Dense Passage Retrieval for Open-Domain Question Answering
Abstract
Open-domain question answering(자유 주제 질의 응답, 이하 OPQA)은 TF-IDF나 BM25같은 sparse vector space model후보 passage를 잘 선택하기 위해 효율적인 passage 탐색에 달려있다. 이번 연구에서는 간단한 이중 인코더 구조를 기반으로 적은 수의 질문과 지문을 학습해 얻은 dense 임베딩을 사용해 구현한 retrieval을 소개한다. 매우 큰 ODQA 데이처셋을 평가할 때 우리의 dense retriever는 현재 대세인 Lucene-BM25 시스템과 top-20 passage retrieval 정확도 부문에서 9~19% 차이의 성능을 냈다. 그리고 다중 ODQD 벤치마크에서 end-to-end QA system이 새로운 sota로 자리잡을 수 있도록 이바지했다.
1 Introduction
ODQA는 question에 대한 사실을 대형 문서집합을 이용해 답을 구하는 task이다. 초기 QA 시스템은 종종 복잡하고 다중 요소로 구성되어 있는 반면에 독해 모델이 발전하면서 더 간단한 두 단계의 구조가 등장했다. (1) context retriever(지문 검색기)가 처음에 question에 대한 답을 가지고 있는 지문의 일부를 고른다. 그러고 나면 (2) reader 모델이 철저히 선택된 지문을 검사하고 올바른 답변인지 파악한다. 비록 기계 독해에서 (여러 구성이) 줄어든 ODQA는 합리적인 방법이지만 실전에서는 종종 엄청난 성능 감소로 이어졌다. 좀 더 개선된 검색기능이 필요하다는 반증이다.
ODQA의 검색은 종종 TF-IDF나 BM25를 가지고 이루어졌다. 이는 키워드를 효과적으로 역색인했고 희소행렬이라는 고차원의 벡터로 질문과 지문을 나타낼 수 있는것처럼 보였다. 거꾸로, dense는 설계적으로 숨어있는 의미적인 인코딩을 통해 sparse를 보조해주는 역할이다. 예를 들어 동의어나 의역과 같은 표현이 완전히 다른 토큰으로 구성되어 있더라도 여전히 유사한 벡터로 매핑된다. “Who is the bad guy in lord of the rings?” 라는 질문은 “Sala Baker is best known for portraying the villain Sauron in the Lord of the Rings trilogy.”로 답변될 수 있는 것처럼 말이다.(여기서 질문과 답변은 동일한 키워드가 존재하지 않는다) 단어 중심적 구조는 이러한(동의어나 의역이 사용되는) 지문을 가져오기란 여간 어렵다. 반면 dense retrieval 방식은 bag guy와 villan을 연결하기에 더 좋으며 올바른 답변을 가져올 수 있다. Dense enocdings은 특정 태스크에 맞게 표현들을 가질 때 유연함을 더해주는 embedding 함수를 가지고 학습을 할 수 있다. 특별한 내부 메모리 데이터 구조와 인덱싱 구조가 있다면 retreival은 최대 내적 연산 탐색 알고리즘을 사용해 효과적으로 이루어질 수 있다.
그러나 좋은 dense vector 표현을 학습하는 것은 일반적으로 매우 많은 수의 질문-지문 쌍의 라벨링 데이터가 있어야 한다. 정교한 ICT 방법론을 사용해 마스킹된 문장을 예측하는 추가적인 사전학습 기법이 적용된 ORQA가 등장하기 전까지는 dense retrieval 방법은 TF-IDF나 BM25가 같은 (sparse) 방법을 뛰어넘지 못했다. (사전학습 이후에) 그러고나서 question encoder와 reader model은 질문과 정답이 한번에 묶인 데이터 쌍을 가지고 fien tuning 됐다. 비록 ORQD는 dense retrieval이 다중 ODQA 데이터셋에 최고 기록을 가지고 있는 BM25를 제쳤다고 성공적으로 증명했지만, dense 역시 두 가지 약점을 극복하지 못했다. 첫번째는 ICT 사전학습 방법은 계산량이 매우 많으며 이러한 방법론에서 질문을 대체할 수 있는 좋은, 일반적인 문장이 불명확하다는 것이다. 두번째는, context encoder가 질문-답변 쌍을 사용해서 fine tuning하지 않기 때문에 이 인코더를 통해 얻은 임베딩 표현이 최선이 아니라는 점이다.
여기서 우리는 한가지 질문을 환기한다. 우리는 질문-지문쌍 또는 질문-답변 쌍만을 가지고 추가적인 사전학습을 진행해서 더 좋은 dense 임베딩 모델을 학습할 수 있을까? 현재 표준 버트 사전학습 모델과 이중 인코더 구조 의 장점을 극대화 하기 위해 우리는 상대적으로 적은 수의 질문-지문 쌍을 사용해 올바른 학습 계획을 세우는데에 초점을 맞췄다. 몇개의 섬세한 ablation(특징제거) 실험을 통해 알아낸 우리의 최종 솔루션은 매우 간단했다. 한 배치에서 사용되는질문, 그리고 질문과 관련된 지문쌍을 최대 내적 연산을 수행해서 비교하는 것으로 임베딩을 최적으로 학습할 수 있다. 우리의 DPR은 역대급으로 강력하다. 우리 모델은 매우 큰 격차로 BM25를 이긴것(65.2% VS 42.9%) 뿐만 아니라 ONQ 부문에서 ORQA와 비교해 end-to-end QA 정확도를 충분히 향상시켰다.(41.5% VS 33.3%)
우리의 성과는 두 가지 측면이 있다. 첫째, 적절한 학습 세팅을 가지고, 기존의 질문-지문 데이텃을 가지고, 간단하게 질문-지문 인코더를 fine tunning 하기만 해도 BM25를 크게 뛰어넘는다. 둘째, 우리는 ODQA의 관점에서 retrieve의 정확도가 증가할 수록 end-to-end QA 정확도도 증가했다. 현재 공개된 reader model에 top retrieved passage를 적용했더니 몇개의 복잡한 시스템과 비교해서 open-retrieval setting에서 다중 QA dataset에 대해 동등하거나 더 좋은 결과를 얻었다.
2 Background
ODQA의 문제점을 이번 장에서 다룬다. “Who first voiced Meg on Family Guy?” 이나 “Where was the 8th Dalai Lama born?”와 같이 간단한 질문이 주어지면 매우 다양한 주제를 가지고 있는 거대한 말뭉치를 사용해서 이에 대한 대답을 해야한다. 자세하게는 말뭉치에서 한개 또는 여러개의 지문의 영역을 정의하는 Extracted QA를 한다고 해보자(QA는 Extracted와 Generation으로 나뉜다) 우리는 라는 Document D를 가지고 있다고 하자. 우리는 처음에 각 문서들을 기본 retrieval unit을 기준으로 동일한 길이의 지문으로 나눈다. 그리고 M개의 전체 지문을 얻고 이를 라고 하자. 각각의 p는 tokens 로 구성된다. 질문이 주어지면, 우리의 목적은 지문 로 부터 질문에 대한 답을 할 수 있는 에서 까지의 범위를 찾는 것이다. 이건 알고 있어야 하는데, 다양한 도메인을 모두 다루다보면 말뭉치 크기는 쉽게 백만개의 문서단위(위키같은)에서 10억만개(웹같은)를 상회하게 된다. 결과적으로 어떤 ODQA 시스템이든 질문에 대한 답을 하기전에 질문과 관련이 있는 지문들 중 매우 작은 일부분만을 선택할 수 있는 효율적인 검색 시스템이 필요하다는 것이다. 수식적으로 표현하면, retriever R은 (q, C) 질문과 말뭉치를 가지고 수행되며, 라는 결과물을 반환해야 한다. 이 함수는 q와 C가 입력으로 들어가서 C의 매우매우매우매우 작은 부분집합인 를 반환한다. 만약 고정된 k가 있으면 retriever는 top-k retrival 정확도를 개별적으로 평가할 수 있다. 이 정확도는 질문에 대해 답변을 할 수 있는 (지문의) 범위를 가지고 있는지에 대한 한 부분이다.
3 Dense Passage Retriever (DPR)
우리는 여기서 ODQA에서 retrieval 요소들을 개선하려는 조사에 초점을 맞췄다. 지문 M의 집합을 가지고 모든 지문을 저차원의 연속 분포(=space, 차원의 값이 연속적이라는 의미인 듯)로 indexing하는 것이 목적이다. 그래서 우리는 reader가 task를 수행할 때 입력된 질문과 관련이 있는 top-k의 지문들을 효율적으로 가져올 수 있게된다. M 이라는 수는 매우 크고(4.1장에서 나오는 우리의 실험에서는 2.1천만개의 지문이 있다) k는 보통 20~100 사이로 작게 설정된다.
3.1 Overview
DPR은 dense Encoder 를 사용하는데, 이것은 d차원의 실수 벡터로 지문을 매핑하고 모든 M개의 지문에 대해서 인덱싱해서 우리가 retrieval에 사용할 수 있도록 한다. 실행될 때는 DPR은 또 다른 인코더 에 적용되며 이는 입력으로 받은 질문을 d 차원의 벡터로 매핑하고 질문 벡터와 가장 유사한 k개의 벡터를 검색한다. 우리는 질문과 지문의 유사도를 벡터 내적을 사용해 정의할 수 있다.
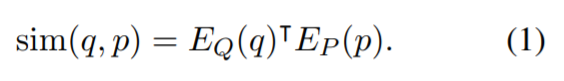
질문과 지문의 유사도를 측정하는데 있어서 cross attention를 사용하는 다층 레이어의 신경망 구성과 같은표현력이 더 좋은 모델들이 존재하지만, 지문의 임베딩 표현이 사전에 계산될 수 있도록 유사도 함수는 기능적으로 분해성이 있을 필요가 있다. 대부분의 분해성을 지닌 유사도 함수들은 유클리드 거리(L2)의 변형이다. 예를 들어 코사인은 단위 벡터들의 내적과 같으며 마할라노비스 거리는 변형된 공간에서의 L2 거리와 동일하다. 내적 탐색은 cosine이나 L2 distance와의 연관성뿐만 아니라 자체로도 넓게 사용되어왔고 연구되어 왔다. 우리의 ablation 실험은 다른 유사도 함수들도 비슷한 성능을 냈기 때문에 (이는 5.2장과 부록 B에 나온다) 우리는 더욱 간단한 내적 함수를 선택했고 이는 인코더가 더 잘 학습하게 함으로써 dnese passage retriever를 개선시켰다.
Enocders
비록 원칙적으로 질문과 지문 인코더는 어떠한 신경망으로도 구현될 수 있지만 여기서는 두개의 독립적인 버트 신경망을 사용한다. 또한 output으로 반환되는 CLS토큰을 임베딩 표현으로 취하며 차원은 768이다.
Inference
추론 기간동안 우리는 passage enocder Ep를 모든 지문에 적용하고 이 지문들을 FAISS를 사용해서 오프라인으로 인덱싱했다. FAISS는 엄청나게 효율적인 오픈 소스 라이브러리인데 이는 유사도 탐색이나 밀집 벡터의 군집화를 수행할 수있으며 이 때 매우 많은 수의 벡터도 쉽게 처리할 수 있다. 런타임에 질문 q가 주어지면 우리는 에 q를 입력해 임베딩 를 얻는다. 그리고 와 유사한 상위 k개의 지문을 탐색한다.
3.2 Training
내적을 이용한 유사도가 retrieval에 있어 좋은 랭킹 함수(항등식 1)가 되기 위해 인코더를 학습하는 것은 본질적으로 지표 학습 문제로 직결된다. 우리의 목표는 벡터 공간을 생성해서 더 좋은 임베딩 함수를 학습함으로써 질문과 지문쌍이 관련이 있다면(유사도가 높다면) 관련이 없는 쌍보다 더 적은 거리를 가지게 되도록 하는 것이다.
라고 m개의 인스턴스로 구성되어 있는 학습 데이터라고 하자. 각각의 인스턴스는 어떠한 질문 와 이와 관련된(=긍정) 지문 그리고 관련이 없는(=부정) n개의 지문 로 이루어져있다. 우리는 관련 지문의 NLL Loss를 사용해서 이를 최적화하려고 한다.
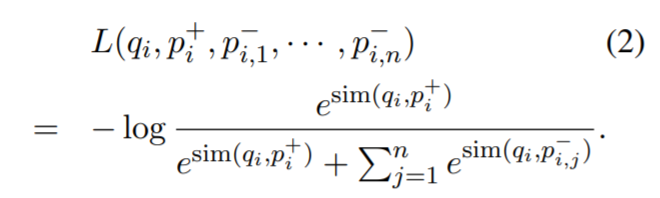
Positive and negative passages
retrieval의 문제라 함은 positive example은 명백하게 존재하면서, negative example은 매우 큰 데이터셋에서 선택되어야 한다는 것이다. 예를 들어, 질문과 관련이 있는 지문은 QA 데이터셋에서 주어지거나 정답을 사용해서 찾을 수 있다. 그 외의 데이터셋에 있는 모든 지문은 명확히 특정되지 않았으며 기본적으로 관련이 없는 것으로 보인다. 실제로 negative example을 선택하는 방법을 그렇게 중요하게 생각하지 않는데, 이는 인코더를 높은 품질로 학습하는데에 있어 영향력 있는 항목이다. 우리는 다음과 같은 3개의 negative type을 고려해야한다. (1) 무작위로 고르자 : 말뭉치에서 가져올 수 있는 무작위의 지문 (2) BM25를 사용하자 : BM25를 사용해 얻은 정답이 없는 상위 지문들은, 질문의 토큰들과 대부분 동일하다. (3) 학습 데이터에만 파묻혀있는 금(positive) : 질문과 관련이 있는 지문들은 학습 데이터에서 나타난다. 우리는 negative 지문들의 다른 유형에 따른 영향과 학습 계획을 5.2장에서 다룰 것이다. 우리의 대표 모델은 동일한 미니 배치에서 얻는 positive(=gold) passage와 BM25로 얻은 negative passage를 사용할 것이다. 특히 동일한 배치에서 gold(=positive) passage를 negative passage로 재사용하는 것은 좋은 성능을 얻으면서 계산을 효율적으로 할 수 있도록 한다. 우리는 이 접근법에 대해 아래에서 소개한다.
In-batch negatives
미니 배치에 B개의 질문이 있다고 하자. 각각의 질문은 유사도가 있는(=relavant) 한 지문과 관련이 있다고 하자. Q와 P를 질문과 지문의 B x d 크기의 임베딩 행렬이라고 하자. 이 때 B는 배치 사이즈이다. 행렬의 유사도 점수를 S라고 하자. 로 나타내지며 B x B의 크기의 행렬이다. 각각의 행은 B개의 지문과 쌍을 이루는 질문과 대응된다. 이 방법에서는 우리는 계산했던 것을 다시 사용함으로써 효율적으로 질문/지문 쌍을 각각의 배치에서 학습할 수 있다. i = j일때는 q와 p는 positive의 관계이며 그 외에는 negative의 관계이다. 이는 B-1개의 negative passage와 1개의 positive passage가 존재하는 각각의 배치에있는 B개의 학습 샘플들을 만든다.
(i, j)에서 사용했던 것을 (j, i)에서 또 사용할 수 있기 때문에 재사용성을 강조한다.
이러한 in-batch negatives 테크닉은 full batch에서 사용되어 왔으며 최근으로 올수록 mini-batch로 사용되고 있다. 이러한 방법은 이중 인코더 모델이 학습시 샘플의 수를 늘린다는 점에서 효과적인 전략으로 소개되어왔다.
4 Experimental Setup
이번 장에서는 우리가 실험에 사용한 데이터와 기본적인 설정에 대해 소개한다.
4.1 Wikipedia Data Pre-processing
우리는 영어 위키피디아를 QA task를 위한 기본 문서로 사용했다. 우린 먼저 DrQA에서 공개된 전처리 코드를 적용해 위키피디아의 기사로부터 깔끔한, 텍스트로 이루어진 데이터를 추출했다. 이 과정은 표나, 정보상자, 리스트, disambiguation pages같은 일부 구조적인 데이터를 제거했다. 이후, 각각의 기사를 100개의 단어로 이루어진 여러개의 텍스트 조각으로 나누었다. 이 텍스트 조각 하나를 지문이라고 간주했고 이는 우리의 기본적인 탐색 단위이다. 결국 21,015,324개의 passage로 분리했다. 각각의 지문에는 위키피디아 기사 제목이 추가되었으며(=prepen) 그 뒤는 SEP Token이 붙는다.
disambiguation pages는 non-article인 page로 article page를 쉽게 찾기 위한 목적으로써 reader들을 위해 마련된 page이다.
4.2 Question Answering Datasets
우리는 5개의 QA 데이터셋을 사용했고 학습, 검증, 시험 데이터로 분리했다. 아래에는 각각의 데이터셋을 간단하게 요약했고 독자들이 데이터 준비에 대한 상세한 부분을 참고할 수 있도록 했다.
Natural Question (NQ)
이 데이터셋은 END-TO-END QA를 위해 만들어져다. 질문은 실제 구글 검색 질문에서 모았고 답변은 글쓴이가 분명한 위키피디아 기사에서 발췌했다.
TriviaQA
이 데이터셋은 사소한 질문들과 답변으로 구성되어 있으며 웹 페이지에서 가져왔다.
WebQuestions (WQ)
이 데이터셋은 구글 제안 API에서 사용해 선택된 질문과, 이 API의 Freebase안에 개체로 존재하는 정답으로 구성되어 있다.
CuratedTREC (TREC)
TREC QA이나 다양한 웹의 출처를 가지고 있는 질문들은 구조화되어있지 않은 말뭉치로부터 OQDA task를 위해 준비되었다.
SQuAD v1.1
독해를 위한 유명한 벤치마크 데이터셋이다. 데이터셋 주석자들은 위키피디아 지문을 받고 주어진 지문으로 부터 답변이 가능한 질문을 작성하도록 요청받았다. 비록 SQuAD는 이전부터 ODQA 연구를 위한 데이터셋으로 사용되어 왔지만 이상적인 데이터는 아니다. 왜냐하면 많은 질문들은 제공된 문단이 없어서 지문이 부족했기 때문이다. 우리는 이전의 연구와 공정한 비교를 위해 여전히 우리 실험에서 SQuAD를 사용하며 이는 5.1장에서 다룰 것이다.
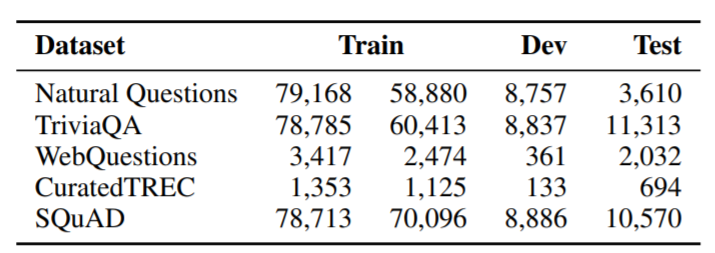
Table 1
각각의 QA 데이터셋에 존재하는 질문의 수이다. train의 두 개의 열은 원래의 학습 데이터의 수와 DPR학습을 위해 필터링 되고 남은 실제 질문들의 수를 나타낸다. 자세한 사항은 글을 참고해라.
Selection of positive passages
TREC와 WebQuestions 그리고 TriviaQA에서는 유일하게 질문-답변쌍만 제공하기 때문에 우리는 BM25로 만든, positive passage를 정답으로 가지고 있는 상위권 지문들을 사용한다. 100개의 검색된 지문 중 정답이 없다면 해당 질문은 버려진다. SQuAD와 NQ에서는 처음에 가지고 있는 지문들이 분리되고 우리가 후보 지문들을 관리하는 것과는 다르게 처리되기 때문에 우리는 각각의 gold 지문들을 그에 대응하는 지문들로 매칭하거나 교체한다. 다른 위키피디아 버전이거나 전처리 때문에 매칭이 실패했다면 우리는 이 질문을 버린다 표 1ㅇ데서는 질문의 훈련/검증/시험 데이터의 질문의 수를 보여준다. 이는 모든 데이터와 retriever 학습에 실제로 적용된 질문의 수를 나타낸다.
5 Experiments: Passage Retrieval
이번 장에서는 우리 DPR의 retrieval의 성능을 평가한다. 평가할 때는, 기존 Retrieval의 방법과는 output이 어떻게 다른지, 다른 학습 방식을 사용했을 때의 효과는 무엇인지, 실행 효율은은 어떤지를 고려한다.
우리 실험에서 사용되는 DPR 모델은 BM25를 이용해 얻은 negative passage들을 128의 batch size로 하는 in-batch negative를 설정해 학습한다. 우리는 지문, 질문 인코더를 NQ, TriviaQA, SQuAD와 같은 대형 데이터셋에 대해 40 에포크까지 학습했고 drop out 0.1과 warm-up을 사용한 선형 스케쥴링과 의 학습률을 사용하는 아담을 사용했다.
리트리버가 각각의 데이터셋에 학습할 때 유연함을 가져야 하는 것은 분명 좋지만, 전반적으로 잘 작동하는 단일 리트리버를 만드는 것도 역시 중요하다. 마지막으로, 우리는 SQuAD를 제외한 모든 데이터셋에서 부터 학습하는 다중 데이터셋을 인코더를 학습한다. 또한 DPR에서는 전통적인 방법인 BM25와 선형결합을 통해 새로운 점수 매김 방식을 이용한 BM25+DPR의 결과를 제시한다. 특히 우리는 BM25와 DPR을 각각 기준으로 한 상위 2천개의 시작 세팅을 구성했다. 그리고 BM25+DPR의 경우 를 랭킹 함수로 사용해서 이들을 다시 평가했다. 이 때 람다는 1.1을 사용했으며 이는 dev set에서 정확도를 기준으로 설정했다.
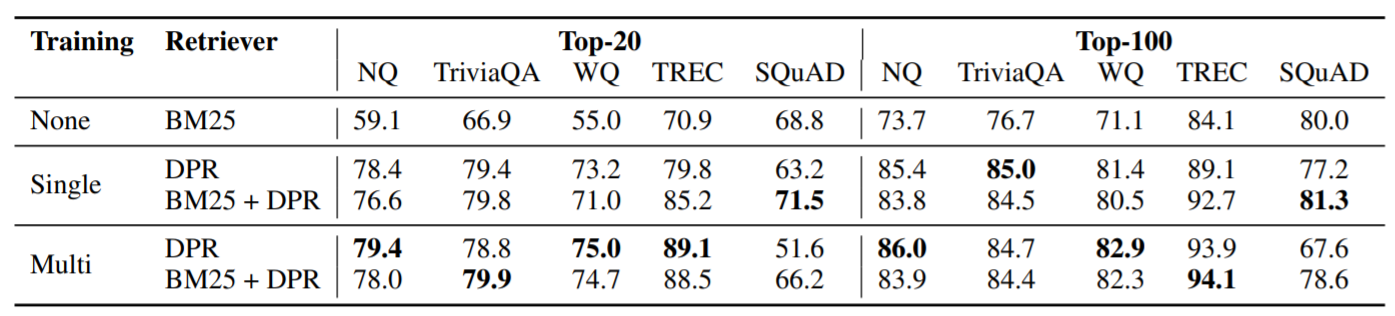
Table 2
테스트 셋에서 상위 20개와 상위 100개의 리트리버 정확도이다. 이는 지문에서 정답을 포함하고 있는 비율로 측정했다. 단일 그리고 다중의 의미는 DPR이 개별 dataset을 학습했냐 아니면 SQuAD를 제외한 모든 dataset을 학습했냐의 차이다. 자세한 것은 글을 읽기를 바란다.
5.1 Main Results
표 2는 다섯개의 QA 데이터셋에 대해 상위 k개의 정확도를 가지고 서로 다른 passage retrieval system 비교한다. SQuAD를 제외한 모든 데이터셋에서 DPR은 BM25보다 좋다. k가 커질수록 성능차이는 특히 커진다. (78.4 vs 59.1 for top-20 accuracy) 다중 데이터셋으로 학습할 때는 데이터셋 중 가장 작은 TREC가 제일 많은 성능을 냈다. NQ나 WQ는 아주 조금 성능이 올랐고 TriviaQA는 약간 감소했다. 이 결과들은 단일, 다중 데이터셋 세팅의 DPR와 BM25를 합치는 몇가지 경우에서 더 개선될 수 있다.
우리는, 두 가지 이유로 SQuAD에서 더 적은 성능을 낸 것이라 추측된다. 첫째, 검수자가 지문을 보고 질문을 작성했기 때문이다. 결과적으로 높은 어휘의 재사용이 질문과 지문내에서 있을 것이고 이는 BM25가 더 유리하게 결과를 내놓을 수 있게 된다. 둘째, 데이터는 500개 이상의 위키피디아 기사에서 모아졌는데, 사실 학습 데이터들은 Lee et al. (2019). 에서 이전에 주장한 것과 같이 극도로 편향되어 있다.
Figure 1
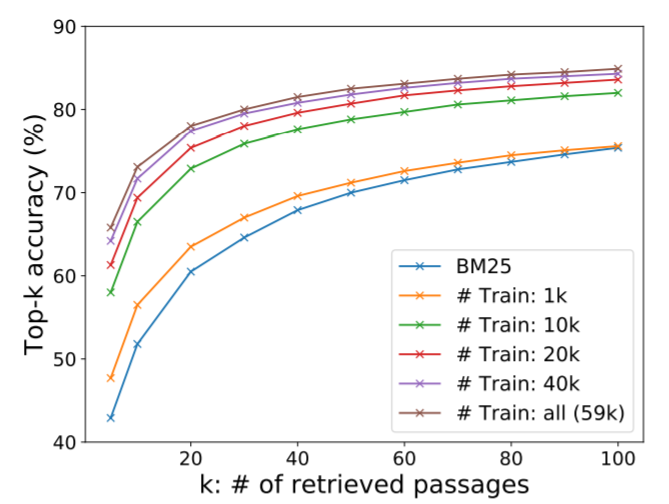
5.2 Ablation Study on Model Training
더 나아가 어떻게 모델의 설정들이 결과에 영향을 주는지 이해하기 위해 몇가지 추가적인 실험을 수행했고 이에 대한 결과를 아래에서 이야기하자.
Sample efficiency
좋은 지문 리트리버 성능을 가지려면 얼마나 많은 훈련 셋이 필요한지 알아보자. 그림 1은 상위 k개의 리트리버 정확도를 각각 다른 학습 셋의 수에 따라 보여준다. NQ의 dev set으로 측정했다. 본 바와 같이 DPR은 단지 1000개의 학습 데이터셋만 학습하더라도 이미 BM25를 압도한다. 이는 일반적으로 사전학습된 모델을 사용한다면, 적은 수의 데이터셋으로 고품질의 리트리버를 만들 수 있다는 것을 보여준다. 학습 셋의 수를 늘릴 수록 정확도는 계속 상승했다.
In-batch negative training
NA dev셋에 대해서 서로 다른 학습 방법을 테스트하고 이 결과를 표 3에 요약했다. 가장 위쪽 부분은 기본으로 사용하는 1 of N 학습 세팅이었다. 이 세팅은 한 배치에서 한 질문이 1개의 positive 지문과 n개의 negative 지문쌍으로 되어있는 것이다. 우리는 negative를 선택함에 있어, 무작위로 고를지, BM25로 고를지, 또는 gold방법을 쓸 지는 k가 20보다 크다면 딱히 상관없다는 것을 알았다.
중간 부분은 negative training의 관한 부분이다. 비슷한 설정에서 in batch nagative setting을 적용한 것이 안정적으로 성능을 높여주었다. gold와 in batch gold의 주된 차이는 negative passage가 같은 배치에서 오느냐 또는 전체 훈련 셋에서 오느냐의 차이다. 새로 만들기 보다는 기존에 이미 존재하는 배치를 nagative example로 재사용함으로써 효과적으로 in-batch negative 학습을 하는 것은 간단하며 메모리-절약적인 방법이다. 이 방법은 더 많은 쌍을 만들고 그래서 학습 샘플 수를 늘려주게되며 이는 곧 좋은 성능으로 연결된다. 결과적으로 정확도는 배치사이즈가 클수록 꾸준히 증가한다.
결국 우리는 in batch nagative 학습을 좀 더 어려운, BM25로 뽑은 negative 지문으로 해보기로 했다. 그치만 이 지문들은 (in batch negative의 passage들과 달리) answer를 가지고 있지는 않다. (아래쪽 부분) 이런 추가적인 지문들이 모든 질문들에 대해 사용되었다. 이 때 BM25의 negative를 2개 준다고 해서 성능이 늘어나지는 않았고 하나정도만 줘도 안정적인 결과를 주었다.
그래서 BM25로 만들어진 negative example들은 오로지 gold passage를 더 잘 학습하기 위한 목적만을 가지고 있다. 이 친구들은 answer가 없기 떄문에 따로 이 친구들에 대한 positive를 찾을 필요가 없다.
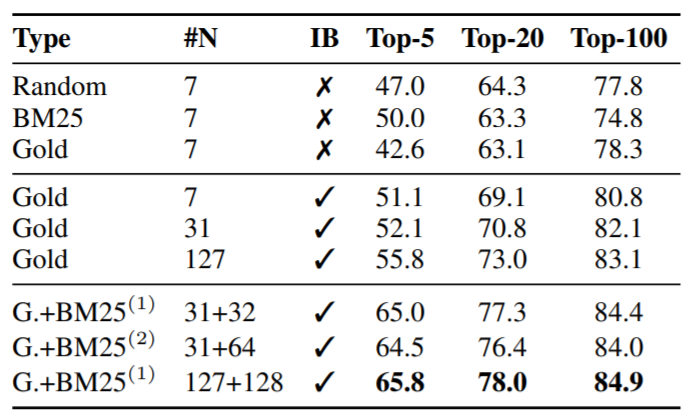
Table 3
서로 다른 학습 방법을 NQ 데이터셋에 대한 상위 k개의 리트리버 정확도를 가지고 측정해 비교했다. #N은 negative sample의 개수이며 IB는 in batch training을 의미한다. G+BM25(1)과 G+BM25(2)에서 기존 Gold에서 nagative sample을 각각의 질문을 기준으로 1개 또는 2개를 추가한 것을 의미한다.
Impact of gold passages
우리는 기존 dataset에 존재하는 gold contexts에 해당하는 지문들을 사용했다. NQ에서 우리의 실험은 disantly-supervised된 passage로 바꾸는 것은 (BM25로 뽑은 높은 순위의, 답을 가지고 있는 지문들을 사용해서) 적은 영향력(top-k 정확도에 대해 1점이 낮아진다)이 있었다. 부록 A에서 자세히 설명한다.
Similarity and loss
6 Experiments: Question Answering
7 Related Work
8 Conclusion
우리 연구에서, dense retrieval이 더 좋고, ODQA에서 sparse tretrieval을 대체할 수 있는 가능성이 있다는 것을 증명했다. 간단한 이중 인코더 접근법은 매우 잘 동작했던 반면에, 이를 성공적으로 수행하기 위해서는 dense를 학습하기 위한 중요한 재료들이 준비되어야 한다. 게다가, 우리의 경험적인 분석과 특징 제거 연구는 모델 구조가 더 복잡해 질수록 유다
