
ILSVRC-2015
이제는 예상이 간다. ResNet은 ILSVRC-2015에서 1등을 한 model이다. ResNet의 논문 제목은 "Deep Residual Learning for Image Recognition"이다. ResNet은 그 전의 우승작이었던 GoogLeNet과의 top-5 error rate를 거의 반으로 낮추었고, layer의 깊이는 더욱 더 깊어졌다.
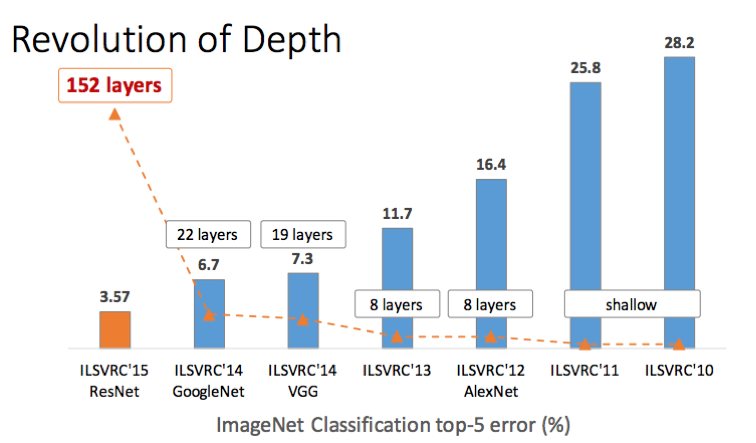
낮은 error rate와 매우 깊은 layer를 가지고 있는 ResNet
ResNet 연구진은 서론에서 layer가 깊어지는 경우 어떤 결과가 나오는지 CIFAR-10 데이터를 가지고 20-layer와 56-layer에 대하여 비교를 하는 실험을 하였다고 되어있다. 실험결과는 아래 그림과 같다.

엥?? 분명 layer가 깊을 수록 좋은 성능을 냈다고 했던 것 같은데 의외로 결과가 20-layer의 결과가 50-layer의 결과보다 error rate가 적게 나왔음을 알 수 있다. 그 이유는 layer가 늘어날 수록 생기는 vanishing/exploding gradient문제 때문이다. 요즘엔 Batch Nomalizaion같은 방법이 적용되고 있지만, layer의 수가 늘어나면 늘어날수록 여전히 이 문제는 심각해진다고 한다.
Residual Learning
위의 문제를 해결하기 위해 ResNet에서 제안한 방법은 바로 이 논문에서 가장 핵심이라고 볼 수 있는 Residual learning이다. 우선 기존의 Convolutional Neural Network(CNN)의 방식을 봐보도록하자.
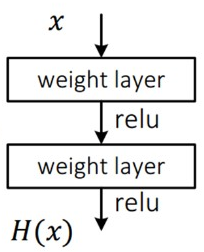
이 기본적인 방식은 input인 x를 받아 2개의 weight layer를 거치면서 출력 H(x)를 낸다. 따라서 최적의 H(x)를 찾는 것이 목표이고, weight layer들의 파라미터도 그로 인해 결정이 되는 것이 일반적인 CNN의 방식이다.
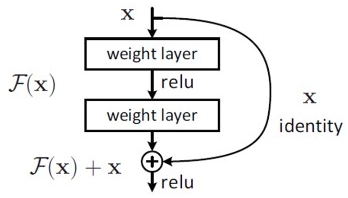
하지만 Residual Learning은 일반적인 CNN의 방식에서 관점을 바꾼 느낌이다. 일반적인 CNN이 최적의 H(x)를 찾는 것이 목표였다면, 위의 그림처럼 Residual Learning은 H(x) - x(input)의 값을 최소화하는 것이 목표이다. 그래서 이름이 Residual(잔차)인 것이다. 여기서 F(x) = H(x) - x 일때, 식을 약간 옮기면 H(x) = F(x) + x 라는 것을 알 수 있다. 그렇기 때문에 위의 그림처럼 weight layer를 거치고 x를 더해주는 것이다. 그래야 H(x) = F(x) + x이기 때문이다. 이렇게 되면 F(x)는 0이어야 최적이기 때문에 학습할 방향을 미리 결정할 수 있다. 그리고 x를 미분하면 값인 1을 가지기 때문에 layer가 아무리 깊어져도 gradient가 1이상의 값을 가지므로 gradient vanishing문제를 해결하였다는 것을 알 수 있다.
ResNet의 구조

위의 그림과 같이 ResNet의 생김새는 VGGNet과 닮아 있다는 것을 알 수 있다. 사실 ResNet은 VGGNet을 토대로 3 x 3 convolution을 사용하여 층을 더 추가해서 깊게 만들고, shortcut(Residual block)들을 추가한 것이라고도 할 수 있다.
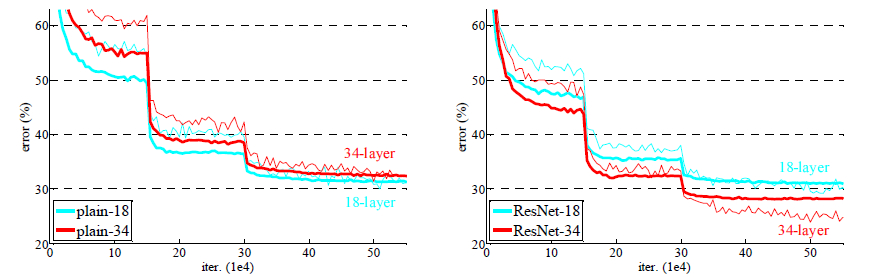
ResNet연구진의 Residual block 성능실험
왼쪽 그래프를 보면 plain-18, 34 네트워크는 깊어지면 깊어질수록 에러가 증가하는 모습을 볼 수 있다. 하지만 오른쪽 그래프의 Residual block을 사용한 ResNet은 깊어질수록 에러도 작아졌다는 사실을 알 수 있다. 이 실험을 통해 Residual block이 효과가 있다는 것이 증명되었다.
결과
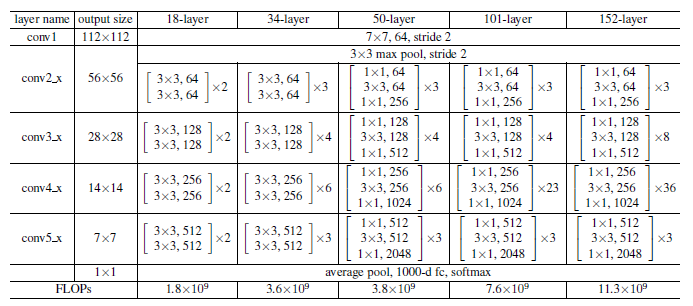
위의 그림은 ResNet의 층수를 달리하여 실험한 결과이다. 152 layer의 ResNet이 가장 성능이 뛰어나다는 것을 알 수 있다.
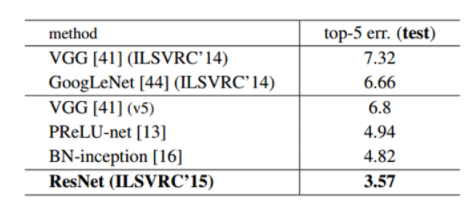
최종적인 결과는 위의 그림과 같다.
