0. 학습목표
- Random Forests모델을 이해하고 문제에 적용할 수 있다.
- 순서형 인코딩(Ordinal Encoding)과 원핫인코딩(One-hot Encoding)을 구분하여 사용할 수 있다.
- 범주형 변수의 인코딩 방법이 트리모델과 선형회귀 모델에 주는 영향을 이해한다.
1. 주요개념
1. Ensemble 기법(학습)
앙상블 학습(Ensemble Learning)을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 얘측을 도출하는 기법을 말한다.
앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것이다.
이미지, 영상, 음성 등의 비정형 데이터의 분류는 딥러닝이 뛰어난 성능을 보이고 있지만, 대부분의 정형 데이터 분류 시에는 앙상블이 뛰어난 성능을 나타내고 있다. 앙상블 알고리즘의 대표격인 Random Forest와 Gradient Boosting 알고리즘은 뛰어난 성능과 쉬운 사용, 다양한 활용도로 인해 그간 분석가 및 데이터 과학자들 사이에서 많이 애용됐다.
최근 매력적인 솔루션으로 불리고 있는 XGBoost, XGBoost와 유사한 예측 성능을 가지면서도 훨씬 빠른 수행 속도를 가진 LightGBM, 여러가지 모델의 결과를 기반으로 메타 모델을 수립하는 스태킹(Stacking)을 포함해 다양한 유형의 앙상블 알고리즘이 머신러닝의 선도 알고리즘으로 인기를 모으고 있다. XGBoost, LightGBM과 같은 최신의 앙상블 모델 한 두개만 잘 알고 있어도 정형 데이터의 분류나 회귀 분야에서 예측 성능이 매우 뛰어난 모델을 쉽게 만들 수 있다. 그만큼 쉽고 편하면서도 강력한 성능을 보유하고 있는 것이 바로 앙상블 학습의 특징이다.
✏ 정형 데이터와 비정형 데이터
- 정형 데이터
그 값의 의미를 파악하고 쉽고, 규칙적인 값으로 데이터가 들어갈 경우 정형 데이터라고 한다.- 비정형 데이터
정형 데이터와 반대되는 의미로, 정해진 규칙이 없어서 값의 의미를 파악하기 힘든 데이터를 의미한다. 흔히, 텍스트, 음성, 영상과 같은 데이터가 대표적인 비정형 데이터이다.
2. Random Forest(랜덤 포레스트)
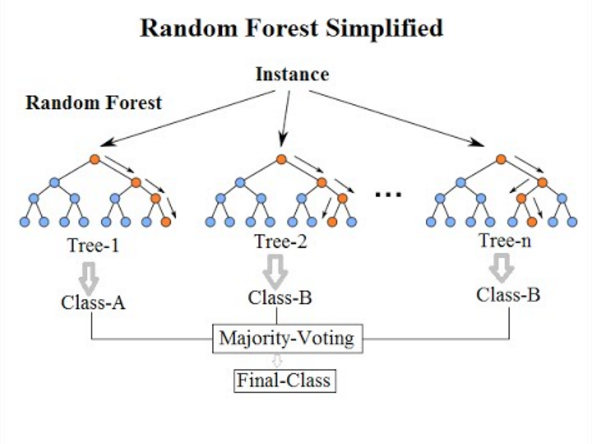
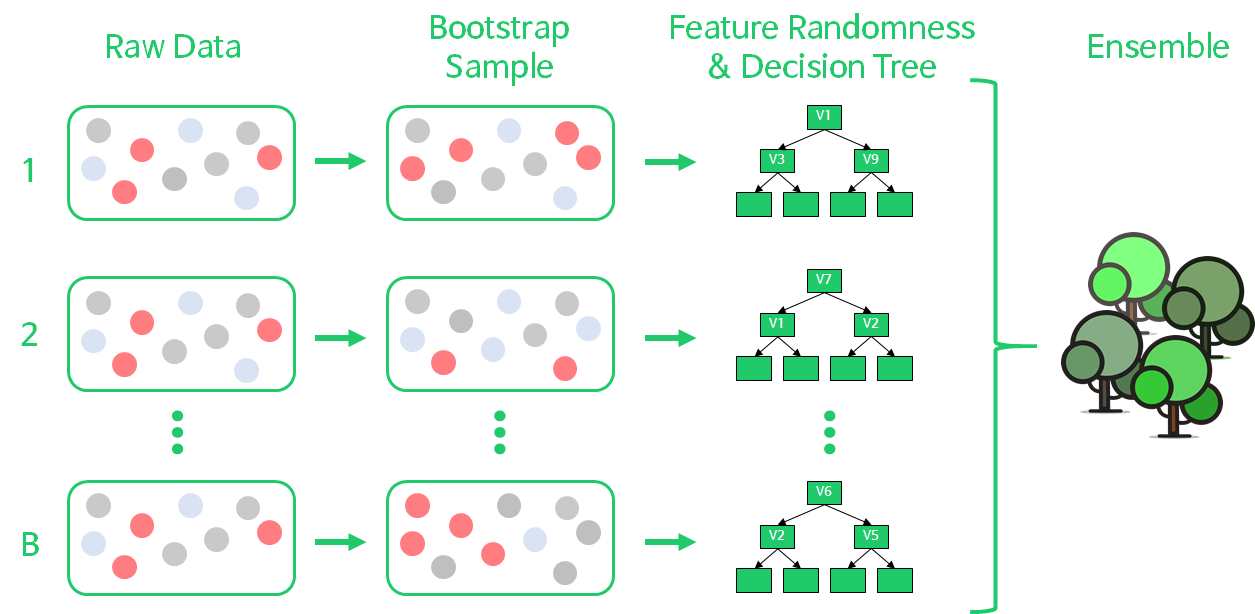
Random Forest는 Bagging 알고리즘의 대표적인 예시이다. 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있으며, 다양한 영역에서 높은 예측 성능을 보이고 있다. 랜덤 포레스트의 기반 알고리즘은 결정 트리로서, 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있다.
랜덤 포레스트는 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 하게 된다. 랜덤 포레스트는 개별적인 분류기의 기반 알고리즘은 결정 트리이지만 개별 트리가 학습하는 데이터 세트는 전체 데이터에서 일부가 중첩되게 샘플링(Bootstrapping)된 데이터 세트이다. 서브세트의 데이터 건수는 전체 데이터 건수와 동일하지만, 개별 데이터가 중첩되어 만들어진다.
- Random Forest의 의사 코드

3. Bootstrap과 Aggregation(Bagging)
"Bootsrap을 분명 어디서 정리했는데 기억이 안난다했더니 정리했던적이 읎네?"
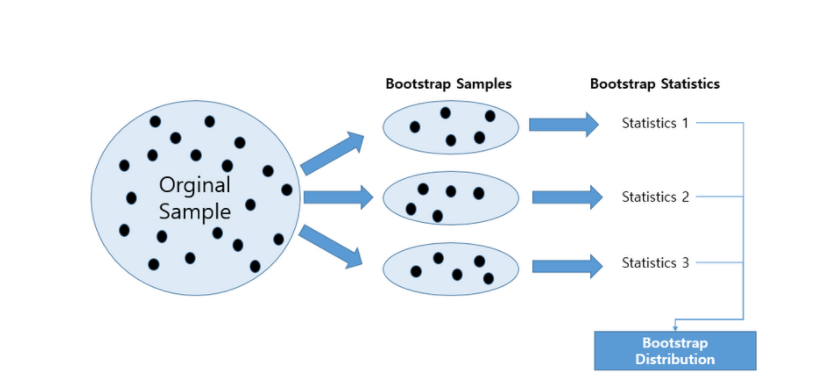
통계량이나 모델 파라미터(모수)의 표본분포를 추정하는 쉽고 효과적인 방법은, 현재 있는 표본에서 추가적으로 표본을 복원추출하고 각 표본에 대한 통계량과 모델을 다시 계산하는 것이다. 이러한 절차를 Bootstrap이라 하며, 데이터나 표본통계량이 정규분포를 따라야 한다는 가정은 꼭 필요하지 않다.
조금 더 쉽게 말하자면 여러 개의 데이터 세트를 원래의 데이터 세트에서 중첩되게 분리하는 것이 Bootstrapping이라고 할 수 있겠다.
Aggregation은 위의 Bootstrapping을 통해 생성된 데이터 세트를 합치는 과정을 의미한다. 회귀 문제일 경우 기본모델 결과들의 평균으로 결과를 내고, 분류문제일 경우 다수결로 가장 많은 모델들이 선택한 범주로 예측한다.
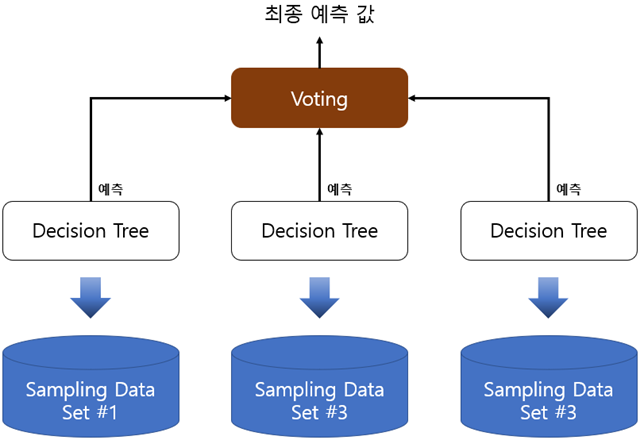
Bootstrap과 Aggregation을 하나의 과정으로 통합하여 Bagging(Bootstrap Agrregation)이라고 한다. Bagging은 다양한 모델들을 정확히 같은 데이터에 대해 구하는 대신, 매번 부트스트랩 재표본에 대해 새로운 모델을 만든다. 이 부분만 빼면 앞에서 설명한 기본적인 앙상블 방법과 동일하다. 알고리즘은 다음과 같다.
💡 Bagging 알고리즘
- Precondition
- 개의 예측변수
- : 응답변수
- : 레코드의 수
- 알고리즘
1. 만든 모델의 개수 M과 모델을 만드는데 사용할 레코드의 개수 n(n)의 값을 초기화 한다. 반복 변수 로 놓는다.
- 훈련 데이터로부터 복원추출 방법으로 개의 부분 데이터 과 을 부투스트랩 재표본 추출한다.
- 의사 결정 규칙 를 얻기 위해, 과 을 이용해 모델을 학습한다.
- 로 모델 개수를 늘린다. 이면 다시 2단계로 간다.
이 인 경우의 확률을 예측한다고 했을 때, 배깅 추정치는 다음과 같이 정의할 수 있다.
4. Ordinal Encoding
Categorical feature(범주형 특성)에 대한 순서형 코딩이라고 하며, 각 범주들을 특성으로 변경하지 않고, 구 안에서 1,2,3 등의 숫자로 변경하는 방법이다. 범주가 너무 많거나, 학습 모델 등의 이유로 One-hot encoding방법이 적절하지 않을 때 사용할 수 있는 또 다른 Encoding방법이다.
트리 기반 모델의 경우는 특히 One-hot Encoding이 적절하지 않은 경우가 많다. 만일 One-hot Encoding을 진행하게 되면 연속 변수의 경우는 트리를 분할 할 수 있는 여러가지 기준을 세워서 비교하며 사용할 수 있다. 따라서 결정트리가 양방향으로 고르게 퍼져가난다. 하지만 One-hot Encoding을 진행하게 되면 인코딩된 각각의 노드에는 이진형인 0,1의 답만 있기 때문에 나무가 한방향으로만 쭈욱 자라게 된다.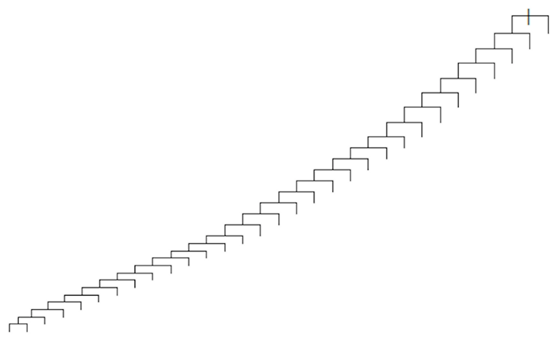
특성 정보가 0과 1로만 구성되기 때문에 데이터 세트이 희소성이 증가하게 된다. 희소성이 증가한다는 의미는 의미 없는 데이터가 많아진다는 뜻이고, 이로 인하여 모델의 학습이 제대로 이루어지지 않는다.
또한, 트리기반 모델 관점에서는 각 특성은 독립적이기 때문에 특성의 수가 늘어나게 되면 분할당 얻는 정보 획득의 양이 줄어들게 되고, 이로 인해서 원래의 특성이 가지는 중요도보다 평가 절하되어 상위노드에서의 선택율이 줄어들고, 이로 인하여 전체적인 성능저하가 발생할 수 있다.
5. __or_(언더스코어,Underscore)
Python에서는 언더스코어(__)는 특별하다. 타 언어에서는 언더스코어는 단지 스네이크 표기법(?)의 변수나 함수명을 위해서만 사용되어지는 반면, 파이썬에서는 이 문자의 의미가 다양하다.
파이썬에서 언더스코어는 다음과 같은 상황에서 사용되는데 크게 5가지의 경우가 있다.
💡 언더스코의 사용
1. 인터프리터(Interpreter)에서 마지막 값을 저장할 때
2. 값을 무시하고 싶을 때(흔히 "I don't care"라고 부른다.)
3. 국제화(Internationalization,i18n)/지역화(Localization,l10n)함수로써 사용할 때
4. 변수나 함수명에 특별한 의미 또는 기능을 부여하고자 할 때
5. 숫자 리터럴 값의 자릿수 구분을 위한 구분자로써 사용할 때
# 1. 인터프리터에서 사용되는 경우
# 파이썬 인터프리터에선 마지막으로 실행된 결과값이 __라는 변수에 저장된다.
>>> 10
10
>>> _
10
>>> _ * 3
30
# 2. 값을무시하고 싶은 경우
# 언패킹시 특정값을 무시
x, _, y = (1, 2, 3) # x = 1, y = 3
# 여러개의 값 무시
x, *_, y = (1, 2, 3, 4, 5) # x = 1, y = 5
# 인덱스 무시
for _ in range(10):
do_something()
# 특정 위치의 값 무시
for _, val in list_of_tuple:
do_something()
# 3. 특별한 의미의 네이밍을 하는 경우
# 이 부분은 너무 길다. 아래의 참고 자료의 링크 확인.
# 나머지도 참고 자료 참고하자. 너무 길어질 것 같다.2. 명령어
1. Module: sklearn.ensemble
앙상블 기반의 학습 모델들을 사용할 수 있는 모듈이다.
1-1. RandomForestClassifier
RandomForest분류기를 사용할 수 있다. 평균화를 사용하여 예측 정확도를 개선하고 과적합을 제어한다. 하위 샘플 크기는 bootstrap=True일 때 max_samples에 의해서 제어되고, 그렇지 않으면 전체 데이터 세트가 각 트리를 구축하는데 사용된다.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(max_depth='None', criterion='gini',...)2. category_encoders.OrdinalEncoder
범주형 Feature를 숫자로 인코딩 해주는 명령어이다. 이때 Mapping을 진행해주지 않으면 범주형 자료에 랜덤하게 숫자가 배정된다.
from category_encoders import OrdinalEncoder
enc = OrdinalEncoder(mapping='None',cols='None',...,handle_missing='Value',
handle_unknown = 'Value')💡 공식 사이트
https://contrib.scikit-learn.org/category_encoders/ordinal.html
3. 회고
공부를 해야하는데 계속해서 뭔가 다른 할 일이 생기는 것 같다. 이번주 주말에는 또 시제 지내러 시골 내려갔다가 김장하러 또 문경에 가야하는데 김장하러는 못갈 거 같다. 사둔 책은 늘어나는데 도무질 펴 보지를 못하고 있다.
주말에 빨리 시제지내고 올라와서 못다한 도전과제들 해결하고 다른 동기분들 코드도 뜯어보면서 공부 좀 하고 책도 사둔거 빨리 시작해야겠다.
❗ 참고 자료
1. Peter Bruce, Andrew Bruce, and Peter Gedeck,Practical Statistics for Data Scientists:데이터 과학을 위한 통계 2판,서울: 한빛미디어,2022
2. 권철민, 파이썬 머신러닝 완벽 가이드(개정 2판), 파주:위키북스, 2022
3. Ordinal Encoding
4. Underscore
5. Underscore2
