
TinyTL : Reduce Activations, Not Trainable Parameters for Efficient On-Device Learning
TinyTL 논문에 대한 내용
Abstract
On-device training을 edge device에서 할 경우 문제점?
edge device는 메모리 제약 ↑
==> 기존 방법으로 training 못함
==> 기존 parameter를 줄임으로써 문제 해결
parameter를 줄임으로써 문제 해결을 할 경우 문제점?
주요 bottleneck은 parameter가 아닌 actiation 때문에 일어남
(즉, on-device training에서 memory bottleneck을 줄이기 위해서는 back-propagation에서 필요한 intermediate activations를 줄이는 것이 중요)
==> weight는 동결, bias만 학습
==> adaptation capacity ↓
==> residual feature maps를 추가적으로 학습하는 TinyTL 도입
Introduction
TinyTL의 배경
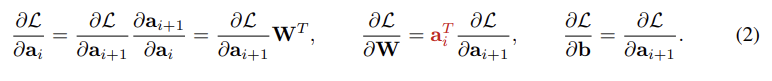
식(2)를 보게되면, backward pass 동안 memory footprint를 분석한 결과. 가중치를 업데이트할 때만 intermediate activations가 필요함, 반면, bias는 필요하지 않음.
==> pre-trained된 feature extractor의 weights를 freeze하고, biases만 업데이트하여, memory footprint ↓
위 내용 상세설명
weights를 학습시, 이전 단계의 모든 activation 값을 저장해야됨
vsbiases를 학습시, Loss를 bias로 미분시 는 상수 취급 되므로, 필요없어짐
==> biases만 학습시 memory footprint ↓
Tiny Transfer Learning

mobile inverted bottleneck block
Inverted Bottleneck Block에 대하여..
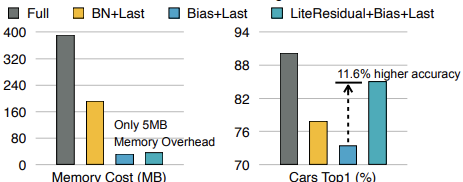
(a) Fine-tune the full network의 단점
학습에 쓰이는 메모리가 너무 많다는 것. 그이유는 TinyTL의 배경에서 설명했 듯이, activation을 저장해야하기 때문이다.
(b) Fine-tune bias only
위의 단점으로 고안된 것이 bias만 학습하는 방법인데, 이 방법으로 memory activation은 많이 줄였으나, 학습에 사용하는 범위가 적기에 accuraccy가 ↓↓

(c) Lite Residual Learning
결국 bias만 학습하는 것을 포기하고, activation도 학습함 ==> accuracy ↑
하지만, activation을 굉장히 작게 사용하여, memory activation도 ↓
Lite Residual Learning이 memory activation을 줄인 방법
-
channel수 감소
Inverted bottleneck block의 경우 expansion factor로 인해 6배로 channel이 증가되었다.
하지만 Lite Residual Learning에서는 expansion 과정을 거치지 않기에, 그 channel 수를 input텐서와 같이 C로 유지할 수 있기에 memory activation ↓ -
resolution 감소
Inverted bottleneck block의 경우 R의 resolution을 갖지만,
Lite Residual Learning에서는 그 해상도를 절반으로 줄여 input tansor의 크기가
가 되기에 memory activation ↓ -
depth 감소
Inverted bottleneck block의 경우 depth-wise Conv로 인해 연산량은 적지만, 연산-메모리 효율성이 낮아 메모리 재사용이 적다,
반면, Lite Residual Learning에서는 Group Conv를 사용하여 메모리 효율을 개선하여, memory activation ↓
위 3가지 방법으로 인해 memory activation인 기존의 %4
Normalization Layers
TinyTL은 어떤 normalization 기법도 적용할 수 있지만,
BN은 학습 중 정확한 running statistics 추정을 위해 큰 batch 크기를 필요로 하며,
이는 메모리 사용량을 줄이기 위해 작은 batch 크기를 요구하는 on-device training에는 적합하지 않다.
게다가, on-device training에서는 데이터가 스트리밍 방식으로 제공될 수 있어 batch 크기가 1이 필요할 수도 있어 BN은 적합하지 않다.
이에 비해 GN(Group Normalization)은 running statistics를 서로 다른 입력에 대해 독립적으로 계산하므로 작은 batch 크기를 처리할 수 있다.
실험 결과, GN은 작은 배치 크기(예: 8)에서 BN이 큰 배치 크기(예: 256)로 동작할 때보다 약간 낮은 성능을 보였다.
그러나 TinyTL은 on-device training을 목표로 하기 때문에, TinyTL에서는 GN을 선택.
