CKA
1.ETCD In Kubernetes

key-value store클러스터에 관한 정보를 저장하는 공간Nodes, Pods, Configs, Secrets, Accounts, Roles, Bindings, Otherskubectl 을 실행할때 얻는 모든 정보는 etcd 서버 참조작업시 (Node 추가, Po
2.etcd command

(Optional) ETCDCTL 유틸리티에 대한 추가 정보ETCDCTL은 ETCD와 상호작용하는 데 사용되는 CLI 도구입니다.ETCDCTL은 버전 2와 버전 3의 두 가지 API 버전을 사용하여 ETCD 서버와 상호 작용할 수 있습니다. 기본적으로 버전 2를 사용하
3.kube-Apiserver

쿠버네티스의 주요 관리 구성 요소kubectl 사용시 명령어가 kube-apiserver에 도달kubeadm이 먼저 요청을 인증하고 유효성을 확인이후 etcd-cluster에서 데이터를 조회해 요청된 정보로 응답Authenticate User⬇️Validate Requ
4.Kube Controller Manager

노드나 컨테이너의 생성과 삭제를 관리노드의 상태를 감시한다상황을 재조정하기 위해 필요한 조치를 취한다쿠버네티스 컨트롤러 매니저는 시스템 내 다양한 구성 요소(컴포넌트)의 상태를 지속적으로 모니터링하고 시스템 전체를 원하는 기능 상태로 만든다watch Status⬇️Re
5.Kube Scheduler

scheduler는 어떤 Pod가 어느 Node에 들어갈지 결정Pod를 Node에 직접 배치하는것이 아님 👉 kubelet의 역할scheduler가 특정 기준에 따라 어느 node에 배치할지 결정예를들어 리소스 요구 사항이 다른 Pod가 있을 수 있음특정 응용 프로그
6.Kubelet

마스터노드에서의 유일한 연락망스케줄러와 협업하여 워커노드에 컨테이너를 생성Pod와 컨테이너의 상태를 일정 간격으로 모니터링 및 kube-apiserver에 보고쿠버네티스의 클러스터의 한 구성원으로 등록이 된후 노드에 컨테이너 또는 Pod를 로드하라는 짓시를 받으면 컨테
7.Kube-proxy

Pod Networking solution을 클러스터에 배포함으로써 서로 Pod끼리 서로 통신 가능하게 함Pod Network는 내부 가상 네트워크로 모든 Pod가 연결되는 클러스터 내 모든 Node에 연결되어 있음이 네트워크를 통해 서로 통신 할 수 있음이 경우 사용
8.Pods

✅ 전제사항1\. Docker Image2\. Kubernetes ClusterDocker Image 를 Docker hub pull 할 수있는 런타임과 클러스터가 구성되어 있어야 함싱글 노드 든 멀티 노드든 셋업이 되어있어야함컨테이너 형태로 노드로 구성된 Cluste
9.Pod with YAML

K8S YAML 파일은 Pods, Replications, Deployment 등 오브젝트 생성을 위한 입력으로 사용항상 상위에 4개의 field를 포함한다 (Root Level Property) 루트 레벨 속성필수 필드이니 반드시 구성 파일에 있어야 한다.이 개체(Y
10.ReplicaSets

쿠버네티스를 지속적으로 모니터링하며 이에 따라 반응 하는 API어떤 이유에서든 앱이 다운되고 Pod가 고장나면 사용자들이 액세스 할 수 없게 된다.사용자가 앱에 대한 액세스를 잃지 않도록 하려면 한 개 이상의 인스턴스나 Pod가 동시에 실행되어야 한다.복제 컨트롤러는
11.Deployments

제품 환경에서 응용 프로그램을 배포하기 위한 Controller웹서버가 운영환경에서 배포 되어야 함한 개가 아니라 여러 개의 웹 서버 인스턴스가 실행됨Docker Hub에 새로운 버전의 응용 프로그램이 상용화 될때 무중단 배포한번에 전체 인스턴스를 업그레이드 하는게 아
12.Service - NodePort

앱 안팎의 다양한 구성요소의 통신을 가능하게 함애플리케이션을 다른 애플리케이션 또는 사용자와 연결하는것을 도움응용 프로그램에는 다양한 Pod가 존재함사용자에게 프론트엔드 로드를 제공하기 위한 그룹, 백엔드를 제공하기 위한 그룹, 외부 데이터 소스에 연결하는 그룹 등이
13.Service - ClusterIP

📌 ClusterIP 풀 스택 웹 애플리케이션은 계층별(프론트앤드, 백앤드, 데이터베이스)를 호스팅하는 Pod들이 존재 프론트앤드는 백앤드와 통신하기 원하고 백앤드 서버는 데이터베이스와 통신하길 원함 앱의 이런 서비스 또는 계층을 연결하는 올바른 방법은? 💬 Po
14.Service - LoadBalancer

NodePort Service를 통해 Worker Node에서 외부 접근이 가능함이해할수 없음 추후 실제 구현후 재작성 요망
15.Namespace

클러스터에 pod, service, deployment 같은 개체를 생성할 수 있었다.K8S에 논리적인 클러스터 구성하는것이 Namespace쿠버네티스가 자동으로 생성하는 Namespace : kube-system : 네트워킹 솔루션, DNS 서비스에 관한 네임스페이스
16.Imperative vs Declarative

IaC 환경에서는 인프라 관리시 명령형, 선언형 등의 접근법이 있다.인프라를 요구에 정확히 어떻게 적용할지 명령하고 있음항상 replace 명령으로 이미 생성된 Pod인지 확인하고create 명령으로 중복된 Pod 인지 확인해야 한다.이는 관리자에게 까다롭다.ansib
17.Manual Scheduling(nodeName)

node 위에 Pod를 수동으로 스케쥴링 하는법클러스터에 Scheduler가 없는 경우 수동으로 직접 스케쥴링nodeName 필드는 default로 설정되어 있지 않음스케쥴러는 모든 pod를 살펴보고 이 필드가 없는 pod를 찾음이후 스케줄러 알고리즘을 통해 올바른 노
18.Labels and Selectors

개체들을 그룹으로 묶는 표준 방법자신의 기준에 근거해 필터링 하기 위함위 예시와 같이 labels은 key: value 로 생성한다.주로 metadata 필드 아래 labels 필드를 작성하고 자식 필드에 작성한다.labels는 원하는 만큼 붙일 수 있다.주석으로 달아
19.Taints and Tolerations

pod와 node의 관계에 대해한 노드에 어떤 pod로 스케줄링할 수 있는지 제한을 설정하기 위해 사용kubectl taint node node01 app=blue:NoSchedule 명령어에서 key, operator, value, NoSchedule 필드를 채워준다
20.Node Selectors and Node Affinity

pod가 특정 노드에서만 작동하도록 한계를 설정해야 한다.예를 들어 1, 2, 3 번 노드 중 리소스 요구사항이 큰 pod는 가장 큰 노드로 배치되어야 한다.두 가지 방법node Selector여기서 size 필드는 사실 key-value로 이루어진 labels 이다.
21.Resource Requirements and Limits

스케줄러는 각 node에 배치될 pod의 요구되는 리소스를, 그리고 노드의 허용 가능한 리소스를 고려한다이후 pod를 설치할 최고의 node를 식별한다.만약 노드의 리소스에 여유가 없다면 해당 노드를 피하여 충분한 리소스 사용이 가능한 노드에 설치한다.만약 노드 리소스
22.Static Pods

📌 Static Pods kubelet 은 kube-apiserver에 의존해 노드에서 로드할 pod에대한 지시를 받음 이는 kube-scheduler의 결정에 근거한 것으로 etcd-cluster(데이터 저장소)에 저장됨 만약 kube-apiserver 나 kube
23.Priority Classes

K8S는 서로 다른 우선순위를 가진 다양한 애플리케이션을 파드로 실행한다예를들면, control plane의 구성요소들은 항상 실행되어야 하며 DB나 Critical Apps 등 우선 순위가 높은 워크로드, jobs 등 낮은 우선순위의 워크로드가 있을 수 있다.때문에,
24.Multiple Scheduler

taint, tolerance, node affinity 등 스케줄러의 동작 원리를 알고 있다 하지만 조건을 만족하는 노드가 없다면? 👉 다른 조건을 찾는 스케줄러를 만들 수 있다.고유의 스케줄링 알고리즘으로 노드에 파드를 추가고유의 사용자 지정 조건을 추가하고 파드
25.Scheduler Profile
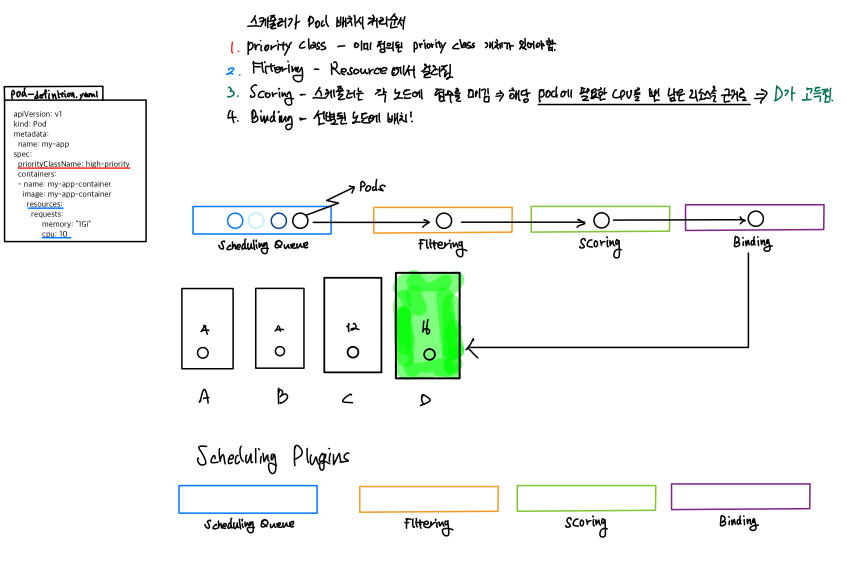
📌 Scheduler Profile
26.Admission Controllers

kubectl 명령어 CLI로 입력Kube-ApiServer를 경유Pod 생성Etcd-cluster (DB에 정보 저장)요청이 API 서버에 도달하면 인증 프로세스를 거침인증서를 통해 이루어짐kubectl을 통해 요청이 전송된 경우 kube-config 파일에 인증서가
27.Validating & Mutating Admission Controllers

객체가 생성되기 전에 객체 자체를 변경하거나 변형할 수 있다.요청을 변경할 수 있는 admission controller이다.NamespaceAutoProvision 플러그인이 대표적인 예시요청의 유효성을 검사하여 허용 또는 거부 할 수 있는 admission cont
28.Monitor Cluster Components

각 노드에서 정상 파드 개수성능지표(CPU, Memory)네트워크와 디스크 활용도 등Metric Server, Prometheus, Elastic Stack, Data Dog, dynatrace위와같은 독점 솔루션 존재Heapster : 초기 쿠버네티스 모니터링 툴Me
29.Application Logs
위와 같은 Docker image가 있는 pod를 생성 (definition 파일 즉, yaml 파일을 사용해서)이 로그는 포드 내부의 컨테이너 로그이다.쿠버네티스는 여러개의 도커 컨테이너를 실을 수 있다.\-pod에 여러개의 컨테이너가 있다면 명령에 컨테이너 이름을
30.Deployment - Updates and Rollback

!\[]Deployment에 일어난 변화를 추적할 수 있다.필요하면 이전 버전으로 되돌릴 수 있게 해준다위 명령어를 통해 rollout status 조회 가능두 가지 유형의 배포 전략이 있다.Recreate : 실행중인 인스턴스를 모두 종료하고 새 버전으로 배포서비스
31.Application Command
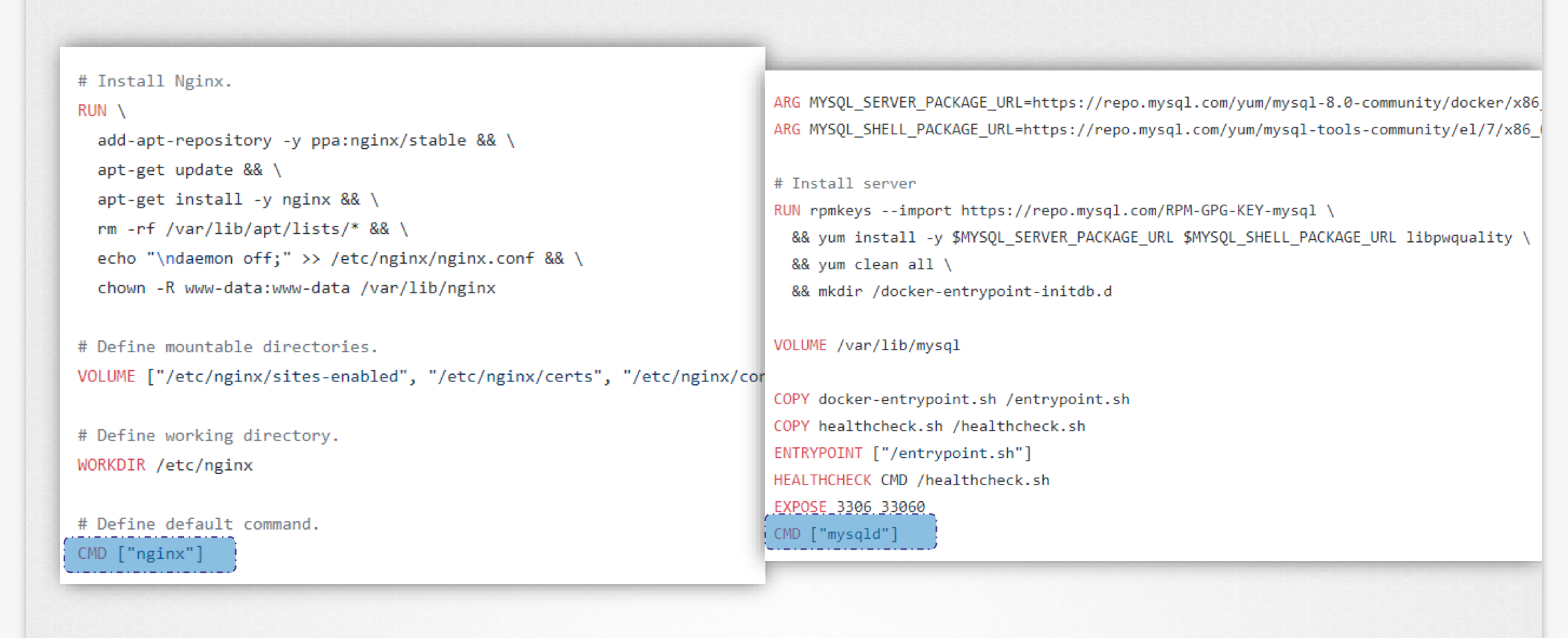
Docker Image로 ubuntu 컨테이너 운용실행하자마자 즉시 증료된다위 명령어로 실행중인 컨테이너를 출력시 아무것도 보이지 않는다새 컨테이너가 종료 상태로 보인다가상 컴퓨터와 달리 컨테이너는 OS를 호스팅하도록 되어 있지 않다컨테이너는 특정 작업이나 프로세스를
32.Commands and Arguments
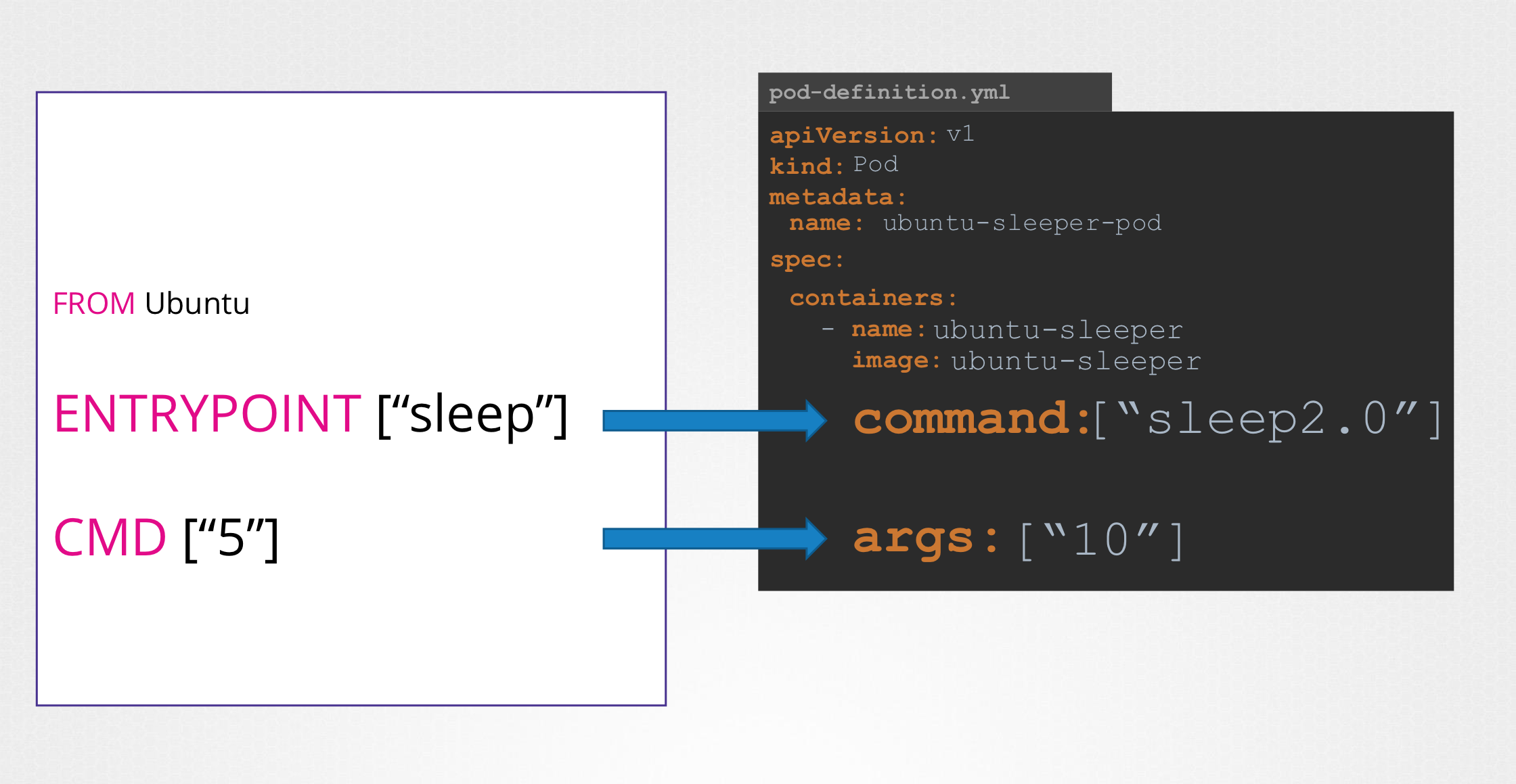
기본적으로 5초 슬립 하지만 CLI 로 인수를 전달하여 동작을 재정의 할 수 있었음(이전 포스팅 참고)이 이미지를 pod로 생성args 필드에 인수 전달, 배열의 형태로 전달한다.Dockerfile CMD 필드에 전달하는 인수를 재정의한다. (아래 예시 참조)ENTRY
33.Configure Environment Variables
Plain Key ValueConfigMapSecrets
34.Configure Secrets in Applications

password or key 같은 민감한 정보를 저장하는데 사용인코딩된 형식으로 저장된다는 점만 빼면 configMap과 동일Create Secret (시크릿 생성)Inject into Pod(파드에 적용)Imperative - (CLI: definition 파일을 사
35.Encrypting Confidential Data at Rest

💬 https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/hexdump를 추가하지 않았을때 (간혹 올바른 형식으로 보이지 않아서)위에 보이는 이것이 etcd에 저장되는 데이터자세히 보면 secre
36.Init Container

멀티 컨테이너 파드에서는 각 컨테이너가 파드의 수명 동안 계속 실행되는 프로세스를 담당하는 것이 일반적입니다. 예를 들어 앞서 언급한 웹 애플리케이션과 로깅 에이전트를 포함하는 멀티 컨테이너 파드에서는, 두 컨테이너 모두 항상 실행 상태를 유지해야 합니다. 로깅 에이전
37.Auto scaling
Vertical Scale Horizontal Scale전통적인 인프라에서 CPU, Memory(리소스)의 확장전통적인 인프라에서 서버(또는 노드)의 확장Horizontal Pod Autoscaler (HPA)Vertical Pod Autoscaler (VPA)CPU
38.In-place Resize of Pods

✍🏻 In-place Resize of Pod Resources 만약 pod의 리소스 요구사항 변경시 기존 파드를 삭제한 다음 새 변경 사항이 포함된 새 파드를 다시 생성하는 것(default)
39.Vertical Pod Autoscaling (VPA)

(수동 리소스 확장 방법)위 명령어로 리소스 소비 모니터링이를 위해 메트릭 서버가 실행 중이어야 한다특정 임계값에 도달하면 pod를 수직 확장을 위해 아래 예시이후 resource 아래 requests와 limits 필드를 변경하고 저장해당 pod가 죽고 새 pod가
40.Operating System Upgrade

유지보수 목적으로 노드를 제거해야 하는 시나리오에 관해 논의소프트웨어 기반 업그레이드나 패치 적용, 보안 패치등을 클러스터에 적용할 때노드가 5분 이상 다운되면 죽은것으로 간주하고 pod가 해당 노드에서 종료되고 ReplicaSet 에 소속되어 있다면 다른 노드에 재현
41.Kubernetes Software Versions

K8S 클러스터 설치시 특정 버전의 쿠버네티스를 설치kubectl get node 명령으로 버전을 확인 할 수 있음K8S의 버전은 세 부분으로 나뉜다Minor : Features, FunctionalitiesPatch : Bug Fixesalpha 릴리스에선 기본값으로
42.Cluster Upgrade Process
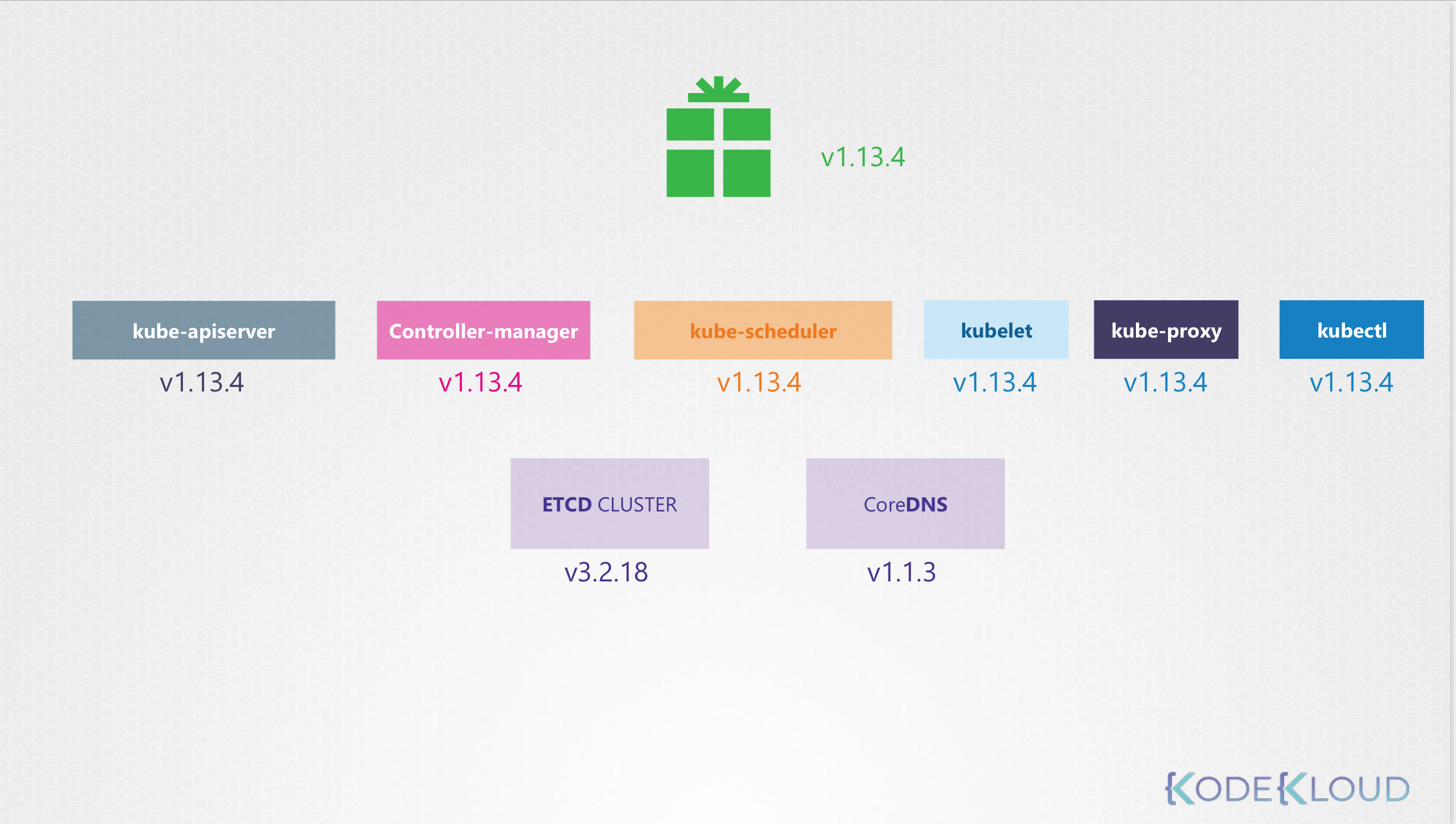
쿠버네티스가 소프트웨어 릴리스 관리 방법과 구성 요소 마다 버전이 다른것을 알아봤다.ETCD, CoreDNS 는 외부 구성요소에 의존Controlplane의 구성요소에 주목하자출처 : kodekloud그렇지 않다. 다른 릴리스로 갈 수있다 하지만 다른 어떤 구성 요소도
43.Backup and Restore Methods

쿠버네티스 리소스를 생성할때 (네임스페이스나 시크릿 configmap 등) 명령적 방법으로 개체 생성구성을 저장하고 싶을때 권장되는 방법모든 단일 응용프로그램에 필요한 개체 정의가 존재파일형식으로 단일 폴더에 있다나중에 재사용하거나 타인과 공유 가능GitHub같은 소스
44.Security Primities (보안 우선 순위)

클러스터 자체를 형성하는 호스트부터 보자호스트에 대한 모든 액세스는 보안 되어야 한다루트 액세스 해제암호 기반 인증 해제SSH 키 기반 인증만 사용 가능물론 호스트 하는 물리 또는 가상 인프라를 보호하기 위해 필요한 다른 수단도 있음쿠버네티스 중심에는 kube-apis
45.Authentication(인증)

쿠버네테스 클러스터는 다중 노드와 물리적, 가상적, 그리고 다양한 구성 요소로 함께 작동하는 구성 요소로 구성됨관리자인 유저는 관리 업무를 수행하기 위해 클러스터에 엑세스 개발자는 앱을 테스트하거나 배포하기 위해 클러스터에 엑세스클러스터에 배포된 응용 프로그램에 액세스
46.TLS Certificates (PRE-REQ)
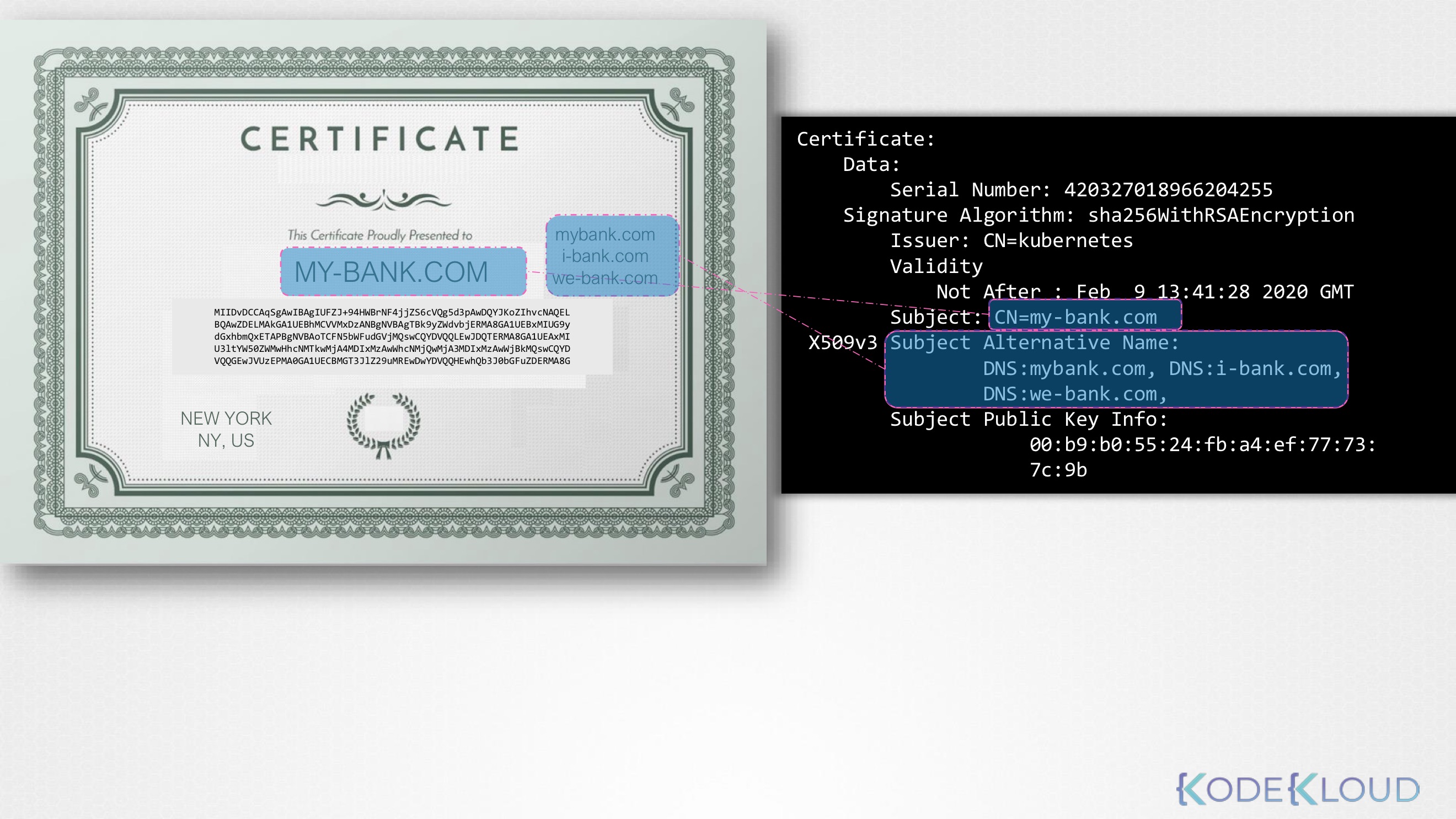
📌 목표 > 👉🏻 SSL TLS 인증서가 무엇인지에 대해 기본을 알아보고 그게 왜 필요한지 SSH나 웹 서버 보안을 위한 인증서 구성법 습득 ❓ 인증서란 무엇인가 * 인증서는 거래 도중 상호 신뢰를 보장하기 위해 사용* 사용자가 웹 서버에 액세스 하려 할때
47.TLS in Kubernetes
1). 서버의 공개키는 TLS 인증서에 포함되어 브라우저로 전달됨2). 브라우저는 이 공개키를 사용하여 '비밀정보(세션 키 등)'를 암호화함3). 서버는 자신의 '개인키'로 복호화하여 그 비밀정보를 읽음📌 이 과정은 브라우저 → 서버 방향의 데이터 전송에서만 비대칭키
48.TLS in Kubernetes - Certificate Creation

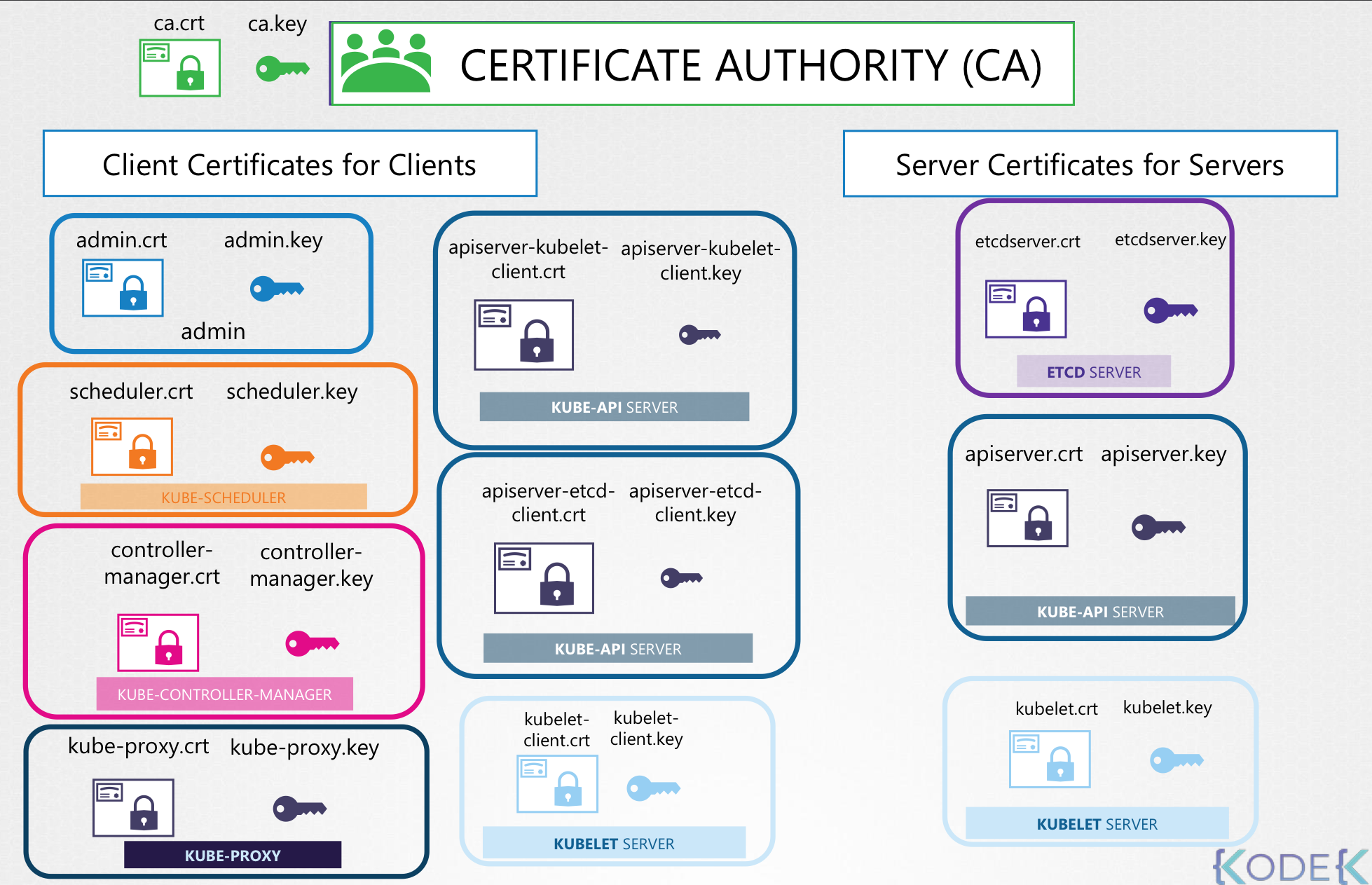
인증서를 생성하기 위한 도구로는 Easy-RSA, OpenSSL, CFSSL 등 다양한 도구들이 있다.예제 에서는 OpenSSL을 사용해서 인증서를 생성.먼저, 클러스터의 CA(Certificate Authority) 인증서를 생성.OpenSSL로 CA의 개인 키 생성
49.View Certificate Details
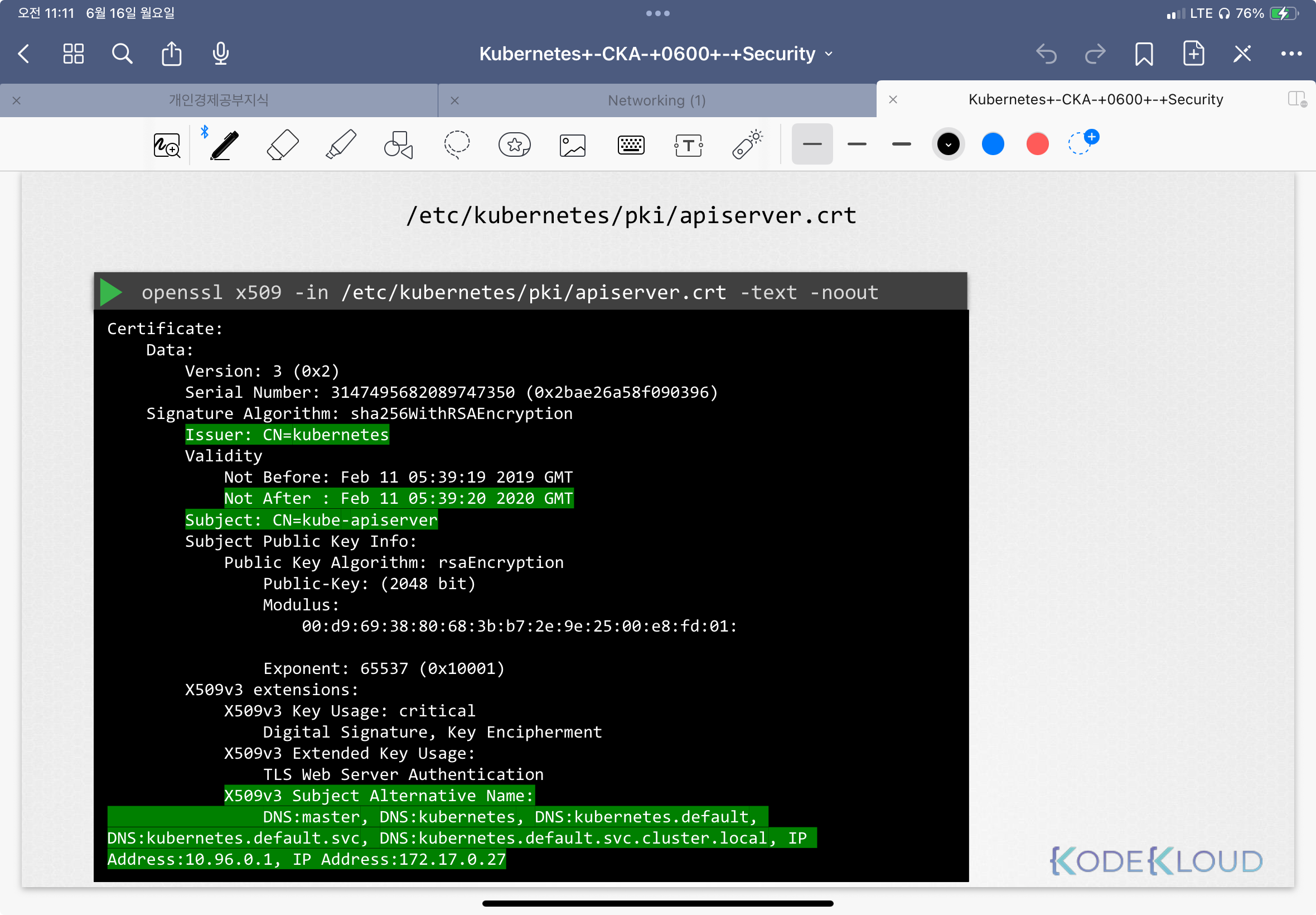
클러스터 전체 인증서 상태 확인 요청을 받았다고 가정클러스터가 어떻게 설정됐는지 확인kubeadm (자동 프로비저닝 툴)“The Hard Way”서비스 배포시 kubeadm 툴은 pod로 배포함어디를 보고 올바른 정보를 봐야하는지 아는게 중요사용되는 모든 인증서를 확인
50.Certificates API
Kubernetes 환경에서 인증서를 어떻게 관리하는지, 그리고 Certificate API의 역할에 대한 설명.Kubernetes 클러스터에서 인증 기반 접근을 위해 CA 서버 및 인증서 사용관리자는 클러스터 초기 설정 시 CA 키 쌍과 각 컴포넌트별 인증서 구성사용
51.kubeconfig
🔐 Kubernetes Kubeconfig Kubeconfig는 kubectl이 Kubernetes 클러스터와 통신하는 핵심 설정 파일 Kubeconfig의 구조와 사용법을 단계별로 정리 📄 Kubeconfig 소개 클라이언트 인증을 위해 사용자가 생성한 인증
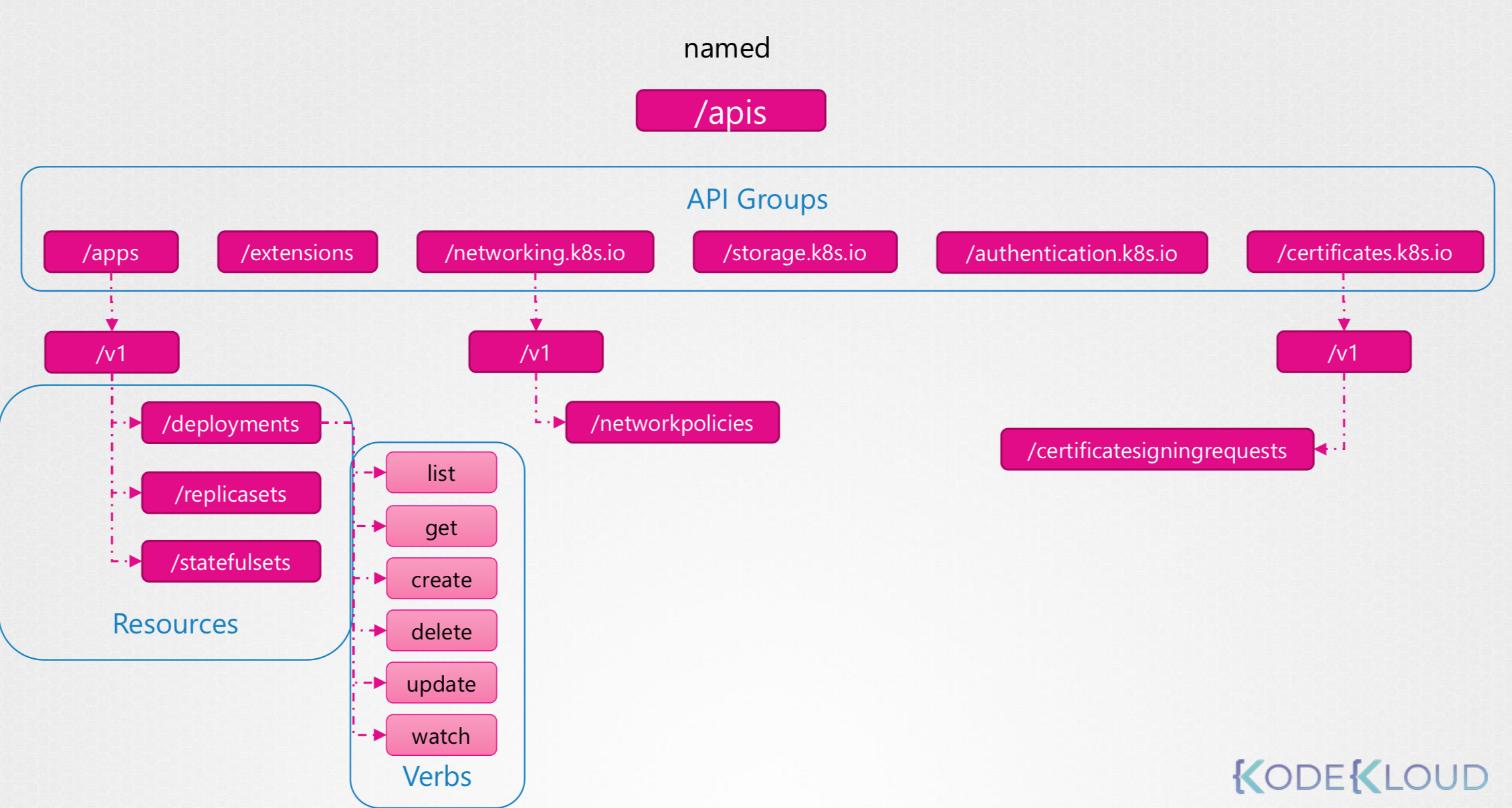
52.API Groups
53.Authorization

\*\*인증(Authentication)\*\*은 누가 접근했는지를 확인하는 절차\*\*권한(Authorization)\*\*은 무엇을 할 수 있는지를 제한하는 정책사용자가 인증을 통해 클러스터에 접근한 후, 허용된 작업 범위를 결정하는 것이 권한 관리의 핵심관리자 계
54.Role-Based Access Control (RBAC)

좋습니다. 아래는 요청하신 내용에 따라 구성한 정중한 문어체, 명사형 끝맺음, 코드 블록 구성, 큰 제목에 이모지, 세부 항목은 하이픈으로 구분한 쿠버네티스 RBAC 교육자료 스타일 번역본입니다.RBAC 설정의 시작은 Role 오브젝트 생성정의 파일 생성 시 사용되는
55.Cluster Roles and Role Bindings

Role과 RoleBinding은 네임스페이스 범위 리소스에 대한 권한 제어에 사용ClusterRole과 ClusterRoleBinding은 클러스터 범위 리소스에 대한 권한 제어에 사용네임스페이스를 지정하지 않으면 Role은 default 네임스페이스에 생성Node,
56.Service Accounts

Kubernetes에서는 User Account와 Service Account 두 가지 계정 유형 존재User Account: 사람(관리자, 개발자 등)이 클러스터에 접근하기 위한 계정Service Account: 애플리케이션이나 서비스가 클러스터와 상호작용할 수 있도
57.Image Security
물론이지. 아래는 강의 내용을 한국어로 번역하고, 요청한 형식(대주제 이모지, 세부내용 대시 구분, 코드 박스 처리)을 모두 반영한 블로그 스타일의 정리본이야.Kubernetes Pod에서 사용하는 컨테이너 이미지는 Docker 이미지 네이밍 규칙을 따름예: nginx
58.Security in Docker

Kubernetes의 SecurityContext를 이해하기 전에, Docker에서의 보안 개념을 먼저 알아두는 것이 유익함.Docker가 설치된 호스트에는 OS 프로세스, Docker 데몬, SSH 서버 등이 실행 중Docker 컨테이너는 호스트와 커널을 공유하지만,
59.Security Contexts

Kubernetes에서 컨테이너 보안 설정(SecurityContext) 은 Docker의 보안 기능(사용자 ID, Linux Capabilities 등)을 기반으로 구성됨.Pod 또는 Container 단위로 설정 가능하며, Container 수준의 설정이 Pod 설
60.Network Policies

Pod 간 트래픽을 제어하는 강력한 보안 기능Ingress: 외부에서 들어오는 트래픽Egress: 내부에서 나가는 트래픽예:웹서버 → API 서버 → DB포트: 80 (웹), 5000 (API), 3306 (DB)모든 Pod는 기본적으로 서로 통신 가능추가 설정 없이도
61.Network Policy (2)

🎯 목표: DB Pod를 보호하고, 오직 prod 네임스페이스의 API Pod만이 3306 포트로 접근 가능하도록 설정podSelector: DB Pod에만 정책 적용policyTypes: Ingress만 설정해 "들어오는 트래픽"만 제어from: role=api인
62.Kubectx and Kubens – Command line Utilities

✅ kubectl config use-context 또는 kubectl -n \[namespace] 입력하는 게 번거롭다면?👉 kubectx와 kubens로 빠르고 정확하게 전환 가능!e여러 클러스터 간 context 전환을 간단하게 처리kubectl config 명
63.Custom Resource Definition (CRD)

⚠️ 아직 이 상태에선 Kubernetes는 FlightTicket이라는 리소스가 무엇인지 모름.이제 kubectl get flighttickets 같은 명령으로 리소스를 다룰 수 있음.CRD만 등록하면, 리소스를 생성하고 저장할 수 있음하지만 실제로 외부 API 호출
64.Custom Controller

CRD를 만들면 kubectl get, kubectl create 등으로 Custom Resource 객체는 다룰 수 있음하지만 이 객체를 실제 동작으로 연결하려면 로직이 필요함이 동작(예: 외부 API 호출, 리소스 생성 등)을 담당하는 것이 Custom Contro
65.Operator Framework

"Operator = Custom Resource + Custom Controller + 패키징 및 자동화 도구"사람이 애플리케이션을 운영하는 방식(설치, 구성, 백업, 복구 등)을 자동화한 것쿠버네티스 내부 논리로 애플리케이션의 생명주기를 관리하게 해줌대표적인 예:
66.Storage in Docker

Docker가 데이터를 저장하는 기본 위치:주요 디렉토리:containers/: 컨테이너 관련 파일image/: 이미지 관련 데이터volumes/: 생성된 볼륨 데이터overlay2/, aufs/, btrfs/: 저장 드라이버 별 디렉토리Dockerfile의 각 명령어
67.Volume Driver Plugins in Docker

기본 드라이버: local볼륨은 다음 위치에 생성됨:컨테이너가 삭제되어도 데이터는 유지서드파티 볼륨 드라이버를 통해 클라우드, 네트워크 스토리지 등 외부에 저장소를 구성할 수 있음.이 경우, EBS 볼륨이 자동으로 프로비저닝되고 컨테이너에 연결됨컨테이너가 종료되어도,
68.Container Storage Interface

기존에는 쿠버네티스가 Docker에 의존적이었고, Docker와 통신하는 코드가 Kubernetes 내부에 하드코딩되어 있었음.이 구조는 아래 문제를 발생시킴:❌ 새로운 컨테이너 런타임(CRI-O, containerd 등) 을 지원하기 어려움❌ 새로운 스토리지 솔루션을
69.Volume

Docker 컨테이너는 휘발성(transient) → 컨테이너가 삭제되면 내부 데이터도 삭제됨데이터를 영속적(persistent) 으로 저장하려면 Volume을 컨테이너에 마운트이 Volume은 컨테이너가 죽어도 데이터를 보존함Pod가 종료되면 안에 있던 데이터도 사라
70.Persistent Volume

좋아 Sangmin, 이번 강의는 Kubernetes의 Persistent Volume(PV) 개념과 목적을 중심으로 설명하고 있어. 핵심 내용을 정리하고, 실제 환경에서 어떻게 쓰이는지 개념도를 함께 설명할게.모든 Pod에 스토리지 구성 정보를 직접 작성해야 함Pod
71.Persistent Volume Claims

사용자(User) 가 Persistent Volume(PV) 중에서 원하는 조건의 스토리지를 "요청(Claim)"하기 위한 객체사용자는 StorageClass, AccessMode, 용량만 명시하면 됨PVC가 PV와 바인딩 되려면 아래 조건이 모두 충족되어야 함:작은
72.CoreDNS
경량화된 DNS 서버Go 언어로 작성플러그인 기반 아키텍처Kubernetes 클러스터의 기본 DNS 서비스로 사용됨CoreDNS 바이너리 다운로드실행 파일 확인DNS 서버 실행기본 포트 53(UDP/TCP) 로 실행됨/etc/hosts 파일을 참조해 내부 도메인 이름
73.Network Namespace
하나의 리눅스 호스트 안에서 독립된 네트워크 스택을 제공컨테이너(도커, 쿠버네티스)가 네트워크를 격리하는 기술의 핵심각 네임스페이스는 자신의 네트워크 인터페이스, 라우팅 테이블, ARP 테이블을 가짐🏠 Host = 집🚪 Namespace = 방각 방(네임스페이스)은
74.Docker Networking
Docker 설치 시 자동으로 bridge network (docker0) 생성브릿지 네트워크 IP: 172.17.0.1/16컨테이너 생성 시:network namespace 생성veth pair 생성한쪽은 컨테이너에 연결다른쪽은 docker0 브릿지에 연결컨테이너는
75.CNI
컨테이너 네트워킹은 모두 비슷한 방식으로 동작한다.네임스페이스 생성가상 인터페이스(veth) 생성브릿지 연결IP 할당 및 라우팅 설정NAT 적용Docker, Rocket, Mesos, Kubernetes 등 각 플랫폼이 제각기 네트워킹 로직을 따로 구현👉 "같은 걸
76.Cluster Networking
✅ Master Node (Control Plane)✅ Worker Node (Data Plane)모든 노드는 최소 1개 이상의 네트워크 인터페이스 필요각 인터페이스는 고유한 IP 주소 필요각 노드는 고유한 Hostname 및 MAC Address 필요👉 클론 VM
77.Pod Networking
노드 간 네트워크는 이미 설정 완료하지만 Pod 간 통신 네트워크는 별도 레이어→ Kubernetes는 Pod Networking을 직접 제공하지 않는다. → 반드시 CNI 플러그인으로 구현 필요각 Pod는 고유한 IP를 가진다.같은 노드 안의 Pod는 IP로 직접 통
78.CNI in kubernetes
\*\*CNI (Container Network Interface)\*\*는 컨테이너 네트워크 설정을 위한 표준 인터페이스Kubernetes는 직접 네트워크를 설정하지 않는다.대신, \*\*Container Runtime (예: containerd, CRI-O)\*\*
79.CNI - Weave
Weave Cloud가 2022년 12월부로 서비스 종료됨기존 설치 URL 더 이상 동작하지 않음🔗 공식 블로그:https://www.weave.works/blog/weave-cloud-end-of-service더 이상 작동 ❌→ 안정적이고 지속적으로 지원되
80.CNI - Weave (2)
Weave는 분산 네트워크 오버레이 솔루션각 노드에 에이전트(Weave Peer)를 설치 → 서로 통신하여 전체 클러스터의 Pod 네트워크 상태를 동기화Pod 간 통신을 위해 VXLAN 기반 터널링 + 캡슐화(Encapsulation) 사용각 노드에 weave라는 브릿
81.IPAM(IP Address Management) - CNI
Pod에게 고유한 IP를 할당하고, 중복 없이 관리하는 시스템노드(Node)의 물리적 IP는 IPAM 대상 아님Pod 내부 네트워크의 가상 IP 관리가 목적→ Kubernetes 자체는 IP 관리하지 않음→ CNI 플러그인이 전적으로 담당각 Node에서 로컬 파일 시스
82.Service Networking
Pod는 수명 주기가 짧음 → 삭제/재생성 시 IP가 변경됨특정 Pod를 직접 IP로 접근하면 불안정→ Service가 중간 프록시 역할Kubernetes가 Service Cluster IP Range 내에서 \*\*가상 IP (ClusterIP)\*\*를 할당kube
83.DNS in Kubernetes

훌륭하다. 이 강의를 바탕으로 Kubernetes 클러스터 내부에서 동작하는 DNS 메커니즘을 명확하게 정리해주겠다.Pod는 IP가 동적이다. (삭제/재생성 시 변경)IP 기반 통신은 불안정하고 유지보수가 어려움→ 서비스나 Pod를 DNS 이름으로 접근 가능하게 만들어
84.CoreDNS in Kubernetes

Pod IP는 동적이다 (삭제/재배포 시 변경).IP가 아닌 DNS 이름 기반 서비스 디스커버리가 필수.수천 개의 Pod와 서비스가 생성/삭제되는 환경에서 /etc/hosts 방식은 불가능.Deployment 형태로 운영일반적으로 ReplicaSet 2개 이상의 Pod
85.Ingress

NodePort 사용외부 접근: http://<Node-IP>:<High-Port>문제:포트 번호 기억해야 함포트는 30000 이상만 사용 가능LoadBalancer 사용클라우드에서 퍼블릭 IP 자동 할당문제:서비스마다 LoadBalancer 생성
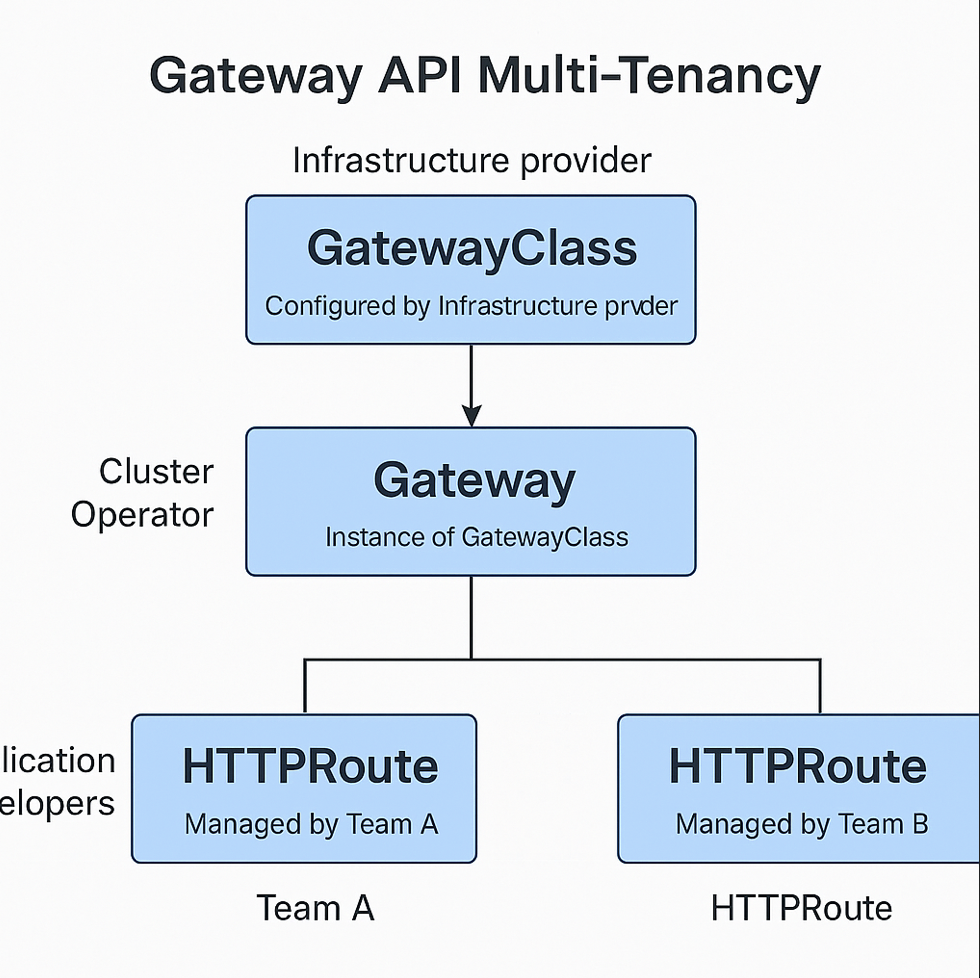
86.Gateway API
멀티 테넌시 불가능→ 하나의 Ingress 리소스를 여러 팀이 공유함 → 충돌 발생기능 확장성 부족→ HTTP 레이어만 지원 (Host, Path 매칭)→ TCP, UDP, gRPC, TLS, Canary, Rate limiting 불가컨트롤러 의존적인 설정→ 기능 확
87.Gateway Practice Guide
이 가이드는 Kubernetes Gateway API를 소개합니다. 이는 Kubernetes에서 인그레스(Ingress) 및 트래픽 라우팅을 관리하는 현대적이고 확장 가능한 접근 방식입니다. 이번 데모에서는 NGINX Gateway Controller를 사용하지만, 이
88.Design a Kubernetes Cluster
애플리케이션 종류:웹 서비스빅데이터, AI, 분석트래픽 패턴:지속적 대량 트래픽버스트성 트래픽애플리케이션 수:소수 → 소규모 클러스터다수 → 확장형 클러스터※ 운영 환경에서는 Control Plane를 별도로 구성하고 Master Node는 워크로드를 수행하지 않음.
89.Choosing Kubernetes Infrastructure
🧠 주요 포인트:Windows는 Hyper-V, VirtualBox를 통해 리눅스 VM 위에 Kubernetes 설치 필요.🧠 특징:클러스터 + VM + 네트워크 모두 클라우드 제공업체가 관리유지보수, 패치, 업그레이드 자동화대상: 학습용환경: 로컬 VirtualB
90.Configure High Availability
Master 노드 장애 시 문제점기존 실행 중인 애플리케이션은 유지됨.하지만,새로운 Pod 스케줄링 불가.장애 복구 불가 (ReplicaSet 작동 안 함).kubectl 명령어, API 호출 모두 실패.✔️ API Server모든 Master에 동시에 동작Load B
91.Deployment with Kubeadm
이번 강의는 kubeadm을 이용하여 Kubernetes 클러스터를 신속하고 올바른 방식으로 부트스트랩(bootstrap) 하는 전체 절차를 고수준에서 설명한 내용입니다. 실무 적용 가능성도 높고, CKA 시험에서도 자주 등장하는 영역이므로 핵심만 정리해볼게요.Kube
92.What is Helm

Helm = Kubernetes용 패키지 매니저복잡한 Kubernetes 애플리케이션을 “하나의 패키지”로 관리하게 해줌kubectl apply -f 수십 개의 YAML 파일을 하나하나 관리하지 않아도 됨Helm은 이를 패키지 단위로 배포, 업그레이드, 롤백, 삭제할
93.Installation and configuration

Kubernetes 클러스터가 먼저 준비되어 있어야 함Minikube, kubeadm 등으로 로컬/리모트 클러스터 운영 중이어야 함kubectl이 설치되어 있어야 함~/.kube/config 파일이 올바르게 설정되어 있어야 함클러스터에 kubectl get nodes로
94.Helm2 vs Helm3

Helm 2에서 Kubernetes에 명령을 내리기 위해 클러스터 내에서 작동하는 서버 역할Helm CLI → Tiller → Kubernetes하지만, 보안 문제 (권한 과다), 구성 복잡성 증가 등의 문제 존재→ 그래서 Helm 3에서 완전히 제거되고, Helm C
95.Helm Components

helm install my-site bitnami/wordpress→ bitnami/wordpress Chart를 이용해 my-site라는 이름의 Release 생성같은 Chart로 여러 Release 생성 가능 → 각각 격리되고 독립적으로 관리 가능
96.Helm charts

이번 강의에서는 Helm Chart의 세부 구성 요소와 구조에 대해 다루었어. Helm이 단순히 helm install 명령어 하나로 배포를 처리하지만, 그 뒤에서는 복잡한 구조를 기반으로 동작하고 있다는 점을 강조하고 있어. 이제 Helm Chart가 어떻게 구성되고
97.Working with Helm: basics

Helm CLI에서 할 수 있는 명령어 목록과 각 명령의 옵션 확인예: helm repo help, helm install --help, helm rollback --help웹사이트: https://artifacthub.io공식/검증 배지 있는 chart 사용
98.Customizing chart parameters

values.yaml 내의 키를 dot notation 없이 직접 지정하여 덮어쓰기 가능복잡한 nested 구조에서는 . 구문을 이용하거나 --set-string 등을 사용장점: 빠르게 소수 값만 수정할 때 유용단점: 여러 값이나 복잡한 구조에서는 관리 어려움복잡하거나
99.Lifecycle management with Helm

helm install을 수행하면 Release가 생성됨.Release = Kubernetes 오브젝트들의 집합 + Helm이 추적할 수 있는 메타데이터Helm은 이 Release를 기준으로:업그레이드 (upgrade)롤백 (rollback)삭제 (uninstall)등
100.Kustomize Problem Statement & idealogy

Kustomize는 Kubernetes 리소스를 "복붙 없이" 환경별로 오버라이드(override) 할 수 있게 도와주는 도구야.템플릿 언어 없이, 순수 YAML 기반으로 구성되어 있고, kubectl에 기본 포함되어 있어 설치도 필요 없어.deployment.yaml
101.Kustomize vs Helm

Helm과 Kustomize를 비교하면서, 왜 두 도구가 모두 필요하고, 어떤 프로젝트에 어떤 도구가 적합한지를 판단할 수 있는 안목을 키우는 데 목적. 단순한 기능 설명을 넘어서 철학, 구조, 유스케이스 차이를 직관적으로 정리.✅ 많은 실무에서는 Helm으로 배포하고
102.Installation/Setup

Kubernetes 클러스터가 실행 중이어야 함 (로컬 또는 원격 클러스터)kubectl 설치되어 있어야 함클러스터와 연결되어 있어야 하며, kubectl get nodes 같은 명령어가 동작해야 함아래 명령어를 실행하면 운영체제를 자동 감지해 알맞은 버전을 설치함:이
103.kustomization.yaml

kustomization.yaml은 Kustomize가 인식하는 중앙 구성 파일이야.이 파일을 기준으로 Kustomize는 다음 두 가지를 수행해:어떤 리소스들(Kubernetes YAML들)을 사용할지어떤 커스터마이징(transformations)을 적용할지Kusto
104.Kustomize Output

kustomize build <경로>는 리소스를 클러스터에 생성하지 않음대신, 최종 변환된 YAML만 터미널에 출력실제 적용하려면 kubectl과 함께 사용해야 함kustomize build k8s/: 변환된 리소스 출력|: 파이프 (출력을 다음 명령어로 전달)k
105.Kustomize ApiVersion & Kind

apiVersion: Kustomize에서 사용하는 API 버전 (예: kustomize.config.k8s.io/v1)kind: 리소스의 종류 → Kustomize에서는 항상 Kustomization💡 apiVersion과 kind를 명시하면 향후 Kustomize
106.Managing Directories

처음에는 단순하게 k8s/ 디렉토리에 .yaml 파일 몇 개만 존재할 수 있음.예:이 상태에선 그냥 kubectl apply -f k8s/로 적용하면 끝남.하지만 리소스가 많아지면 하위 디렉토리로 나누는것이 용이함.이제 kubectl apply를 하려면 각 디렉토리마다
107.Managing Directories 2

k8s/ 디렉토리는 모든 Kubernetes 매니페스트 파일을 포함하는 상위 디렉토리하위 디렉토리는 다음 세 가지로 구성api/: 애플리케이션 API 관련 리소스를 포함하는 디렉토리cache/: Redis 캐시 관련 리소스를 포함하는 디렉토리database/: Mong
108.RBAC에 대하여

전체 클러스터에서 사용할 수 있거나 단일 네임스페이스에서만 사용전체 클러스터에 적용되거나 단일 네임스페이스에만 적용됩니다.이로 인해 4가지 서로 다른 RBAC 조합이 있으며, 그 중 3가지가 유효합니다:Role + RoleBinding 단일 네임스페이스에서 사용 가능,
109.Gateway API TLS configuration

TLS 인증서 적용을 위해 작성된 필드 spec.listeners.protocol 필드의 값을 HTTPS 로 설정spec.listeners.port : 443spec.listeners.tls.mode : Terminate spec.listeners.tls.certifi
110.Network Trouble Shooting

여러 플러그인이 사용 가능하며 다음과 같은 것들이 있습니다.설치하려면:네트워크 플러그인에 대한 자세한 내용은 다음 문서에서 확인할 수 있습니다:https://kubernetes.io/docs/concepts/cluster-administration/addons