SpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting
SpecEE에 대한 내용
Abstract
Early Exiting(EE)는 최근 하드웨어 연산량과 메모리 접근을 효과적으로 줄임으로써 LLM의 inference 속도를 높이는 유망한 기법으로 주목받고 있다.
Q1. EE란?
A1. 모델이 모든 레이어를 거치지 않고, 중간에서 추론을 종료하는 방식
논문에서 제시하는 문제점 :
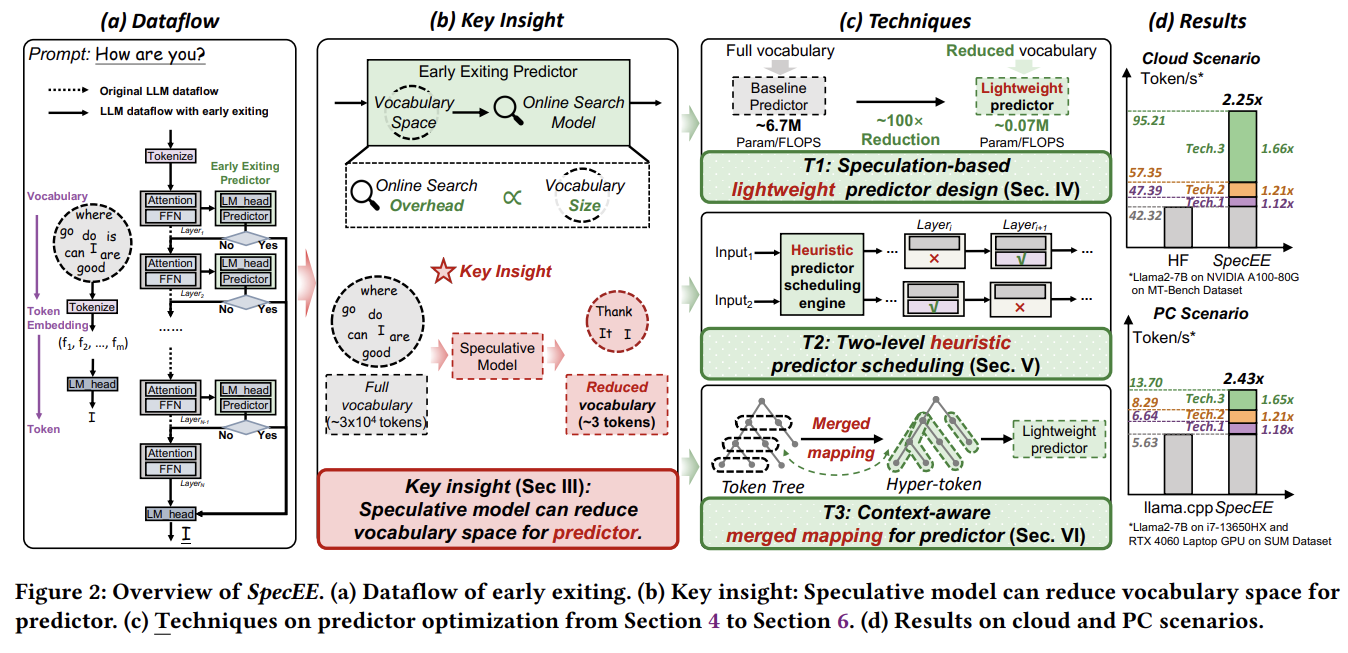
LLM의 vocabulary가 EE predictor의 runtime search space로 작동하며, predictor workload에 큰 영향을 미친다.
(e.g., Llama2에서 약 30,000 단어 크기의 vocabulary를 search 하는 데 전체 inferecne 지연 시간의 20% 차지)
구체적으로 다음 세 가지 문제 해결.
1. 높은 계산 복잡도의 predictor
기존 predictor의 경우, vocabulary size 전체가 search space이다. => 문제점
2. 계층별 예측기 배치의 비효율적 활용
3. speculative decoding에서의 예측기 매핑 복잡도의 기하급수적 증가
1. Introduction
LLM inference 속도를 높이고, deployment cost를 줄이기 위한 연구들이 다수 진행되어 왔다.
이들 중 일부 연구(fast decoding)는 결과의 일관성을 유지하지만, 다른 연구들(pruning, quantization)은 정확도 손실을 초래할 수 있어, Figure 1(a)와 같이 LLM inference 및 deployment에서 정확도와 속도 향상 간의 pareto frontier를 형성한다.
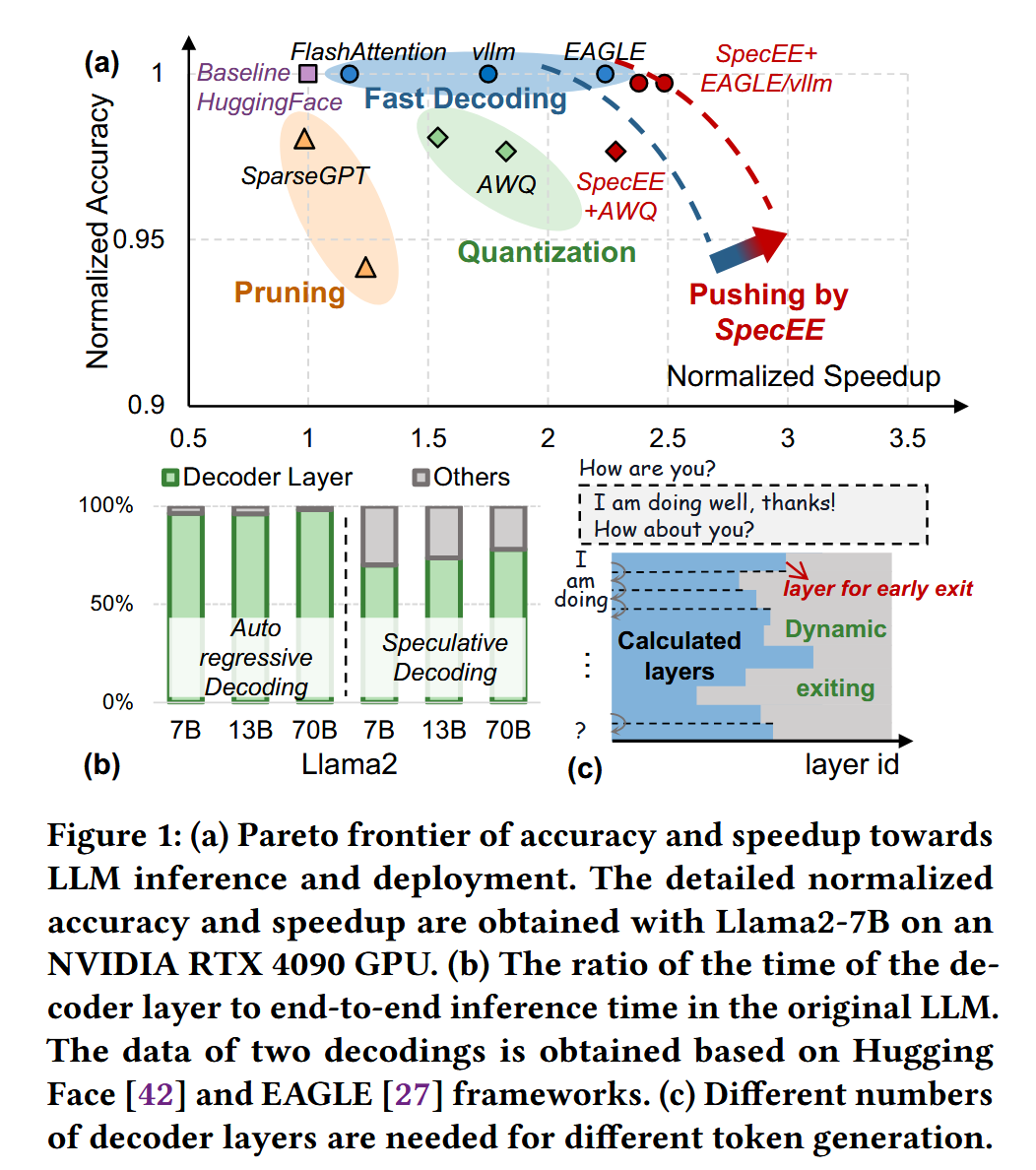
더 속도 향상을 하기 위해서 Early Exiting(EE)와 같은 기법이 있다. 이는 LLM inference에서 일련의 decoder layer를 전체 다 사용하는 것이 아니라, 동적으로 조정하여, 부분 사용하는 것이다.
이런 방법이 속도 향상을 이루는 이유는 Figure 1(b)에서 보듯이 decoder layer가 LLM inference에서 대부분의 시간을 쓰기 때문이다.
EE의 신뢰성은 Figure 1(c)에서 보듯이 token 생성 시 각 token마다 필요한 decoder layer가 다름에서 얻을 수 있다.
+ 또한 EE는 파라미터를 조정하지 않으므로, 일반성에서도 좋다.
EE 구조
물론입니다. 아래는 말씀하신 내용을 포함해 AdaInfer의 Early Exit 구조를 구체적이고 체계적으로 정리한 설명입니다. 각 단계는 연산 방식, 입력 차원, 분류기 학습 방식까지 포괄합니다.
🔍 AdaInfer의 Early Exit 구조 (차원・학습 방식 포함한 상세 설명)
Logits 기반 Feature 추출 및 차원 축소
각 디코더 레이어에서 마지막 토큰의 hidden state (예: )를 LM Head 와 곱해 logit 계산 후, softmax를 통해 확률 분포 를 생성한다.
이 확률 분포에서 다음 두 가지 scalar 통계치를 추출하여 feature vector 를 구성:
gap: 상위 두 토큰 확률 차이 →top prob: 가장 높은 확률값 →이진 분류기 학습을 위한 데이터 구성
각 레이어에서 생성한 feature vector 에 대해 정답 레이블 을 다음 기준으로 부여:
- 해당 레이어에서 예측한 토큰 가 최종 레이어에서 예측한 토큰 와 동일하면 → label
- 다르면 → label
수식:즉, L개의 레이어가 있는 LLM에 대해 하나의 입력 는 총 L개의 (feature, label) 쌍 을 생성하게 된다.
통계적 이진 분류기 학습 (SVM, CRF)
- SVM: 각 레이어에서 독립적으로 분류. 입력 만으로 “Exit 여부”를 판단.
- CRF: 디코더 레이어 전체를 시퀀스로 보고, 레이어 간 문맥 의존성(e.g., 점진적 확신 증가)을 학습하여 더 정교한 exit 타이밍 예측 가능.
추론 시 Early Exit 실행
추론 중 각 디코더 레이어에서 feature vector 를 추출 → 학습된 분류기에 입력 → 출력이 1이면 해당 레이어에서 inference 중단 후 LM Head로 최종 토큰 예측 수행.
- 이때 사용되는 logit 계산은 마지막 토큰 하나에 한정되므로 전체 시퀀스 길이에 비해 연산량은 매우 작음 (논문 기준: 전체 FLOPs의 0.03% 수준).
효율성과 확장성
- feature vector가 2차원이므로, 분류기의 파라미터 수 및 연산량은 매우 작고 빠름.
- 분류기는 task-independent하게 학습되므로 다양한 LLM에 generalize 가능.
- Llama2, OPT 등 다양한 LLM에서 평균 17.8%의 레이어 pruning, sentiment task에서는 최대 43% pruning을 성능 저하 없이 달성함.
📌 요약 포인트
- 입력 차원:
- 레이블 조건:
- 분류기 종류: SVM (독립적), CRF (시퀀스 모델링)
- 학습 데이터 수: 입력 하나당 개의 훈련 샘플 생성
- 효율성: logit 연산은 마지막 토큰만 사용하므로 미미한 오버헤드
🔁 기본 LLM 추론 흐름
LLM은 한 번에 토큰 하나만 생성합니다.하나의 토큰을 생성하려면 입력 토큰 시퀀스를 받아서,
디코더 블록 전체(L개 레이어) 를 순차적으로 통과해야 합니다.마지막 레이어까지 도달한 후 LM Head를 통해 확률 분포 → 다음 토큰 선택
→ 이 과정을 반복하여 시퀀스를 생성합니다.즉,
“하나의 토큰 생성을 위해 디코더 전체를 1회 통과”
🚀 AdaInfer는 이 중간을 “스마트하게 잘라내는” 구조
디코더 블록을 통과하면서 매 레이어에서 EE predictor가 판단:“지금 레이어까지만 계산해도, 예측이 충분히 확신 있어 보여?”
그렇다면 해당 레이어에서 멈추고, 그 상태로 다음 토큰을 확정합니다.
그리고 다음 토큰 생성을 위해 다시 디코더 블록을 layer 1부터 시작합니다.
문제점
=>
LLM vocabulary가 EE predictor의 online search space(LLM에서 가중치를 가진 linear 연산, 즉 LM Head)로 작동하여, 연산량에 상당한 영향을 미침
해결책
=>
Speculative token 생성을 통해 predictor의 search space를 배 축소
3가지 Challenge
Challenge-1: Time-consuming predictor with high design complexity
기존 LLM EE predictor는 예측 전에 full search space(완전한 LM Head와 곱해지는)을 순회해야 하며, 이후 고차원 원시 데이터(4,000차원 초과)를 특성 분석이나 추출 없이 그대로 예측 입력으로 사용한다.
이러한 고차원 입력을 처리하기 위해 예측기는 AdaInfer의 SVM과 같은 기본 모델을 사용하며, GPU 병렬성을 고려하지 않아 전체 연산의 약 30%, 전체 추론 지연의 약 15%를 차지하게 된다.
Challenge-2: Under-utilization of layer-wise predictor deployment
기존 LLM EE system에서 predictor를 모든 decoder layer뒤에 삽입한다.
하지만 통계적으로 예측 성공의 확률은 skewed distribution을 따른다.
=> 대부분의 토큰이 특정 소수의 레이어에서만 EE 된다.
=> 대부분의 predictor 계산이 불필요.
Challenge-3: Exponential mapping complexity of predictor in speculative decoding.
Speculative decoding은 트리 기반의 토큰 구조를 통해, 초안 생성과 토큰 검증을 수행하는 방식으로, autoregressive decoding의 낮은 throughput 문제를 해결하고자했다.
Speculative decoding?
LLM inference throughput을 높이기 위한 기법으로,
1. Lightweight Draft Model이 main LLM 대신 먼저 K개의 토큰을 "추측"하여 생성(빠름)
2. Main LLM이 해당 K개의 토큰이 실제로 나올 수 있는지 검증
- 정확하면 -> 그대로 채택
- 틀리면 -> 일부 교체, 다시 생성
위에서 트리 기반이라고 한것은 첫 speculative token을 K개를 생성 그 다음 speculative token은 개, 그 다음은 개 ... 여서.
하지만 speculative decoder에서의 EE mapping은 각 토큰을 문맥적 의미 고려 없이 predictor의 독립적인 탐색 공간으로 취급하여, 매핑 복잡도가 기하급수적으로 증가하고, 높은 throughput의 이점을 활용 X.
speculative decoder에서의 EE mapping은 다음을 의미
📌 목적
Speculative Decoding 중에 나온 여러 후보 토큰(트리 구조)을 어느 레이어에서 종료할 수 있을지(Predictor의 exit 판단) 매핑하는 과정.⚠️ 기존 방식의 문제
각 후보 토큰을 독립적으로 매핑함 (e.g., Tree 내 각 노드를 개별적인 입력으로 처리)토큰 간 문맥/의미적 연관성을 고려하지 않음
결과적으로 Token 수가 늘면 Predictor search space도 지수적으로 늘어남
3가지 해결방법 요약
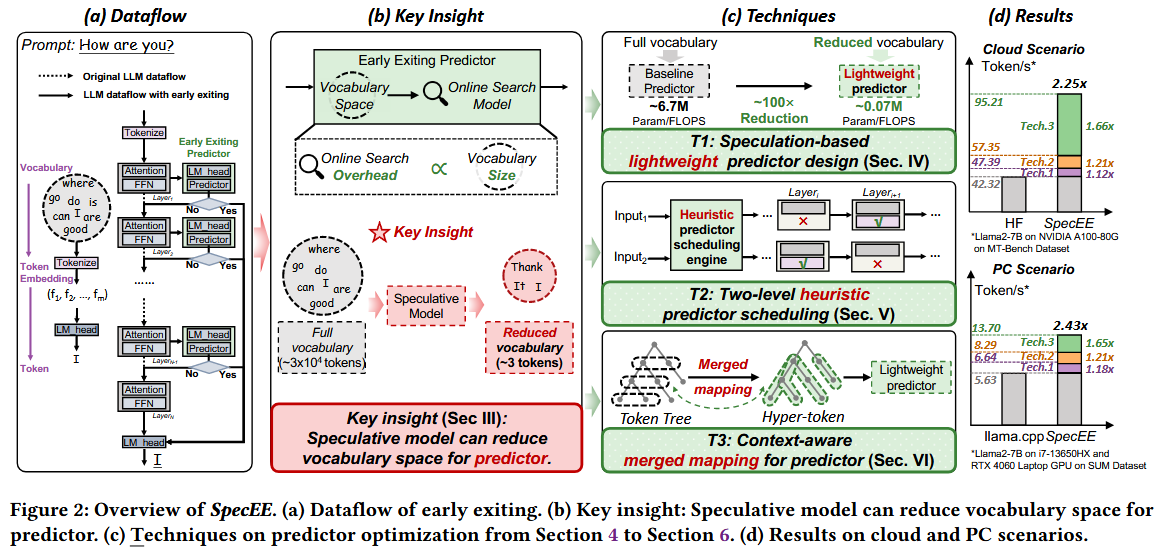
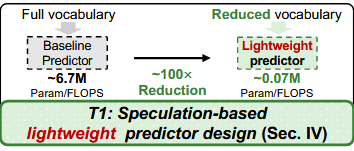
(1) Speculation-based lightweight predictor design at the algorithm level.
speculative 토큰의 확률 변화가 정답 여부와 강하게 상관되어 있다.
=> 이를 예측 특징으로 활용할 수 있는 여러 의미 있는 지표들을 추출한다.
+
GPU의 병렬성을 최대한 활용하기 위해, 우리는 예측기로 경량 MLP를 채택
(2) Two-level heuristic predictor scheduling at the system level.
추론 중 예측기의 통합 및 계산을 휴리스틱하게 제어하기 위해 오프라인 및 온라인 스케줄링을 포함하는 2단계 휴리스틱 예측기 스케줄링 기법
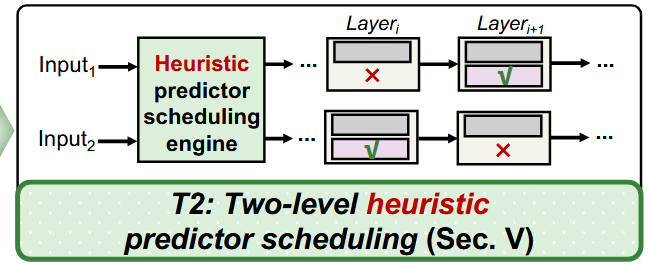
오프라인 스케줄링은 광범위한 통계 분석을 통해 얻은 skewed distribution을 기반으로 예측기를 할당한다.
온라인 스케줄링은 실행 시간 중에 수행되며, exit 레이어 위치의 context similarity에 기반한다. 즉, 현재 토큰의 exit 레이어가 이전 다섯 개 토큰의 exit 레이어로부터 ±2 레이어 이내에 있을 확률은 70%를 초과한다.
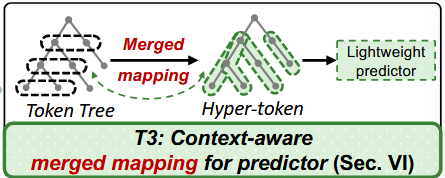
(3) Context-aware merged mapping for predictors at the mapping level.
매핑 수준에서의 문맥 인식 기반 예측기 병합 매핑. 기법 (2)에서 언급한 종료 레이어 위치 간 문맥 유사성에 기반하여, 우리는 이러한 특성이 트리 기반 speculative decoding에도 적용된다는 점을 지적한다. 이는 입력 토큰 트리 간에도 문맥적 의존성이 존재함을 의미한다.
이에 따라 speculative decoding을 지원하는 효율적인 GPU 구현 기반의 문맥 인식 기반 예측기 병합 매핑을 제안하며, 트리 기반 토큰의 각 경로를 하나의 하이퍼 토큰으로 병합함으로써 기하급수적 매핑 복잡도를 선형 복잡도로 전환
전체 SpecEE 구조
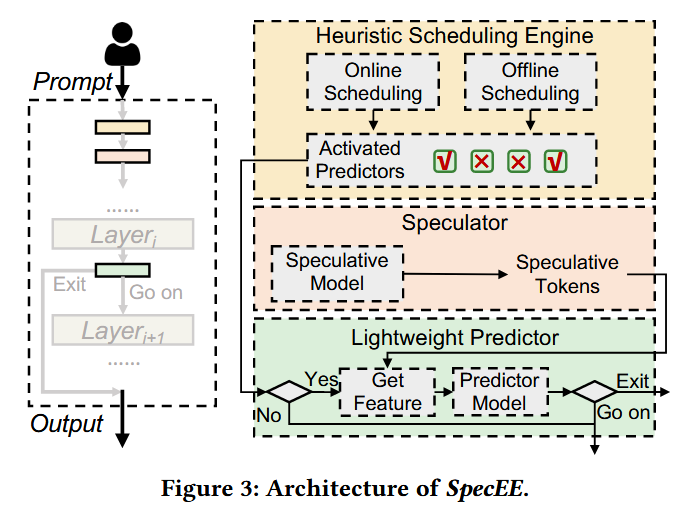
1. 입력 프롬프트를 받은 후, 오프라인 및 온라인 스케줄링 메커니즘으로 구성된 휴리스틱 스케줄링 엔진이 활성화가 필요한 예측기를 식별한다.
2. speculative 모델이 호출되어 speculative 토큰을 생성한다.
3. 연속된 디코더 레이어 쌍 사이마다, 예측기를 활성화해야 하는 경우에는 특징(feature)을 추출하고, 예측기 모델을 활용하여 추론을 계속 진행할지 종료할지를 판단한다.
위 1, 2, 3을 시퀀스 끝까지 반복
2. Background
생략
3. Motivation
3.1 Key Challenges of Early Exiting
vocabulary size가 크면 클수록, predictor가 순회해야하는 search space가 크다.
=> 어휘 공간을 줄여, online token prediction을 효과적으로 수행.
3.2 Key Insight
컴퓨터 시스템 설계에서의 추론(speculation) 개념과 2.2절에서 다룬 speculative decoding에서 영감을 받아, 우리는 speculative decoding에서 DLM(Draft LLM)의 역할이 TLM(Original LLM)을 위한 speculative 토큰을 생성하는 것이라 본다.
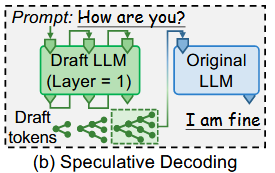
TLM의 관점에서 볼 때, DLM의 출력은 실제로 항상 정답이 아닐 수는 있으나, 토큰 선택 범위(즉, 탐색 공간)를 좁히는 잠재적인 수단을 제공한다.
=> DLM을 학습시키는 목적은 TLM의 결과가 가능한 한 이 speculative 토큰들과 잘 일치하도록 만드는 데 있다.
=> 즉, 충분히 성능이 좋은 DLM을 사용한다면, TLM의 결과를 speculative 토큰이 포함된 좁은 공간(그림 2(a)에서 언급된 유효한 소규모 공간)으로 완전히 제한할 수 있다.
=> DLM이 충분히 강력하면, TLM이 굳이 모든 디코더 레이어를 사용하지 않아도 되고, 결과는 speculative token 내부에서 결정되므로 search space가 작아진다
4 Speculation-based Lightweight Predictor
4.1 Motivation: Time-consuming Predictor
Speculative 모델이 줄여주는 건 “TLM의 토큰 후보군”,
하지만 EE Predictor가 쓰는 feature는 여전히 “디코더 내부의 고차원 hidden state” 이기 때문에,
search space가 줄었다고 해서 predictor의 연산량이 자동으로 줄지는 않는다.
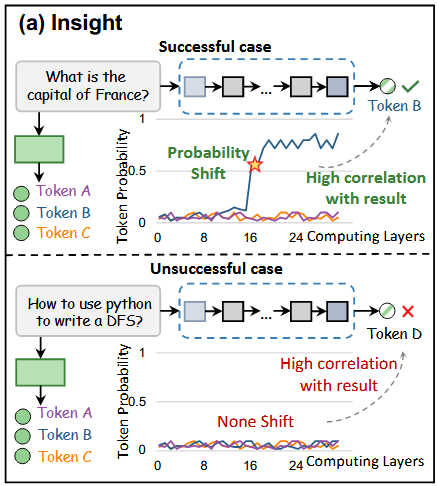
4.2 Insight: Probability Shift
- (아래의 위 그림) 최종 출력이 축소된 search space에 존재하는 경우, 해당 토큰의 확률은 특정 레이어에서 급격히 상승하고, 반면, 다른 토큰들의 확률은 낮은 수준에서 안정적으로 유지.
=> EE를 했어야 되는 상황에서 EE를 하게 해줌 - (아래의 아래 그림) 최종 출력이 축소된 search space에 없는 경우,
모든 토큰의 확률은 낮은 값에서 안정적으로 유지.
=> EE를 안했어야 되는 상황에서 EE를 안하게 해줌
4.3 Approach: Lightweight Design
위의 motivation, insight를 통해, speculation-based lightweight predictor 설계.
이는
- feature selection
- judgment mechanism
- correction algorithm
단계로 이루어짐.
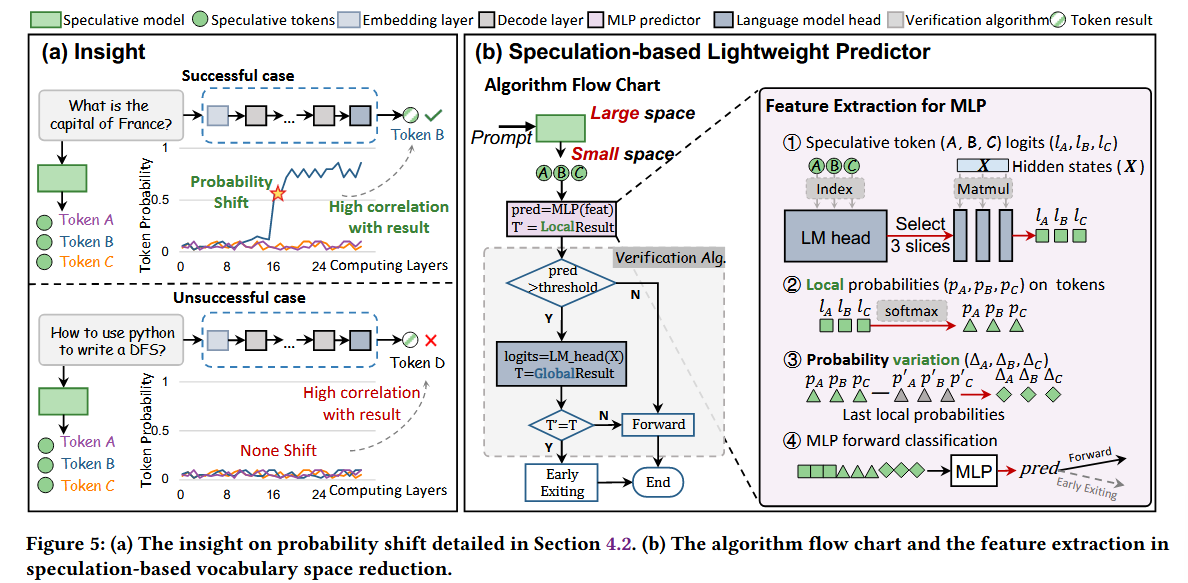
4.3.1 Feature selection
Predictor가 사용할 feature는 다음과 같다.
(1) Speculative token logits
각 레이어의 출력(hidden_states)과 speculative 토큰에 해당하는 lm_head의 컬럼 간의 행렬 곱(1 × hidden_dim × num_speculatives) 의 결과로,
LLM이 해당 speculative token에 대해 얼마나 확신을 가지는 지 직관적으로 반영.
(2) Local probabilities
speculative token logits에 softmax 한 것
(3) Probability variation
현재 레이어와 이전 레이어 간의 local probabilities의 차이로, 레이어를 지남에 따라 확률이 어떻게 달라지는지 포착
=> 양수이면, 해당 토큰에 더 확신이 생기고 있는 거임
| 상황 | variation 의미 | EE 판단 |
|---|---|---|
| + 값 (증가) | 확률이 커짐 → 확신이 강화됨 | Exit 가능성 ↑ |
| 0 또는 매우 작음 | 변화 없음 → 이미 안정적 | Exit 가능성 ↑ |
| − 값 (감소) | 확률이 떨어짐 → 불확실성 증가 | Exit 보류 (Proceed) |
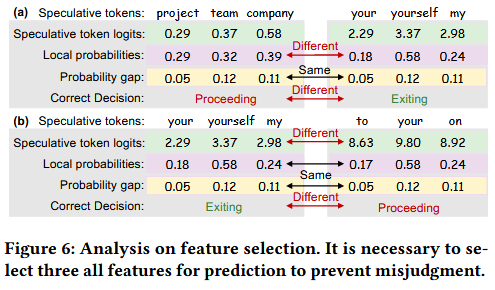
보면, (a)에서 team의 probability gap을 보면 0.12, yourself 또한 0.12이다. 그러나, local probabilites를 보면, yourself가 더 높다. 즉, yourself가 exiting 확률이 더 높아야한다.
=> probability gap과 local probabilities를 같이 사용
+ (b)에서 yourself와 your는 local probabilities는 0.58로 같지만, speculative token logits는 your가 9.80으로 더 크다.
이럴때, 같은 local probability일 때, logit 값이 더 작다
=> 상대적 우세 => yourself가 exiting 확률이 높음
=> (b)에서 왼쪽 case의 후보들 (your, yourself, my)이 마지막 layer의 lm head로 가서 최종 토큰 생성!
4.3.2 Judment mechanism
앞서 언급된 특징들을 기반으로, speculative 모델은 매번 4개의 speculative 토큰을 생성하도록 구성되며,
이에 따라 총 특징 차원은 12개(4 × 3)가 된다.
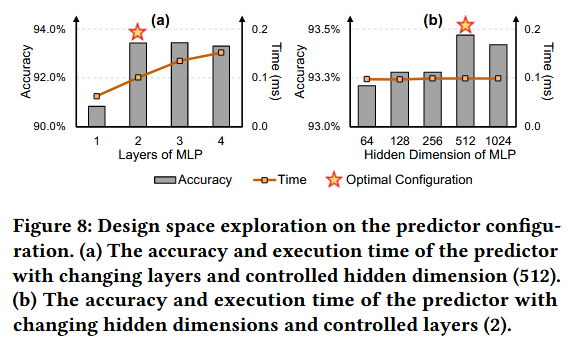
GPU의 Tensor Core가 제공하는 높은 연산 성능을 최대한 활용하기 위해, 우리는 기존의 머신러닝 방식(SVM 등) 대신 은닉 차원이 512인 2-레이어 MLP를 예측기로 채택하였다.
이 예측기는 ReLU 활성 함수를 사용하고, 이진 분류 작업을 처리하기 위해 출력층에 Sigmoid 함수를 설정한다.
입력된 특징은 예측기로 전달되며, 예측기의 출력이 사전 정의된 임계값(예: 0.5)과 비교되어 exiting 여부가 결정된다.
4.3.3 Verification algorithm
위에 Judgment mechanism에 추가로 Verificator를 장착하여, 안전장치를 하나 추가했다.
verificator는 pred가 threshold 보다 클 경우,
Global LM Head를 통해(Hidden state * vocalbulary) global token logits를 계산하고, 제일 높은 확률을 가진 global token이 speculative 목록에 있다면, 해당 토큰을 출력하고, 추론을 종료한다.
// 여기서 말하는 speculative 목록은
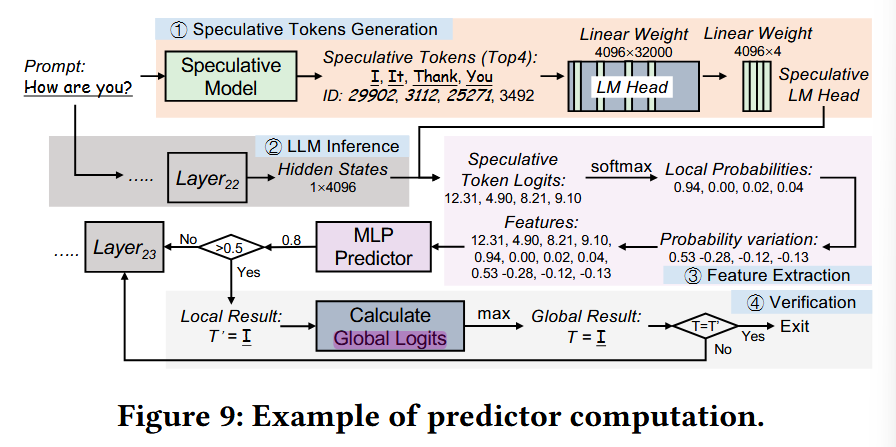
Q. 근데 그러면, speculative 방식을 써서 LM Head의 search space를 극단적으로 줄이는 방법이 의미가 없지 않나? 결국 verificator에서 global logits을 계산하니까
A. ㄴㄴ. 애초에 MLP Predictor를 통해 나온 pred 값이 threshold 보다 높을 결우가 드물게 일어남. (당연하지, 보통 exit 직전에 일어나겠지...) 그래서 global logits을 계산하는 횟수 자체가 줄어듦. 이전 방식 (AdaInfer)는 모든 레이어에서 exit predictor를 수행하는데, 그때마다 full LM Head를 사용했었음.
4.4. Evaluation
생략
5. Two-level Heuristic Scheduling Engine
5.1 Motivation
7.5 Ablation study에서 Llama2-7B를 사용했을 때, end-to-end inference speedup이 15% 밖에 안됨.
=> 그럼에도 평균 실행 layer 수는 23개, 이는 이론적으로 약 33%(32/(23+1))이 가능함을 시사
=> 어딘가 문제가 있음
문제의 원인을 찾기위해, speculative model의 overhead를 생각해보면, 대략 decoder layer 한 개의 실행 시간.
=> 전체적인 inference speed를 저하시키는 원인은 predictor overhead
predictor overhead는 이다.
이때, 단일 predictor 실행 시간은 다음 실험을 통해, 최적으로 구성하였기에
=> 레이어 수를 줄여야됨
또한 Figure 10(a)(c)에서 나타난 바와 같이, 종료 확률이 하위 50%에 해당하는 레이어들(가로 점선 아래)의 확률 합은 20%를 넘지 않으며, 이는 해당 레이어들에서의 예측이 대부분 불필요함을 시사한다.
종료 확률이 낮은데 예측을 하고 있는 상황
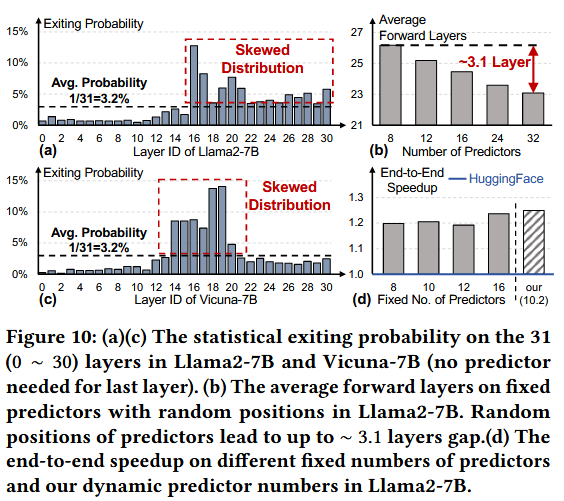
Figure 10(b)에서 32레이어 쓸 때 보다, 8레이어 쓸 때, average forward layers 가 3.1 증가한다고 한다.
=> predictor가 너무 적어, 적절한 시점에 종료 실패해서...
=> end-to-end inference acceleration을 위해서는 적절한 predictor 수와 위치를 제어해야 한다.
5.2 Insights and Analysis: Skewed Distribution and Context Similarity
LLM inference 과정에서 model 선택과, 문맥 입력이라는 두 변수에 따라 예측기의 수와 위치를 동적으로 조정해야 한다.
Skewed Distribution
Figure 10(a)(c)에서 보여주는 예측기 결과 분포를 보면, 모델에 따라 편향의 정도가 다름을 알 수 있다.
Context Similarity
현재 토큰의 종료 레이어와 상관관계가 있는 레이어가 있나?에서 출발하여, 직전 N개의 토큰의 종료 레이어와의 관계에 주목.
통계 결과에 따르면, 현재 토큰의 종료 레이어는 이전 5개의 토큰의 종료 레이어로부터 ±2 레이어 이내에 위치할 확률이 약 80%에 달한다.
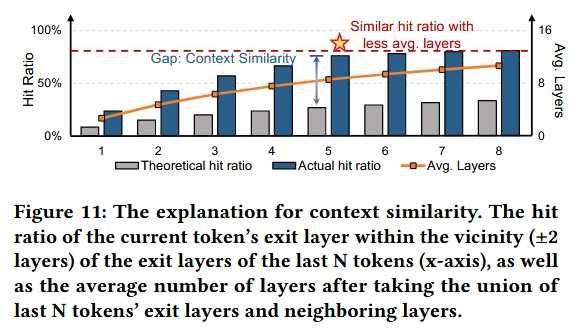
그래프 예시
가정
N(x-axis)이 3,
현재 7번 째 token 종료 layer 10.N이 3이므로,
이전 3개 layer를 보자6번 째 token: 8에서 EE → {6, 7, 8, 9, 10}
5번 째 token: 8에서 EE → {6, 7, 8, 9, 10}
4번 째 token: 10에서 EE → {8, 9, 10, 11, 12}→ 수집된 exit layer = {6, 7, 8, 9, 10, 11, 12} (중복 제거)
이 수집된 exit layer set에 현재 종료 layer(10)가 포함될 확률이 (y-axis)
Figure 11에 따르면,
N이 5일 때, 수집된 exit layer set에 현재 종료 layer가 포함될 할 확률이 80%
만약 이런 수집된 exit 레이어와 현재 토큰의 종료 레이어가 상관관계가 없다면,
실제 현재 토큰의 종료 레이어가 수집된 exit 레이어에 들어갈 확률은 이다.
// 위의 그래프 예시임
하지만 실제 현재 토큰의 종료 레이어가 수집된 exit 레이어에 들어갈 확률이 0.8이므로 이 둘은 상관관계가 있다고 볼 수 있다.
=> exit 레이어의 위치는 뚜렷한 context similarity가 존재한다.
Q. 왜 이전 5 토큰을 기준으로 exit layer를 수집하나?
A.
참고하는 과거 토큰이 많으면 많을수록, 수집된 exit 레이어의 수 많아짐. => predictor 많아짐!!! => 연산 多
참고하는 과거 토큰이 적으면 적을수록, hit ratio가 확 떨어짐.=> 연산이 적으면서도 hit ratio가 높은, trade-off 지점이 과거 5개의 토큰을 보는 거임
5.3 Approach: Two-level Heuristic Scheduling
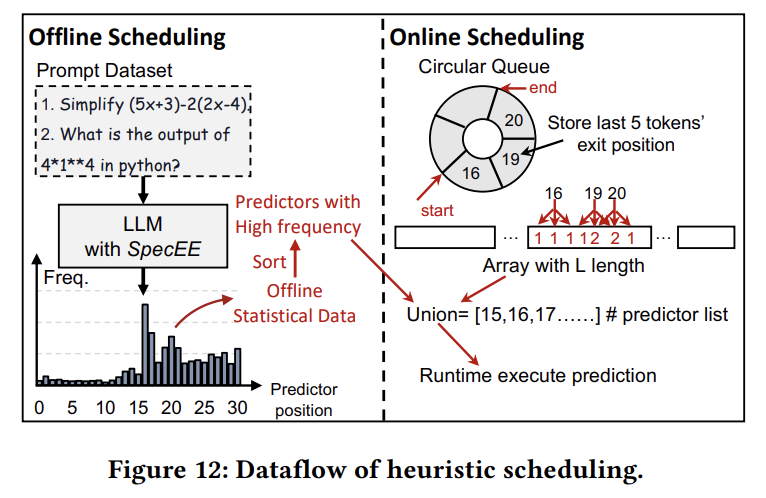
위의 Figure 12에서 보이듯 offline scheduling과 online scheduling 두 부분으로 구성된다.
Offline Scheduling
서로 다른 LLM에 대한 데이터를 사전에 수집하여 사용.
수많은 프롬프트를 이용하여 모든 predictor가 완전히 통합된 상태로 LLM inference를 수행한뒤, 각 predictor에서 수집된 데이터를 기반으로 predictor의 사용 빈도를 순위화한다.
이 결과는 모델 구성 파라미터로 통합되며, 이는 LLM마다 달라지며 한 번만 오프라인으로 수행하면 된다.
Online Scheduling
앞서 언급했듯 context similarity에 기반하기 위해, 최근 N 토큰을 기준으로 exit 레이어를 수집했다.
이때 N이 circular queue의 길이가 된다.
또한, 전체 레이어 수 L에 해당하는 길이의 배열도 사용한다.
circular queue는 최근 N개의 토큰에 대한 exit layer 위치를 순차적으로 기록한다.
전체 레이어 수 L에 해당하는 길이의 배열의 i번째 요소는 해당 레이어가 큐에 기록된 최근 N개의 토큰의 exit 레이어 주변 (±2)에 위치한 횟수를 누산한다.
최종적으로 예측기의 수와 위치는
offline scheduling에서 선택된 결과의 하위 집합과,
online scheduling에서 파생된 결과의 합집합에 의해 결정된다.
위 그림 설명
길이 5짜리 버퍼로, 최근 5개의 토큰이 어느 레이어에서 exit됐는지를 저장
최근 5개 토큰의 exit 레이어 = [16, 19, 20, 19, 20] = [16, 19, 20]
16레이어 주변 (±1)에 위치한 횟수를 누산
=>
16 → [15, 16, 17] → array[15]++, array[16]++, array[17]++
19 → [18, 19, 20] → array[18]++, array[19]++, array[20]++
20 → [19, 20, 21]→ array[19]++, array[20]++, array[21]++=>
| Layer | Count |
| ----- | ----- |
| 15 | 1 |
| 16 | 1 |
| 17 | 1 |
| 18 | 1 |
| 19 | 2 |
| 20 | 2 |
| 21 | 1 |Union 생성:
카운트가 1 이상인 레이어들의 모음
+ offline에서 exit된 횟수가 상위 M개인 레이어들의 모음
6. Context-aware Merged Mapping for Predictor
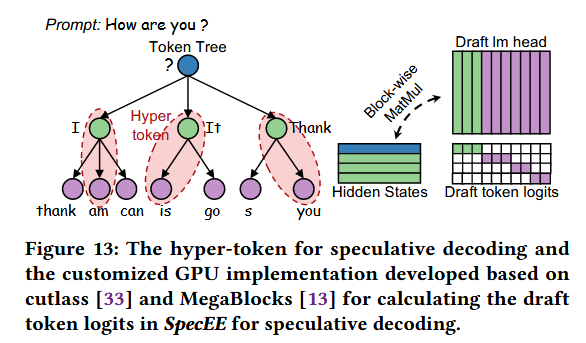
6.1 Motivation
Speculative model은 autoregressive 방식으로 여러 개의 토큰을 병렬적으로 생성하여, token tree를 구성한다.
① 일반 Autoregressive 방식
"How are you" → "?" 생성32개 레이어 × 1회 토큰
→ 한 번에 하나의 토큰 생성만 가능
② Speculative Decoding (DLM)
"How are you" → Top-3 토큰 생성: ["I", "It", "Thank"]3개의 후보 토큰 → 병렬
이어서:
"I" → [thank, am, can]
"It" → [is, go, s]
"Thank" → [you, ...]
→ 이렇게 해서 “Token Tree”가 만들어지고
→ 이후 이 전체 후보 트리 구조를 한 번의 TLM 추론으로 검증
Q. “DLM이 트리 전체를 만들고 나서야 TLM이 검증을 시작한다면, 그 트리 생성 자체가 느리면 전체 속도 이득이 상쇄되는 것 아닌가?”
A.
DLM 자체가 엄청 빨라서 ㄱㅊ
검증 추론 과정에서 EE를 적용할 때, 현재의 predictor mapping 방식은 토큰 트리의 각 토큰을 문맥적 의미를 고려하지 않은 독립적인 탐색 공간으로 취급한다.
즉, 각 분기의 토큰들을 predictor에 mapping하는 것이다. 위 Figure 13에서는
✅ "?" → Top-3 후보 ["I", "It", "Thank"]
→ 1개의 predictor: 이 3개를 묶어서 exit 판단
✅ "I" → ["am", "can", "think"]
✅ "It" → ["is", "go", "do"]
✅ "Thank" → ["you", "him", "them"]
→ 각각 1개 predictor씩 할당
총 4개의 predictor이다.
이런 predictor는 서로 독립적으로 작동하기 때문에, 전체 mapping 복잡도는 각 예측기의 복잡도의 곱으로 계산되어,
지수적으로 증가!
