
ILSVRC-2012
ILSVRC는 ImageNet Large Scale Visual Recognition Challenge의 약자로 이미지인식 경연대회이다. 2010년부터 시작하였고, 이 대회에서 우승한 알고리즘들은 Computer Vision 분야에 큰 발전을 가지고 왔다.
그 중에서 2012년도에 우승한 AlexNet은 합성곱 신경망(CNN)구조로써 CNN의 부흥에 아주 큰 역할을 한 구조이다. AlexNet의 이름은 AlexNet의 논문인 "ImageNet Classification with Deep Convolutional Neural Networks"의 첫번째 저자인 Alex Krizhevsky의 이름을 따서 지어졌다고 한다.

위의 그래프를 보면 AlexNet은 2위와 비교가 안 될 정도로 현저히 낮은 오류율을 가지고 있음을 알 수 있다. 이 AlexNet을 시작으로 딥러닝의 시대가 열렸다고 할 수 있다. 한번 전체적인 구조를 보도록 해보자.
AlexNet의 구조

일단 gpu를 두 대를 써서 위와 아래로 나눠져있다. AlexNet은 8개의 레이어로 5개의 컨볼루션 레이어와 3개의 fully-connected레이어로 구성되어 있다. 그리고 마지막에 softmax를 이용해서 1000가지의 class가 나오게 된다. 또한 dropout을 사용하였다.
dataset은 1000개의 이미지 카테고리로 분류된 120만개의 train set, 50000개의 validation set, 150000개의 test set을 사용하였다고 한다. 그리고 모든 이미지는 256X256 사이즈의 RGB 컬러 사진으로 크기를 통일하였다.
1. ReLU activation function
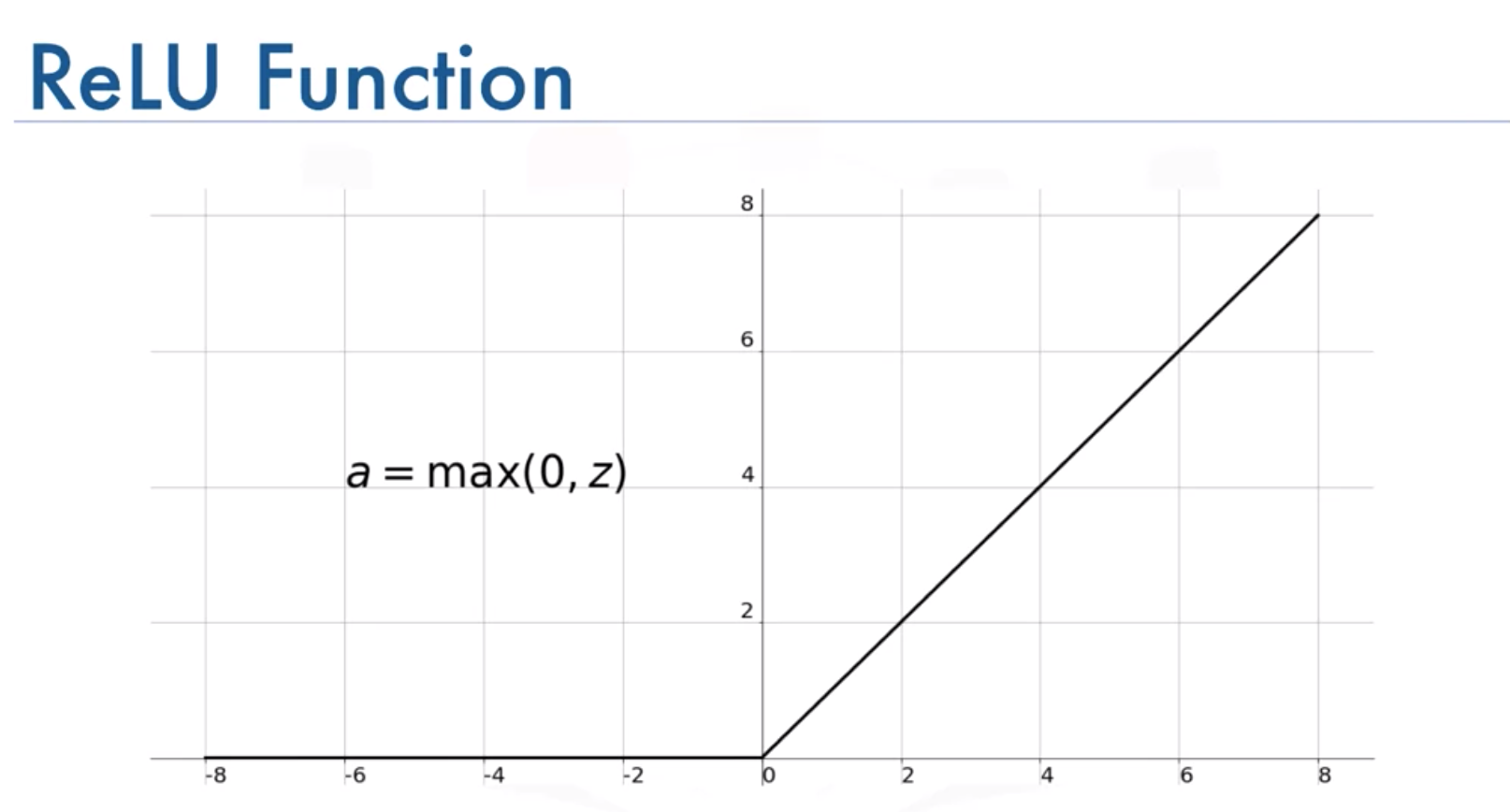
이전에는 활성화함수로 Tanh나 sigmoid를 사용했지만, AlexNet에서는 ReLU 함수를 사용하였다고 한다. 그 이유는 실험을 했을 때 ReLU 함수가 Tanh 함수를 사용을 했을 때보다 Error rate 수렴을 빠르게 하기 때문이라고한다.
2. 2개의 GPU
GPU를 한개만 쓰면 메모리가 너무 적기때문에 더 많이 모델을 훈련시키고 싶어 GPU 2개를 병렬로 연결해서 사용했다고 한다.
3. Local Response Nomalization
Local Response Nomalization은 인공지능 용어가 아닌 실제 뇌세포의 증상으로, 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 억제시키는 현상이다. 아래 그림을 한번 봐보자.
 이 그림은 측면 억제의 대표적인 예시인 헤르만 격자이다. 그림을 보면 흰색선들 사이로 회색점이 보일랑 말랑하다. 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 억제시키는 현상이라고 한다. AlexNet의 이 LRN도 이 현상을 사용하였다고 한다. 그 이유는 ReLU 활성화 함수의 사용 때문이다. ReLU는 양수의 입력값은 그대로 사용하기 때문에 매우 높은 픽셀 하나의 값이 주변의 픽셀에 영향을 미치게 되기 때문에 이런 것을 막기 위해 측면 억제를 사용하여 픽셀끼리 정규화를 해주는 것이다. 이게 바로 Local Response Nomalization이다.
이 그림은 측면 억제의 대표적인 예시인 헤르만 격자이다. 그림을 보면 흰색선들 사이로 회색점이 보일랑 말랑하다. 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 억제시키는 현상이라고 한다. AlexNet의 이 LRN도 이 현상을 사용하였다고 한다. 그 이유는 ReLU 활성화 함수의 사용 때문이다. ReLU는 양수의 입력값은 그대로 사용하기 때문에 매우 높은 픽셀 하나의 값이 주변의 픽셀에 영향을 미치게 되기 때문에 이런 것을 막기 위해 측면 억제를 사용하여 픽셀끼리 정규화를 해주는 것이다. 이게 바로 Local Response Nomalization이다.
4. Overlapping Pooling
기존의 Pooling layer의 방식은 필터의 크기와 stride의 크기가 같아 필터가 중첩이 되지않고 지나가는 반면에 Overaping Pooling 방식은 stride의 크기가 필터의 크기보다 더 크기때문에 중첩이 되면서 진행된다. 이 방식은 top-1, top-5 error rate를 줄이는데 효과적이라고 한다.
여기서 top1, top-5 error rate란 이미지 분류 성능을 평가하기 위한 지표이다. 분류기가 새로운 테스트 이미지들에 대해 예측한 클래스, 즉 top-1 클래스가 실제 정답 클래스와 같다면 top-1 error는 0%가 된다. top-5 error는 top-5 클래스 중에 실제 정답 클래스가 있다면 0%가 된다. 그래서 top-1, top-5 error rate가 낮으면 분류 성능이 뛰어나다고 판단할 수 있다.
5. Overall Architecture
* 본 논문에서는 input size가 224라고 나와있지만 이게 224인지 227인지 사람마다 말이 다 다르기 때문에 227로 수정하겠다.
-
첫번째 레이어(convolutional layer)
11 x 11 x 3 사이즈의 커널로 input image를 컨볼루션해준다. stride는 4이고, padding은 0이다. 계산을 해보면 (227 - 11) /4 + 1 = 55이고, 커널은 96개가 된다. 하지만 AlexNet은 gpu를 2대를 사용하기 때문에 반으로 쪼개져서 들어가 각각 48개씩 들어간다. 계산 공식 설명은 https://seongkyun.github.io/study/2019/01/25/num_of_parameters/에 잘 설명되어있다.
그리고 Max Pooling과 LRN을 시행한다. MaxPolling에서 커널 size는 3 x 3이고 stride는 2이므로 (55 - 3) / 2 + 1 = 27이고 LRN은 특성 맵의 차원을 변화시키지 않기 때문에 27 x 27 x 96으로 유지된다. -
두번째 레이어(convolutional layer)
5 x 5 x 48의 커널로 256개이다. stride는 1이고 padding은 2이고 Bias는 1이다. Bias는 편향으로 나중에 1씩 다 더해준다고 생각한다. (27 +2 x 1 - 5) / 1 + 1 = 27이된다. 다음 Max Pooling과 LRN을 해주면 사이즈가 27에서 13으로 줄어든다. 그러므로 13 x 13 x 256이 된다.
-
세번째 레이어(convolutional layer)
3 x 3 x 256, 384개의 커널이다. stride는 1이고 paddig은 1이고 bias는 0이므로 사이즈는 13으로 유지되고 커널은 384개가 된다.
-
네번째 레이어(convolutional layer)
3 x 3 x 192 커널을 사용해서 stride는 1, paddig도 1로 설정한다. 따라서 13 x 13 x 384 크기의 특성맵을 얻게 된다.
-
다섯번째 레이어(convolutional layer)
3 x 3 x 192 커널을 사용해서 stride는 1, paddig도 1로 설정한다. 따라서 13 x 13 x 256개의 특성맵을 얻게 된다. 그 다음에 Max Polling을 수행하면 6 x 6 x 256 특성맵을 얻게 된다.
-
여섯번째 레이어(Fully connected layer)
전의 특성맵을 flatten해줘서 6 x 6 x 256 = 9216차원의 벡터로 만들어준다.
-
일곱번째 레이어(Fully connected layer)
4096개의 뉴런을 사용하여 전 단계의 레이어와 fully connected 해준다. 출력값은 ReLU 활성화 함수로 활성화한다.
-
여덟번째 레이어(Fully connected layer)
1000개의 뉴런으로 구성되어 있고, softmax 활성화함수로 1000개의 클래스에 속할 확률을 각각 나타낸다.
Reducing Overfitting
AlexNet의 파라미터 개수는 6천만개 정도가 있는데, 많은 네트워크가 그렇듯 과적합이 고생이었다고 한다. 그리고 논문에서는 이 과대적합(Overfitting)을 줄였던 방법 2가지를 서술하였다.
1. Data Augmentation

여러가지 데이터 증식 기법
AlexNet에서는 좌우반전을 사용하여 이미지의 양을 2배로 증가시켰다. 또한 256 x 256이미지를 랜덤으로 잘라서 224 x 224의 이미지를 만들어 양을 1024배가 증가한다. 그래서 결국 이미지가 2048배가 증가한다는 것을 알 수 있다.
근데 224 x 224면 처음 input image의 크기와 맞지 않는데.. 이거는 사람마다 말이 달라 모르겠다.
또한 이미지들의 RGB값의 공분산에서 고유벡터와 고유값을 구해 각각의 픽셀에다가 더해 준다고 한다. 이런 방식을 이용해서 과대적합이 되는 것을 방지할 수 있었고 top-1 error rate를 1%이상 감소시켰다고한다.
2. DropOut
 dropout이 탄생한 이야기는, 힌튼 교수가 가는 은행에서 은행원들이 계속 바뀌는 것을 발견하고 물어봤더니 직원들간의 부정행위를 막기위해 직원들을 여기저기 순환시키면서 일을 시켰다고한다. 이것을 토대로 dropout을 고안하게 되었다고 한다. dropout은 일정한 갯수의 hidden neuron의 값을 0으로 바꿔주어 뉴런들 사이의 의존성을 낮추기 때문에 과대적합을 해결하는데 도움을 준다. AlexNet에서는 3개의 fully connected layer에서 앞의 두개에 dropout을 사용했다.
dropout이 탄생한 이야기는, 힌튼 교수가 가는 은행에서 은행원들이 계속 바뀌는 것을 발견하고 물어봤더니 직원들간의 부정행위를 막기위해 직원들을 여기저기 순환시키면서 일을 시켰다고한다. 이것을 토대로 dropout을 고안하게 되었다고 한다. dropout은 일정한 갯수의 hidden neuron의 값을 0으로 바꿔주어 뉴런들 사이의 의존성을 낮추기 때문에 과대적합을 해결하는데 도움을 준다. AlexNet에서는 3개의 fully connected layer에서 앞의 두개에 dropout을 사용했다.
Details of learning
- AlexNet에 gpu 두개중 gpu1은 색감과 관련이 없는 feature map을 뽑아내고, gpu2는 색 감과 관련이 있는 feature map을 뽑아냈다고한다.
Result
- AlexNet은 top-1 error와 top-5 error가 각각 37.5 % 및 17.0%의 오류율이 나왔다.



대단하네요 분명 영어로 된 논문이였을텐데 쉽지 않았겠네요.