0. 학습목표
- AB 테스트가 무엇인지 설명할 수 있다.
- 주어진 데이터를 가지고 직접 AB테스트를 진행할 수 있다.
- AB테스트를 진행할 때, 주의해야 할 사항들에 대해서 설명할 수 있다.
1. 주요개념
1-1. A/B test
A/B test는 두 가지 처리 방법, 제품, 절차 중 어느 족이 다른 쪽보다 더 우월하다는 것을 입증하기 위해서 실험군을 두 그룹으로 나누어 진행하는 실험이다. 종종 두 가지 처리 방법 중 하나는 기준이 되는 기존 방법이거나 아예 아무런 처리도 적용하지 않는 방법이 된다. 이를 대조군이라고 한다. 새로운 처리 방법을 적용하는 것이 대조군보다 더 낫다는 것이 일반적인 가설이 된다.
이때, 서로 다른 처리 조건을 제외한 나머지 조건들은 정확히 동일하게 처리 되어야 한다. 또한 두 비교집단의 샘플은 이상적으로, 무작위하게 배정된다.
A/B 테스트를 실시하기 위해서는 충분한 Sample size가 확보되어야 한다. 이는 AB test는 통계적 개념인 가설검정이기 때문이다. 통계적으로 의미 있는 차이를 데이터에서 도출하기 위해서는 충분한 데이터가 뒷받침 되어야 한다. 그리고 우리는 통계적으로 의미있는 차가 생겨야지만 결과를 신뢰할 수 있게 되므로 충분한 Sample size는 매우 중요하다.
이때, 충분한 Sample size의 크기는 Baseline Conversion Rate, Minimum Detectable Effect, Statistical Significance를 기반으로 계산한다. 옵티마이즐리라는 Tool을 통하여 테스트 시작 전 어느 정도의 데이터가 필요한지 적절한 샘플 사이즈를 파악할 수 있다.
1-2. Conversion Rate
기준 전환율을 의미하며, 현재의 전환율을 의미한다. 즉 현 상태에서 수행된 성공적인 작업의 수를 총 데이터 수로 나눈 값이다.
1-3. MDE(minimum Detectable Effect)
A/B test 진행 시, MDE(Minimum Detectable Effect)는 Sample에서의 A안과 B안의 상대적인 통계량치가 유의미한 것인지를 판단하는 기준이라고 할 수 있다.
예시)
A안의 전환율: 6.19%
B안의 전환율: 9.71%
👉 effect size = (57%)
※ 이때, A안이 대조군, B안이 실험군이다.
여기서 57%가 유의미하게 큰 차이인 것인지, 아닌지를 판단하기 위하여 기준을 삼는 것이 MDE이다. 만일 MDE가 35%라면, 결과를 통해 B안이 A안에 비하여 상당히 우수한 대안임을 주장할 수 있다.
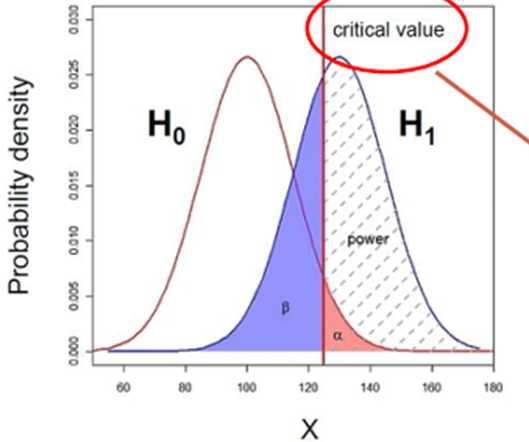
1-4. Power(검정력)
대립가설이 사실일 때, 이를 사실로서 결정할 확률이다. 검정력이 90%라고 하면, 대립가설이 사실임에도 불구하고 귀무가설을 채택할 확률(2종 오류,)의 확률은 10%이다.
검정력이 좋아지게 되면 2종 오류를 범할 확률은 작아지게 된다. 따라서 검정력은 와 같다.
만일 검정력이 0.8이라는 이야기는 탐지하려는 효과가 실제로 효과가 있다고 판단할 가능성이 0.8이라는 의미다. 효과가 없는데 없다고 판단할 능력이 높은 것도 중요하지만, 실제로 효과가 있을 때 있다고 판단할 수 있는 능력도 중요하다. P-value는 효과가 없다는 가정 하에서 평가한 숫자다. 따라서 p-value와 별도로 검정력에 신경쓸 필요가 있다. 최악의 경우에 원하는 효과 크기를 탐지할 가능성이 절반 이하인 실험 결과를 신뢰히고 중요한 의사결정을 하게 될 수도 있다.
1-5. Sample ratio mismatch(샘플비율 불일치)
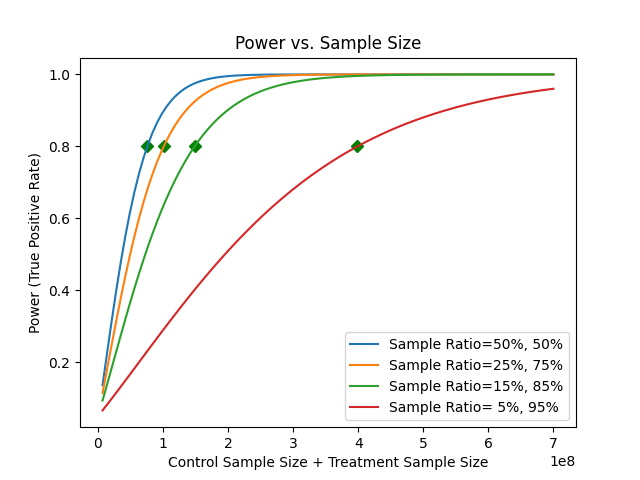
대조군과 실험군의 비울을 비슷하게 설정하는 것이 검정력이 가장 빠르게 올라가는 것을 확인할 수 있다. 이러한 대조군과 실험군의 비율이 일치하지 않는 것을 SRM(sample ratio mismatch)라고 한다. 샘플의 비율을 같게 나누는 것은 다음과 같은 이점을 가진다.
- 구현성 문제들과 버그가 나타나는 위험을 완화 할 수 있다.
- 실험이 실패했을 경우 비용 절약
- 리스크를 최소화하면서 테스트 신뢰성을 높일 수 있는 적정 수준의 비율
- 편향되지 않고 공정한 결과 비교가 가능하다.
1-6. Z-test
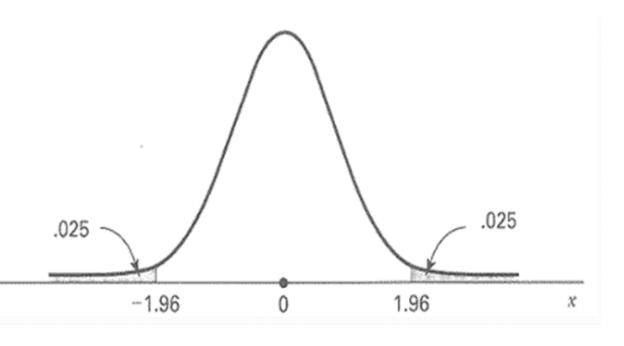
Z-test는 표준정규분포를 가정하며, 보통 단일 혹은 두 집단에서 데이커가 독립적이며 정규분포를 따르고, 두 집단을 검정할 경우 모집단에 동일한 확률로 선택되어 샘플의 크기가 비슷할 경우 사용할 수 있다. 하지만 표본의 크기가 30이상이 넘어가면 중심극한정리에 의하여 정규분포를 따른다고 가정하고 z-test를 수행할 수 있다.
Z-test는 다음과 같은 다양한 상황에서 사용할 수 있다.
검정 1: 모집단 평균에 대한 Z-검정(알려진 분산)
검정 2: 두 모집단 평균에 대한 Z-검정(알려진 분산 및 같음)
검정 3: 두 모집단 평균에 대한 Z-검정(알려진 분산 및 같지 않은 분산)
검정 4: 비율에 대한 Z-검정(이항 분포)
검정 5: 두 비율의 동일성에 대한 Z-검정(이항 분포)
검정 6: 두 카운트를 비교하기 위한 Z-검정(푸아송 분포)
검정 7: 상관 계수의 Z-검정
검정 8: 두 상관 계수에 대한 Z-검정
검정 9: 상관 비율에 대한 Z-검정
검정 10: 사건의 불확실성에 대한 Z-검정
검정 11: '로그 승산비'를 사용하여 두 그룹의 순차적 우발성을 비교하기 위한 Z-검정
상황에 따른 검정 방법을 알 수 있는 사이트:
https://r2bit.shinyapps.io/infer_shiny/
2. 추가개념
2-1. List Comprehension
comprehension을 사전으로 찾아보면 (언어적인)이해력을 의미한다. python의 공식 문서에서는 다음과 같이 Comprehension을 정의한다.
🌎python공식 문서의 Comprehension 정의
하나의 표현식과 그 뒤를 따르는 최소한 하나의 for 절과 없거나 여러 개의 for 또는 if절로 구성된다. 이 경우, 새 컨테이너의 요소들은 각 for 또는 if 절이 왼쪽에서 오른쪽으로 중첩된 블록을 이루고, 가장 안쪽에 있는 블록에서 표현식의 값을 구해서 만들어낸 것이다.
코드로 문법을 확인하면 더욱 쉽다. List Comprehension에서 확인해볼 구조는 크게 다섯 가지로 정리할 수 있을 것 같다.
- 기본 구조 : 표현식 + for문
result = [표현식 for 변수 in 리스트]- 표현식 + for문 + 조건문
result = [표현식 for 변수 in 리스트 조건문]- 조건문 + for문
result = [조건문 for 변수 in 리스트]- 중첩 for문
result = [조건문 for 변수1 in 리스트1 for 변수2 in 리스트2 ...]
사실 자세한 것은 나도 모른다. 그러므로 링크를 아래에 첨부하도록 하겠다. List comprehension을 잘 활용하면 코드가 짧고 깨긋해진다고 한다. 이런 코드를 pythonic하다고 한다고하는데 사실 뭔 말인지 잘 모르겠다.
참고 사이트:
List Comprehension
3. 명령어
3-1. .nunique()
지정된 축에 있는 고유한 요소의 수를 계산한다. 고유한 요소의 수를 가진 시리즈를 반환하며,NaN값을 무시할 수 있다.
pandas.DataFrame.nunique(axis=0,dropna=True)axis: {0 또는 index}를 입력히거나 {1 또는 columns}를 입력한다. 입력하지 않으면 0이 defalut이다. 지정된 축을 기준으로 고유한 수를 계산한다.
dropna:NaN값을 포함할지 않할지 결정한다. defalut값은 True로 포함하지 않는다.
3-2. Pandas.to_datetime()
입력된 인수를 날짜 시간으로 변환한다.
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=True)세세한 인수에 대한 설명은 하지 않도록 하겠다. 아래의 정식 문서를 참조하자.
pandas.to_datetime
3-3. numpy.random.binomial()
이항 분포에서 표본을 추출한다. 샘플은 지정된 매개변수, n번의 시행, p개의 성공 확률이 있는 이항 분포에서 추출한다. 여기서 n은 정수 >=0이고 p는 구간 [0,1]에 있다.
random.binomial(n, p, size=None)회고
이번주도 어느덧 끝이 났다. 시간 참 잘가는 거 같다. 이번 주는 살짝 머리가 아팠다. 확률과 통계는 이번주 내내 그냥 말했지만 진짜 토가 나온다 토가나와...말이 너무 어렵다. 이해할려면 한 수십번은 읽어야하는 것 같다. 그래도 이제 통계 part는 끝나니까 행복하다.
