PTQ4ViT: Post-Training Quantization for Vision Transformers with Twin Uniform Quantization
Abstract.
Softmax, GeLU 이후 activation의 distribution
≠ gaussian distribution
+
MSE, cosine distance를 통한, optimal SF 결정은 정확 X
⇒
Twin uniform Q
+
Hessian guided metric을 통한, SF optimizing
1 Introduction
생소했던 개념들
- Self-attention module은 global information을 포착
- PTQ는 label 없는 calibraion images를 사용
문제1. 특수 분포 activation
- Softmax:
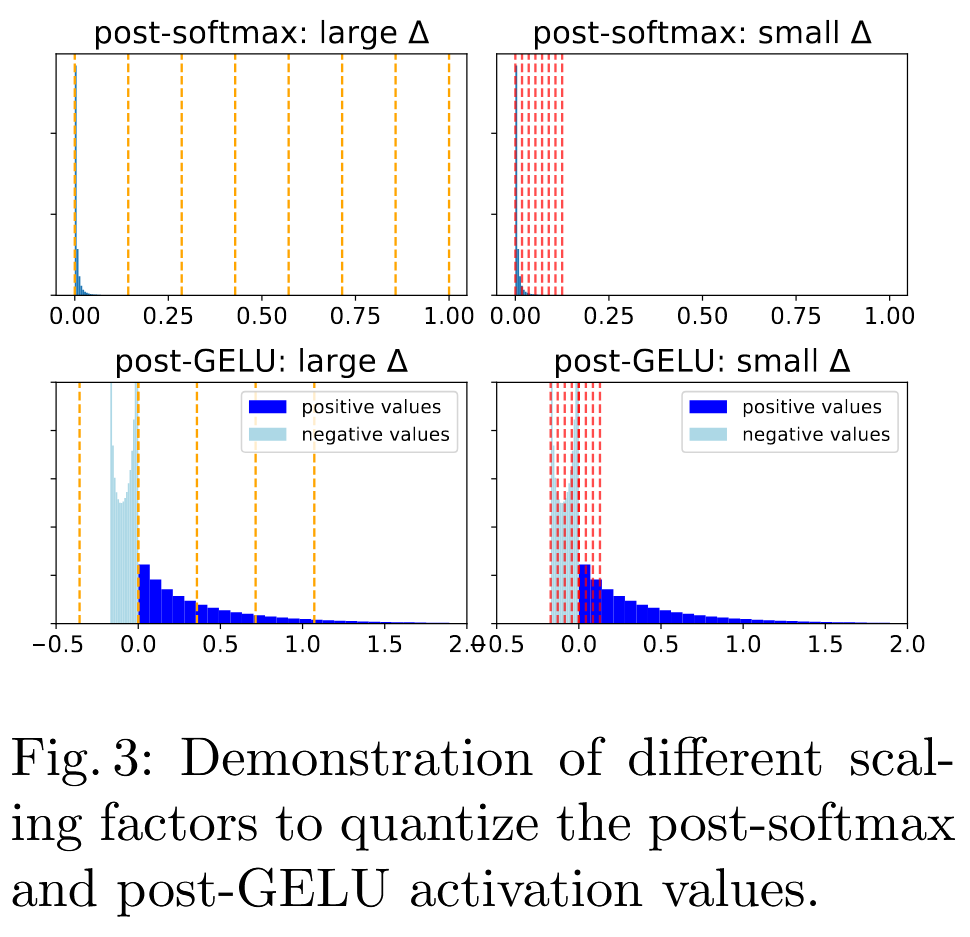
Softmax를 거친 값들은 [0, 1] 범위에서 매우 unbalanced된 distribution을 갖음.
대부분 값이 0에 매우 가까움.
+
큰 값의 수는 매우 적지만, 이 값들은 두 patch 간 높은 연관성(attention)을 의미. ⇒ 매우 중요한 값
⇒ 이 큰 값을 Q 범위에 포함시키기 위해, 큰 SF 要
⇒ 大多數의 작은 값들이 0으로 Q됨
⇒ Q Error ↑ - GeLU:
GeLU를 거친 값들은 asymmetrical한 distribution 갖음.
양수 값들은 분포가 넓음.
+
음수 값들은 skewed됨.
⇒ 이런 특수 distribution을 해결하기 위해, Twin uniform Q
이는 값들은 두 범위로 분리하여 각각 Q.
문제2. SF를 결정하는 지표 정확 X
MSE, Cosine distance, Pearson correlation coefficient등이 있었음.
⇒ local information만 사용
⇒ suboptimal
⇒ Hessian guided metric
2 Background and Related Work
2.1 Vision Transformer
생략
2.2 QuantizationFang, J., Shafiee, A., Abdel-Aziz, H., Thorsley, D., Georgiadis, G., Hassoun, J.: Post-training piecewise linear quantization for deep neural networks. In: ECCV (2020)
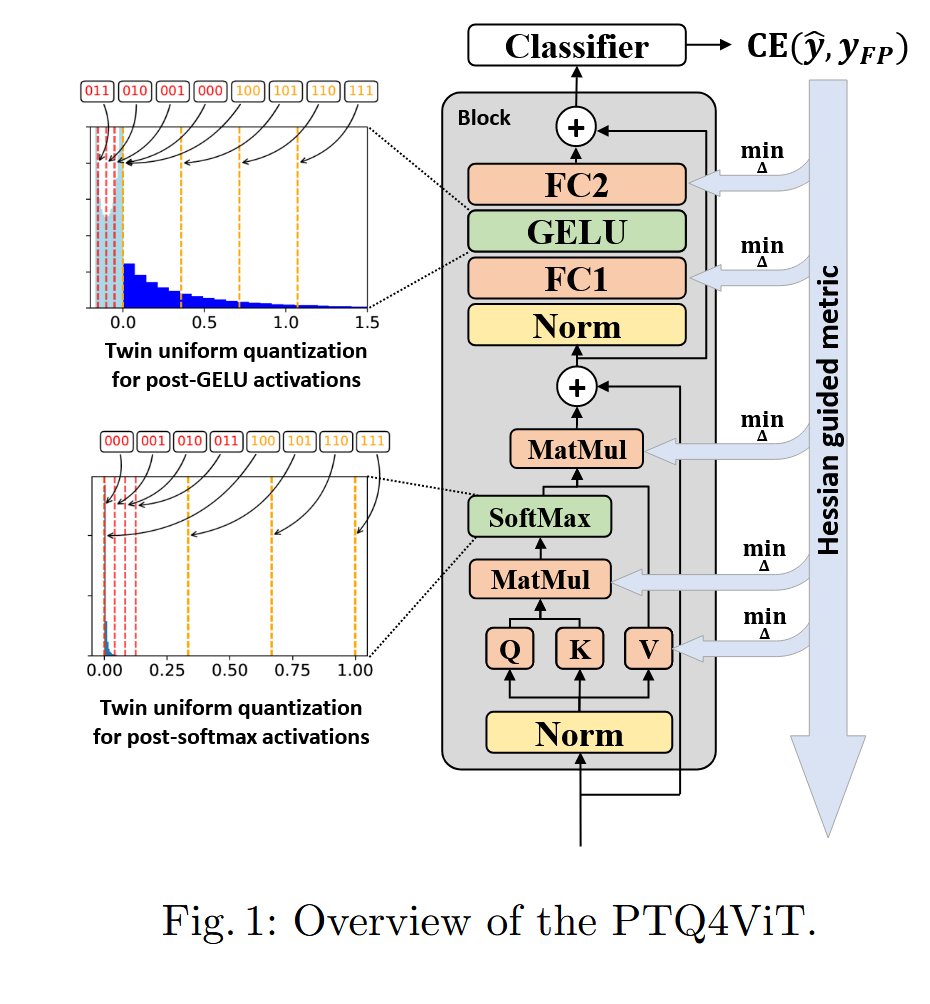
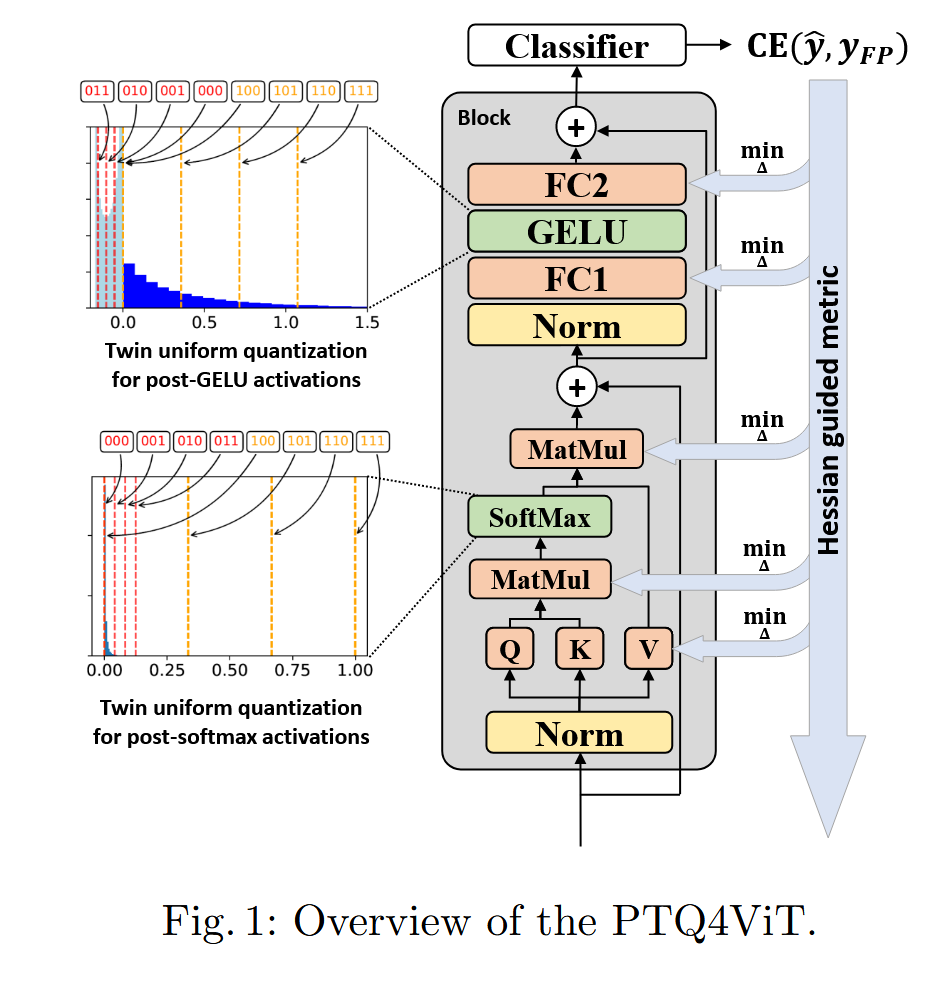
3 Method
3.1 Base PTQ for Vision Transformer
생략
3.2 Twin Uniform Quantization
- Softmax 후 활성화 분포: 활성화 분포가 매우 불균형하며(unbalanced), 대부분의 값이 0에 매우 가깝고 소수의 값만이 1에 가깝습니다.
- GELU 후 활성화 분포: GELU 함수를 거친 값들은 높은 비대칭 분포(highly asymmetric distribution)를 가지며, 무한정한 양수 값들은 범위가 큰 반면 음수 값들은 분포 범위가 매우 작습니다.
⇒ Twin uniform Q
Twin uniform Q는 2개의 Q 범위 를 갖음.
각각은 다른 SF 과 에 의해 제어됨.
⇒
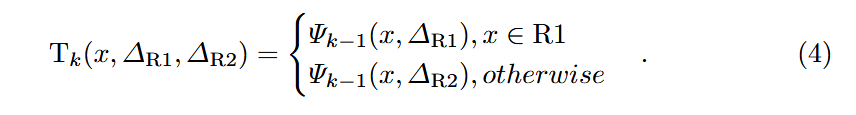
-
Softmax 後 값에 대한 범위 설정
작은 를 사용하여, 를 잘게 Q.
+
상대적으로 큰 로 고정하여, 을 크게 크게 Q. ∵ calibration 영향을 피하기 위해. -
GeLU 後 값에 대한 범위 설정
작은 로 고정하여, 를 잘게 Q. ∵ 음수 전체 범위 를 포괄하려고.
+
상대적으로 큰 를 사용하여, 를 크게 크게 Q.
⇒ 이제 optimal 만 찾으면 됨.
⇒
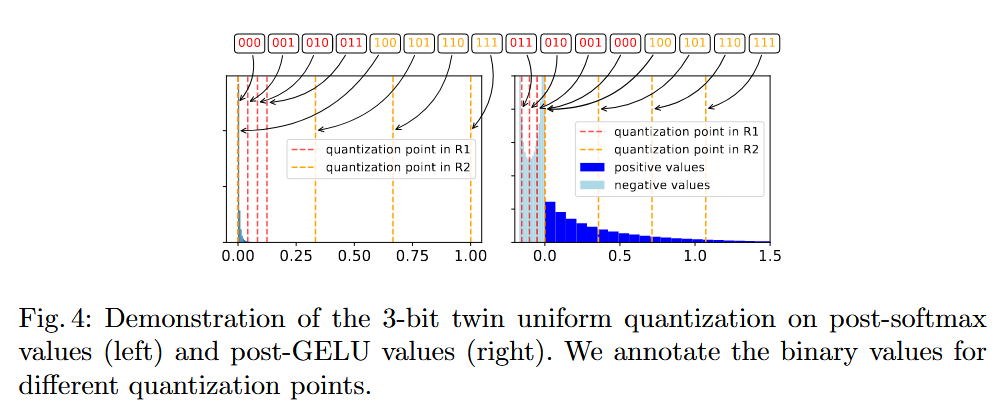
그림4에서, optimal 빨간색 범위만 찾으면 됨!!!
3.3 Hessian Guided Metric
Optimal SF를 찾기위해, 여러 metric(MSE, Cosine, Pearson, ...)으로 layer-wise + greedy하게 했었음
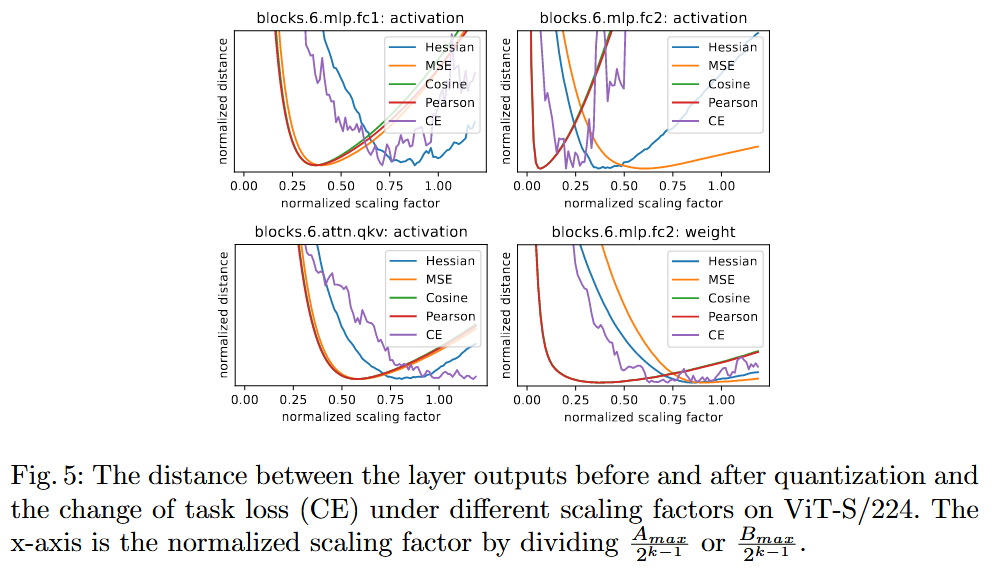
물론 Q 前/後 마지막 layer output 간의 distance ()를 사용하는 것이 PTQ에서 가장 정확.
But,
forward 너무 많이 해야됨.
⇒ Hessian Guided Metric
weight 를 변수로 취급할 때, Loss의 expectation은
Q는 weight에 작은 perturbation 을 갖게 함.
⇒
⇒ Taylor series expansion을 통해, Q가 Loss에 미치는영향을 분석 可能
⇒
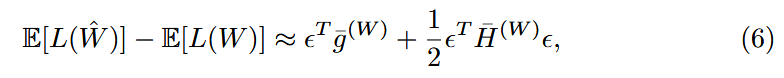
optimal SF를 찾아야 함!!!
⇒ 을 layer-wise하게 구성해야함.
⇒
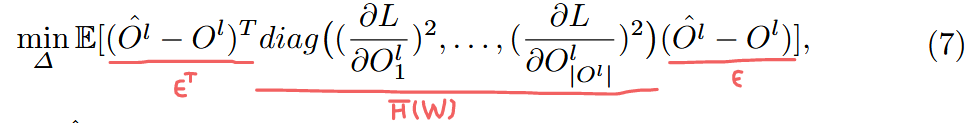
∵ 는 잘 training된 model에서 0을 갖고, 이어서.
3.4 PTQ4ViT Framework

1단계: Output() 및 gradient 수집
1 ~ 6 line
2단계: Optimal SF찾기
7 ~ 14 line
문제점
10 ~ 13 line에서 특정 layer를 Q하면,
이 바뀌는데,
그럼 도 매번 새로 계산해야 되는데, 그렇게 안함...
∵ GPU 메모리 줄이려고...
4 Experiments
4.1 Experiment Settings
- Softmax 後: 의 탐색 공간은
- , # Round
- BasePTQ
- , # Round = 1
- PTQ4ViT
- , # Round = 3
- BasePTQ
- ImageNet
- Calibration 32개
4.2 Results on ImageNet Classification Task
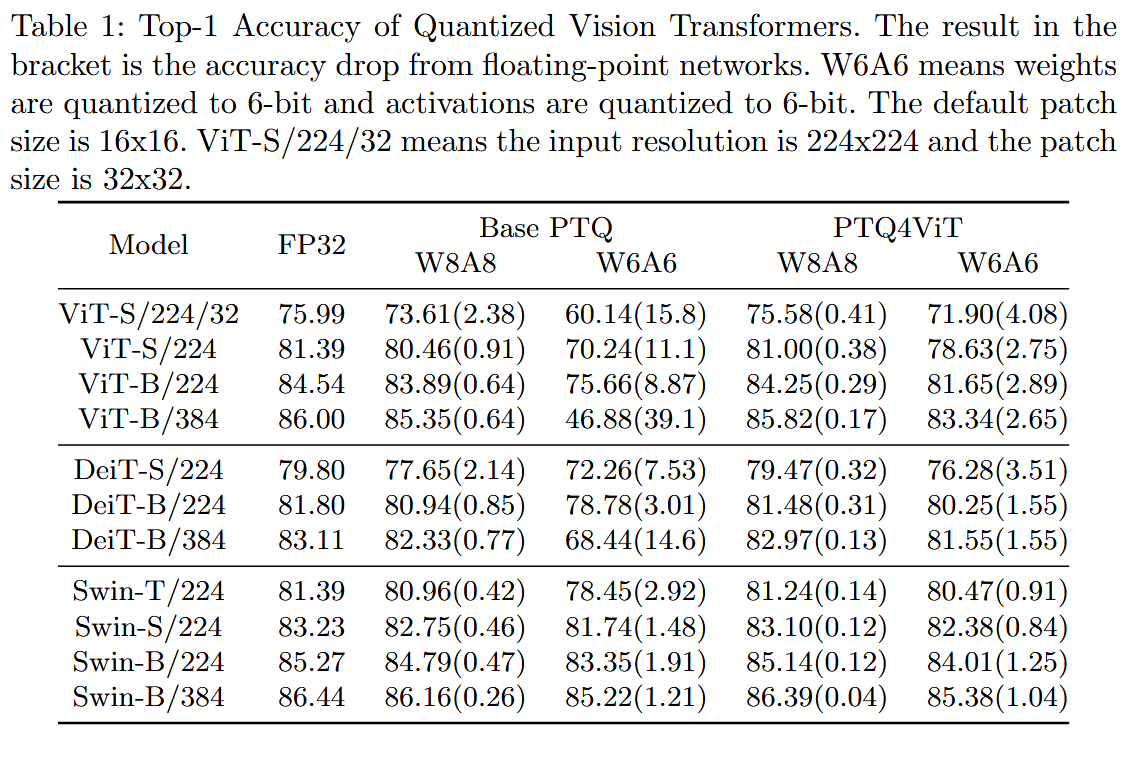
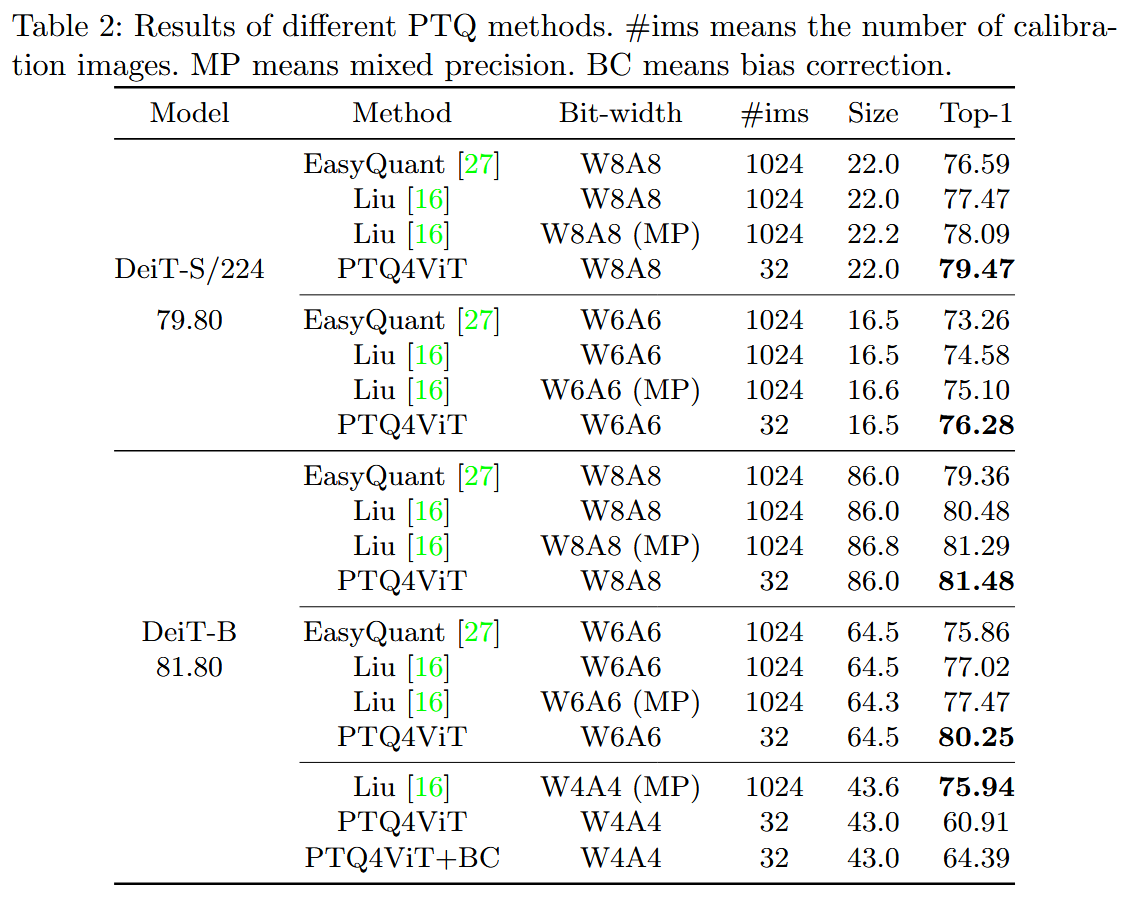
4.3 Ablation Study
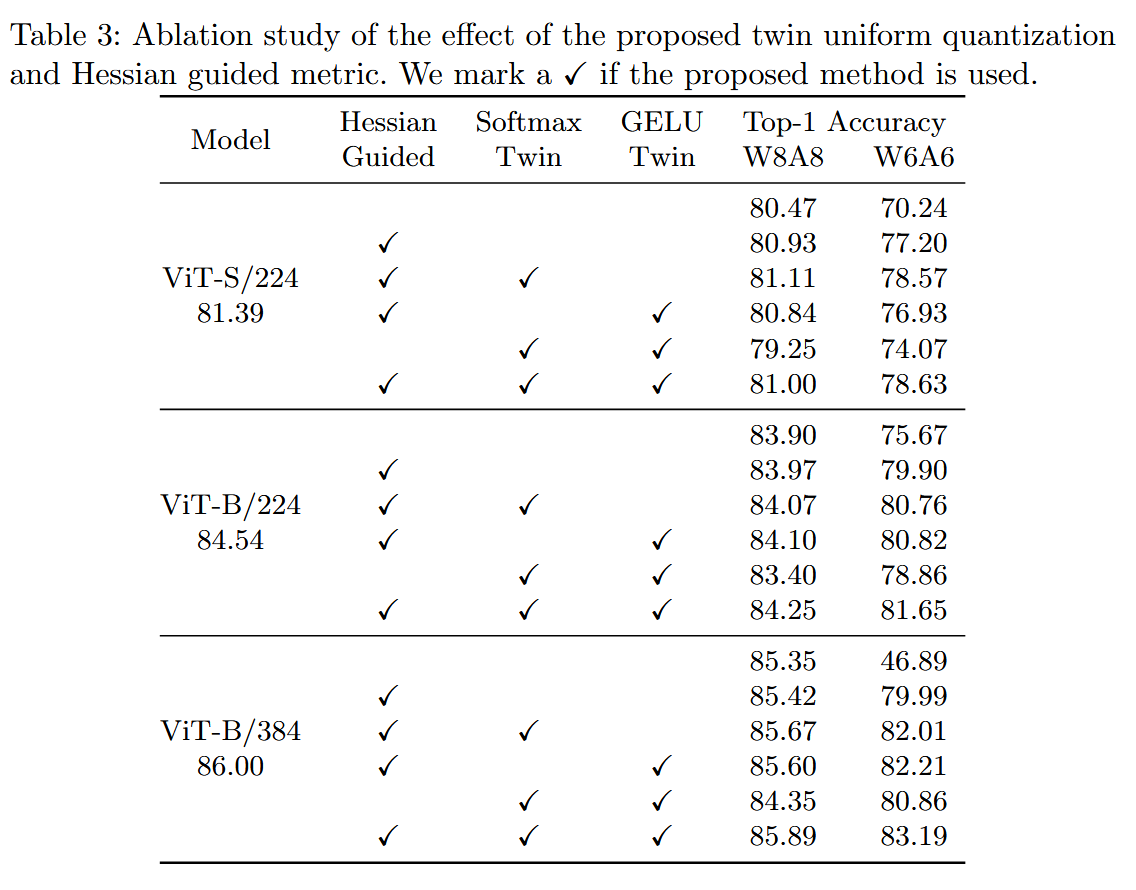
Conclusion
생략
