
지난 글에서는 GAN의 시초였던 논문 "Generative Adversarial Nets"을 리뷰했었다. 이번 글은 GAN에서 파생된 두 번째 논문, GAN에 CNN을 결합한 DCGAN에 대한 논문인 "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks"을 읽어보겠다.
GAN의 문제점?
항상 그렇듯, 완벽하지 않기에 무언가 새롭게 개발이 된다. DCGAN도 마찬가지로 GAN의 문제점을 해결하기 위해 발표된 논문이라고 할 수 있다. 그렇다면 GAN의 문제점은 무엇일까.
논문에서 GAN의 문제점은 훈련을 할 때 안정성이 떨어지는 것과, 고해상도의 이미지를 생성하기 힘들다는 것 그리고 GAN이 학습한 내용과 다층 GAN의 중간 표현을 이해하고 시각화하려는 시도가 어렵다는 점을 들었다. 그래서 논문의 저자는 이러한 문제점을 해결하기 위해 GAN에다 CNN을 적용하려는 노력을 하였다. 하지만 GAN의 망에 단순히 CNN을 적용하였을 때 충분히 좋은 결과를 얻을 수 없다는 사실을 확인하고 최적의 결과를 만들기위해 아래의 5가지 방법을 적용하였다.
1. Pooling layer를 strided convolutions (discriminator) 나 fractional-strided convolutions (generator)로 교체한다.
2. 생성자와 판별자에서 모두 Batch normalization을 적용한다. 단 모든 layer에 다 적용하면 모델이 불안정해지기 때문에 생성자의 output layer와 판별자의 input layer에는 적용하지 않는다.
3. Fully connected layer를 제거한다.
4. 생성자의 마지막 output을 제외한 모든 활성화 함수는 ReLU를 사용한다. 그러나 마지막 output은 Tanh를 사용한다.
5. 판별자의 모든 활성화 함수는 LeakyReLU를 사용한다.
DCGAN의 구조
그렇다면 GAN에 CNN을 적용했다는 DCGAN은 어떤 구조를 가지고 있을까?
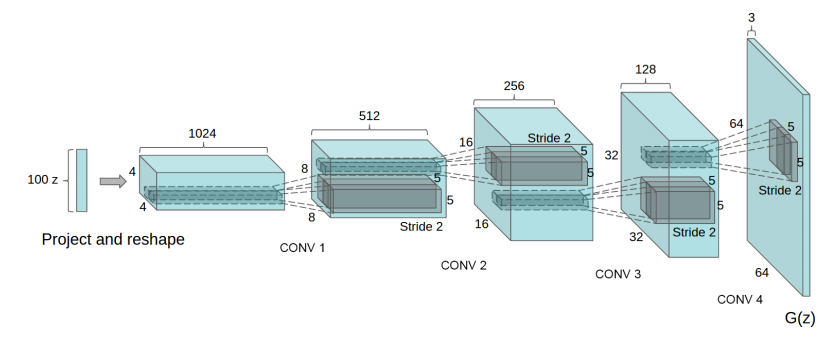
생성자의 구조
input으로 100 x 1의 noise vector를 사용하여 Project and reshape라는 layer를 통해 1024 x 4 x 4로 확장이 된다. 그리고 convolution layer로 넘어가 fractional-strided convolution layer를 거치며 64 x 64 pixel의 이미지를 생성한다.
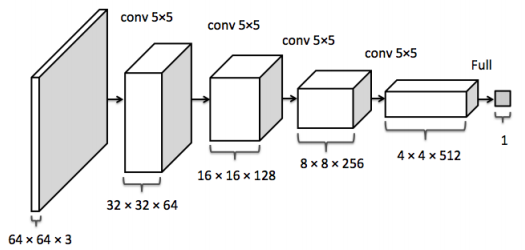
판별자의 구조
판별자는 input으로 64 x 64 크기의 이미지를 받아 마지막 sigmoid로 1 or 0의 1차원 결과를 출력한다. 활성화 함수는 위에서 언급했던 것 처럼 LeakyReLU를 사용하는데, ReLU와 다른 점은 LeakyReLU는 음수영역에서 약간의 기울기를 갖는 값을 출력한다는 점이 다르다.
결과

논문에서 이미지에 대해 별도의 전처리를 하지 않고 -1, 1의 범위로 scaling하여 사용하였다고 한다. 위의 사진은 침실 사진을 생성해낸 것인데, 꽤 그럴듯한 결과가 나온 것을 알 수 있다. 특히, z의 값을 변화시켜 얻은 마지막줄 이미지는 TV가 벽면에 붙어있는 사진이 창문이 달린 사진으로 바뀐 것을 알 수 있다.

위의 사진은 Discriminator의 feature을 시각화하여 나온 사진이다. 사진을 보면 filter들이 침실의 일부분을 학습했다는 사실을 알 수 있다.

재밌는 사실은, 학습을 통해서 얻어진 z값을 이용하여 위의 그림처럼 새로운 사진을 생성할 수 있다는 것이다. 안경을 쓴 남자 - 안경을 안 쓴 남자 + 안경을 안 쓴 여자 = 안경을 쓴 여자 가 되는 것이다.
