LightGBM
LightGBM의 Motivation
- 전통적으로 GBM계열의 알고리즘은 모든 Feature에 대해, 모든 Data에 대해 Scan하여 Information Gain을 획득하게 됨
- Idea
- 사용하는 Feature와 Data를 줄여보자
- Gradient based One Side Sampling (GOSS)
- Information Gain을 계산할 때 각각의 Data는 다 다른 Gradient를 갖고 있음
- 그렇다고 하면 Gradient가 큰 Data는 Keep 하고 Gradient가 낮은 Data는 Randomly Drop을 수행
- Exclusive Feature Bundling (EFB)
- 대게 0(Zero) 값을 동시에 가지는 Data는 거의 없음 (One-hot encoding)
- 따라서, 독립적인(Exclusive) Feature는 하나로 Bundling 함

Gradient-based One-sided Sampling (GOSS)
- 각 Data 마다의 Gradient를 구하고 Sorting 함
- Gradient가 높은 것은 계속 Keep 하고, Gradient가 낮은 것은 Randomly Drop을 수행
- 할 때, 효과가 극대화 되게 됨
(권장 사항)
Exclusive Feature Bundling (EFB)
- Step 1 Greedy Bundling : 어떤 Feature들을 하나로 Bundling 할 것인지 탐색함
- Step 2 Merge Exclusive Features : 새로운 하나의 변수로 치환해 줌
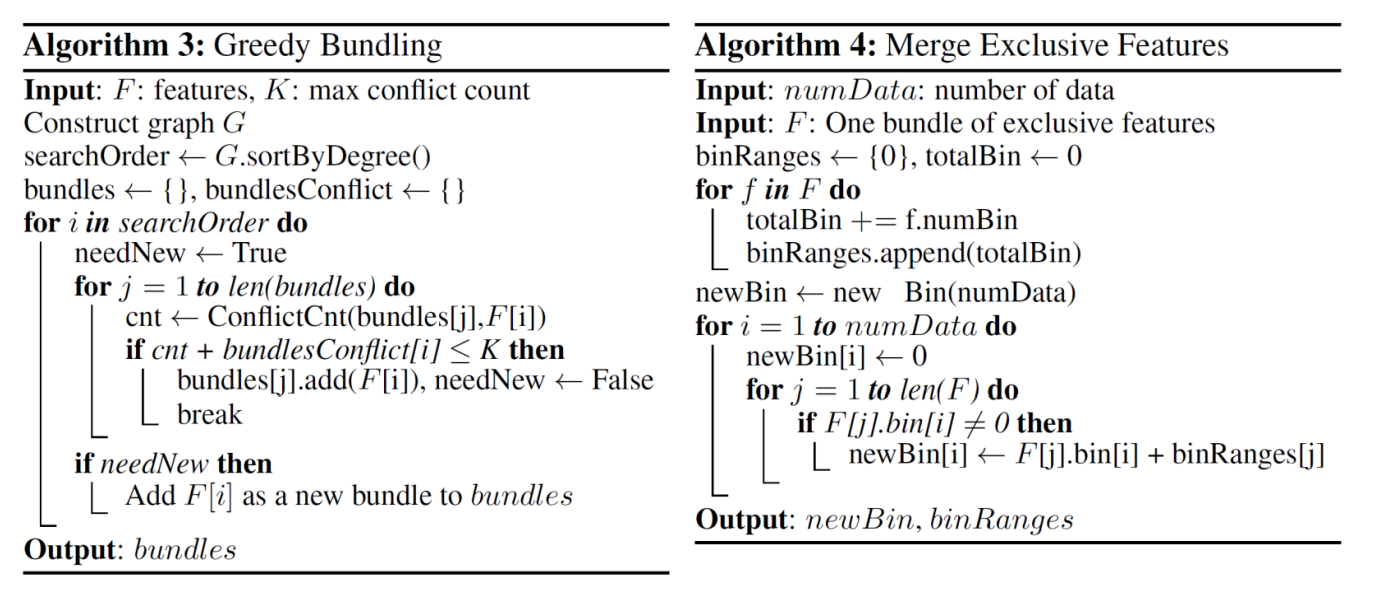
Step 1 Greedy Bundling
- Feature 간 독립적인 관계를 판단하기 위해 Graph를 구축함
- Graph (V, E) (단, V=feature, E: total conflicts between features)
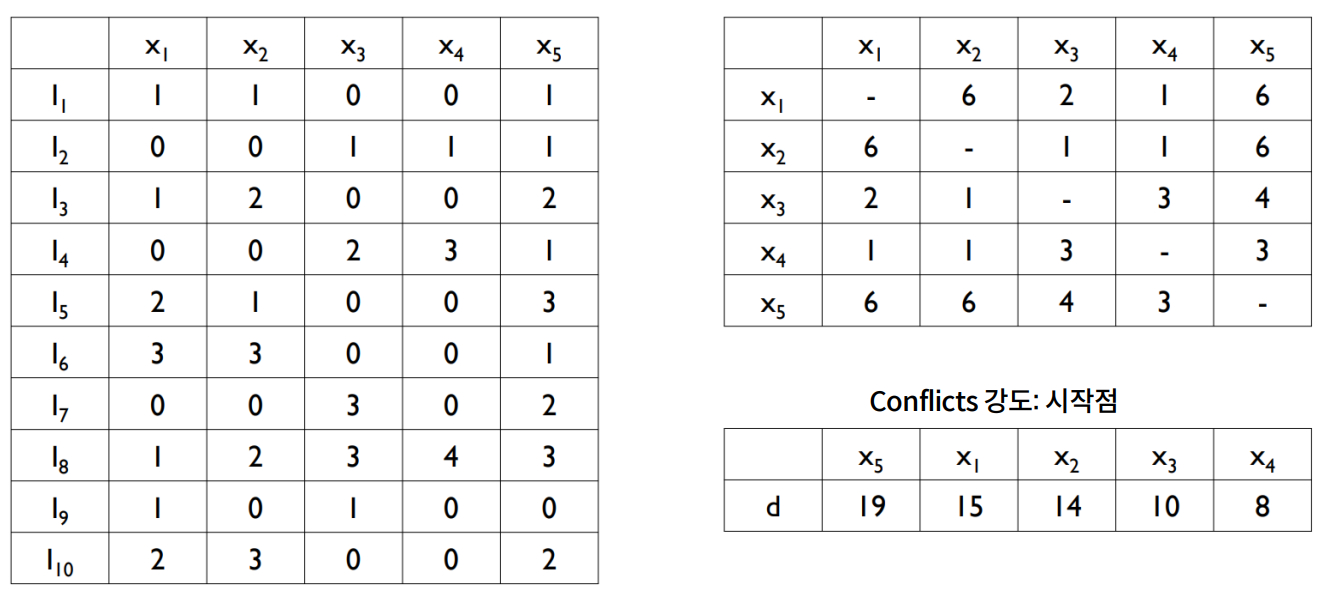
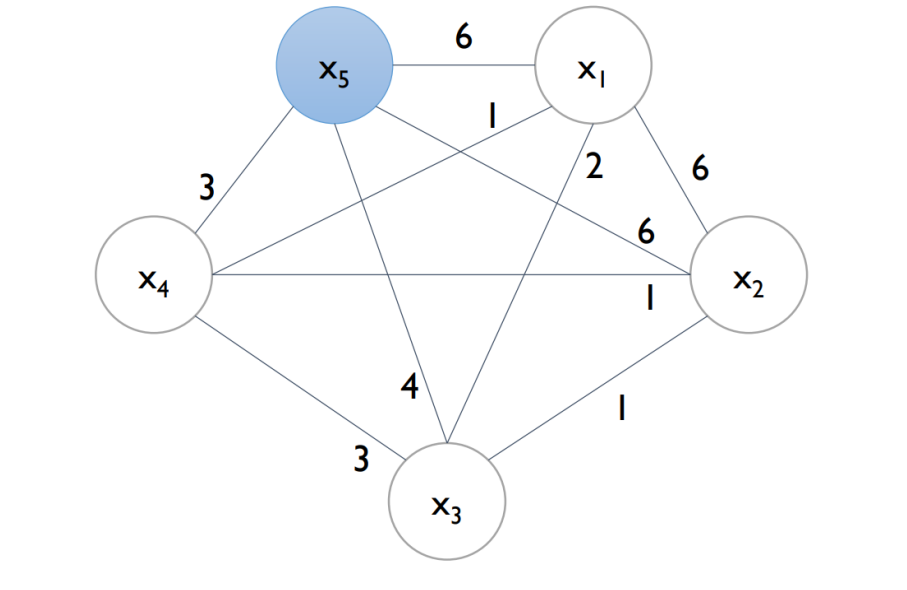
- example (cut-off = 0.2) → N=10 → 10 x 2 = 2회 이상은 Edge 가 끊어지게 됨
| Step 1 | Step 2 | Step 3 |
|---|---|---|
 | 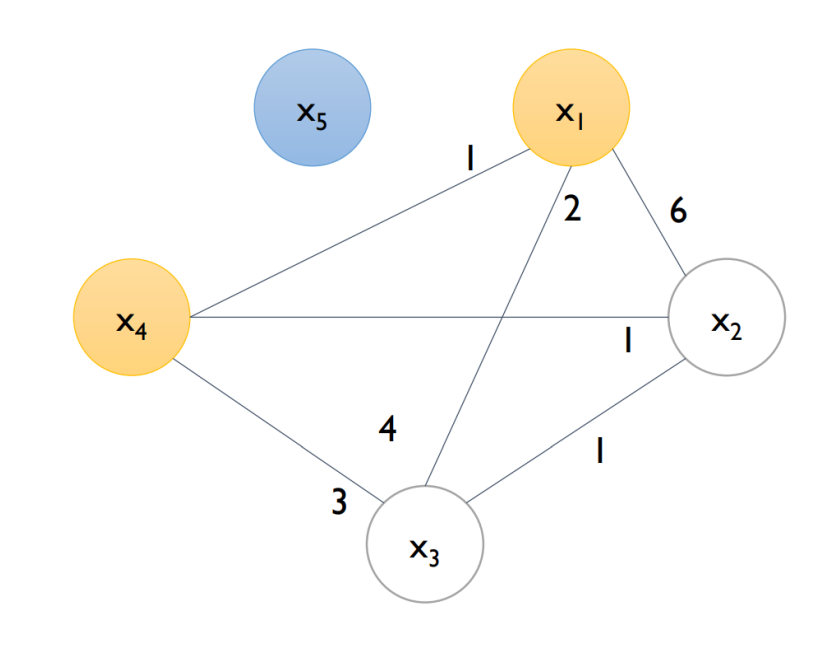 | 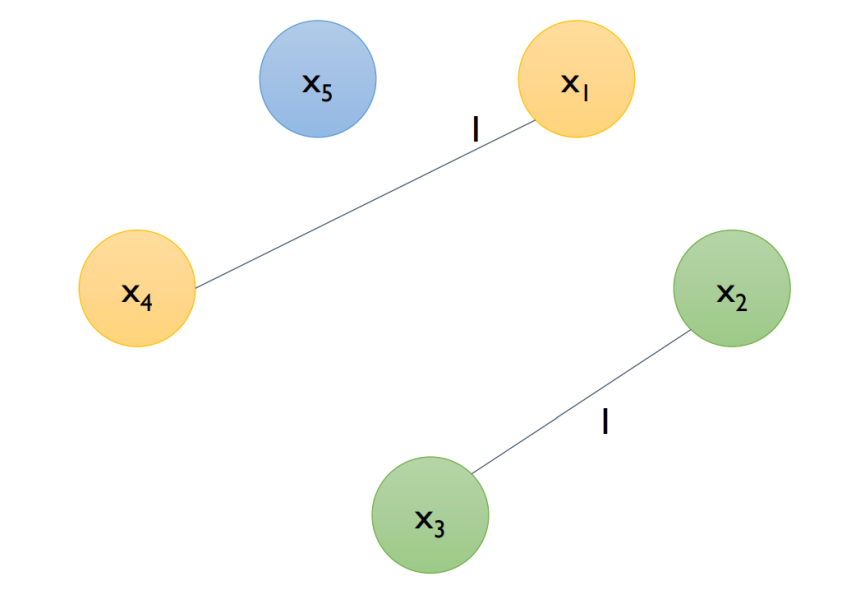 |
Exclusive Feature Bundling (EFB)
: Step 2 Merge Exclusive Features
- Add offsets to the original values of the features
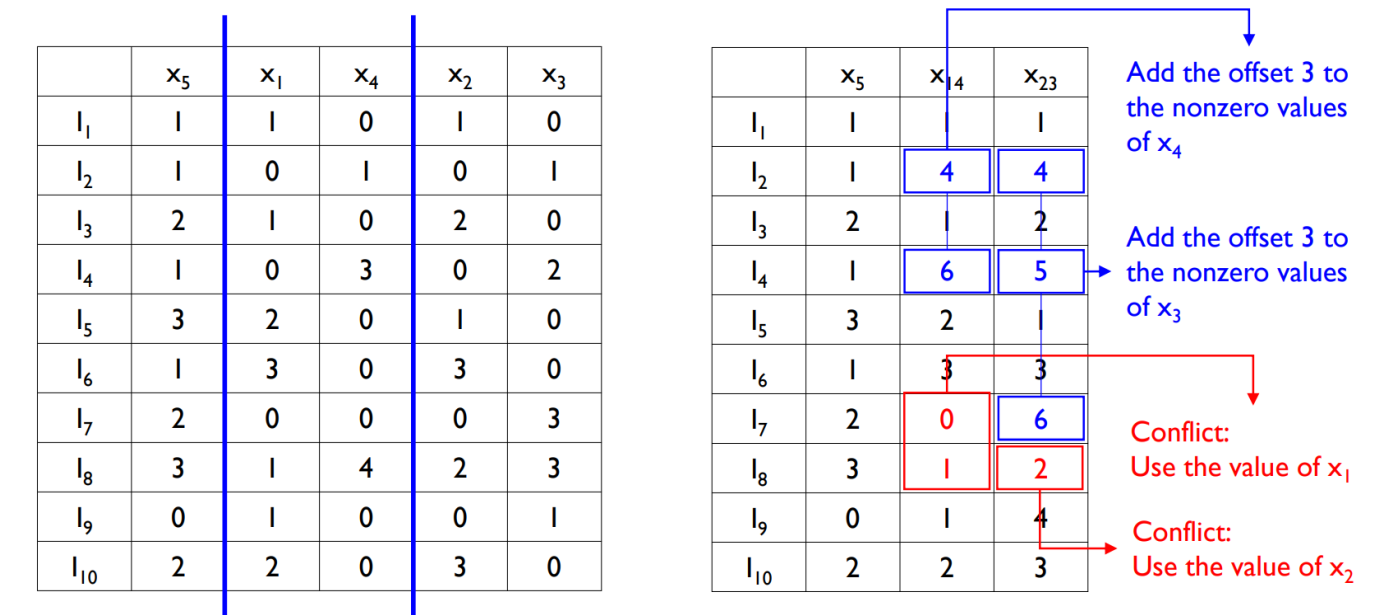
[LightGBM Parameters]
Package : https://lightgbm.readthedocs.io/en/latest/Python-Intro.html
learning_rate : GBM에서 shrinking 하는 것과 같은 것
reg_lambda : L2 regularization term on weights (analogous to Ridge regression)
reg_alpha : L1 regularization term on weight (analogous to Lasso regression)
objective
objective 🔗︎, default = regression, type = enum, options: regression, regression_l1, huber, fair, poisson, quantile, mape, gamma, tweedie, binary, multiclass, multiclassova, cross_entropy, cross_entropy_lambda, lambdarank, rank_xendcg, aliases: objective_type, app, application, loss
eval_metric [ default according to objective ]
The metric to be used for validation data.
The default values are rmse for regression and error for classification.
Typical values are:
rmse – root mean square error
mae – mean absolute error
logloss – negative log-likelihood
error – Binary classification error rate (0.5 threshold)
merror – Multiclass classification error rate
mlogloss – Multiclass logloss
auc: Area under the curve
[LightGBM]
Hyperparameter tuning
n_estimators, learning_rate, max_depth, reg_alpha
LightGBM은 Hyperparam이 굉장히 많은 알고리즘 중에 하나임
위에 4가지만 잘 조정해도 좋은 결과를 얻을 수 있음
