Califonia 집값 살펴보기
캘리포니아의 집 값은 얼마일까요?
집 값을 한눈에 알아볼 수 있다면 얼마나 좋을까요?
파이썬을 이용해서 시각화까지 해보겠습니다!
저는 이번 과정을 Colab을 활용해서 진행했습니다.
Califonia Data set 받아오기
import os
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing") # 디렉토리 설정하기 - /기본 경로/datasets/housing
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz" # 다운로드 할 파일의 URL
def fetch_housing_data(housing_url= HOUSING_URL, housing_path= HOUSING_PATH):
os.makedirs(housing_path, exist_ok= True) # 디렉토리 만들기
tgz_path = os.path.join(housing_path, "housing.tgz") # 파일의 경로
urllib.request.urlretrieve(housing_url, tgz_path) # URL로 지정한 파일을 다운로드
housing_tgz = tarfile.open(tgz_path) # 다운 받은 파일 열기
housing_tgz.extractall(path= housing_path) # 압축 파일(housing.tgz) 압축 풀기
housing_tgz.close() # 파일 닫기
fetch_housing_data()import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH, filename="housing.csv"):
csv_path = os.path.join(housing_path, filename) # os.path.join("/datasets/housing", "housing.csv") -> /datasets/housing/housing.csv
return pd.read_csv(csv_path) # 데이터 프레임 리턴Data 불러오기
housing = load_housing_data()
housing.head()
housing Data EDA
- EDA : 탐색적 데이터 분석
각 컬럼의 의미를 살펴보기
- longitude : 경도
- latitude : 위도
- housing_median_age : 중간 주택 연도
- total_rooms : 방의 총 개수
- total_bedrooms : 침실의 총 개수
- population : 인구
- households : 가구
- median_income : 중간 소득
- median_house_value : 중간 주택 가격
- ocean_proximity : 바다와의 거리
각 컬럼들이 나타내는 것들을 보아 우리는 캘리포니아 집값을 어떻게 나타낼지 어림짐작을 할 수 있습니다.
이를테면 중간 소득과 집값은 연관 관계가 있지 않을까?
중간소득이 높다면 집값도 비싸지 않을까?
이런식으로 말이죠!
housing.info()반드시 info를 해서 정보를 확인하는게 좋습니다.
이 부분에서 null값을 확인할 수 있고, Dtype별로 각각 다른 전략을 세울 수 있기 때문입니다.
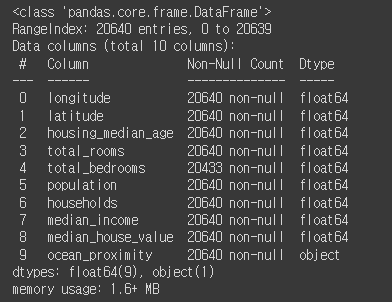
ocean_proximity를 제외하고는 모두 float으로 구성됐다는 것을 알 수 있습니다.
나중에 이게 어떻게 영향을 미치게 되는지도 알아보겠습니다!
housing.describe()describe 함수 : 여러 종류의 통계들을 한 눈에 보기 쉽게 만들어주는 함수입니다!
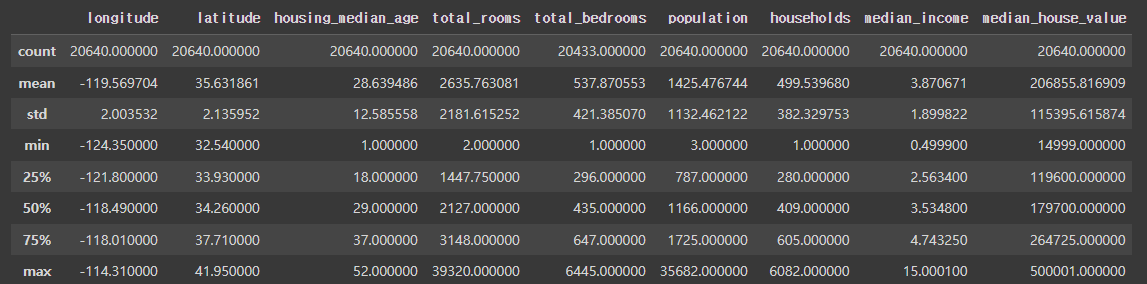
히스토그램으로 시각화
matplotlib을 사용해서 시각화를 해보겠습니다!
# 시각화!!!
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20, 15))
# hist를 통해 히스토그램을 그립니다
# bins는 히스토그램의 가로축 구간의 개수를 의미합니다
plt.show()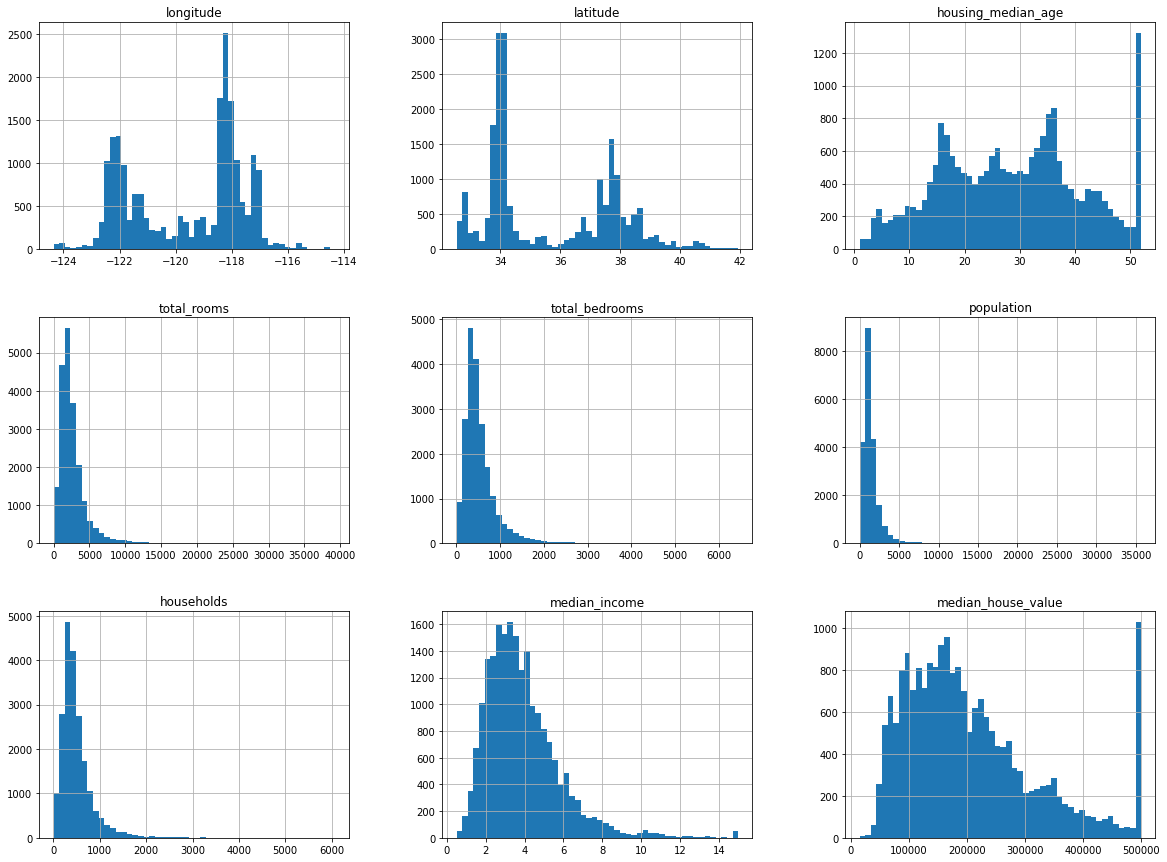
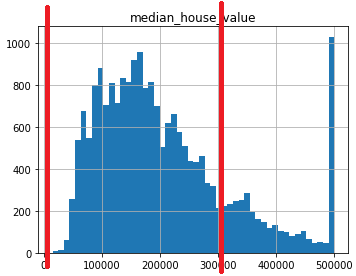
히스토그램을 통해 확인할 수 있는 점
- 바다와의 거리 data는 문자열 형태(object)이므로 히스토그램에서는 나타나지 않습니다.
(히스토그램은 숫자만 나타내기 때문이죠!)
- 히스토그램을 확인해보면 한쪽으로 쏠려있으며 아웃라이어가 많다는 것을 예측할 수 있습니다.
(housing_median_age를 보면 맨 왼쪽이 갑자기 혼자 올라가는데 이를 보고 아웃라이어가 존재하구나 예측할 수 있습니다.)
- 앞서 한 예측과 같이 집 가격은 수입(income)에 영향을 많이 받겠구나 라는 예측을 할 수 있습니다.
잠깐 그러면 쉬는 시간 겸 간단하게 데이터 스누핑 편향에 대해 알아볼까요?
데이터 스누핑 편향
훈련된 데이터에만 머신러닝의 적합성이 쏠려있는걸 일컫습니다.
즉, 제가 갖고 있는 모든 데이터를 넣어버려서 새로운 데이터를 머신러닝 모델에 넣어주자 머신러닝 모델이 새로운 데이터는 잘 맞추지 못 하는 현상이라고 합니다.
그렇다면 어떻게 데이터 스누핑 편향을 해결할 수 있을까요?
테스트 데이터 세트 만들기
- 데이터 세트를 나누지 않고, 전체 데이터 세트를 활용해서 훈련을 하게 되면 훈련을 진행한 데이터 이외에 새로운 데이터를 넣었을 때 머신러닝 모델이 새로운 데이터에 대한 예측이 제대로 잘 안되는 현상을 데이터 스누핑 편향이라고 한답니다.
- 데이터 스누핑 편향을 해결하려면?
- => 테스트 세트를 따로 만들어서 훈련 세트로 알고리즘을 훈련을 하면 데이터 스누핑 편향에서 벗어날 수 있습니다.
데이터 쪼개기(split)
-
훈련 세트와 테스트 세트의 비율은 8:2 또는 7:3 정도로 설정. 7.5 : 2.5로 설정하는게 일반적입니다.
-
테스트 세트를 생성할 때는 전체 데이터를 한번 섞고(Shuffle) 잘라야(Split)합니다.
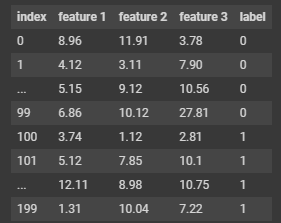
결과를 보고 알 수 있는 점
- 200개의 데이터 세트가 존재
- 0 ~ 139 : 140개 / TRAIN_SET
- 140 ~ 199 : 60개 / TEST_SET
- data를 섞어야 된답니다.
- 안 섞으면 test할 때 내가 train한 부분이 아예 안 나오게 되면 결과는 나쁘게 말하면 똥이 됩니다...!
데이터 쪼개기 실습!
무작위로 데이터를 선택
import numpy as np
np.random.permutation(100) # 0 ~ 99 까지의 정수 100개를 랜덤하게 생성결과
array([87, 49, 19, 43, 24, 62, 72, 64, 82, 52, 29, 68, 39, 95, 67, 76, 91,
54, 92, 63, 1, 69, 30, 83, 61, 23, 89, 5, 79, 12, 6, 45, 56, 33,
40, 90, 75, 9, 10, 85, 14, 93, 50, 16, 21, 34, 38, 26, 17, 48, 8,
98, 57, 11, 60, 37, 65, 51, 31, 36, 28, 88, 25, 7, 41, 66, 73, 20,
99, 94, 84, 58, 35, 32, 53, 27, 77, 22, 80, 0, 59, 70, 97, 55, 42,
4, 74, 47, 13, 2, 71, 3, 96, 46, 44, 18, 81, 15, 78, 86])데이터 개수 만큼 무작위 인덱스를 가진 리스트 생성
def my_split_train_test(data, test_ratio=0.2):
shuffled_indices = np.random.permutation(len(data))
# 테스트 세트의 크기
test_set_size = int(len(data) * test_ratio)
# 테스트 세트의 인덱스 구하기
test_indices = shuffled_indices[ : test_set_size]
# 훈련 세트의 인덱스 구하기
train_indices = shuffled_indices[test_set_size : ]
return data.iloc[train_indices], data.iloc[test_indices]사이킷런에서 제공하는 데이터 분할 함수
train_test_split은 sklearn에서 제공하는 train과 test를 split 할 수 있는 함수랍니다.
이를 활용해서 train set과 test set을 분할 할 수 있죠!
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(
housing, # split할 데이터 세트
test_size=0.2, # 테스트 세트의 크기
random_state=42 # 랜덤 시드 지정
)샘플링 편향과 계층적 샘플링
-
median_income(중간소득)은label인median_house_value(중간 주택 가격)를 예측하는데 있어서 매우 중요한 데이터입니다. -
그런데,
median_income(중간 주택 가격)은 저소득 구간에 편중되어 있는 데이터라는걸 알 수 있습니다.
-
단순하게 랜덤으로 나누게 되면 머신러닝 모델은 데이터의 비중이 많은 저소득 구간을 중점적으로 데이터를 해석하여 데이터의 비중이 적은 고소득 구간은 훈련 데이터 세트에 포함이 안될 가능성이 커지게 될 것 입니다.
고소득 구간 데이터는 제외될 가능성이 커지고 저소득 구간 데이터만 훈련 세트에 들어갈 가능성이 커지는 것을 "샘플링 편향" 이라 합니다.
구간 만들기
그렇다면 실제로 눈에 보이도록 확인을 해봐야겠죠?
히스토그램으로 눈대중으로 봤을 때는 느낌만 알 수 있으니 구간을 만들어서 확인해보겠습니다.
housing["income_cat"] = pd.cut(
# cut 함수 : 구간을 나누기 위해서 사용하는 함수입니다.
# 여기에서는 median_income만을 보기 위해 cut이 사용되는거죠.
housing["median_income"], # 구간을 나눌 대상이 되는 시리즈
bins=[0.0, 1.5, 3.0, 4.5, 6.0, np.inf], # 구간 나누기
labels=[1, 2, 3, 4, 5]
# 아시다시피 label은 문자를 숫자로 라벨링 할 때 사용되는 그 label이랍니다.
)
housing[["median_income", "income_cat"]].head(10)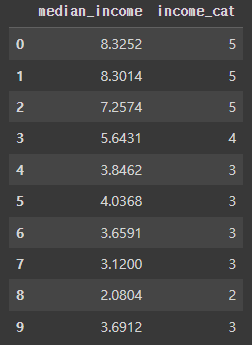
이제는 이렇게 숫자만 보여주는 것만으로는 뭔가 부족합니다.
시각화를 해보겠습니다.
housing['income_cat'].hist()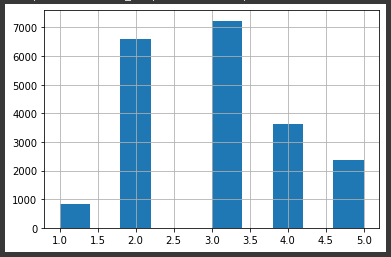
보시다시피 저소득 구간에 데이터가 뭉텅이로 존재하는 것을 볼 수 있습니다.
미숙한 글이지만 보러 와주셔서 감사합니다.
부족한 부분이 많습니다. 잘 못 작성된 부분이 있다면 지적해주시면 가르침을 얻었다는 사실에 감사한 마음으로 수정하겠습니다!!
아! 이 글은 다음 글로 이어집니다!!!
분량이 생각보다 기네요 ㅎㅎ
