
ILSVRC-2014
GoogLeNet은 ILSVRC-2014 대회에서 우승한 모델이다. 이름이 왜 구글넷인가 했더니, 정말 구글이 만든 모델이었다. 또한 LeNet 네트워크를 만든 Yann LeCuns에게 경의를 표하기 위해서라고 한다. GoogLeNet의 논문의 이름은 "Going Deeper with Convolutions"이다. 논문이름에서 유추해 볼 수 있듯이 이 대회에서 우승한 모델인 GoogLeNet과 나중에 소개할 준우승 모델인 VGGNet은 구조를 보면 과거에 비해 어떠한 변화가 있음을 알 수 있다. 바로 layer의 수가 늘어났다는 것이다.
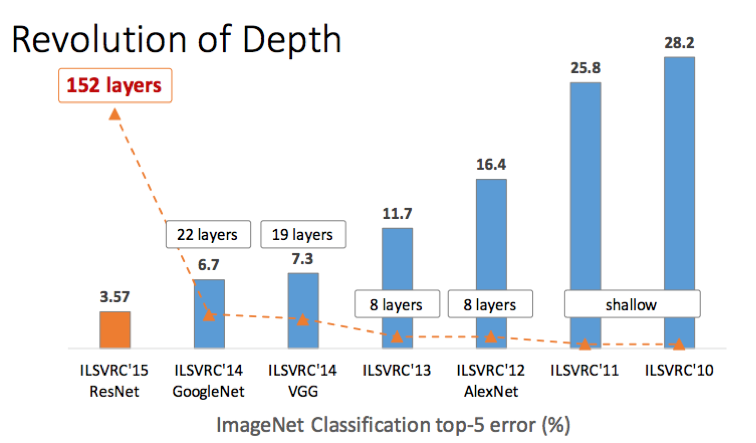
ResNet까지의 layer의 수 변화에 따른 top-5 error
그래프를 보면 AlexNet까지는 8개의 layer였다가 GoogLeNet과 VGGNet을 시작으로 ResNet까지 layer의 수가 급격히 늘어난 것을 알 수 있다. 또한 layer가 늘어남에 따라 top-5 error rate도 줄어든 것을 알 수 있다.
GoogLeNet의 구조
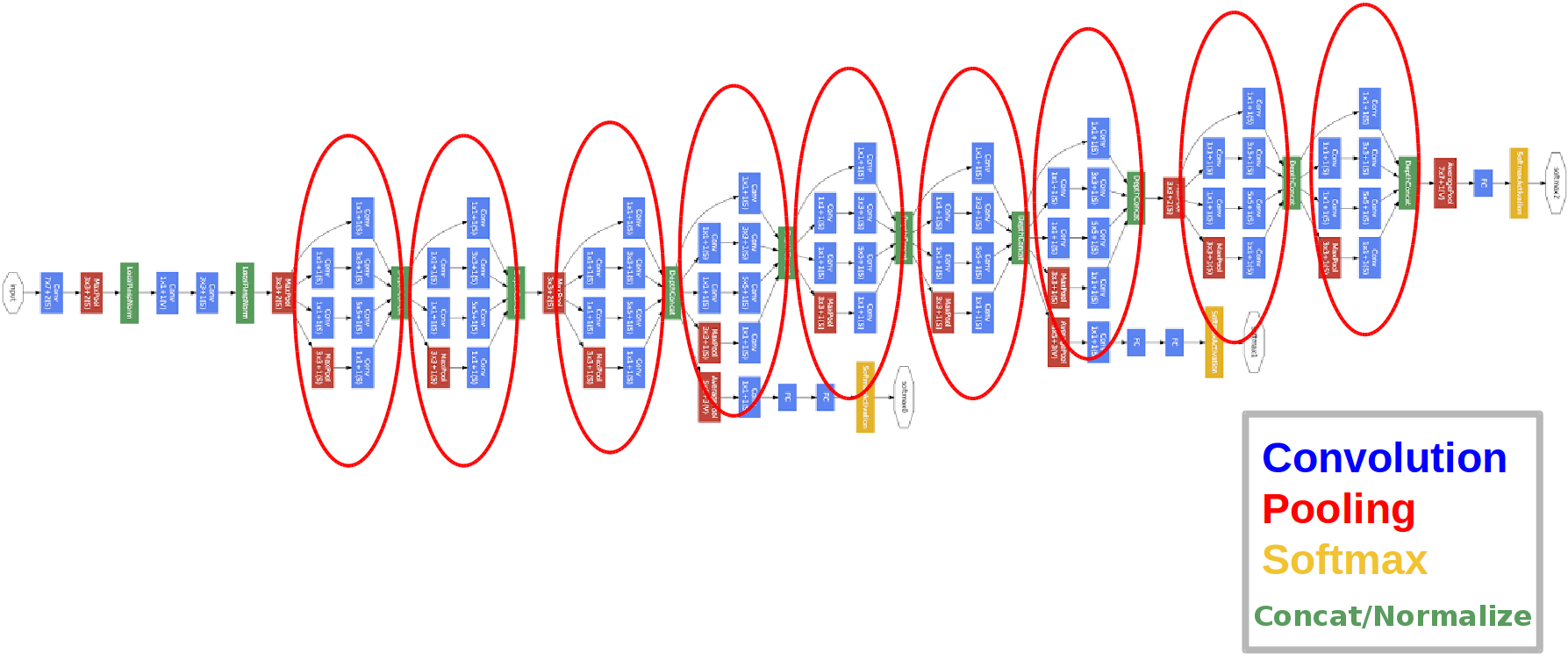
전에 읽은 AlexNet에 비하면 구조가 굉장히 복잡해진 느낌이 든다. 사진만 봐도 layer가 굉장히 깊은것을 알 수 있는데, 그 이유는 Imagenet과 같은 대규모 데이터 세트를 사용할 때 과적합문제를 해결하기 위해 drop out을 사용하고 layer의 수와 layer의 크기를 늘리는 것에 주목했기 때문이다. 위의 사진을 보면 9개의 빨간 원이 그려져있는데, 바로 저 구조는 GoogLeNet의 특이한 구조중 하나인 인셉션(Inception)모듈이다.
Network-in-Network
Inception모듈을 알기 전에, Inception모듈의 기본이 된 Network-in-Network를 짚고 넘어가보자. Network-in-Network(NIN)은 싱가포르 국립대학의 Min Lin이 2013년에 발표한 모델이다. 이름 그대로 NIN은 "네트워크 안의 네트워크"라고 유추를 해볼 수 있다.
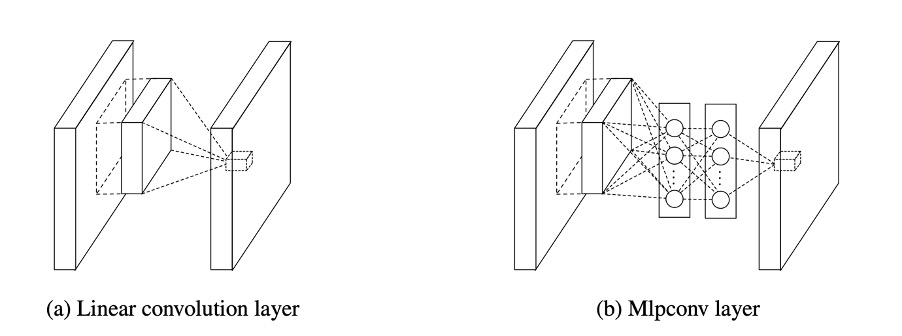
NIN은 convolutional layer의 filter의 특징이 선형적이기 때문에 비선형적인 성질을 갖는 feature를 추출하기엔 어려움이 있기 때문에 feature map의 개수를 늘리기 위해 counvolution filter 대신에 MLP(Multi-Layer Perceptron, 다층 퍼셉트론)을 사용하여 feature를 추출하도록 하였다. MLP를 사용한 이유는 사용하는 뉴런의 수를 늘리고 층을 추가하여 복잡한 구조를 생성할 수 있기 때문에 비선형적인 성질을 잘 활용할 수 있어서 feature를 추출할 수 있는 능력이 우수하기 때문이다.
Network in Network 논문 : https://arxiv.org/abs/1312.4400
1 x 1 Convolution
1 x 1 convolution이라는 걸 처음보고 난 이게뭐지...싶었다. 1 x 1 counvolution은 Inception모듈에서도 중요한 존재이다. 1 x 1 counvolution은 말 그대로 1 x 1사이즈의 filter를 이용한 convolution layer이다. 1 x 1 counvolution에는 세가지 장점이 있다고 한다. 첫째, 채널의 수를 조절할 수 있다. Channel수는 하이퍼 파라미터이기 때문에 우리가 직접 결정을 해줘야하는데, 큰 크기의 Channel수를 사용하고자 하면 그만큼 파라미터의 수가 증가하기 때문에 문제가 된다. 하지만 1 x 1 convolution를 사용하면 모델이 효율적이고 성능도 그만큼 좋아지게 된다. 둘째, 연산량이 감소한다. 1 x 1 convolution을 사용하면 그냥 n x n filter를 적용할 때보다 연산량이 굉장히 차이가 많이난다. 연산량이 감소하면 당연히 연산속도도 감소하게된다. 셋째, 비선형성을 추가로 얻을 수 있다. 1 x 1 convolution의 활성화함수를 ReLU를 사용하면 모델의 비선형성을 더해줄 수 있다는 장점이 있다.
1 x 1 convolution의 연산량 비교 https://kyuns96.tistory.com/4
Inception
본격적으로 Inception 모듈에 대해서 알아보도록 하자. Inception이라....혹시 떠오르는 영화가 있지않나?? 나는 딱 이 이름을 듣는 순간 바로 크리스토퍼 놀란 감독의 영화 인셉션이 떠올랐다. 개인적으로 재미있게 봤었던 영화였기에, 이 영화와 Inception 모듈이 어떤 연관이 있는지 궁금했다.

놀란 감독의 동명의 영화 <인셉션>
영화 <인셉션>에서는 주인공인 디카프리오가 타인의 꿈에 들어가 생각을 훔치거나 생각을 심는 일을 한다. GoogLeNet의 Inception 모듈은, 이 영화에서 컨셉을 가져와 만든 CNN모듈이다.

인셉션 모듈
Inception 모듈의 기본 구조는 위 그림과 같다. 다양한 feature를 추출하기 위해 여러개의 convolution을 병렬적으로 활용하였다. 그런데 사실 Inception 모듈은 위의 구조와 다른, 3개의 convolution(1 x 1, 3 x 3, 5 x 5)와 3 x 3 max pooling을 사용하는 구조를 고안하였다. 그 구조는 아래 그림과 같다. 하지만 앞에서 말했지만 3 x 3과 5 x 5 convolution은 연산량이 엄청 크기 때문에 망의 깊이와 넓이를 깊게 하려는 GoogLeNet에서의 치명적인 문제점이 되고 말았다. 그래서 각 convolution의 앞에 1 x 1 convolution을 두어 연산량을 줄이고, 다양한 크기의 feature 추출도 할 수 있었다. 이런 Inception 모듈은 GoogLeNet에 9개가 적용되어 있다.
하지만 앞에서 말했지만 3 x 3과 5 x 5 convolution은 연산량이 엄청 크기 때문에 망의 깊이와 넓이를 깊게 하려는 GoogLeNet에서의 치명적인 문제점이 되고 말았다. 그래서 각 convolution의 앞에 1 x 1 convolution을 두어 연산량을 줄이고, 다양한 크기의 feature 추출도 할 수 있었다. 이런 Inception 모듈은 GoogLeNet에 9개가 적용되어 있다.
GoogLeNet layer
.png)
GoogLeNet의 layer 구조
-
patch size/stride : 커널의 크기와 stride의 간격이다.
-
output size : 얻어진 feature map의 크기와 개수를 의미한다.
-
depth : 연속적인 convolution layer의 개수를 의미한다.
-
#1x1 : 이름처럼 1 x 1 convolution을 실행하고 얻어지는 feature map의 개수이다.
-
#3x3 reduce : 3 x 3 convolution을 실행하기 전에 차원을 n차원으로 줄인 것을 의미한다.
-
#3x3 : 3 x 3 convolution을 적용하고 난 후의 feature map의 개수이다.
-
#5x5 reduce와 #5x5 : 3x3과 동일하다.
-
pool/proj : max pooling과 뒤에오는 1 x 1 convolution을 적용한 것을 의미한다.
-
params : 파라미터의 개수이다.
-
ops : 연산의 수를 나타낸다.
예를 들면 Inception(3a)에서 얻은 feature map의 개수는 1 x 1 convolution에서 얻은 64개, 1 x 1에서 3 x 3 convolution까지 128개, 1 x 1에서 5 x 5 까지 32개, max pooling과 1 x 1 convolution을 통해 얻은 32개를 합쳐 256개를 얻었다는 것을 알 수 있다.
Auxiliary classifiers(보조 분류기)

다시 GoogLeNet을 봐보면 신기한 구조가 있다는 것을 알 수 있다. 바로 위에 동그라미가 쳐진 것이 바로 Auxiliary classifier이라는 것이다.
이것이 등장하게된 계기는 바로 vanishing gradient문제 때문이다. 요즘 DNN에서는 활성화 함수로 ReLU를 사용하기 때문에 다른 활성화 함수를 사용했을 때 보다 많이 나아지긴 했지만, layer가 깊어질수록 vanishing gradient문제는 더욱 악화된다. 그래서 GoogLeNet에서는 이 문제를 해결하기위해 Auxiliary classifier을 중간의 2곳에 두었다. 학습을 할 때는 이 Auxiliary classifier을 이용하여 vanishing gradient를 해결하고, 나중에 모델을 이용할 때는 Auxiliary classifier를 제거한다. GoogLeNet의 논문에는 Auxiliary classifier에 대한 자세한 내용이 포함되어 있지않다. 나중에 한번 다뤄보도록 하겠다.
결과
.png)
우승작들의 top-5 error rate
.png)
GoogLeNet에서 모델수와 cropping해서 나온 이미지의 수에 변경에 따른 성능 비교
