Semantic Segmentation
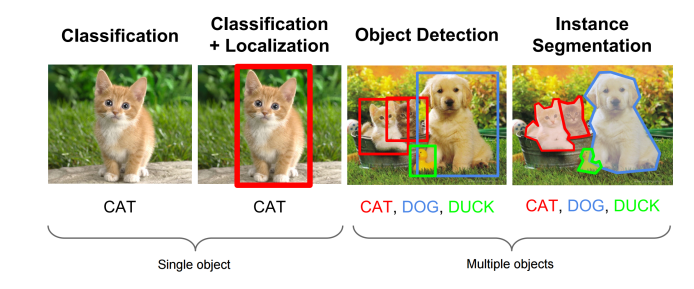
이번에 공부해보려고 하는 주제는 바로 Semantic Segmentation이다. Segmentation은 기존의 내가 공부했던 분류 모델과 다르게 사진을 분류하는 것을 넘어서 사진에 있는 모든 픽셀을 지정해놓은 class로 분류하는 것이 바로 이 Semantic Segmentation이다.
이해가 잘되게 설명된 그림
Semantic Segmentation은 같은 class의 instance를 구별하지 않는데, 예를 들자면 강아지가 여러마리가 찍힌 사진이 있다고 가정했을 때 강아지를 분류하지 않고 강아지 class에 속한다고만 나오는 것이고, instance를 구별하는 것은 따로 instance segmentation이라고 부른다.
그래서 이번에 공부해볼 것은 Semantic Segmentation 모델들에게 많은 영향을 끼친 FCN(Fully Convolutional Network)를 공부해볼 것이다.
Segmentation에 대해 더 궁금하다면 잘 설명된 블로그를 참고해보자.
FCN
FCN의 논문 제목은 "Fully Convolutional Network for Semantic Segmentation"이다. 논문의 저자들은 분류 부분에서 좋은 결과를 보였던 AlexNet이라던지, VGGNet에 이용하는 것에 대해 주목했지만, 이 모델들은 모두 fully connected layer가 오게되면서 위치정보가 사라지게 되어 위치정보를 알아야하는 Segmentation에서는 심각한 결함이 되었다. 그래서 FCN은 그 Fully connected layer를 convolutional layer로 바꿔버린다(이것을 convolutionalization이라고 한다). 아니 이게 무슨 소리인가.
어떻게 Fully connected layer를 conv-layer로 간주한다는 것일까?
Convolutionalization
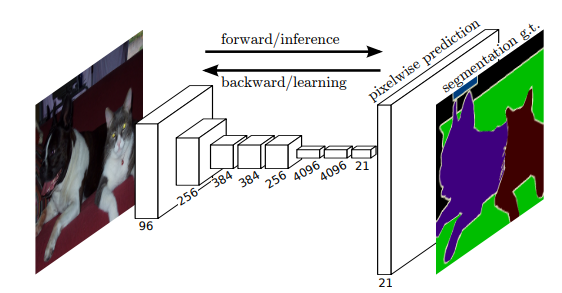
FCN의 구조
연구진들은 fully connected layer를 1 x 1 convolutional layer로 간주를 하였다고 한다. 위의 구조를 보면 뒤에있는 3개의 fu lly connected layer를 1 x 1 x 4096의 conv layer로 간주한 것을 알 수 있다. 이렇게 fully connected layer가 1 x 1 conv layer가 된다면 위치정보를 잃지 않고, 모든 network가 conv layer이기 때문에 input image의 크기 제한을 받지 않을 수 있게 되었다.
Deconvolution
그런데 계속 conv layer나 pooling layer를 거치면서 feature map은 작아지게 된다. pixel 단위로 예측을 해야하는 Segmentation에서는 feature map이 작아지면 안되기 때문에 upsampling을 해준다. upsampling을 하는 가장 좋은 방법은 바로 Bilinear Interpolation이라는 방법을 사용하는데, 이 Bilinear Interpolation이란 우리말로 이중선형 보간법이고, 1차원에서의 선형 보간법을 2차원으로 확장한 것이다.
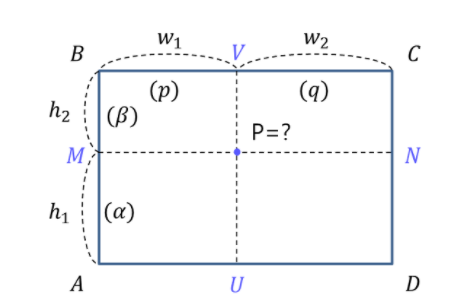
Bilinear Interpolation
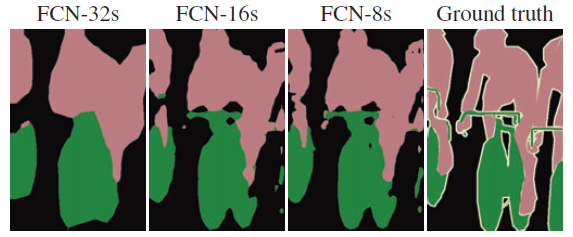
또한 skip connection을 이용하여 앞에 나온 output을 사용하여 detail을 보강하는 작업을 해줌으로써 더욱 더 정교한 예측이 가능해진다.
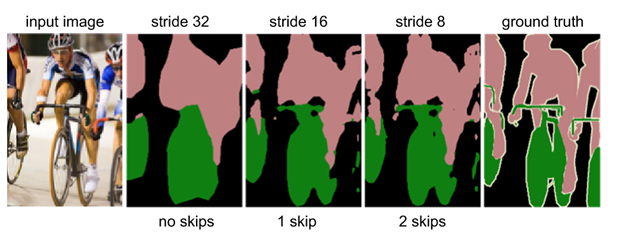
결과

