머신러닝 1에서 이어집니다!
계층적 샘플링 하기
sklearn에서 제공하는 StratifiedShuffleSplit을 사용하여 계층적 샘플링을 진행하겠습니다.
from sklearn.model_selection import StratifiedShuffleSplit
spliter = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
result = spliter.split(
housing, # 자를 대상 데이터
housing['income_cat']) # 잘라질 계층 데이터
for train_idx, test_idx in result:
strat_train_set = housing.loc[train_idx]
strat_test_set = housing.loc[test_idx]spliter = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
- n_splits 는 데이터 분할 수를 의미합니다.
- n_spllits는 당연하게도 전체 데이터 수를 넘어서게 자를 수는 없습니다!
- 0.2 : 20%의 data를 자르겠다는 의미입니다.
stratify 옵션 살펴보기
# train_test_split 에 계층적 분할을 위한 옵션 stratify 옵션
train_set, test_set = train_test_split(housing,
test_size=0.2,
stratify=housing["income_cat"])stratify : 계층적 분할을 위한 옵션입니다.
즉, 한쪽으로 쏠리는 것을 방지하기 위함인데, 지금의 경우에는housing["income_cat"]이
편향되지 않도록 만들기 위해 사용되고 있습니다.
income_cat이라는 구간을 "머신러닝 1"에서 만들어서 넣었습니다.
why? : 샘플링 편향을 확인하기 위해서!
계층 샘플링 결과 확인
from sklearn.model_selection import train_test_split
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"전체": income_cat_proportions(housing),
"계층 샘플링": income_cat_proportions(strat_train_set),
"무작위 샘플링": income_cat_proportions(test_set),
}).sort_index()
# 데이터 프레임을 만들고 정렬(sort)하겠다.
compare_props["무작위 샘플링 오류율"] = 100 * compare_props["무작위 샘플링"] / compare_props["전체"] - 100
compare_props["계층 샘플링 오류율"] = 100 * compare_props["계층 샘플링"] / compare_props["전체"] - 100
compare_props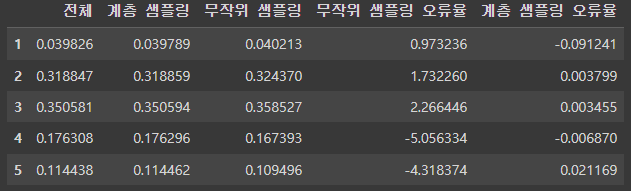
결과를 보았을 때 계층 샘플링을 했을 때 공평하게 만들어진다는 것을 알 수 있습니다.
훈련 데이터 세트에 대한 EDA
housing = strat_train_set.copy()
# housing은 start_train_set을 복사하여 사용합니다.
housing.head()
시각화 하기
housing.plot(
kind='scatter',
# scatter : 산점도 그래프
x='longitude',
# 경도
y='latitude',
# 위도
alpha=0.1
# alpha : 불투명도
)
plt.show()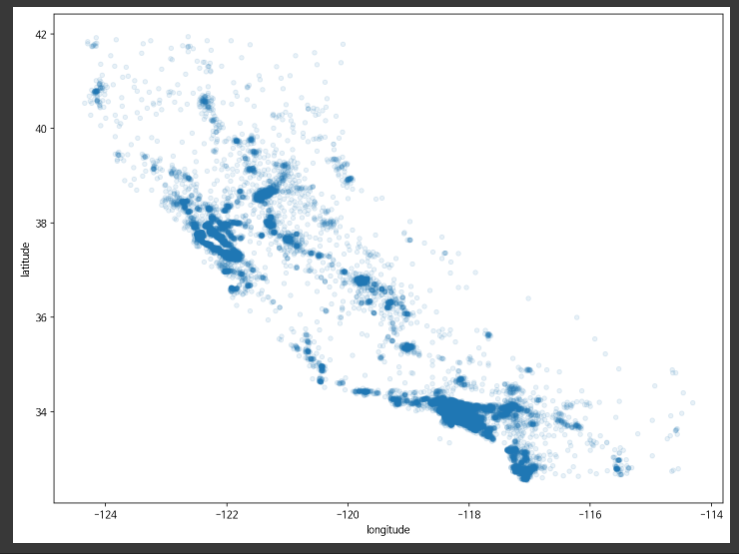
경도와 위도를 통해 집값을 산점도 그래프로 나타낸 모습입니다.
상세 시각화
# 비즈니스적으로 봤을 때, 사람이 많이 밀집해서 사는 지역의 집값이 비싸다는 것을 시각적으로 표현
housing.plot(
kind='scatter',
x='longitude',
y='latitude',
alpha=.4,
figsize=(10, 7),
s = housing['population'] / 100,
# 인구수를 기준으로 100으로 나눕니다
label='population',
c='median_house_value', # color를 표현할 컬럼의 이름
cmap=plt.get_cmap('jet'), # 무지개색으로 표현
colorbar=True
)
plt.legend()
plt.show()*****결과******
s = housing['population'] / 100,
인구수를 기준으로 100으로 나누는 이유
이를 해주지 않으면 population의 크기가 커서 산점의 크기가 굉장히 크게 나와서 확인에 어려움을 겪게 됩니다.
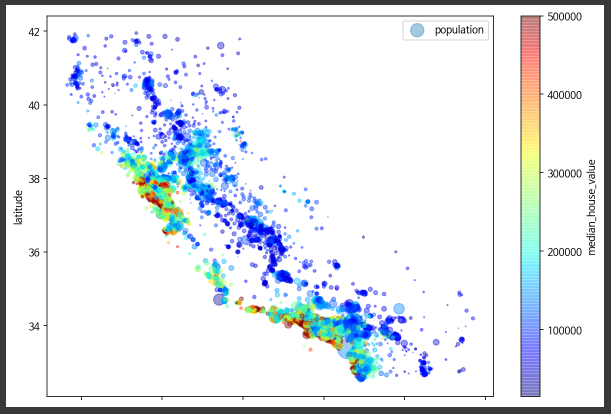
s = housing['population'] / 100,을 하자 위 그래프처럼
깔끔하게 잘 나와서 데이터의 확인이 용이해진 것을 볼 수 있습니다.
지도 위에 집값 시각화
import matplotlib.image as mpimg
images_path = os.path.join(".", "images", "end_to_end_project")
os.makedirs(images_path, exist_ok=True)
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
filename = "california.png"
print("Downloading", filename)
url = DOWNLOAD_ROOT + "images/end_to_end_project/" + filename
urllib.request.urlretrieve(url, os.path.join(images_path, filename))
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=True, alpha=0.4)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5, cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
plt.legend(fontsize=16)
plt.show()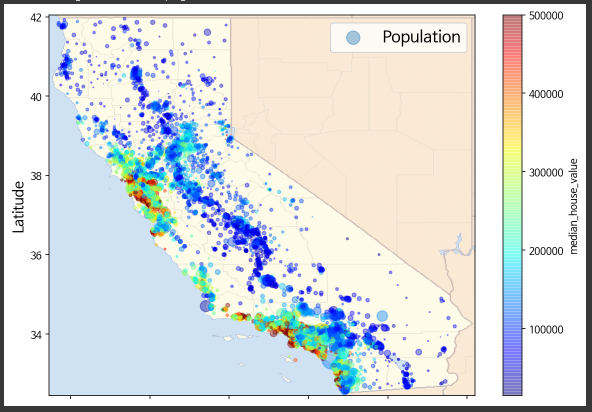
집 값에 대한 상관관계 확인
중간 주택 가격과 집 값의 상관관계 확인
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False) # 집 값에 대한 상관관계를 파악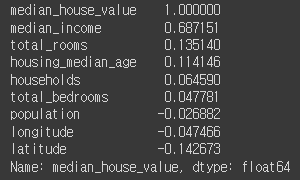
median_house_value와 median_income 사이 상관관계
=> 0.687151 : 수입과 집값의 상관관계는 밀접하다는 것을 알 수 있습니다.
머신러닝 3에서 연결됩니다!
아직 미숙한게 많은 글 입니다. 잘 못된 부분이 있다면 따끔한 충고와 가르침을 받겠습니다. 긴 글 읽어주셔서 감사합니다!

행복합시다~