Post-Training Quantization for Vision Transformer
Abstract
- Attention mechanism 기능을 보존하기 위해,
Q된 attention map의 relative order를 유지하게하는 ranking loss를 최종 Q 목적 함수에 도입 - MHA의 Attention map과 MLP의 output feature 간 nuclear norm을 활용하여, MixQ
1 Introduction
이 논문 이전의 PTQ 방법들은 CNN이나 RNN을 위해 설계됨
⇒ transformer의 특징 고려 X
⇒
- Attention map의 relative order를 유지하기 위해, ranking loss 도입
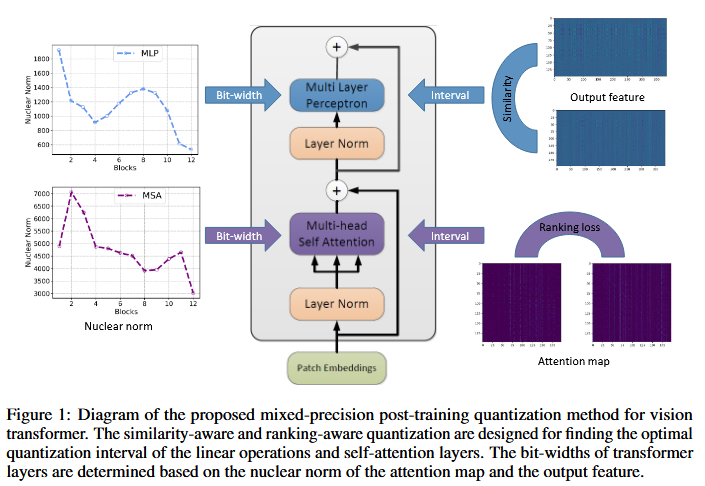
- Attention map과 MLP의 output feature의 sensitivity 측정을 위해, nuclear norm을 사용해서, MixQ
- Bias correction을 통한, Q error 보정
2 Related Works
생략
3 Methodology
- Linear layer를 위한 similarity-aware quantization + ranking-aware quantization
- Accuracy ↑을 위한 bias correction
- Nuclear norm을 통한 MixQ
3.1 Preliminaries
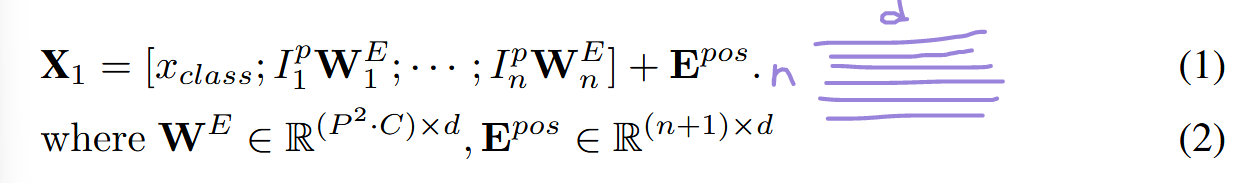
에서 의 가로 한 줄이 patch 하나에 대한 정보
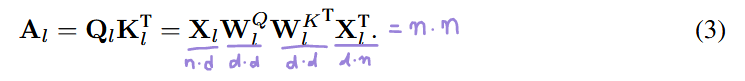
에서 의 결과 또한 가로 한 줄이 patch 하나에 대한 정보
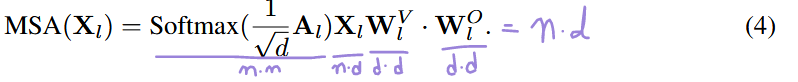
3.2 Ranking-Aware Post-Training Quantization
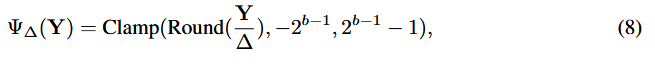
는 Q 함수이다.
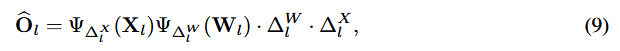
는 Q된 출력이다.
scale factor ()가 Q 결과에 큰 영향을 미침을 알 수 있다.
∵ 사실상 조절 가능한 것이 와 이기 때문에...
⇒ Calibration Dataset에서 생성된 weight와 activation에 대한 optimal scale factor를 찾자!!!
Self-attention layer는 전역적 관련성을 계산하는 CNN과 차별화를 갖는 구성 요소임.
Q 後 attention map의 relative order가 변경되는 것을 empirically 관찰
⇒ 이는 심각한 performance degradation 발생
Relative order란?
Attention map의 한 행 내에서, 임의의 두 값 의 대소 관계를 의미Q 後 attention map의 relative order가 변경됬다는 것은
Q 前에는 한 row에
..., 3.61, 5.234, ..., 4.24, ...
이었는데,
Q 後에는 한 row에
..., 4, 5, ..., 4, ...
가 되면,
의 대소 관계가 사라짐
⇒ Ranking Loss 도입
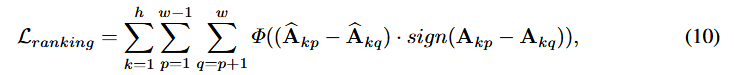
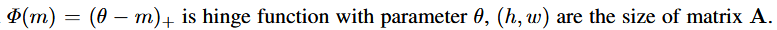


⇒ Ranking Loss function을 통해, Q Attention 값의 쌍별 순서가 원본 attention 값의 순서를 유지하도록 함.
전체 최적화 목표
전체 Loss Runction은 다음과 같음
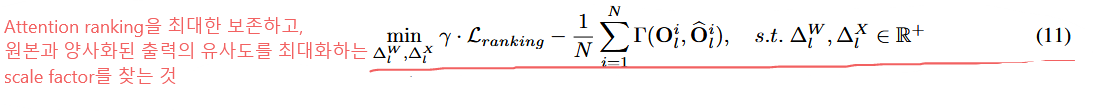
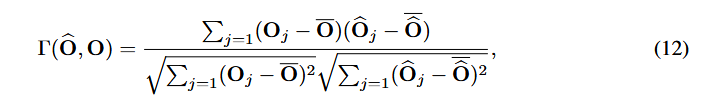
는 pearson correlation coefficient로 Q 전/후 텐서의 유사도 측정 지표로 사용됨
Alternative searching method
위의 식(11)을 해결하기 위해,
weight scale factor 최적화
後
input scale factor 최적화
Bias Correcition
Q로 인해 발생하는 오차를 출이기 위해, 최적의 scale factor를 찾고, biased 된 error를 보정
Q errors는 다음과 같아,
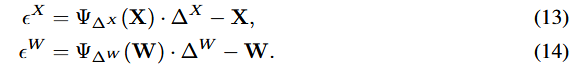
Q된 한 layer의 출력 의 error 기댓값은 다음과 같음
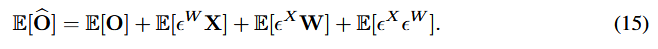
∵
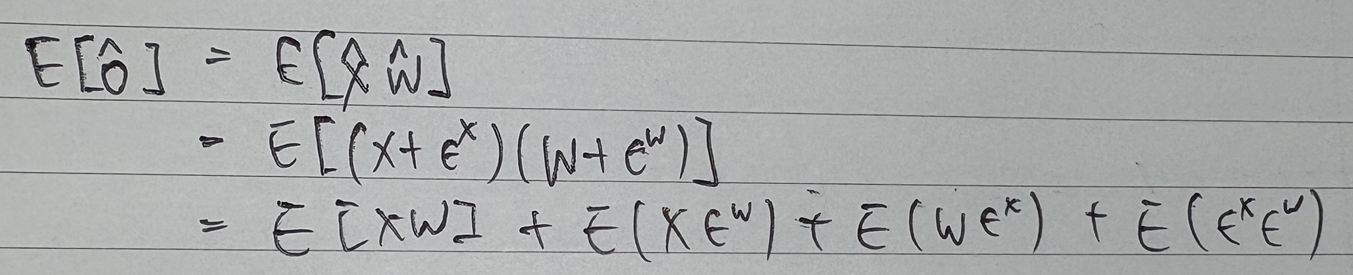
⇒ 를 통해, 보정!!!
3.3 Nuclear Norm Based Mixed-Precision Quantization
MHA, MLP를 MPQ 대상으로 보고,
두 모듈의 sensitivity를 계산하기 위해,
nuclear norm 사용
Nuclear norm이란 SVD의 matrix의 tr()임
즉,
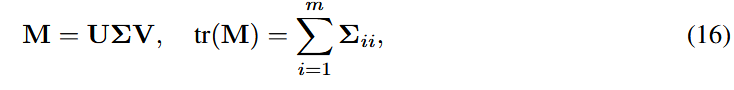 임
임
위 nuclear norm을
특정 MPQ 설정에서 model 전체에 얼마나 큰 perturbation을 일으키는지 측정하는
종합 sensitivity indicator 에 적용
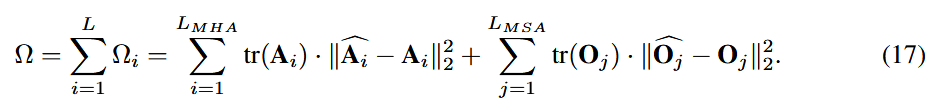
: nuclear norm
: Q error의 곱
⇒

4 Exprimental results
이태까지 Vit의 PTQ 연구가 없어서, 기존 CNN을 위한 PTQ 기법들과 비교함
4.1 Implementation details
생략
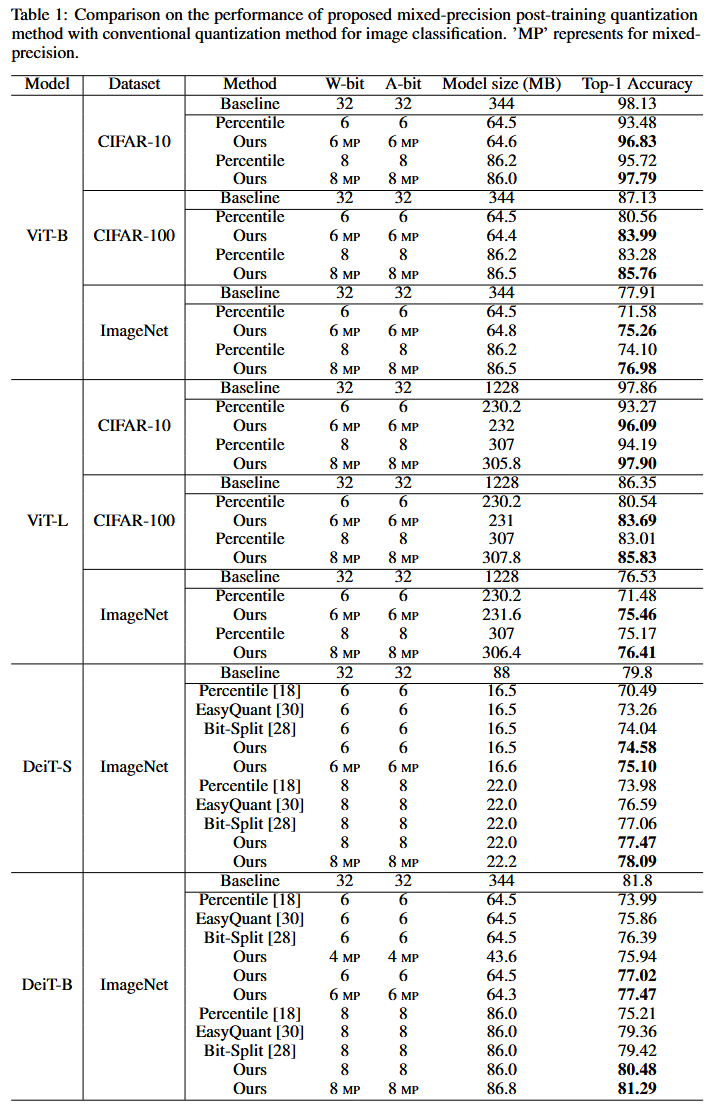
4.2 Results and Analysis
4.3 Ablation study
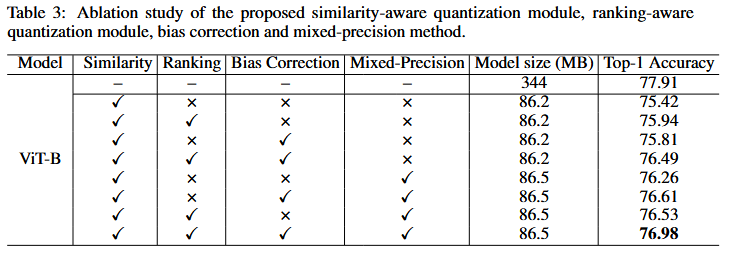
5 Conclusion
생략
