0. 학습목표
- 사이킷런 파이프라인(Pipelines)을 이해하고 활용 할 수 있다.
- 사이킷런 결정트리(Decision Tree)를 사용할 수 있다.
- 결정트리의 특성 중요도(Feature importances)를 활용할 수 있다.
- 결정트리 모델의 장점을 이해하고 선형회귀 모델과 비교할 수 있다.
1. 주요개념
0. Pipe Line
Pipe Line의 대략적 개념 설명과 실행 코드 예제는 앞의 N212에서 정리하였다. 참조하자.
💡 N212 :https://velog.io/@sea_panda/N212-TIL-%EB%B0%8F-%ED%9A%8C%EA%B3%A0
1. Decision Tree(의사결정 트리)
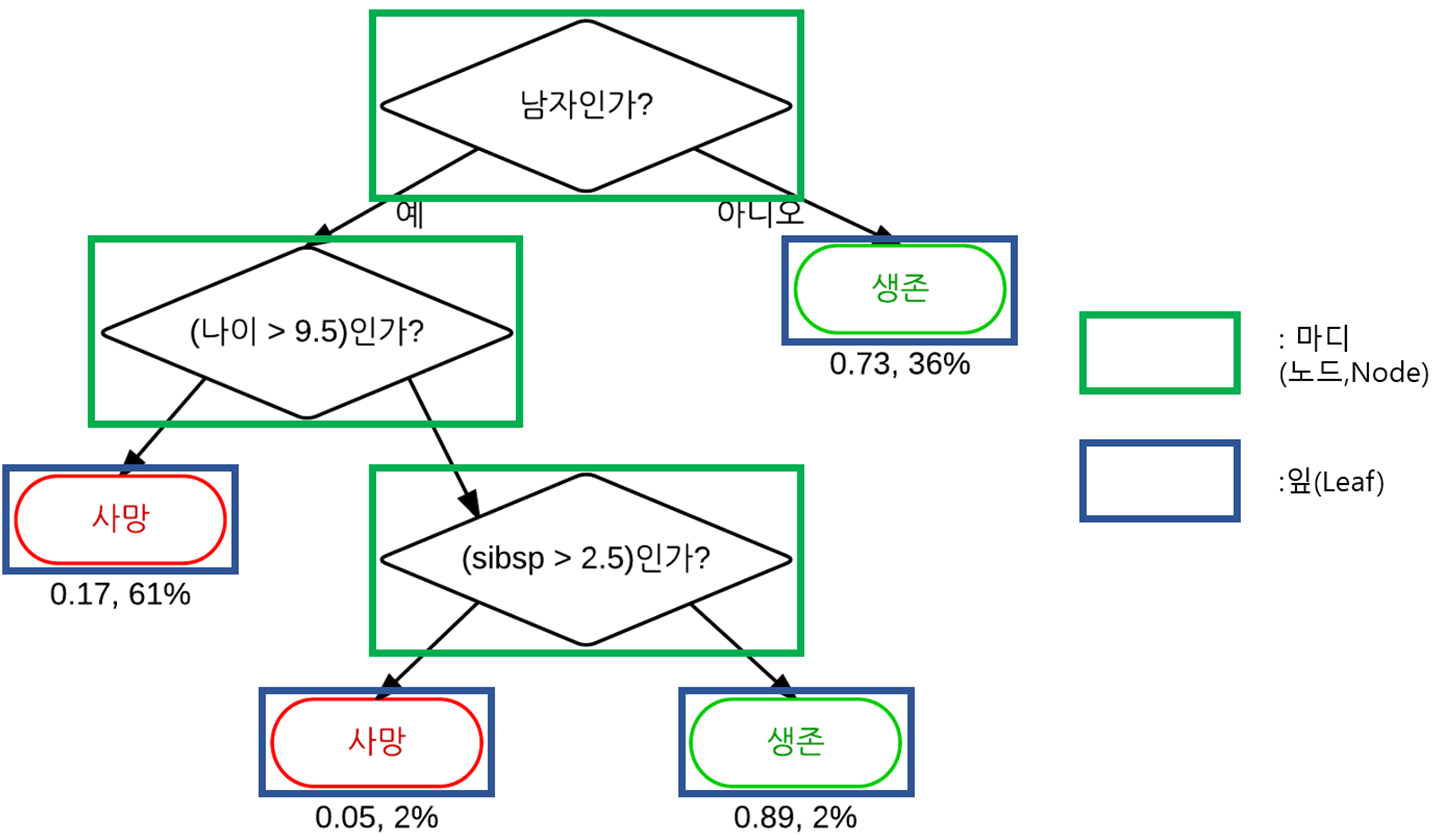
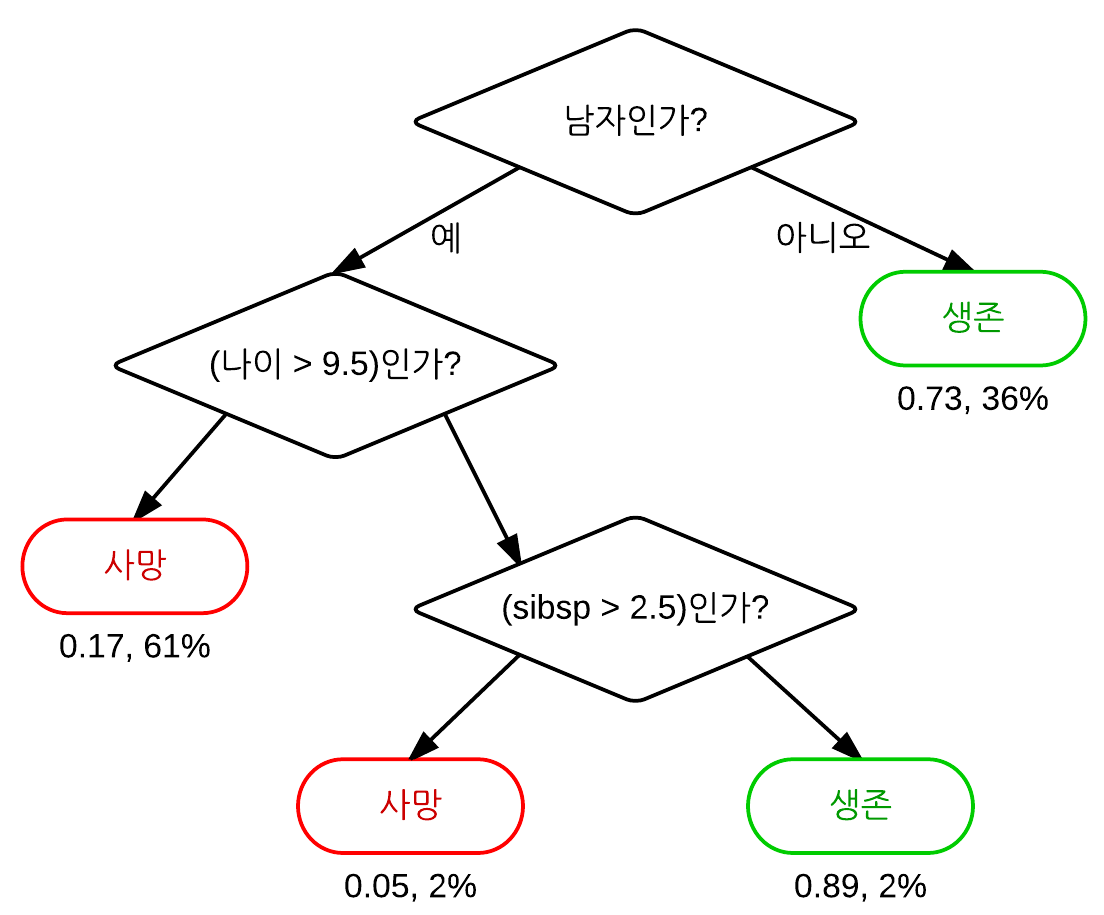
- 마디(노드,Node)
의사 결정 트리와 같은 가지치기 형태로 구성된 규칙들이 집합에서, 노드는 분할 규칙의 시각적인 표시라고 할 수 있다.- 잎(Leaf)
if-then 규칙의 가장 마지막 부분, 혹은 트리의 마지막 가지(Branch)부분을 의미한다. 트리 모델에서 잎 노드는 어떤 레코드에 적용할 최종적인 분류 규칙을 의미한다.
트리 모델은 회귀 및 분석 트리(Classification And Regression Tree,CART), 의사 결정 트리(Decision Tree), 혹은 단순히 그냥 트리(Tree)라고도 불리며 1984년 레오 브레이먼과 그의 동료들이 처음 개발한 효과적이고 대중적인 분류(및 회귀) 방법이다. 트리 모델들과 여기서 파생된 강력한 랜덤 포레스트(Random Forest)와 부스팅 트리 같은 방법들은 회귀나 분류 문제를 위해 데이터 과학에서 가장 널리 사용되는 강력한 예측 모델링 기법들의 기초라고 할 수 있다.
트리 모델이란 쉽게 말해 if-then-else 규칙의 집합체라고 할 수 있다. 따라서 이해하기도 쉽고 구현하기도 쉽다. 선형회귀나 로지스틱 회귀와 반대로 트리는 데이터에 존재하는 복잡한 상호 관계에 따른 숨겨진 패턴들을 발견하는 능력이 있다. 게다가 KNN이나 나이브 베이즈 모델과 달리, 예측변수들 사이의 관계로 단순 트리 모델을 표시할 수 있고 쉽게 해석이 가능하다.
의사 결정 트리 만들 때는 재귀 분할(Recursive Partitioning)이라고 하는 알고리즘을 사용한다. 재귀 분할이란 마지막 분할 영역에 해당하는 출력이 최대한 비슷한(Homogeneous)결과를 보이도록 데이터를 반복적으로 분할하는 것을 의미한다. 간단하면서도 직관적인 방법이다. 예측변수 값을 기준으로 데이터를 반복적으로 분할해나간다. 분할할 때에는 상대적으로 같은 클래스의 데이터들끼리 구분되도록 한다.
응답변수 Y와 P개의 예측변수 집합 가 있다고 가정하자. 어떤 파티션(분할영역) 에 대해, 를 두 개의 하위 분할 영역으로 나누기 위한 가장 좋은 재귀적 분할 방법을 찾아야 한다.
💡 재귀적 분할 방법 탐색 과정
- 1. 각 예측변수 에 대해,
- a. 에 해당하는 각 변수 에 대해
- i. 에 해당하는 모든 레코드를 인 부분과 나머지 인 부분으로 나눈다.
- ii. 의 각 하위 분할 영역 안에 해당 클래스의 동징설을 측정한다.
- 클래스의 동질성이 가장 큰 변수 와 값을 선택한다.
이제 알고리즘의 재귀 부분이 나온다.
💡 알고리즘의 재귀 부분
1. 전체 데이터를 가지고 A를 초기화한다.
2. 를 두 부분 과 로 나누기 위해 분할 알고리즘을 적용한다.
3. 과 각각에서 2번 과정을 반복한다.
4. 분할을 해도 더는 하위 분할 영역의 동질성이 개선되지 않을 정도로 충분히 분할을 진행 했을 때 , 알고리즘을 종료한다.
각 영역은 해당 영역에 속한 응답변수들의 다수결 결과에 따라 0 또는 1로 예측 결과를 결정한다.
이때, 위에서 이미 설명했듯이 각 분할 영역에 대한 동질성, 즉 클래스 순도(Class purity)를 측정하는 방법이 필요하다. 혹은 동일한 목적을 위해서 불순도를 측정해도 된다. 해당 파티션 내에서 오분류된 레코드의 비율 p로 예측의 정확도를 표기할 수 있다. 이는 0(완전)~0.5(순수 랜덤 추측) 사이의 값을 가진다.
정확도는 불순도를 측정하는 좋지 않은 것으로 밝혀졌다. 따라서 불순도를 측정하기 위해(불순도를 측정하는 것이 결정 트리의 비용함수가 된다.) 지니 불순도(Gini impurity)와 Entropy(엔트로피)를 대표적으로 사용한다.
이때 여기서 의미하는 불순도라는 개념은 여러 범주가 섞여 있는 정도를 이야기 한다. 만일 샘플에 단일 범주만 존재한다면 불순도는 0이 된다.
먼저 이진 분류에서의 Gini impurity와 Entropy의 식은 다음과 같다.
이 식을 일반화 시켜서 다중 분류에서의 불순도의 식은 다음과 같이 전개할 수 있다.
❗ 지니계수
지니 불순도를 지니 계수와 혼동해서는 안된다. 둘 다 모두 개념적으로는 비슷하지만 지니 계수는 이진 분류 문제로 한정되며, AUC지표와 관련 있는 용어이다.
이를 통해 계산한 불순도를 이용하여 정보획득(특정한 특성을 사용해 분할할 때의 불순도 감소량)이 가장 큰 것을 선택한다. 정보획득의 식은 다음과 같다.
단일 트리 모델의 장점은 먼저 데이터 탐색을 위한 시각하가 가능하다는 것이다. 이는 어떤 변수가 중요하고 변수 간에 어떤 관계가 있는지를 보여준다. 트리 모델은 예측변수들 간의 비선형 관계를 담아낼 수 있다.
두번째로는 일종의 규칙들의 집합으로 볼 수 있기 때문에 실제 구현 방법에 대해서, 아니면 데이터 마이닝 프로젝트 홍보에 대해서 비전문가들과 대화하는데 아주 효과적이라고 할 수 있다.
하지만 예측에 관해서는, 다중 트리에서 나온 결과를 이용하는 것이 단일 트리를 이용하는 것보다 보통은 훨씬 강력하다. 특히 랜덤 포레스트와 부스팅 트리 알고리즘은 거의 항상 우수한 예측 정확도나 성능을 보여준다. 물론 앞서 설명한 단일 트리의 장점들을 잃어버린다는 단점이 있다.
2. Grid Search
Grid Search란 모델의 하이퍼 파라미터(하이퍼 파라미터도 앞에서 정리했다.)에 넣을 수 있는 값들을 순차적으로 입력한 뒤에 가장 높은 성능을 보이는 하이퍼 파라미터를 찾는 탐색 방법이다.
굳이 사람이 하나하나 대입하여 주지 않아도 만들어 둔 틀을 이용하여 우리가 자고 있는 시간에도 잠재적인 하이퍼 파라미터들의 후보군둘의 조합 중에서 가장 Best조합을 찾아준다. 하지만 가장 큰 단점은 HyperParmeter 후보군의 갯수만큼 비례하여 시간이 늘어나기 때문에 최적의 조합을 찾을 때까지 매우 오랜 시간이 걸린다는 단점이 존재한다.
💡 Grid Search관련 참고 사이트
1. Sklearn Grid Search
2. Logistic Regressin-hyperparameter
3. 특성 중요도(feature Importance)
선형 모델에서는 특성과 타겟의 관계를 확인하기 위하여 회귀 계수(Coefficients)를 살펴보았다. 하지만 결정트리에서는 회귀 계수 대신 특성 중요도(Feature Importance)를 확인할 수 있다. 회귀계수와 달리 특성중요도는 항상 양수값을 가진다. 이 값을 통하여 특성이 얼마나 일찍 그리고 자주 분기에 사용되는지 결정된다.
랜덤 포레스트 모델의 경우는 학습 후에 특성들의 중요도 정보를 기본으로 제공한다. 이때 이 중요도는 노드들의 불순도를 가지고 계산하는데, 노드가 중요할수록 불순도가 크게 감소한다는 사실을 이용한다. 노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성의 중요도가 올라가게 된다.
이때 특성 중요도를 계산할 때 사용하는 방식이 Mean decrease impurity(MDI)라는 방식을 사용한다.
MDI는 각 변수가 Split 될 때 불순도 감소분의 평균을 중요도로 정의하는 것이다.
이 방식은 빠르고 직관적이라는 장점이 존재한다. 하지만 High-cardinality 범주형 변수에 대해서 Bias가 나타난다. 범주가 많은 특성은 트리가 나뉠 때 이용될 확률이 높고, 따라서 전체적인 일반화보단 범주가 많은 특성에 편향되어 과적합을 일으키기 쉽고, 정보획득이 높게 측정되는 오류를 발생시켜 잘못된 해석으로 귀결될 수 있다.
4. 특성 상호작용
특성상호작용은 특성들끼리 서로 상호작용을 하는 경우를 말한다. 회귀분석에서는 서로 상호작용이 높은 특성들이 있으면 개별 계수를 해석하는데 어려움이 있고 학습이 올바르게 되지 않을 수 있다. 하지만 트리모델은 이런 상호작용을 자동으로 걸러내는 특징이 있다.
특성상호작용에 대한 상세한 예시는 아래의 참고사이트를 참고하자.
5. Monotonic/ Non-monotonic function
갑자기 함수가 튀어나온 이유는 결정트리 모델의 장점 때문이다. 결정 트리 모델은 선형 모델과 달리 비선형, 비단조, 특성 상호작용 특징을 가지고 있는 데이터 분석에 용의하다는 장점이 존재한다. 이때 비단조함수가 무엇인지 정리하여 본다.
5-1. Monotonic function(단조함수)
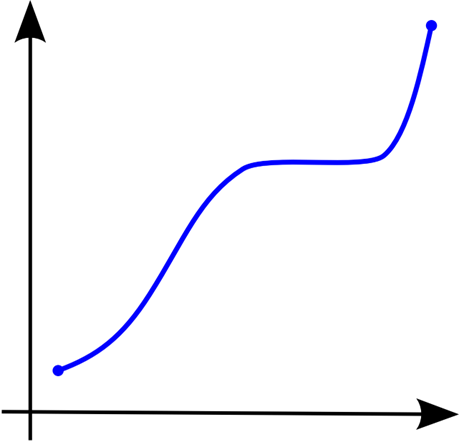
수학에서 Monotonic function은 주어진 순서를 보존하는 함수를 의미한다. 이 말을 풀어서 설명하자면 결국 줄곧 상승하거나, 줄곧 하강하는 함수를 말한다. 이때 증가하는 함수가 수평으로 나아가도 상관은 없다. 일차함수, 지수함수, 로그함수가 대표적인 단조함수이다.
5-2. Non-monotonic function(비단조 함수)
앞서 설명한 단조함수와 다르게 함수가 상승과 하강을 반복하는 함수를 의미한다. 이차함수는 비단조 함수의 예시이다.
2. 명령어
1. .select_dtypes()
df.select_dtypes(include='None',exclude='None')열의 data type을 기준으로 include인자에 할당된 데이터 타입에 해당하는 열을 반환한다. exclude인자를 사용할 경우 해당 data type을 가지는 열을 제외한 나머지 열들을 반환한다.
2. .nunique()
df['column명'].nunique()해당 열에 고유값의 수가 몇개인지 출력하여 준다. 만일 범주형 변수일 경우 범주의 수를 출력하여 준다고 생각하면 된다.
3. .tolist()
numpy라이브러리의 명령어이다.
numpy.ndarray.tolist()numpy의 array를 python의 list로 바꿔준다. 변경할 시 array의 차원을 그대로 유지한다. 이 명령어는 매개변수들이 존재하지 않는다.
4. pipe.named_steps[ ]
# 사용예제
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(),
DecisionTreeClassifier(max_depth=6, random_state=2)
)
model_dt = pipe.named_steps['decisiontreeclassifier']pipe라인에서 각 단계에 접근할 수 있도록 해주는 명령어이다. 이를 통하여 각 단계에서 어떤 과정으로 명령어가 실행되는지 확인해 볼 수 있다.
5. .plot.barch()
가로 막대를 출력해주는 Pandas라이브러리의 method이다. 이 가로 막대 그래프는 수평 막대 도표라고도 하며 값에 비례하는 길이의 직사각형 막대로 정량적 데이터를 나타낸다.
그래프의 한 축은 비교 중인 특정 범주를 나타내고 다른 축은 측정된 값을 나타낸다.
df = pd.DataFrame({'lab': ['A', 'B', 'C'], 'val': [10, 30, 20]})
ax = df.plot.barh(x='lab', y='val')
>>> 실행결과 아래 사진과 같은 그래프 출력.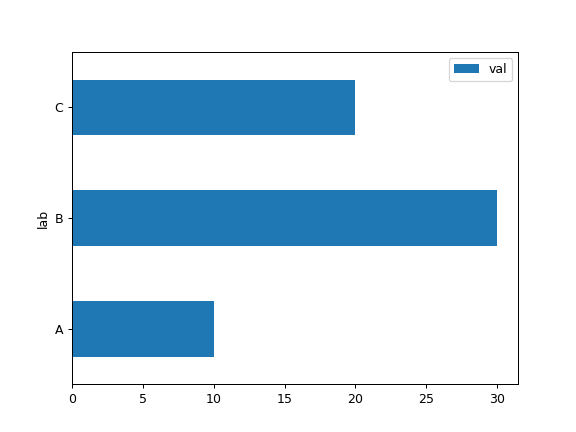
6. Module: sklearn.tree
분류 및 회귀 문제를 해결하기 위한 의사 결정 트리 기반 모델들을 사용할 수 있는 모듈이다.
💡 Sklearn.Tree 모듈에서 사용 가능한 모델들
1. DecisionTreeClassifier: Decision Tree 분류 모델
2. DecisionTreeRegressor: Decision Tree 회귀 모델
3. ExtrealTreeClassifier: 극도로 무작위화된 Decision Tree 분류 모델
4. ExtrealTreeRegressor: 극도로 무작위화된 Decision Tree 회귀 모델
6-1. DecisionTreeClassifier
의사 결정트리 분류기(Decision Tree)모델을 생성, 학습하여 예측을 진행할 수 있게 해주는 명령어이다.
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='gini',splitter='best',
max_depth='None','min_samples_split=2
min_samples_leaf=1,....)💡 각 인자들의 기능
Criterion: 불순도를 계산하는 방식을 선택한다.gini외에entropy와log_loss가 있다. 하지만log_loss는 실행해 봤을 때 잘 안됐다. 아직 내 잘 못인지 sklearn잘 못인지 모르겠다.
splitter: 각 노들 분할할 때 어떤 방식으로 분할할지 결정한다. defalut는best로 위에서 설정한Criterion인자의 계산 방식을 통해서 정보획득이 최대가 되는 방식으로 분할한다. 이 외에random방식으로도 분할 할 수 있다.
max_depth: 트리의 최대 깊이를 나타낸다. None이면 최대 깊이로 분할하며,min_samples_split샘플 미만을 포함할 때까지 노드가 확장된다.
min_samples_split: 내부 노드를 분할하는데 필요한 최소의 샘플 수를 의미한다.
min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수를 의미한다.
6-2. export_graphviz
# 사용예제
# pipe는 생성된 pipeline을 의미한다.
import graphviz
from sklearn.tree import export_graphviz
model_dt = pipe.named_steps['decisiontreeclassifier']
enc = pipe.named_steps['onehotencoder']
encoded_columns = enc.transform(X_val).columns
dot_data = export_graphviz(model_dt
, max_depth=3
, feature_names=encoded_columns
, class_names=['no', 'yes']
, filled=True
, proportion=True)의사결정트리 모델을 DOT형식으로 내보낸다.
이 함수는 의사 결정트리에서 GrphViz표현을 생성하여 출력한다. 상세한 내용은 킹식 문서를 참조하자.
여기서 말하는 DOT형식이라는 것은 그래프 서술언어로 마이크로소프트에서 만든 파일 형식이다.
위의 사진과 같은 그래프를 출력하여 주는 것이다.
❗ Export_graphviz 공식문서
사이트 주소: https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html#sklearn.tree.export_graphviz
7. Library: graphviz
GraphViz는 GraphViz.org에서 개발중인 오픈소스 다이어그램 생성기이다.
❗ GraphViz 공식 사이트
사이트 주소: https://narusas.github.io/2019/01/25/Graphviz.html
3. 회고
<11월 17일 밤>
오늘은 과제를 처음으로 Kaggle로 진행했다. 점수가 나오고 또 그에 따른 순위가 나오다보니까 잘하고 싶다는 욕심에 기본과제만 붙잡고 하루를 날린 것 같다. 내 욕심이지...심지어 도전과제도 못했다. 그리고 이 정리도 다 못끝낼 거 같다. 어제 정상화 시키고 이어나간다고 했는데 결심이 24시간도 못갔다. 제출하고도 미련이 남아서 계속 이것저것 하고 디스코드에 새로운 내용 올라오면 해보고 하느라 시간이 다 간 것 같다. 여하튼 내일은 진짜 딱 멘토님들이 말씀하신대로 기본적인 것만 해서 빠르게 제출하고 해당 노트에 대해서 더 개인적으로 공부하는 시간을 늘려야겠다.

오늘의 교훈: 욕심 부리지말자. 난 말하는 감자다.
<11월 18일>
명령어 정리 완료. 그리고 가능하다면 디스커션 내용도 정리하고 싶은데 그건 너무 욕심인거 같다 그 내용은 노션을 그냥 보는게 더 좋을 것 같다. 지금 이렇게 정리하는 것도 너무 많은 시간을 들이는거 아닌가 걱정이다.
❗ 참고자료
1. Peter Bruce, Andrew Bruce, and Peter Gedeck,Practical Statistics for Data Scientists:데이터 과학을 위한 통계 2판,서울: 한빛미디어,2022
2. 특성 중요도
3. 특성 상호작용
4. DOT(그래프 서술 언어)
