최근 인공지능을 공부하며 CV, NLP, ASR 등 딥러닝과 관련된 다양한 분야의 학습을 진행중이다.
도시빅데이터응용수업에서 음성처리 관련 학습을 진행중인데, 복습용으로 정리해둘까 싶다.
이론
KOCW(서울사이버대학교 보안음성인식)
http://www.kocw.net/home/cview.do?mty=p&kemId=1379711&ar=relateCourse
실습
오디오 전처리 github https://github.com/ithingv/AudioProcessing
허깅페이스 오디오 코스 https://huggingface.co/learn/audio-course/ko/chapter0/introduction
Librosa MFCC로 특징추출 및 음성인식 CNN 모델 https://youdaeng-com.tistory.com/5
파이썬 오디오 라이브러리 Top 5종 https://richwind.co.kr/174#google_vignette
인공지능 자동 음성 인식 모델 만들기 https://happy-obok.tistory.com/69
한국어 음성인식 STT API 리스트, 각 성능 벤치마크
https://github.com/rtzr/Awesome-Korean-Speech-Recognition
API hubert-large-korean
Naver clova: https://api.ncloud-docs.com/docs/ai-naver-clovaspeechrecognition-stt
ETRI: https://aiopen.etri.re.kr/guide/Recognition
허깅페이스 asr leaderboard https://huggingface.co/spaces/hf-audio/open_asr_leaderboard
고려대학교 DMQA LAB SEMINAR 자료
자료
Audio transformer
https://www.youtube.com/watch?v=z_yW1xTuWUQ
Handling Signal Data with Fourier Transform
https://www.youtube.com/watch?v=DCAzyv2IoUs
Introduction to Analysis for Sound data
https://www.youtube.com/watch?v=1Hhj14QhkaE
T아카데미: 딥러닝 기반 음성인식 기초
자료
https://tacademy.skplanet.com/live/player/onlineLectureDetail.action?seq=181
(75차)오디오분류와음성인식강의자료
-
DSP
https://colab.research.google.com/drive/1ibIE5ilUhV5zsT1afK9_1gQ9V9YllP6E?usp=sharing -
ASR
https://colab.research.google.com/drive/1w6dcTaLrxi2L7SNLrXex6igeOCUUHp7E?usp=sharing -
seq2seq 예제
https://colab.research.google.com/drive/1Wa1NNhSSwk28Tj4KO8U4YvKSp2QLCSbr?usp=sharing
참고 블로그
https://medium.com/@vtiya/audio-journey-1-10-keywords-for-audio-processing-d9a6d6fab197
파이썬으로 배우는 음성인식 https://github.com/bjpublic/python_speech_recognition
ratsgo’s speech book https://ratsgo.github.io/speechbook/
음성인식으로 시작하는 딥러닝 https://wikidocs.net/book/2553
CMU/Fall2022-Speech Recognition & understanding
https://www.youtube.com/@wavlab3016/videos
https://www.wavlab.org/activities/2022/11751-2022f/
Lec19 - End-to-End ASR: CTC
화자 구분 음성 기록 서비스
Speech To Text(STT)
ratsgo's SPEECH BOOK
개인적으로 ratsgo님의 ASR관련 학습물을 정리한 사이트인데 정리가 정말 잘 되있어서 일단은 이 내용물로 공부를 한번 하면 괜찮을 것 같다. 저작권도 열어놓으셔서 하나하나 따라가며 정리해도 좋을것같다.
Introduction
Automatic Speech Recognition
자동 음성 인식(Automatic Speech Recognition)의 문제 정의와 아키텍처 전반을 소개합니다. 자동 음성 인식 모델은 크게 음향 모델(Acoustic Model)과 언어 모델(Language Model)로 구성되는데요. 음향 모델의 경우 기존에는 ‘히든 마코프 모델(Hidden Markov Model)과 가우시안 믹스처 모델(Gaussian Mixture Model)’, 언어 모델은 통계 기반 n-gram 모델이 주로 쓰였습니다. 최근에는 딥러닝 기반 기법들이 주목 받고 있습니다.
1. Problem Setting
자동 음성 인식(Automatic Speech Recognition)이란 음성 신호(acoustic signal)를 단어(word) 혹은 음소(phoneme) 시퀀스로 변환하는 시스템을 가리킵니다. 사람 말소리를 텍스트로 바꾸는 모델(Speech to Text model)이라고 말할 수 있겠습니다.
자동 음성 인식 모델은 입력 음성 신호 에 대해 가장 그럴듯한(likely) 음소/단어 시퀀스 를 추정합니다. 자동 음성 인식 모델의 목표는 를 최대화하는 음소/단어 시퀀스 를 추론(inference)하는 데에 있습니다. 이를 식으로 표현하면 수식1과 같습니다.
수식1 AUTOMATIC SPEECH RECOGNITION (1)
를 바로 추정하는 모델을 구축하는 것이 가장 이상적입니다. 하지만 같은 음소나 단어라 하더라도 사람마다 발음하는 양상이 다릅니다. 화자가 남성이냐 여성이냐에 따라서도 음성 신호는 달라질 수 있습니다. 다시 말해 음성 신호의 다양한 변이형을 모두 커버하는 모델을 만들기가 쉽지 않다는 것입니다. 이에 베이즈 정리(Bayes’ Theorem)를 활용해 수식2처럼 문제를 다시 정의합니다.
수식2 AUTOMATIC SPEECH RECOGNITION (2)
수식2의 우변에 등장한 는 베이즈 정리에서 evidence로 불립니다. evidence는 의 모든 경우의 수에 해당하는 의 발생 확률이기 때문에 추정하기가 매우 어렵습니다. 그런데 다행히 추론(inference) 과정에서 입력 신호 는 와 관계없이 고정되어 있습니다. 따라서 추론 과정에서 를 계산에서 생략할 수 있습니다. 의 후보 시퀀스가 2가지뿐이라면 수식3처럼 예측 결과를 만들 때 분자만 고려하면 됩니다.
수식3 ASR INFERENCE
결론적으로 음성 인식 모델은 수식4처럼 크게 두 가지 컴포넌트로 구성됩니다. 수식4 우변의 첫번째 항 는 음향 모델(Acoustic Model), 는 언어 모델(Language Model)로 불립니다. 음향 모델은 ‘음소/단어 시퀀스’와 ‘입력 음성 신호’가 어느 정도 관계를 맺고 있는지 추출하고, 언어 모델은 해당 음소/단어 시퀀스가 얼마나 자연스러운지 확률값 형태로 나타냅니다.
수식4 AUTOMATIC SPEECH RECOGNITION (3)
2. Architecture
그림1은 자동 음성 인식 모델의 전체 아키텍처를 도식화한 것입니다. 음향 모델(Acoustic Model)은 P(X|Y)
를 반환합니다. 음향 모델은 음소(또는 단어) 시퀀스 Y 가 주어졌을 때 입력 음성 신호 시퀀스 X 가 나타날 확률을 부여한다는 이야기입니다(그림2 참조). 이를 바꿔 이해하면 음향 모델은 음성 신호와 음소(또는 단어)와의 관계를 표현(represent the relationship between an audio signal and the phonemes or other linguistic units that make up speech)하는 역할을 담당합니다. 기존 자동 음성 인식 모델에서 음향 모델은 히든 마코프 모델(Hidden Markov Model, HMM)과 가우시안 믹스처 모델(Gaussian Mixture Model, GMM) 조합이 자주 쓰였습니다.
그림1 HMM, GMM 기반 음성인식 모델
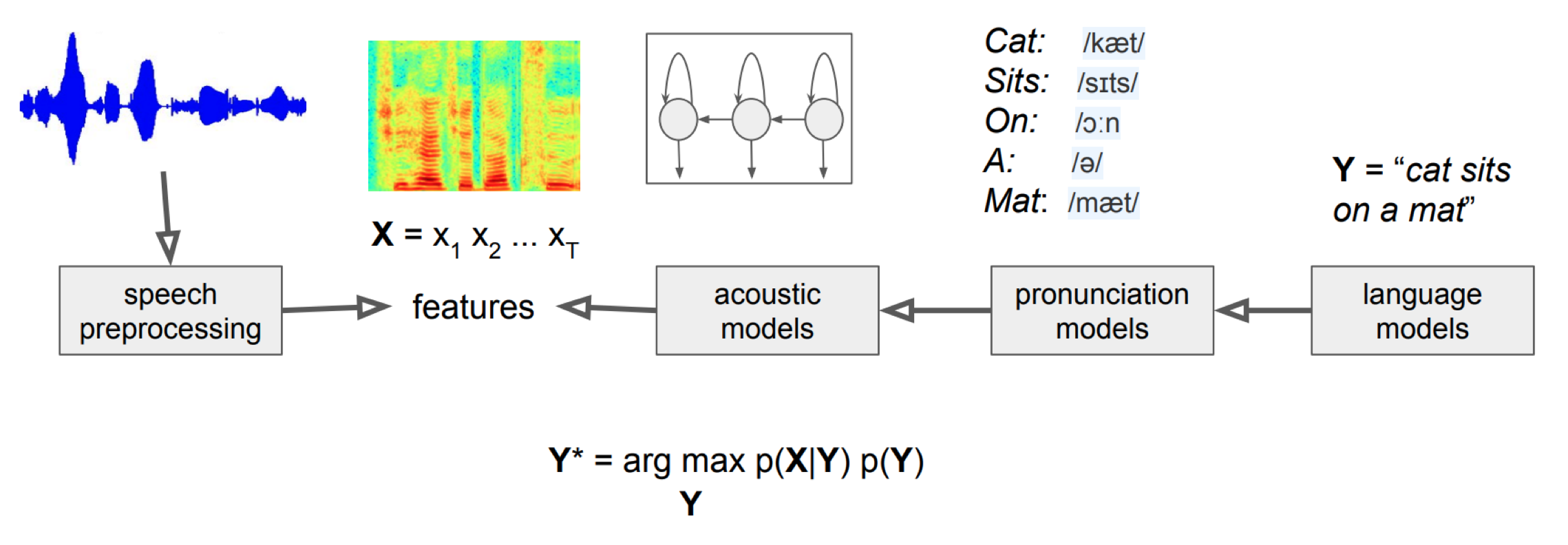
그림2 ACOUSTIC MODEL

한편 언어 모델(Language Model)은 음소(또는 단어) 시퀀스에 대한 확률 분포(a probability distribution over sequences of words)입니다. 다시 말해 음소(또는 단어) 시퀀스 가 얼마나 그럴듯한지(likely)에 관한 정보, 즉 를 반환합니다. 기존 자동 음성 인식 모델에서 언어 모델은 통계 기반 n-gram 모델이 자주 쓰였습니다.
딥러닝(Deep Learning)이 대세가 되면서 그림1의 각 컴포넌트들이 딥러닝 기법으로 대체되고 있습니다. 음향 특징 추출(Acoustic Feature Extraction), 음향 모델, 언어모델 등 거의 모든 컴포넌트가 딥러닝으로 바뀌는 추세입니다. 딥러닝 기반 특징 추출 기법과 음향 모델은 각각 Neural Feature Extraction, Neural Acoustic Models을 참고하시면 되겠습니다.
그림3 딥러닝 기반 음성인식 모델
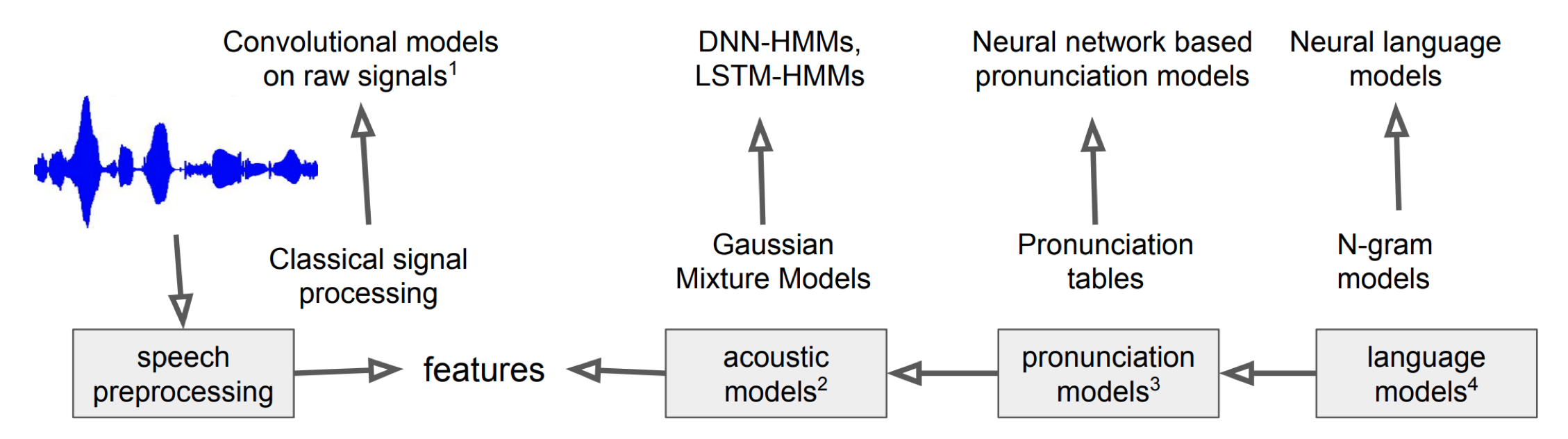
최근에는 그림2보다 한발 더 나아가 수식1의 을 바로 추정하는 엔드투엔드(end-to-end) 자동 음성 인식 모델 역시 제안되고 있습니다. 엔드투엔드 자동 음성 인식 모델과 관련해서는 End-to-end Models 항목을 보시면 좋을 것 같습니다.
3. Acoustic Features
기존 자동 음성 인식 모델의 주요 컴포넌트인 ‘HMM+GMM’이 사용하는 음향 특징(Acoustic Feture)이 바로 MFCCs(Mel-Frequency Cepstral Coefficients)입니다. 사람이 잘 인식하는 말소리 특성을 부각시키고 그렇지 않은 특성은 생략하거나 감소시킨 피처(feature)입니다. 피처를 만드는 과정은 사전에 정의된 수식에 따라 진행됩니다. 즉 연구자들이 한땀한땀 만들어낸 룰(rule)에 기반한 피처라고 할 수 있겠습니다. MFCC 추출 과정은 그림3과 같습니다.
그림4 MFCC
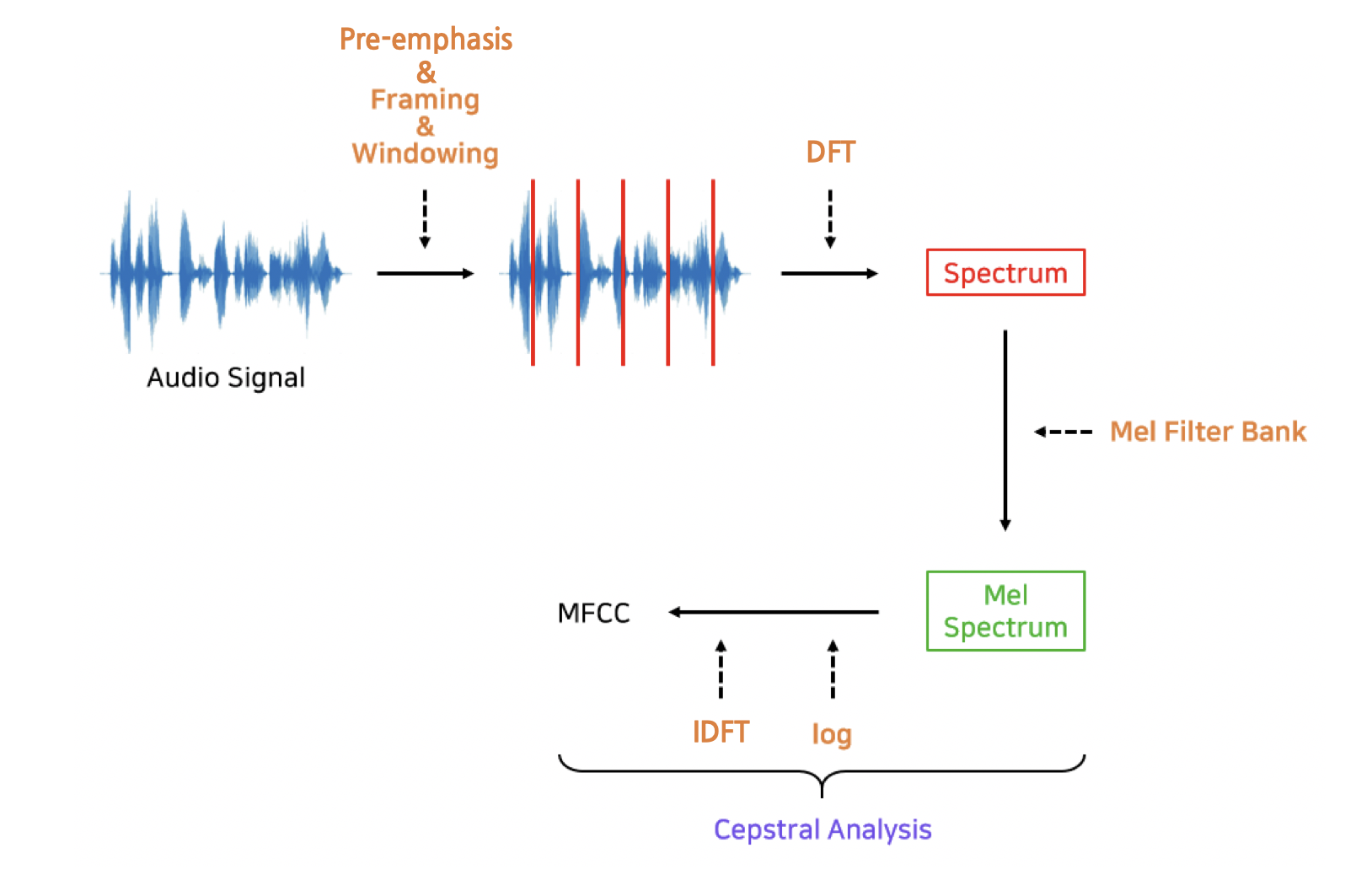
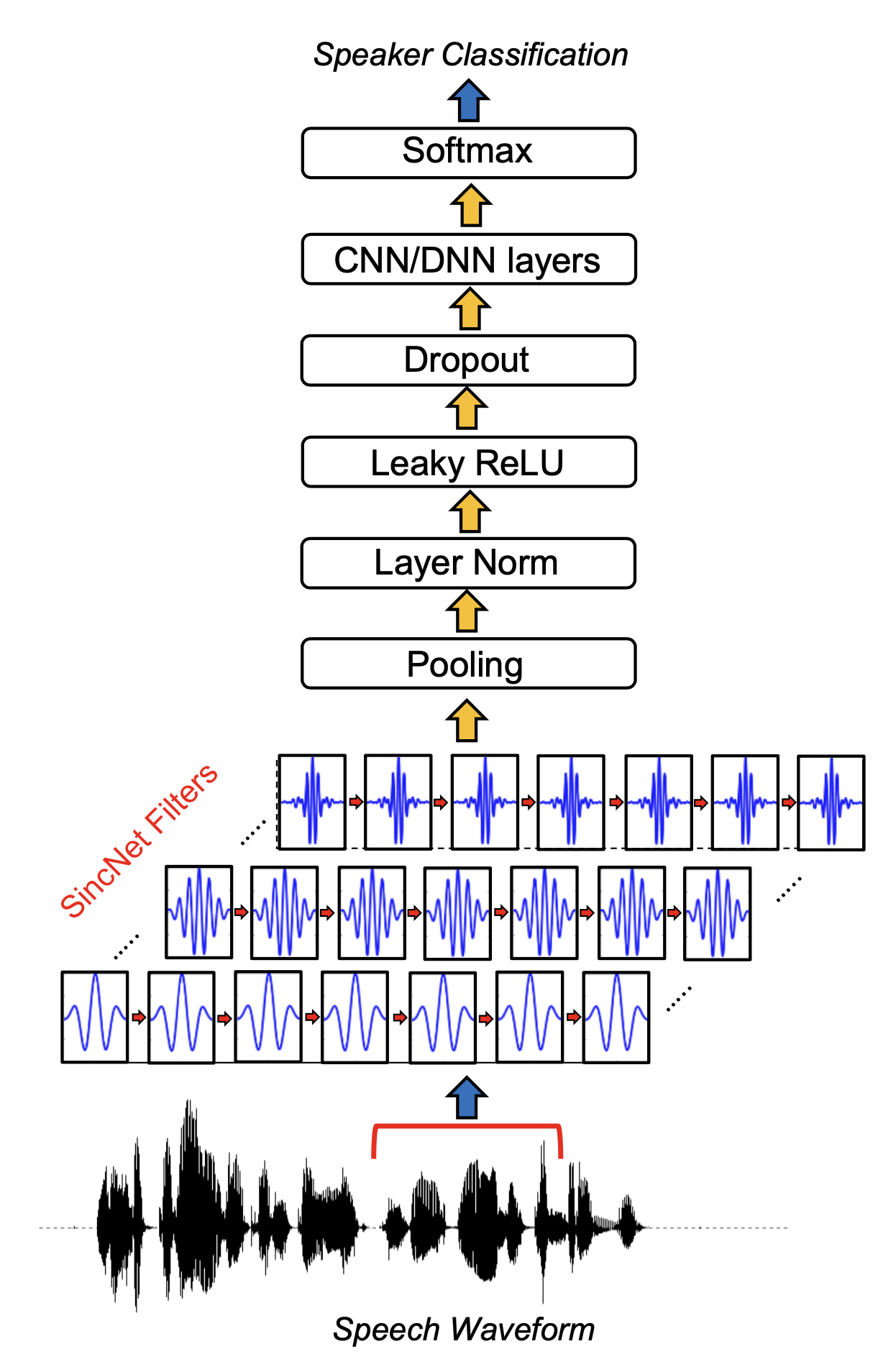
그림3에서 제시된 것처럼 음향 특징 추출도 딥러닝으로 대체되는 추세입니다. Wav2Vec, SincNet 등 다양한 기법이 제시되었습니다. 그림4는 SincNet을 도식화한 것입니다. 입력 음성 신호에 다양한 싱크 함수(sinc function)을 통과시켜 문제 해결에 도움이 되는 주파수 영역대를 부각시키고 나머지는 버립니다. 이때 각 싱크 함수가 주로 관장하는 주파수 영역대가 학습 대상(trainable parameter)이 되는데요. 룰 기반 피처인 MFCC와 달리 딥러닝 기반 음향 특징 추출 기법들은 그 과정이 결정적(deterministic)이지 않고 확률적(probabilistic)입니다.
그림5 SINCNET
Copyright © 2020 Gichang LEE. Distributed by an CC BY-NC-SA 3.0 license.
