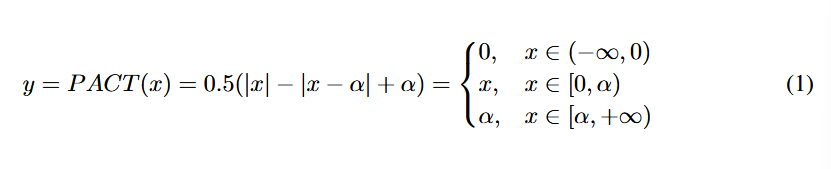
PACT: PARAMETERIZED CLIPPING ACTIVATION FOR QUANTIZED NEURAL NETWORKS
ABSTRACT
CNN의 FC layer에서 Activation이 weight보다 크기가 큼
But, weight Q 논문만 다수 존재
PACT = learnable activation clipping param 를 사용
1 INRODUCTION
PACT = learnable activation clipping param 를 사용
+ 더 빠른 수렴을 위해, loss function에 에 대한 regularization 적용
2 RELATED WORK
생략
3 CHALLENGES IN ACTIVATION QUANTIZAITON
Weight Q는 loss function을 weight 변수에 대해 이산화하는 것과 같음
⇒ Training 中 Q error를 보상 가능
But,
Activation Q는 learnable param X
⇒ Training 中 Q error를 보상 불가능
Activation Q는 특히 ReLU를 쓸 때(그림 1의 relu with quantization) 더 어려워짐
∵ ReLU는 upperbound가 없어, 더 많은 bit-width요구
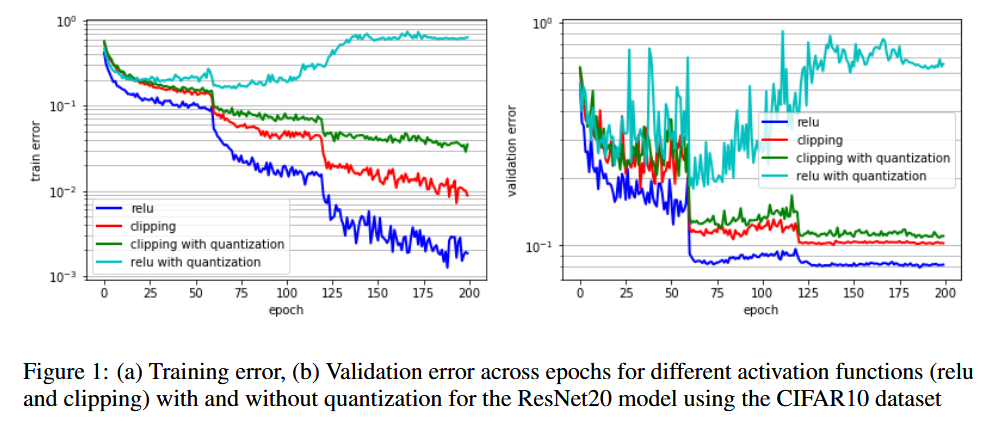
그림 1을 보면, relu with quantization에서 error가 relu에 비해 엄청 큼
⇒ Globally uppder-bound 설정하는 (그림 1의 clippping with quantization) clipping activation function
But,
Model가 차이로 인해, globally optimal clipping value를 결정 hard
⇒ Globally optimal clipping value를 결정하기 위해, learnable 도입
4 PACT: PARAMETERIZED CLIPPING ACTIVATION FUNCTION
⇒ activation의 범위를 로 제한
이후, clipping된 activation 는 dot-product를 위해, bitfh linearly quantized됨
⇒ 을 scale factor로도 씀
⇒ 단순히 clipping range만 학습하는 것이 아니라, 양자화 구간(interval)과 라운딩 함수(mapping function)의 형태를 함께 학습
4.1 UNDERSTANDING HOW PARAMETERIZED CLIPPING WORKS
의 범위를 sweep해가며, Q를 적용했을 때의 training loss를 기록
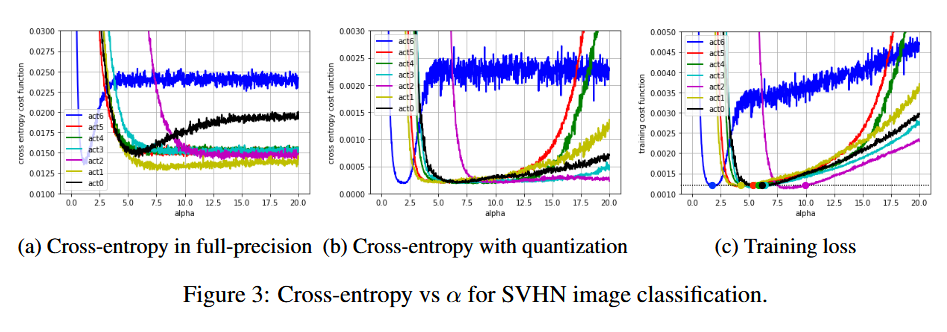
Pretrained된 SVHN에 대해, 의 범위에 따른, cross-entropy및 training loss를 측정
한 layer씩, ReLU대신 PACT로 했을 때의 cross-entropy가 그림 3(b)에 있음
-
그림 3(a)는
FP forward-pass를 통해 계산된 cross-entropy인데,
Q가 적용되지 않았을 때,
즉, 식 (1)만 됬을 때, 가 증가함에 따라(ReLU에 가까워짐에 따라) 많은 layer에서 cross-entropy가 작은 값으로 수렴
⇒ ReLU가 좋은 activation function임을 보임
But,
Q가 없는 현재 상황에서도, 특정 layer에 대해서는 잘 훈련된 를 쓰는게 cross-entropy를 줄임을 알 수 있음
(act0 layer를 정도로 했을 때, 가장 낮은 cross-entropy,
act6 layer를 정도로 했을 때, 가장 낮은 cross-entropy를 갖음)
⇒ ReLU가 항상 optimal은 아님 -
그림 3(b)는
Q forward-pass를 통해 계산된 cross-entropy인데,
가 증가함에 따라(ReLU에 가까워짐에 따라) 대부분의 layer에서 cross-entropy가 커짐
⇒ ReLU가 좋은 activation function이 아님을 보임
+ 최적의 가 layer마다 다른 범위를 가진다는 것을 관찰, 이는 training을 통해 양자화 스케일을 '학습'할 필요성을 뒷받침
4.2 EXPLORATION OF HYPER-PARAMETERS
생략
5 EXPERIMENTS
5.1 ACTIVATION QUANTIZATION PERFOMANCE
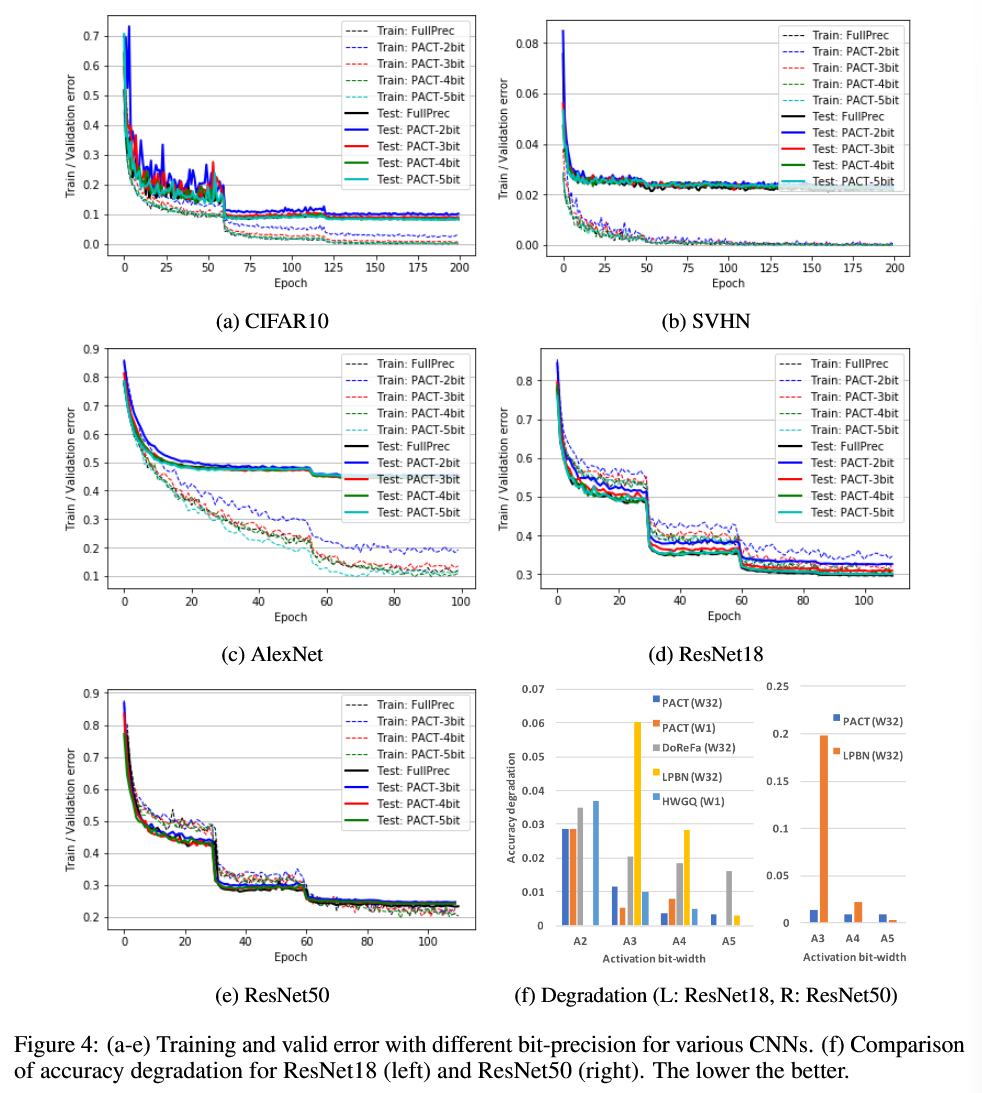
- Bit-width가 높을수록 train/test error가 FP(baseline)에 더 가까워짐
- 3bit보다 높은 bit-width를 사용하여 훈련하면 FP(baseline)과 거의 동일하게 수렴하는 것을 볼 수 있음
- 그림 4(f)를 보면,
ResNet18과 ResNet50 모두에서 PACT는 다른 Q 기법들과 비교하여 일관되게 더 낮은 acc degradation을 달성했으며, 이는 이전의 Q 접근 방식들에 비해 PACT의 강건성(robustness)을 입증
5.2 PACT PERFORMANCE FOR QUANTIZED CNNs
PACT가 activation Q에 초점을 맞추고 있음에도 불구하고, weight Q와 함께 사용할 수 있음을 입증하기 위해,
activation PACT Q, weight DoReFa Q 해봄
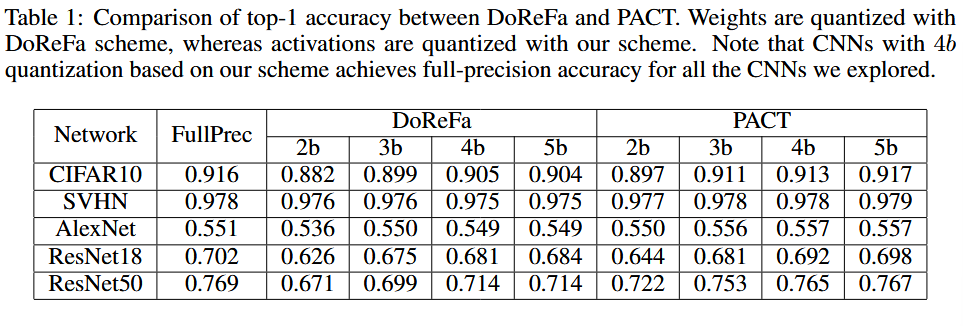
표 1은 다양한 model에서,
activation, weight 모두 DoReFa Q 했을 때와,
activation PACT Q, weight DoReFa Q 했을 때를 비교하여 보여줌
- 가중치와 활성화 모두 4비트 정밀도일 때, PACT는 테스트된 모든 네트워크에서 전체 정밀도(full-precision) 정확도를 일관되게 달성
6 SYSTEM-LEVEL PERFORMANCE GAIN
생략
7 CONCLUSION
생략
