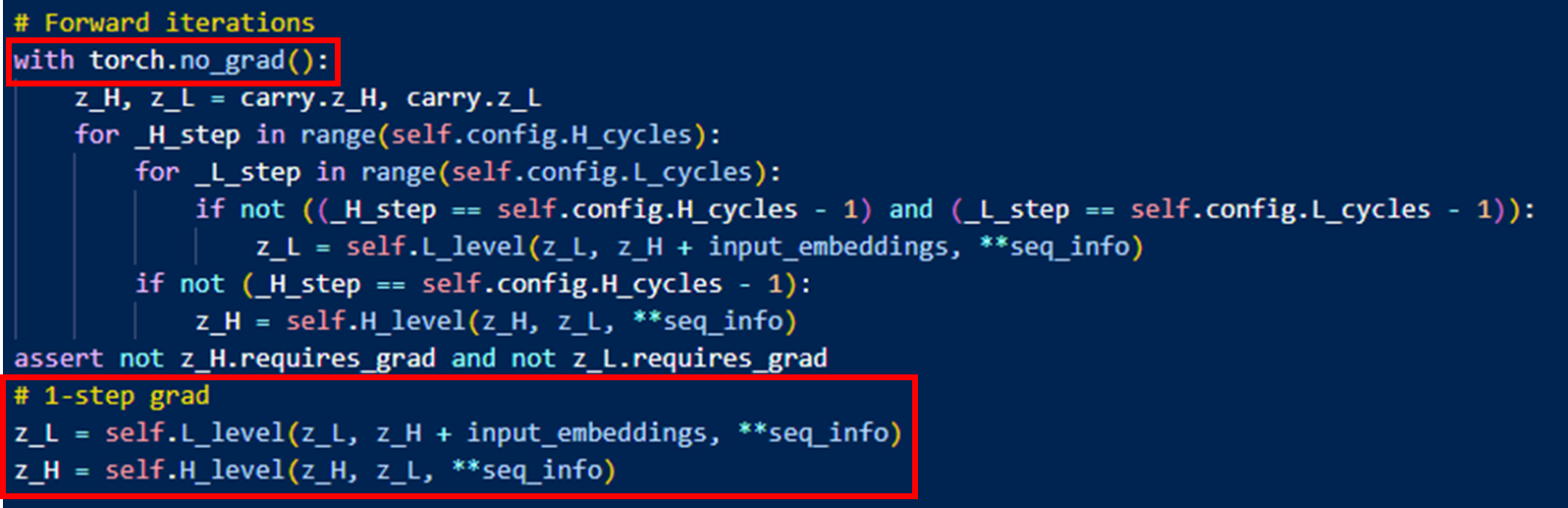
Deep supervision
Let, 한 번의 forward pass를 segment.
총 segment 수를 M이라고 한다면, 각 segment .
Let, segment 에서의 최종 H/L module의 hidden state를 .
⇒
+
Hidden state 을 다음 segment로 넘길 때 계산 그래프에서 '분리(detach)'하여, gradient가 이전 segment로 backpropagation되지 않도록 차단!!!
⇒ H module에 더 빈번한 피드백을 제공 + 메모리 부담 X
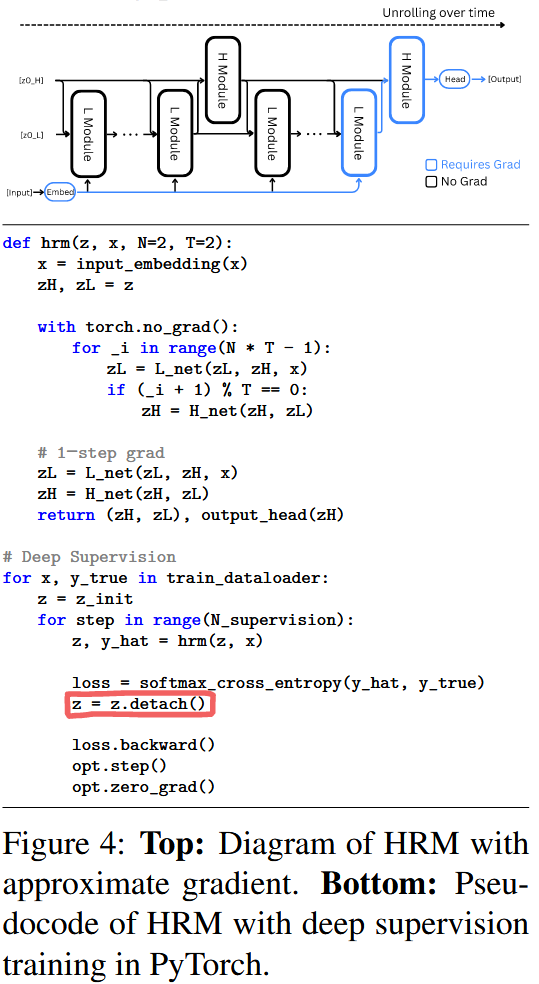
'Approximate gradient' vs. 'Deep supervision'
-
근사 기울기 (Approximate Gradient): detach로 인해 과거의 계산 기록이 의도적으로 잘린 상태에서, 각 지도 단계(step)마다 계산되는 기울기 값.
-
심층 지도 (Deep Supervision): detach로 계산 그래프를 분리하며 (순전파 → 손실 계산 → 역전파) 과정을 n_supervision번 반복하는 전체 훈련 기법.
Adaptive computational time (ACT)
뇌는 과제 복잡성과 잠재적 보상에 따라 학습 시간을 동적으로 조절함.
⇒ Training 中에만 adaptive halting strategy를 HRM에 통합.
⇒ 학습 中 segment 수를 동적으로 조절.
Q-head를 통해, H module의 최종 상태()를 사용하여, halt, continue 행동의 Q-value를 예측.
if ((m ≥ ) or (( > ) and ()))
⇒ halt
cf) : 고정 하이퍼 파라미터, : 확률적으로 랜덤하게 1 ~ 에서 선택.
⇒ Q-value를 통해, halt 여부 결정
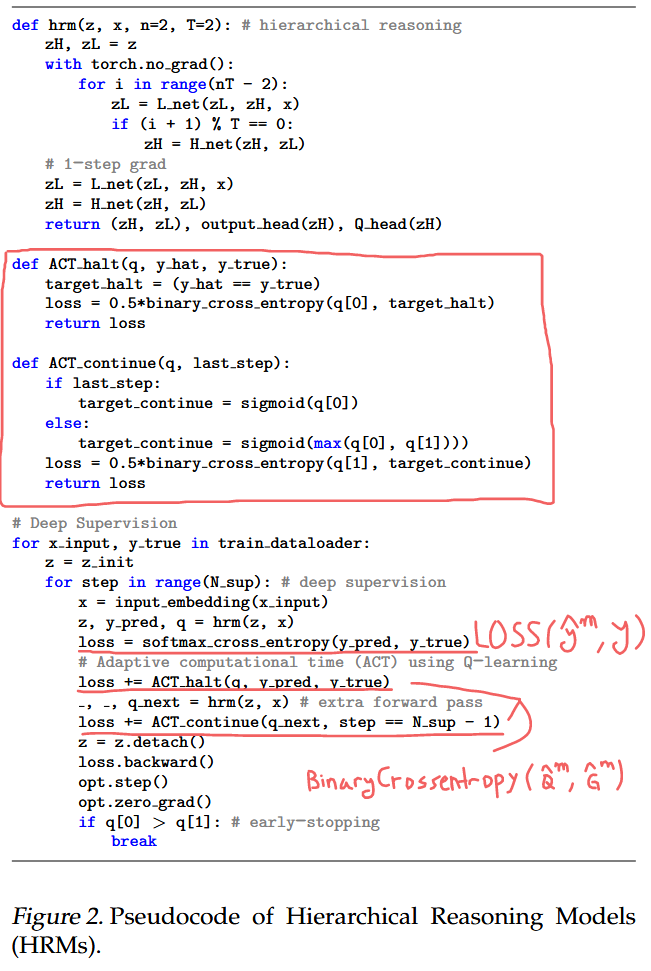
Q-head update 과정
: "halt" action을 선택했을 때의 보상이고,
: "continue" action을 선택했을 때의 미래의 보상임
: "action"에 대한 loss
⇒ 예측()이 실제 목표()와 비슷해 지도록 함!!!
전체
cf) 이때, halt action을 했다고 해서, 배치의 모든 샘플이 새로운 샘플로 대체 X ⇒ 해당 샘플만 대체 O
