Abstract
아이템 추천은 여러 아이템을 개인에 맞춰 순위를 매겨주는 문제이다. 여기서는 클릭이나 구매기록 같은 간접 피드백을 이용하는 일반적인 시나리오로 설명하겠다. 아이템 추천에는 MF나 kNN같은 많은 방법이 있다. 이런 방법들은 유저별로 순위는 잘 구축하지만 순위 자체를 최적화 시키는 방법은 아니다. 여기서는 개인화 랭킹에 적용 가능한 일반적인 최적화 함수 BPR-OPT를 소개한다. 이는, 베이시안 정리의 사후 확률을 최대화하는 함수이다. 또, 우리는 BPR-OPT로 모델을 최적화하는 학습 알고리즘을 하나 소개한다. 이 방법은 부트스트랩 샘플링이 적용되는 SGD에 기반한다. 이런 방법들이 두가지의 최신 추천 모델인 MF와 kNN에 어떻게 적용되는지 보여줄 것이다. 우리가 실험한 개인화 추천 최적화 방법은 MF와 kNN에 대한 기존의 방법들보다 훨씬 뛰어나다. 이러한 결과는 올바른 함수를 사용해 모델을 최적화 하는 것이 매우 중요함을 보여준다.
boostrap sampling
사실 우리가 가지고 있는 데이터는 모집단의 표본이다. 그리고 모집단은 거의 대부분에 상황에서는 완벽히 구하지 못한다. 따라서 우리는 표본 데이터만을 이용해야 하는데, 사실 궁극적으로 우리가 원하는 것은 모집단의 통계적 수치이지 표본집단의 통계적 수치가 아니다.
이 방법은 가지고 있는 데이터의 일부를 샘플링한다. 샘플링 한 결과를 분석하고, 샘플링을 여러번 해본다. 여러 개의 결과가 나오면 이를 종합해본다. 평균적인 결과를 구해보면 이 것이 모집단의 통계적 특징과 근사된다고 한다.
참고 링크
(간단) https://modern-manual.tistory.com/31
(상세) https://lee-jaejoon.github.io/stat-bootstrap/1 Introduction
컨텐츠를 추천하는 것은 여러 정보 시스템에서 매우 중요하다. 아마존같은 온라인 쇼핑몰은 각각의 유저가 관심있는 아이템을 보여주도록 추천한다. 미디어 사이트의 예로는 유튜브가 있다. 개인화라는 특징은 컨텐츠를 제공하는 사람과 제공받는 사람에게 모두 매력적인 특징이다. 쉽게 조회수와 매출을 올릴 수 있고, 쉽게 재미있는 컨텐츠를 발견할 수 있기 때문이다. 아이템 추천은 특정 유저에게 아이템 랭킹을 제공한다. 유저의 선호도는 구매 내역, 접속 내역 등 유저의 과거 기록을 가지고 결정된다.
추천 시스템은 발전하고 있는 연구분야이다. 대부분의 연구는 평점과 같은 직접 피드백에 관한 연구이다. 그런데 사실, 현실에서는 대부분의 피드백이 간접적이다. 간접 피드백은 클릭 여부, 몇 번 봤는지, 구매했는지처럼 자동으로 기록된다. 이런 기록은 유저가 분명하게 의사를 표현하는 데이터가 아니어서 데이터를 모으기 훨씬 쉽다. 사실 간접 피드백은 이미 대부분의 정보 시스템에서 사용되고 있다. 예를 들어 웹 서버는 페이지 접속 기록을 로그 파일에 저장한다.
우리 연구에서는 개인화 추천을 위한 일반적인 알고리즘을 제공한다. 우리 연구의 의의는 다음과 같다.
- 개인화 랭킹을 최적화하기 위해 최대 우도를 사용하는 BPR-OPT 최적화 범용 함수를 제시했다
- BPR-OPT를 최대화 하기 위해서 학습 데이터를 부스트래핑 하는 SGD에 기반한 LEARN BRP 알고리즘을 제안한다. 이 알고리즘은 BPR-OPT를 최적화하는데에 있어 기존의 GD보다 더 좋다.
- LEARN BPR을 두 개의 최신 추천 모델에 적용하는 방법을 보여준다.
- 개인화 랭킹을 할 때 BPR을 가지고 모델을 학습하는 것이 다른 방법보다 우수함을 실험적으로 증명했다.
2 Related Work
추천 시스템에서 가장 유명한 모델을 kNN 협업 필터링이다. 전통적으로 kNN 유사 행렬은 피어슨 상관관계와 같이 휴리스틱하게 계산되었다. 그러나 최근 연구에서는 유사 행렬이 모델의 파라미터로 간주되고 구체적으로 학습되기 시작했다. 최근, MF는 직접/간접 피드백을 이용하는 추천 시스템에서 매우 유명해졌다. 그 전 연구에서는 SVD가 피처 학습을 위해 제안되었다. SVD로 학습되는 MF 모델은 오버피팅되는 경향이 있다보니 규제화 알고리즘이 많이 제안되어왔다. 아이템 예측에서는 정규화된 최소자승법, WR-MF가 제안되었다. 파라미터는 반대되는 예제들의 영향을 줄이기 위해 사용될 수 있다. 호프만은 아이템 추천에 확률론적 잠재 의미 모델을 제안했다. 슈미트 티메는 아이템 추천을 다중 분류 문제로 전환해 여러개의 이진분류기를 통해 해결하려고 했다. 지금까지 이야기한 여러 아이템 추천에 관한 연구들은 개인화 랭킹 데이터셋으로 평가되었는데 그 중 어느것도 직접적으로 모델의 파라미터를 직접적으로 최적화하지 않았다. 대신에 유저가 아이템을 고를지 안고를지를 예측하는데 더 힘을 썼다. 우리 연구에서는 이러한 개인화 추천을 하는 함수를 최적화하는 것부터 시작한다. 우리는 MF나 adaptive kNN같은 최신 모델들이 어떻게 평범한 학습 방법론들보다 함수를 최적화함으로써 훨씬 좋은 성능을 낼 수 있는지 보여준다. WR-MF 방법과 최대 마진 MF, 그리고 우리의 방법간의 자세한 연관성은 섹션 5에서 다룬다. 섹션 4.1.1에서는 우리의 최적화부터 AUC 최적화까지 다룬다.
case weight
최소자승법, least-square에서 사용하는 parameters를 의미한다.우리 연구에서는 모델의 파라미터를 offline learning 하는데 초점을 두었다. 새로운 유저가 등장하고 해당 유저의 정보나 기록이 증가하는 등의 online learning 까지 연장하는 것은 이미 MF의 rating prediction에서 연구되어 왔다. 이와 같은 동일한 전략이 BPR에서도 사용된다.
또 비협업 방식의 모델 랭킹 방법도 존재하긴 한다. 한가지 방법은 순열을 이용해 모델의 파라미터를 설정하는 방법이다. 또 다른 방법은 GD를 사용해서 랭킹을 위한 신경망 모델을 최적화한다. 이와같은 모든 방법은 한 가지 랭킹만 학습한다. 이러한 방법은 개인화되지 않는데 반대로 우리의 모델은 개인화 추천이 가능한 협업 모델이다. 유저마다 개인 랭킹이 존재한다. 어떻게 평가할 것이냐면, 제일 먼저 전형적인 추천 시스템 세팅에서 우리의 개인화 BPR 모델이 비개인화 모델보다 이론적으로 우수함을 실험적으로 보여줄 것이다.
3 Personalized Ranking
personalized ranking은 한 유저에게 순위가 매겨진 아이템 리스트를 제공하는 문제이다. 아이템 추천이라고도 불린다. 예를 들어 온라인 쇼핑몰은 유저가 구매하기 원하는 아이템 리스트를 순위 매겨 추천해주길 원할 것이다. 여기서는 간접 행동으로부터 랭킹을 추론하는 시나리오를 다룬다. 간접 피드백의 흥미로운 점은 유저가 관측한 부분에 대해서만 피드백을 얻을 수 있다는 것이다. 아직 유저가 보지 않은 아이템에 대해서는 유저가 정말로 관심이 없는 것일수도, 또는 두었다가 나중에 구매할 아이템일 수도 있다.
3.1 Formalization
U를 모든 유저의 집합, I를 모든 아이템의 집합이라 하자. 간접 피드백 S는 U x I 행렬에서 얻을 수 있다. (Fig 1의 왼쪽을 보면 됨) 이러한 피드백의 예시는 온라인 쇼핑몰에서 구매내역, 미디어 사이트에서 조회수, 웹 사이트에서 클릭등이 있다. 추천 시스템은 유저에게 전체 커스텀 랭킹 >u 를 제공한다. >u는 모든 아이템 행렬에 포함되며 다음과 같은 속성을 만족한다. (전체성, 반대칭성, 전이성)
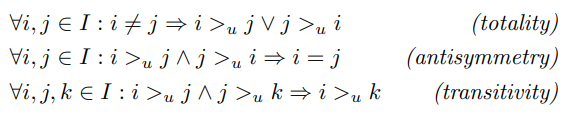
totality : 서로 다른 아이템 i, j에 대해 임의의 유저 u는 아이템 i보다 j를 더 선호할 수도 또는 그 반대일 수도 있다
antisymmetry : 임의의 유저 u가 i보다 j를 선호하고 j보다 i를 선호한다면 i랑 j는 같은 아이템이다
transitivity : 임의의 유저 u가 아이템 i, j, k에 대해 i보다 j를 선호하고 j보다 k를 선호한다면 i보다 k를 선호한다좀 더 편하게 다음과 같이 정의할 수 있다
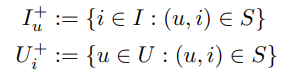
3.2 Analysis of the problem setting
전에 언급한 바와 같이 implicit feedback system은 positive class만 관찰할 수 있다. 그외에는 negative하거나 아직 발견하지 못한 것들이다. 결측치 문제를 대처하는 가장 흔한 방법은 전부 무시하는 것이다. 하지만 그렇기 떄문에 일반적인 머신러닝 모델은 해당 데이터가 실제로 결측치였는지 negative 였는지 학습할 수 없다.
personalized score를 예측하기 위해 아이템 추천에서 흔히 사용하는 방법은 아이템에 대한 유저의 선호도를 반영하는 것이다. 그러고나서 선호도에 맞춰 아이템의 순서를 매긴다. 머신러닝적 방법은 positive 또는 negative 클래스를 가진 유저와 아이템 쌍으로부터 학습 데이터를 만든다. 그리고 모델은 이를 학습한다. 이 말은 모델이 S의 요소들은 1로, 그 외에는 0으로 예측하기 위해 학습한다. 문제는 현재가 아닌 나중에 채워져야 하는 데이터들이 학습을 하면서 negative feedback 학습 방법으로 채워진다는 것이다. 이는, 충분히 표현력있는 모델이 이 요소들을 0으로 밖에 채우지 못한다는 것이 문제이다. 그럼에도 이러한 머신러닝 방법론들이 랭킹을 예측할 수 있는 이유는 정규화와 같은 오버피팅을 막기 위한 전략이 있기 때문이다.
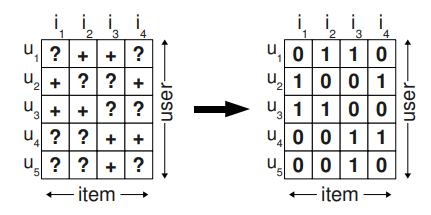
Figure 1 : 왼쪽에는 관측된 데이터 S가 있다. 이러한 S로부터 학습할 수 있는 것은 긍정 데이터 뿐이다. 보통 부정 데이터는 0으로 채운다.
우리는 학습 데이터로 사용되는 아이템 쌍을 다른 방식으로 사용한다. 그리고 하나의 아이템을 단순히 결측치를 부정값으로 바꾸는 방법 보다는 더 좋은 표현식을 사용함으로써, 단일 아이템을 점수 매기기 보다는 올바르게 아이템 쌍들을 순위 매기는 방법으로 최적화한다. S로 부터 우리는 각각의 유저 파트를 재구성한다. 아이템이 특정 유저에 의해 관측되면 우리는 유저가 관측하지 않은 아이템보다는 관측된 아이템을 선호한다고 가정한다. 예를 들어, 그림 2에서는 유저 u1이 아이템 i2는 보고 아이템 i1은 보지 않는다면 i2 >u i1 라고 말할 수 있는 것이다. 유저가 두 개의 아이템을 봤다면 여기서는 더이상 어떤 선호도도 추론할 수 없다. 또한 유저가 관측하지 않은 두 아이템에 대해서도 선호도를 추론할 수 없다. (예를 들면 u1과 i1, i4가 그러하다) 이를 공식화하면 다음과 같다.
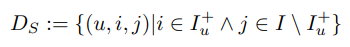
Ds에 속하는 u, i, j의 의미는 다음과 같다. user u는 j보다 i를 선호한다. >u 기호가 비대칭적성 특징을 가지기 때문에 그 반대의 경우도 성립한다.
우리의 방법은 다음과 같은 두 개의 장점이 있다.
-
학습 데이터는 positive and negative pairs 그리고 missing values로 구성되어 있다. 관측되지 않은 두 아이템 사이의 결측치에도 추후에 순위가 매겨져야만 한다. 이는 Pairwise 관점에서, 학습데이터 Ds와 테스트 데이터가 서로 배타적이다.
-
학습 데이터는 실제 데이터의 랭킹을 위해 만들어졌다. 예를 들어 관측된 데이터 Ds는 학습 데이터로 사용한다.
