
ILSVRC-2014
VGGNet은 특이하게도 ILSVRC-2014에서 우승을 한 모델이 아닌, 준우승을 한 모델이다. 그럼에도 불구하고 VGGNet이 우승 모델이었던 GoogLeNet보다 각광을 받은 이유는 구조의 간결함과 사용의 편이성으로 인해서라고한다. 또한 내가 앞으로 배울 모델의 기본적인 구조로 VGGNet이 사용되기 때문에 공부해야겠다고 생각을 하였다.
VGGNet의 구조
VGGNet의 논문 이름은 "Very Deep Convolutional Networks For Large-Scale Image Recognition"이다. 이름에서 알 수 있듯이 VGGNet의 논문의 개요를 보면 이 연구의 핵심은 네트워크의 깊이가 모델의 성능에 어느정도 미치는지 확인하는 것이다. 그래서 커널의 사이즈를 가장 작은 3 x 3으로 고정했다고 한다. 3 x 3으로 커널의 사이즈를 정한 이유는 커널 사이즈를 7 x 7로 했을 때 4 x 4이미지가 나오기위해선 7 x 7 사이즈는 파라미터수가 49개이지만, 3 x 3 사이즈는 3 x 3 x 3 = 27개로 더 적은 것을 알 수 있다. 결과적으로 사이즈를 3 x 3로 하면, 깊이는 깊어지지만 파라미터수는 적어진다. VGGNet의 대략적인 구조는 전에 리뷰한 AlexNet하고 크게 다른 점이 없다. convolution layer뒤에 max pooling layer가 오고 마지막에 fully-connected layer가 오는 것까지 똑같다.

(좌)VGGNet의 6가지 구조 (우)VGGNet16의 구조
VGGNet의 단점
VGGNet의 단점이라하면 바로 파라미터의 개수가 굉장히 많다는 것이다.

Number of parameters를 주목!!
가장 간단한 구조인 A구조에서도 133 million 수준으로 굉장히 많다는 것을 알 수 있다. 저번에 리뷰한 GoogLeNet은 5 million 수준이다. 그 이유가 무엇일까? 바로 GoogLeNet에는 없지만 VGGNet에서는 존재하는 이 layer! 바로 fully connected layer때문이다. fully connected layer에서만 파라미터를 약 120 million개가 온다고 한다.VGGNet의 특이한점??
첫째, 1 x 1 convolution을 사용하지만 GoogLeNet처럼 차원의 수를 줄이는 쓰임새보다는 모델에 비선형성을 추가하기 위한 목적으로 사용했다.
둘째, vanishing gradient문제를 해결하기 위해 가장 간단한 A구조로 훈련을 시작한 후 더 깊은 구조를 학습할때는 처음 4개의 convolution layer와 마지막 3개의 fully connected layer를 A구조의 학습 결과로 초기값을 설정 한 후 학습을 시켜 vanishing gradient문제를 해결하였다. GoogLeNet은 신기한 구조인 보조 분류기(auxiliary clssifier)을 사용하여 이 문제를 해결했다.
Data Augmentation
VGGNet에서는 scale jittering이라는 data augmentation방식을 사용하였다. scale jittering이 무엇이냐?? 이미지의 너비 & 높이인 n값을 고정하지 않고 256~512의 값들 사이에서 무작위로 값을 설정해주는 것이다. 모두 같은 사이즈가 아닌 각각 다른 사이즈가 되기 때문에 이렇게 학습을 시켜주면 학습효과가 더 좋아질 수 있다고 한다.
test를 할 때도 data를 256 x 256크기로 조정하고 각각의 코너와 중앙에서 224 x 224 크기를 잘라 5개의 data를 만들고 또 이것을 좌우반전시켜 10장의 data를 추출할 수 있었다. 또한 Q라고 부르는 test scale을 사용하여 Q로 크기조절을 하여 학습의 결과를 좋아지게 하였다.
결과
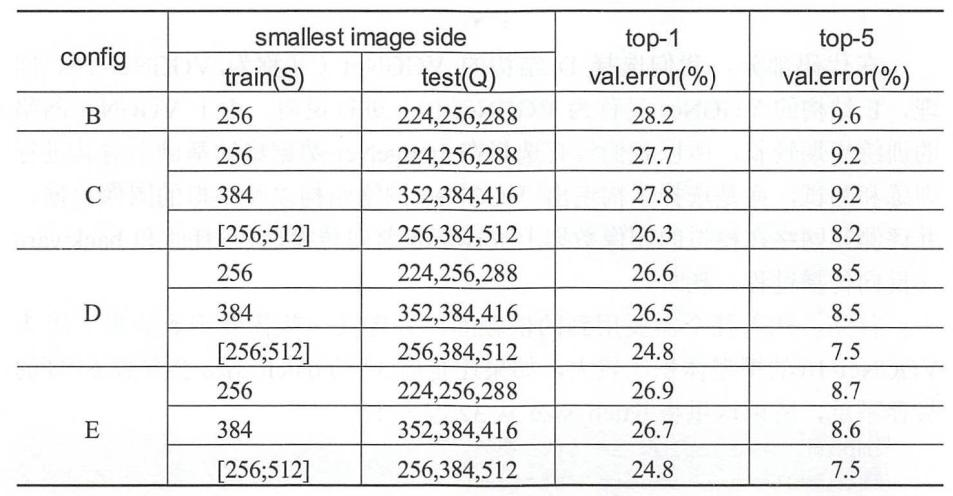
VGGNet은 단순한 구조로 인해 준우승작이었지만 GoogLeNet보다 많은 관심을 받았다. VGGNet의 top-1, top-5 error rate는 위의 표와 같다.
