
Inception Block
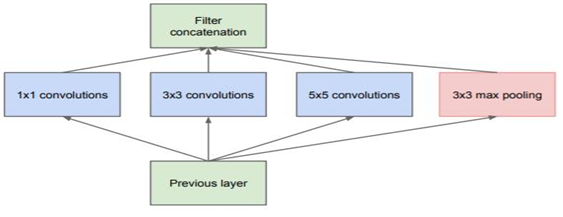
Inception Block을 사용하게 된 이유는 더 다양한 feature를 추출하기 위해서입니다. 그래서
초기의 Inception Block은 위의 그림과 같이 1x1, 3x3, 5x5 Convolution Layer와 3x3 Max
Pooling을 나란히 놓는 구조였지만, 연산량이 엄청났기에 1x1 Convolution을 사용하여 연산
량을 조절하였습니다. 1x1 Convolution Layer를 추가한 Inception Block은 아래 그림과 같
습니다.
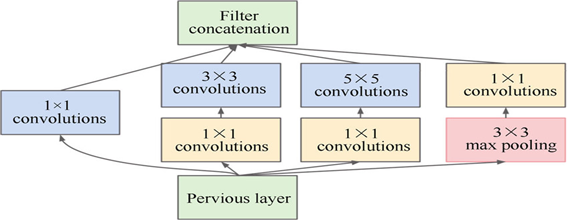
Max Pooling뒤에 1x1 Convolution을 적용한 이유는 Pooling연산 결과의 채널수는 이전과
같기 때문에 바꿔주기 위해서입니다. 이러한 Inception Block 9개를 적용한 GoogLeNet은
AlexNet에 비해 네트워크의 깊이는 훨씬 더 깊지만 파라미터의 수가 1/12분의 수준입니다.
1x1 Convolution
1x1 Convolution은 Inception Block에서 연산량 감소를 위해 쓰이는 방법입니다. 처음 공부
할 때 “대체 이게 뭐지?”라는 생각이 들었는데, 공부해보니 1x1 Convolution은 말 그대로
1x1사이즈의 filter를 이용한 Convolution Layer였습니다. 이렇게 Convolution을 진행할 경
우 장점은 Channel수를 조절할 수 있다는 것입니다. Channel수는 하이퍼 파라미터이기 때
문에 사용자가 직접 결정을 해주는데, 큰 크기의 Channel수를 사용하려면 그만큼 파라미터
의 수가 증가하기 때문에 문제가 됩니다. 하지만 1x1 Convolution을 사용하면 모델이 효율
적이고 성능도 그만큼 좋아지게 됩니다. 또한 Channel수 조절은 연산량 감소에 직접적으로
영향을 주기 때문에 네트워크를 조금 더 깊게 구성할 수 있도록 도움을 줍니다. 그리고
Activation function을 1x1 Convolution Layer에 사용할 수 있기 때문에 모델의 비선형성을
증가시켜준다는 장점이 있습니다.
구현

forward부분에서 Convolution을 수행했던 부분들을 Concat연산을 해줍니다. 0차원은 Batch
차원이기 때문에 1차원인 filter를 기준으로 output들을 묶어줍니다.
장/단점
Inception block은 Feature를 더 잘 뽑아내기 위해 큰 사이즈의 Convolution을 적용하기 전
1x1 Convolution을 적용시키면서 연산량을 조절하고 비선형성을 추가하였습니다. 이 구조를
Bottleneck이라고 부르는데, Inception block이 처음 사용된 GoogLeNet이후 등장하는 모델
구조에 광범위하게 사용되게 되었습니다. 단점으로는 Inception Block이 연산량을 줄이기
위해 노력했지만 아직도 큰 사이즈의 Convolution은 많은 연산량이 있었기 때문에, 이를 해
결하기 위해 후에 만들어진 Inception v2부터는 큰 사이즈의 Convolution도 3x3
Convolution로 분해하여 더욱 더 연산량을 줄였습니다.
