상황
Java17, SpringBoot 3.1.5, SpringBatch, MySQL
전국 도서관의 1521곳의 소장 도서 정보를 담고 있는 1521개의 csv 파일이 있다.
이 1521개의 파일 안에는 총 1.3억개의 데이터가 있다.
BookSpot 서비스는 전국 도서관의 소장 도서를 확인할 수 있는 서비스이기 때문에
원활한 서비스를 위해 1.3억개의 데이터를 모두 DB에 집어넣어야 한다.하지만 1.3억 데이터 전체를 DB에 넣는 작업은 오래걸리는 작업이다.
그래도 테스트 환경 구성을 위해 일단 전체 데이터 중 일부인 700만 개의 데이터만 넣는 작업을 진행한다.
csv 파일 데이터

테이블 구조
Book : 책 정보(Book_ID, ISBN, Title ...)
Library : 도서관 정보(Library_ID, Name, Location ...)
Library_stock : 도서관 소장 도서 정보(Stock_ID, Library_ID, Book_ID ...)
Library_stock에는 Book_ID와 Library_ID가 함께 유니크 제약 조건으로 묶여있다.
이 글을 작성하면서 멀티 스레딩을 적용하면서 데드락이 발생하고, 그 데드락을 해결하기 위한 과정도 있었다. 하지만 InnoDB 버퍼풀 사이즈가 이 글의 내용이기 때문에 자세한 내용은 다른 글에서 다룬다.
💥 접근 1) 싱글 스레드 삽입
- CSV 파일 정규화 Step
- 불필요한 정보가 많은 csv 파일을 필요한 Library_ID, Book_ID만 가진 csv 파일로 변환
- Library_stock 테이블 삽입 Step
약 700만개를 처리하는데 39분이나 걸렸다.
단순 계산으로 1.3억개를 모두 처리한다면 약 12시간 정도가 예상됐다.
아마 유니크 인덱스의 크기가 계속 증가하기 때문에 12시간보다 훨씬 더 오랜 시간이 걸릴 것이다.
최적화가 필요했다.
✅ 접근 2) 멀티 스레딩 삽입
멀티 스레딩 전환 시 데드락은 유니크 키 중복 시 발생했기 때문에 도서관 파일에 중복된 Book_ID를 제거해주어 해결했다.
- CSV 파일 정규화 Step (멀티 스레딩)
- 불필요한 정보가 많은 csv 파일을 필요한 Library_ID, Book_ID만 가진 csv 파일로 변환
- 중복된 book_id 제거 Step (멀티 스레딩)
중복을 제거한 csv 파일로 변환 (중복 비율은 약 15%) - Library_stock 테이블 삽입 Step (멀티 스레딩)
결과: 39 -> 33분
Insert 시간이 얼마나 개선되는지 확인하기 위해서 정규화 시간과 중복 제거 시간을 제외했다.
싱글 스레드에서 스레드 수를 늘렸기 때문에 적어도 절반으로 줄지 않을까라는 기대를 했는데 700만 건을 저장하는데 33분이 걸렸다.
왜 6분만 빨라진 것일까?
멀티 스레드로 작업을 진행할 때 PC 작업 관리자에서 컴퓨터 상태를 확인해봤는데 디스크 활성 시간이 100%에 도달했다.

Insert 요청을 멀티 스레드로 보내면서 DB 내에서 디스크 IO 요청이 많아졌고, 이 요청들로 디스크 IO가 병목이 되어 6분밖에 줄이지 못했다고 생각했다.
DB 내의 디스크 IO 요청을 줄여야 한다.
DB 디스크 IO 줄이기 (33 -> 9분)
innodb 버퍼풀의 사이즈를 128MB -> 512MB로 늘려서 33분 -> 9분으로 줄였다.
innodb 버퍼풀의 크기를 키우면 버퍼풀에 머물 수 있는 인덱스 페이지가 많아진다.
버퍼풀에 머무는 인덱스 페이지 덕분에 요청마다 디스크를 뒤지지 않고 메모리 내에서 처리하는 상황이 많아지고, 그만큼 디스크 IO 횟수가 줄게 되어 성능이 높아지는 것이다.
추가적으로 IO를 줄이는 방법
- 버퍼풀의 크기를 512MB에서 점차 늘려가기
- DB 서버를 모니터링해보고 메모리가 여유가 있다면
Book_Id,Library_Id를 정렬시킨 후 Insert 요청을 보내기- 현재 유니크 제약조건이 Book_Id, Library_Id로 걸려있으니 이에 맞게 데이터를 정렬한 후에 Insert하는 방식이다.
- 인덱스의 맨 앞 페이지부터 차근차근 데이터를 삽입해 나가기 때문에 무작위로 요청하는 방식보다 디스크 IO 요청이 감소할 수 있다.
결과적으로 빨라졌긴 했지만 1.3억개의 데이터 중에서 겨우 700만개의 데이터를 삽입하는 작업이였다.
1.3억개를 모두 넣는다면 방대해진 인덱스 크기로 디스크 IO는 다시 많아지고, Insert 작업은 다시 느려지게 될 것이다.
✅ 초기 데이터를 빠르게 Insert하기
만약 실시간으로 서비스 중인 테이블을 대상으로 Insert 작업을 하는게 아니라, 초기 데이터를 빠르게 Insert 해야한다면 다음 방식을 고려해보자.
제약조건을 나중에 걸기
- 유니크 제약 조건 제거 -> Bulk Insert -> 유니크 인덱스 추가
- 인덱스 제거 -> Bulk Insert -> 인덱스 추가
- 외래키 체크 제거
추가적으로 다음 사진 내용을 확인하자.
출처) https://stackoverflow.com/a/52471232
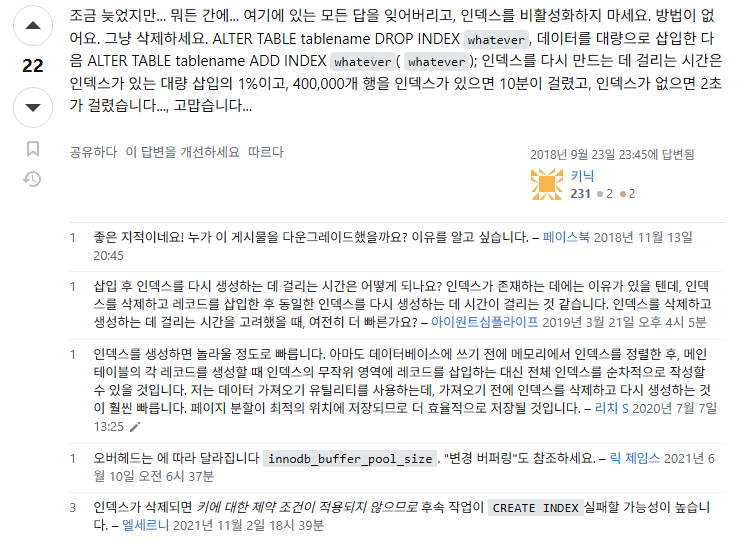
말 그대로 시작 데이터를 빨리 넣기 위함이다. 이미 서비스 중인 테이블을 대상으로 이 방법을 사용하는 것은 더 깊게 고민해봐야 한다.
외래키, 인덱스, 유니크 제약조건 등을 다 없애고 외래키 체크도 껐을 때 약 1억건 Insert 시간
- 데이터 올리는데 -> 1h 2m 21s
- (book_id, library_id )유니크 제약 조건 거는데 -> 8m 7s
- library_id 외래키 거는데 - 7m 24s
- book_id 외래키 거는데 - 19ms
총 1h 9m 52s가 걸렸다